
Elasticsearch 如何实现查询/聚合不区分大小写?
1、实战问题
最近社区里有多个关于区分大小写的问题:
问题1:ES查询和聚合怎么设置不区分大小写呢?
问题2:ES7.6 如何实现模糊查询不区分大小写? 主要是如何进行分词和mapping的一些设置来实现这个效果,
自己也尝试过对setting 和 mapping字段进行设置,都是报错比较着急,
类似的问题,既然有很多同学问到,那么咱们就有必要梳理出完整的思路和方案。
这或许是铭毅天下公众号的使命所在。
这个问题不复杂,所以本文会言简意赅,直击要害!
2、问题拆解
2.1 拆解一:如果默认分词方式,能区分大小写的吗?
是的,默认分词器是Standard 标准分词器,是不区分大小写的。
官方文档原理部分:
如下的两张图很直观的说明了:标准分词器的 Token filters 核心组成是:Lower Case Token Filter。
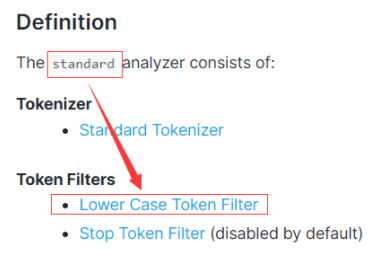
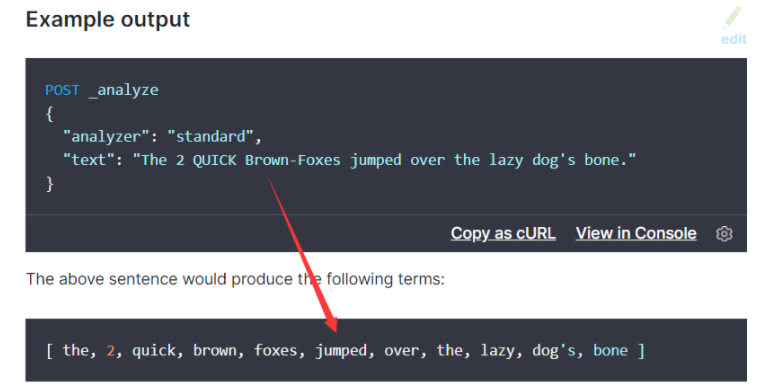
什么意思呢?大写的英文字符会转换成小写。
2.2 拆解二:实践 Demo 验证
DELETE test_003
PUT test_003
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "standard"
},
"keyword":{
"type":"keyword"
}
}
}
}
POST test_003/_bulk
{"index":{"_id":1}}
{ "city": "New York"}
{"index":{"_id":2}}
{ "city": "new York"}
{"index":{"_id":3}}
{ "city": "New york"}
{"index":{"_id":4}}
{ "city": "NEW YORK"}
{"index":{"_id":5}}
{ "city": "Seattle"}
POST test_003/_analyze
{
"text": "New york",
"analyzer": "standard"
}
POST test_003/_search
{
"query": {
"match_phrase":{
"city":"new york"
}
}
}
match_phrase 检索返回结果非常明确:_id = 1,2,3,4 的数据都被召回。
这里初步结论是:standard 标准默认分词器可以实现区分大小写。
但是,我们再看一下聚合呢?
GET test_003/_search
{
"size": 0,
"aggs": {
"cities": {
"terms": {
"field": "city.keyword"
}
}
}
}
返回结果如下:
"aggregations" : {
"cities" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "NEW YORK",
"doc_count" : 1
},
{
"key" : "New York",
"doc_count" : 1
},
{
"key" : "New york",
"doc_count" : 1
},
{
"key" : "Seattle",
"doc_count" : 1
},
{
"key" : "new York",
"doc_count" : 1
}
]
}
}
这里最核心的是:
Mapping 设置是:multi-fields。
聚合走的是 keyword 类型了,不涉及分词器:standard 了。
既然提到了 keyword, 我们进一步看:
POST test_003/_search
{
"query": {
"term":{
"city.keyword":"new york"
}
}
}
执行精准匹配后,召回结果为空。
怎么解释呢?keyword 类型属于精准匹配,也就是说:单纯的keyword 类型没法实现大小写区分。
进一步小结:
我们上面的组合multi-field 方式,并没有解决检索和聚合区分大小写的问题?
multi-field 都搞不定,那还有招吗?别急,我们慢慢来......
这时候得思考:需要在 Mapping 阶段做文章了。
核心原理:把所有都转为小写,写入时候设置 Mapping——设置filter过滤:小写过滤。
这个是一个我们过往文章没有提及的知识点 normalizer,希望你把它看完并掌握。
3、解决方案
先给出实现,后面讲原理。
PUT caseinsensitive
{
"settings": {
"analysis": {
"normalizer": {
"lowercase_normalizer": {
"type": "custom",
"char_filter": [],
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"properties": {
"city": {
"type": "keyword",
"normalizer": "lowercase_normalizer"
}
}
}
}
POST caseinsensitive/_bulk
{"index":{"_id":1}}
{ "city": "New York"}
{"index":{"_id":2}}
{ "city": "new York"}
{"index":{"_id":3}}
{ "city": "New york"}
{"index":{"_id":4}}
{ "city": "NEW YORK"}
{"index":{"_id":5}}
{ "city": "Seattle"}
GET caseinsensitive/_search
{
"query": {
"bool": {
"filter": {
"term": {
"city": "NEW YORK"
}
}
}
}
}
此时的检索返回结果是:_id = 1,2,3,4 文档都被召回。
注意,我们使用了 terms 检索。
GET caseinsensitive/_search
{
"size": 0,
"aggs": {
"cities": {
"terms": {
"field": "city"
}
}
}
}
返回结果是:
"aggregations" : {
"cities" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "new york",
"doc_count" : 4
},
{
"key" : "seattle",
"doc_count" : 1
}
]
}
}
以上 new york 4种不同大小写的全都聚合到了一起,这是我们期望的结果。
4、解决方案的原理解读
核心的核心是我们使用了:normalizer。
这个概念咱们之前分词的文章都没有提及,这里要普及一下。
官方解读如下:
The normalizer property of keyword fields is similar to analyzer except that it guarantees that the analysis chain produces a single token. The normalizer is applied prior to indexing the keyword, as well as at search-time when the keyword field is searched via a query parser such as the match query or via a term-level query such as the term query.
核心点如下:
第一:normalizer是 keyword的一个属性,类似 analyzer分词器的功能,不同的地方在于:可以对 keyword生成的单一 Term再做进一步的处理。
第二:normalizer 在 keyword 类型数据索引化之前被使用,同时在 match 或者 term 类型检索阶段也能被使用。
刚才提及的进一步处理,反映到我们的解决方案上:就是可以做小写 lowercase 转换。
由于写入阶段和检索阶段:normalizer 都生效,所以就实现了我们想要的不区分大小写的结果。
5、小结
如果官方文档熟悉,我们的示例,实际就是官方文档:normalizer 的举例。
中间的 filter 我们设置了小写,当然也可以有其他的设置,需要结合业务场景灵活使用。
欢迎大家留言说一下类似问题的其他不同实现方案。
和你一起,死磕 Elasticsearch!