
《PytorchConference2023 翻译系列》16.PyTorch 边缘部署之编译器和...
我们推出了一个新的系列,对PytorchConference2023 的博客进行中文编译,会陆续在公众号发表。也可以访问下面的地址 https://www.aispacewalk.cn/docs/ai/framework/pytorch/PytorchConference2023/PyTorch%20%E8%BE%B9%E7%BC%98%E9%83%A8%E7%BD%B2%E4%B9%8B%E7%BC%96%E8%AF%91%E5%99%A8%E5%92%8C%E5%90%8E%E7%AB%AF%E7%9A%84%E4%BE%9B%E5%BA%94%E5%95%86%E9%9B%86%E6%88%90%E4%B9%8B%E6%97%85 阅读。
大纲
1.引入
2.为什么需要合作伙伴集成
3.合作伙伴集成的优点
4.合作伙伴集成的关键技术
- 量化接口
- 委托接口
-
一个例子说明量化和委托接口
-
运行时集成
-
调试支持
-
合作伙伴案例
详细要点
-
引入
- 介绍了传统模型从PyTorch到设备的转换过程
- 每个设备都有不同的框架造成生态系统碎片化
为什么需要合作伙伴集成
- 传统转换过程会导致信息丢失和难以维护
- 覆盖范围和生产效率受限
合作伙伴集成的优点
- 提高可移植性和生产效率
- 拓宽覆盖范围促进生态系统发展
合作伙伴集成的关键技术
- 量化接口实现量化模型
- 委托接口在目标设备上高效运行部分子图
一个例子说明接口
- 示例网络和后端能力
- 使用量化和委托接口注释和分层网络
运行时集成
- 初始化和执行委托负载
调试支持
- 调试句柄支持错误定位和性能分析
大家好,我是Kimish Patel,这是我的同事Chen。我们俩都在Meta的人工智能部门工作,也是一个由合作伙伴领导的团队的一员。非常高兴能在这里与大家分享我们加速AI模型的合作伙伴集成的构想。让我先回答一个问题,为什么合作伙伴集成如此重要呢?我希望我们能先看看当前设备上AI的情况,将PyTorch模型部署到设备上的过程通常是这样的:
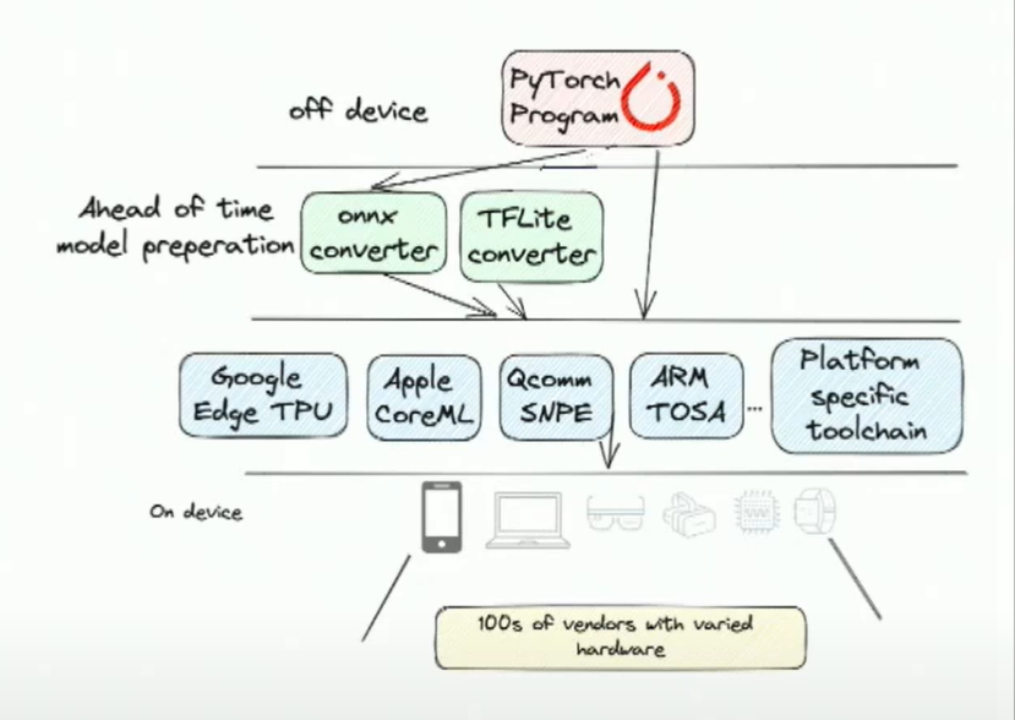
你有一个经过训练的PyTorch模型,然后它离开PyTorch进入另一个将其转换成另一种IR表示的转换器。这个IR有时是从PyTorch原始模型本身开始的。然后你会使用特定于供应商的工具链,最终将转换后的IR lower到工具链特定的IR水平。这个IR是工具链所理解的,它们可以进行翻译,对其进行设备特定的转换。此时,您实际上获得了最终要部署的资源。
您在这里看到的设备数量具有高度的多样性。您会面临操作系统的多样性,或者在一些嵌入式环境中根本没有操作系统,或者如果有操作系统,它们是一些专有的实时操作系统,专为特定的供应商定制。除此之外,从硬件多样性本身来看,这些OEM厂商使用了许多不同的芯片组和专有IPS,来自世界各地。而每个不同的IP和硬件都有各自的专有工具链、编译器等。这就是为什么设备部署变得非常困难。由于多样性的原因,目前大部分的生产工作流程中,需要使用多个转换脚本来将PyTorch模型转换为设备上的部署资源。
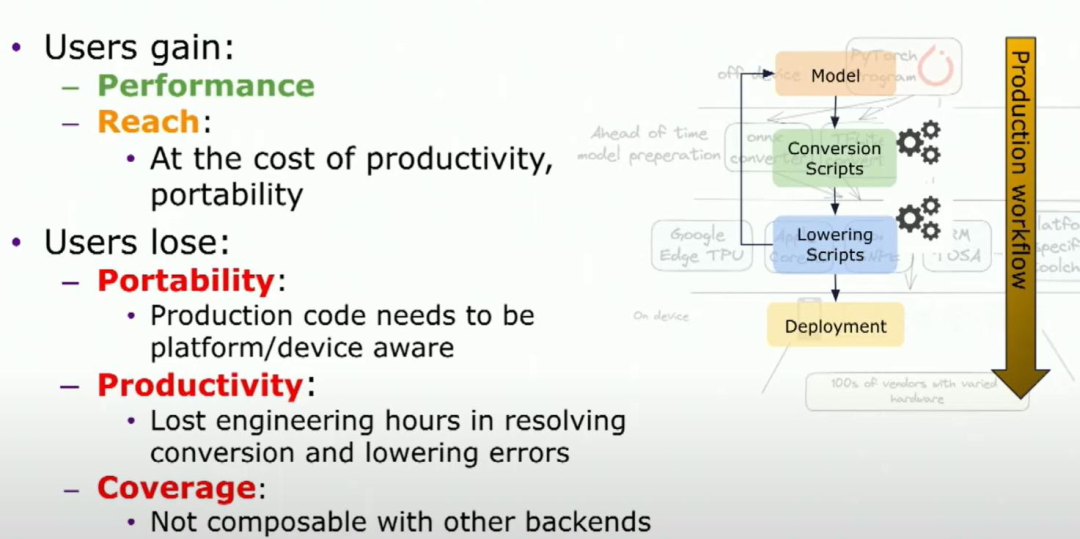
pytorch model可以转换为另一种IR,然后通过lower处理,这个处理过程包含一套自己的脚本,并最终获得部署模型所需的结果。然而,这种转换会导致信息的丢失。为什么会这样呢?因为当你从一个IR转换为另一个IR时,就像从一个领域转换到另一个领域,它们使用完全不同的语言进行交流,而且每种语言都有足够的不同之处,这就导致了信息的丢失。实际上,当你将原始的PyTorch模型部署到设备上时,它已经不再是一个PyTorch模型了。所以,如果你想了解模型的哪个部分来自于你的原始PyTorch代码,你将失去这些信息。
你可能会说,好吧,我失去了很多信息,但我确实获得了性能上的提升。我可以在特定的硬件上加速我的模型,你能够将一些模型部署到某些设备上,仅限于某些设备,因此,要么你lower整个模型,要么不lower整个模型。如果你不lower整个模型,那么实际上限制了你所能应用的模型和设备的数量。所以,你赚得不多。
对于那些机器学习工程师或部署工程师,因为要进行这些转换,意味着你的生产代码现在需要知道你在哪个设备或平台上运行你的模型。你离开了生态系统的局部,转向了整个生态系统。你需要知道的是各种模型加载和运行的接口,运行时和模型加载的API,以及分析API等等。你失去了生产力,因为现在必须处理10个不同的工具链,每个不同的设备或平台都有自己特定的工具链,你希望在上面部署同样的PyTorch模型。而且每个工具链可能都有它们自己的一套低级错误,你现在必须应对。
为了回到原始的PyTorch模型,你可能需要修改代码,以让他变成lower前的状况。整个过程包括:转换过程、查找降低错误、修复错误和往返时间。这使得即使对一个模型进行lower也变得非常低效。我们在很多使用案例中都看到过这种情况。最后,你还会失去覆盖范围。在这里,覆盖范围不仅指你在目标设备数量上失去了覆盖范围,还指你在可以应用的模型类型上也失去了覆盖范围。记得我说过lower过程是全盘接受的,对吧?所以如果你有一个模型,只有模型的一部分可以在加速或某些特定硬件上运行,现在你不能只运行那一部分。因此,你带来了一些性能和范围上的收益,但同时失去了很多东西。
是的,这并不好。理想情况下,我们希望有一个可以解决我们所有痛点的万灵药。如果我必须想一个,那就是一个联盟的形式,其中供应商、OEM合作伙伴聚集在一起,成为PyTorch和执行器生态系统的一部分。而这正是我今天要说的,对吧?这是我们在这里的目的。它能够实现什么?这正是我们谈论的愿景。以前的生态系统很零散,每个供应商都有自己的工具链或加载脚本之类的。我们希望倡导一种情况,我们能够提供一组集成入口,不同的合作伙伴可以集成进来,成为PyTorch和执行器生态系统的一部分。通过这样做,现在我们能够获得与以前相同的性能。我们能够获得更广泛的影响,因为现在通过与合作伙伴合作,我们能够针对更大的细分市场,更大的OEM、供应商和芯片领域。
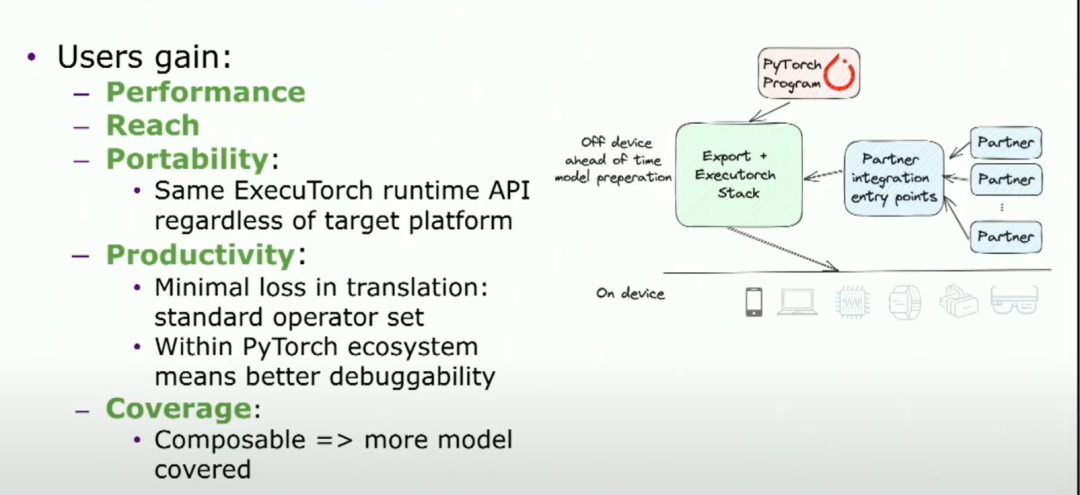
我们之所以能够实现可移植性,是因为现在可以在任何一种设备上部署相同的执行模型,用户无需改变自己的API。这样做的好处是,部署代码无需意识到这个模型实际上是为特定的Android手机或特定的iPhone设计的。从用户运行时API的角度来看,它们都是相同的。从生产力方面而言,因为您正在使用一组标准的运算符以及lower的IR和partner integration entry points,您可以进行功能和性能调试,对吧?这意味着,如果模型的某个部分运行缓慢,您可以知道这部分模型源自原始的PyTorch代码的哪个部分。也许您可以尝试找出,在这种特定设备上,实际上运行缓慢的是哪个部分,以便您可以针对该硬件进行模型的优化。因此,在优化您的工作时,您会变得更加高效。
你能够获得coverage是因为当你的模型的一部分被加速时,这些入口点的可组合性使得你只加载以加速的部分在硬件上。不能加速的部分可以由剩下的堆栈来处理,无论是另一个特殊的软件栈还是本地执行器运行时本身。对于供应商来说,这意味着他们现在只需要关注堆栈提供的入口点,而不需要担心堆栈的其余部分在做什么。所以它给你提供了一个自包含的API,并提供了隔离性,与这种可组合性相对应。所以你无法处理的部分可以让堆栈的其余部分来处理。你只需要担心优化你最擅长的部分。
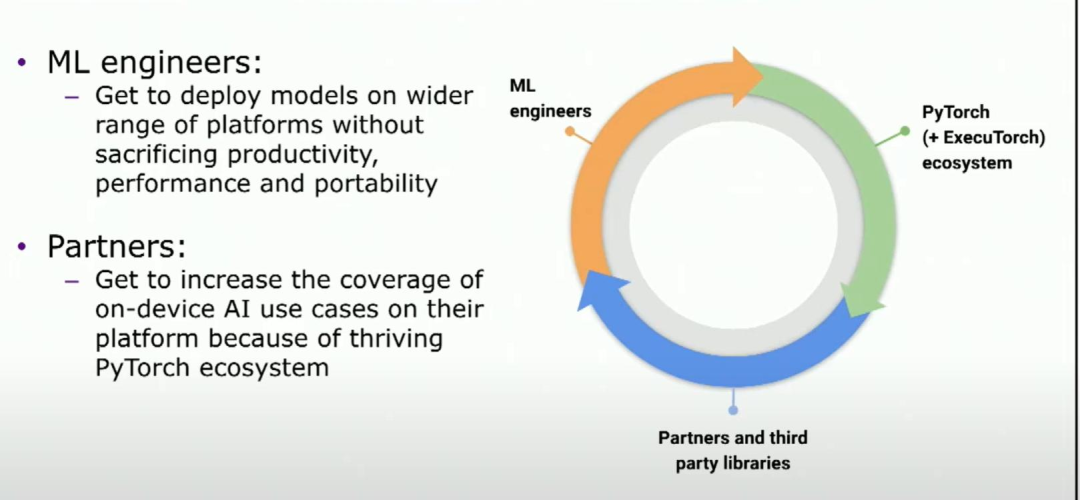
但是当我们实现了这个愿景,对于机器学习工程师来说,现在他们能够在更多种类的硬件和设备上部署他们的模型,无论是手机、流动设备还是其他任何设备。这样可以扩大他们的覆盖范围,而不会牺牲任何性能、生产力或可移植性。从合作伙伴的角度来看,这意味着他们现在能够在你们的平台上解锁更多的PyTorch模型,进而激励更多的投资,因为他们也可以在自己的设备上解锁更多模型。所以这里形成了一个正向的反馈循环,这将带来一个蓬勃发展的生态系统。
你可能会说,好吧,这一切都很好,但我该如何做到这一点呢?我们谈论了所有这些,但你所说的入口点是什么?主要有两个入口点,量化和委托(delegation)。在之前的演讲中,我们谈到了模型编写到部署的堆栈,对吧?量化和委托是这两个入口点。

这些是与合作伙伴有关的问题,发生在堆栈的不同部分。自然而然,你可能会好奇为什么有这两个入口点?我将会介绍一下这两个入口点。通常情况下,当你为加速特定类型的计算而制作专用的硬件时,它们的性能和功耗可能属于不同的类别。它们针对性能、延迟、功耗、内存等方面的高效执行进行了优化。为了进行高效执行,你需要将它们限制为特定的一组数据类型或其他类似的限制。例如,你可能有一个融合乘加的特殊指令,或者一个特定于int4或int8数据类型用于权重计算,特定于int16用于激活计算的指令。为了基于这些高效执行,我们必须确保生成的模型实际上是根据这些限制进行了训练的。这就是量化API的作用所在,因为你希望能够指定硬件特定的限制。
一旦您生成了模型,您想要做的是将供应商和原始设备制造商的特定工具链、驱动程序和运行时程序纳入生态系统中,而与系统的交互最小化。因此,所提供的集成点和API足够小,其中许多复杂性被隐藏和委托给供应商特定的软件,从而使它可组合,因为您的接口更小,你只处理需要处理的部分,而将剩余部分交给堆栈的其他部分。所以在下一个演讲的后半部分,我的同事陈将为我们介绍一个示例模型以及如何使用这两个API来实现加速和高效执行。
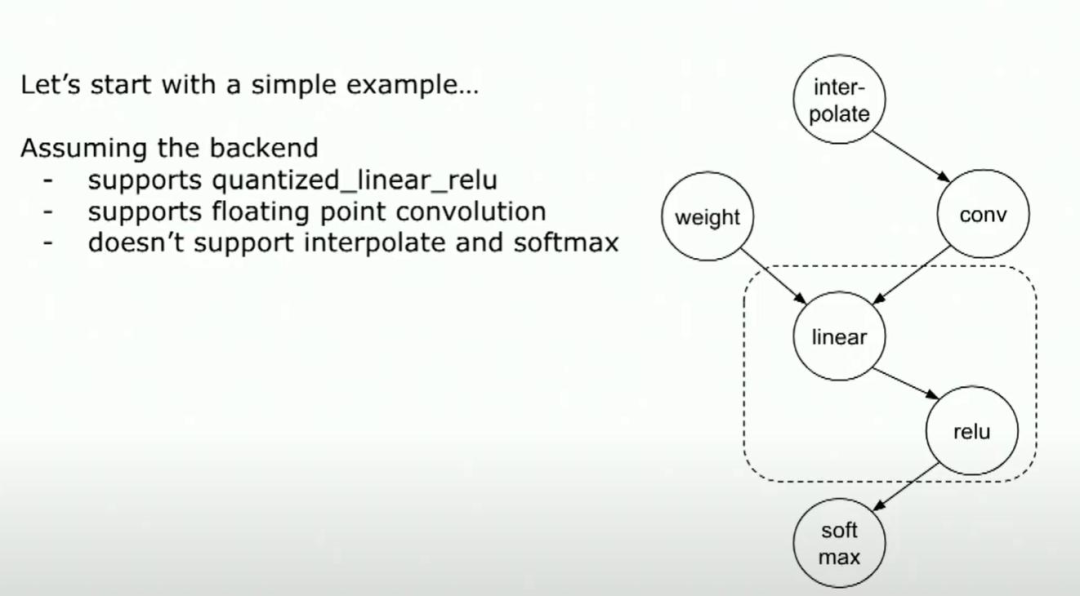
大家好,我是陈。那么让我们看一个简单的示例,并看看如何实现这些入口点。这是许多神经网络(如CNN等)中的常见模式。它是由interpolate紧跟卷积、ReLU,最后是Softmax。
所以,假设我们有一个后端,该后端支持量化卷积、linear、且量化linear ReLU作为一个内核,并支持浮点卷积。但是它不支持interpolate和softmax。
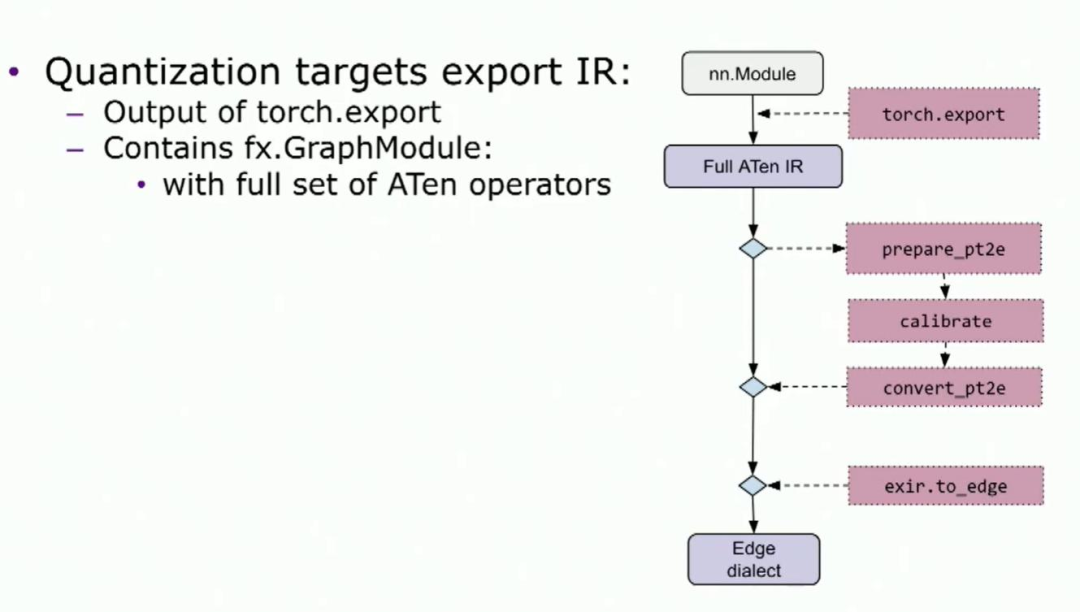
所以第一个入口点将是量化入口点。量化入口点目标是导出IR,即torch.export后的IR。用户的操作步骤是,他们将调用prepare、calibrate和convert。然后从最后一个API,他们可以得到一个量化模型。等效train的API也存在。对于合作伙伴,我们需要实现的是量化器。
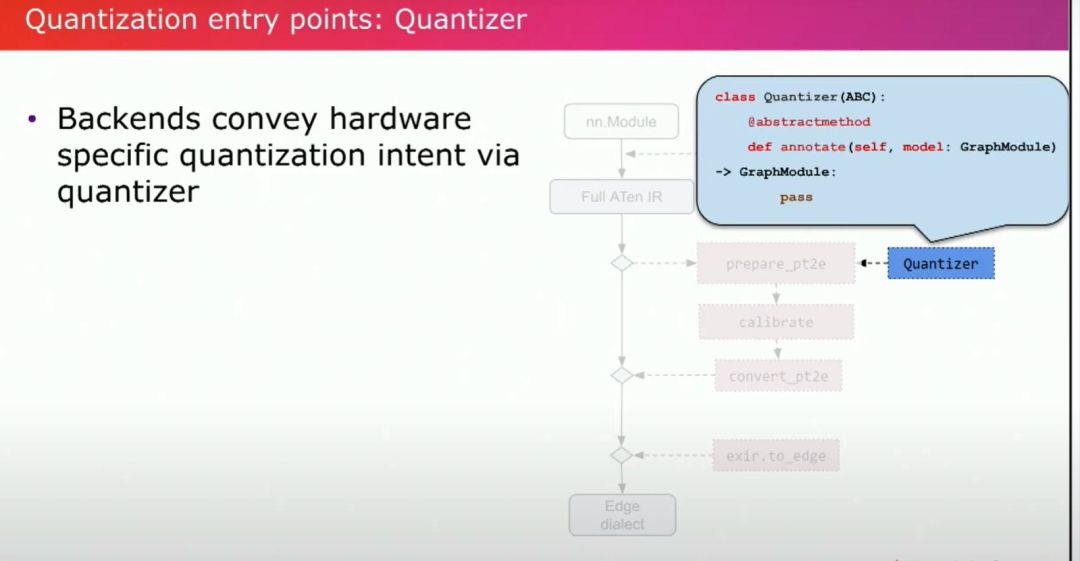
我们在这里需要实现的核心功能是annotate。通过注释和记录,它使后端可以传达他们希望拥有的计算类型。例如,如果我们想要有8位量化权重或4位量化权重,这个量化器将被送到prepare。然后prepare也是用户将调用的第一个量化API。
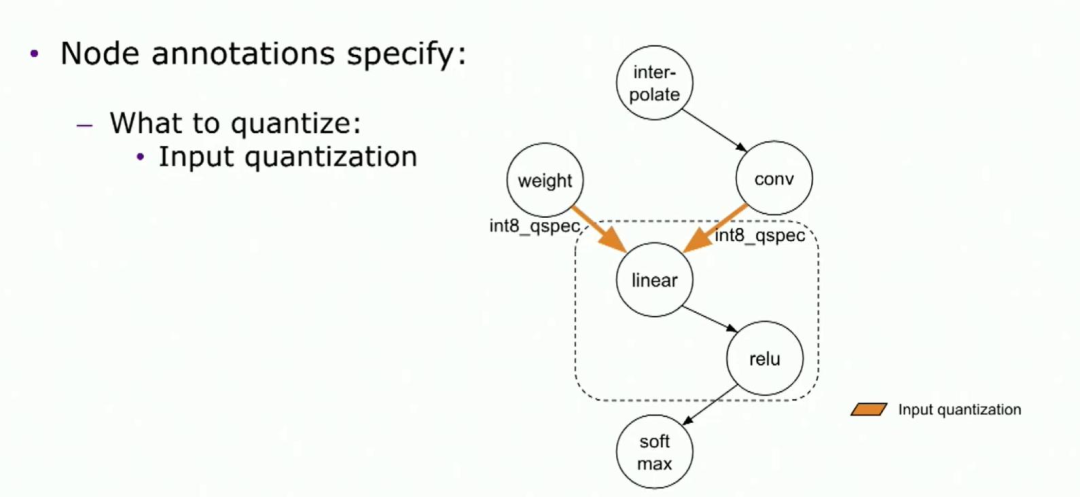
让我们回到例子中。请记住,量化linear ReLU是由后端支持的一种内核。因此,在这种情况下,我们需要将linear 和ReLU一起进行量化。第一,我们将annotate输入。在这个例子中,权重和激活都将被量化。然后我们将annotate输出。从图表中,annotate输入是指向linear的边,annotate输出是relu的输出边。通过这种方式,我们可以将linear和ReLU作为整体量化。量化规范是我们用来描述我们希望如何量化节点的类。它包括例如数据类型、对称与非对称、通道轴等。是的,它是一种丰富的语言,允许后端传达他们如何希望量化节点的方式。
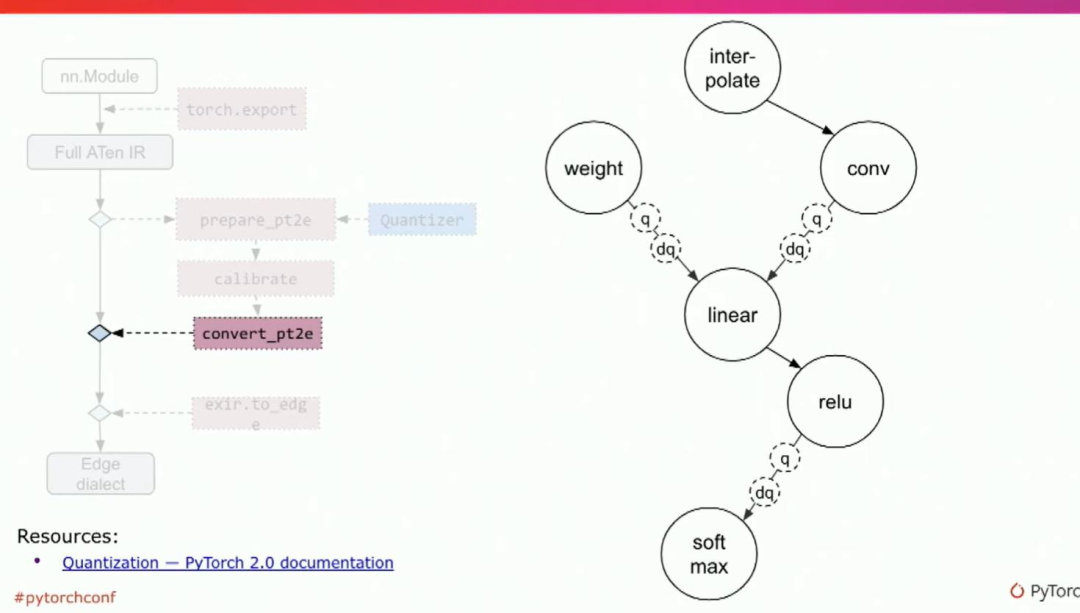
在准备完成后,用户调用的最后一个API是获得量化模型的API。从图表中可以看出,我们之前annotate的内容现在都变成了q和dq点。quant和dquant节点包含量化参数,如缩放因子和零点等。详细的文档https://pytorch.org/docs/2.0/quantization.html?highlight=quantization。
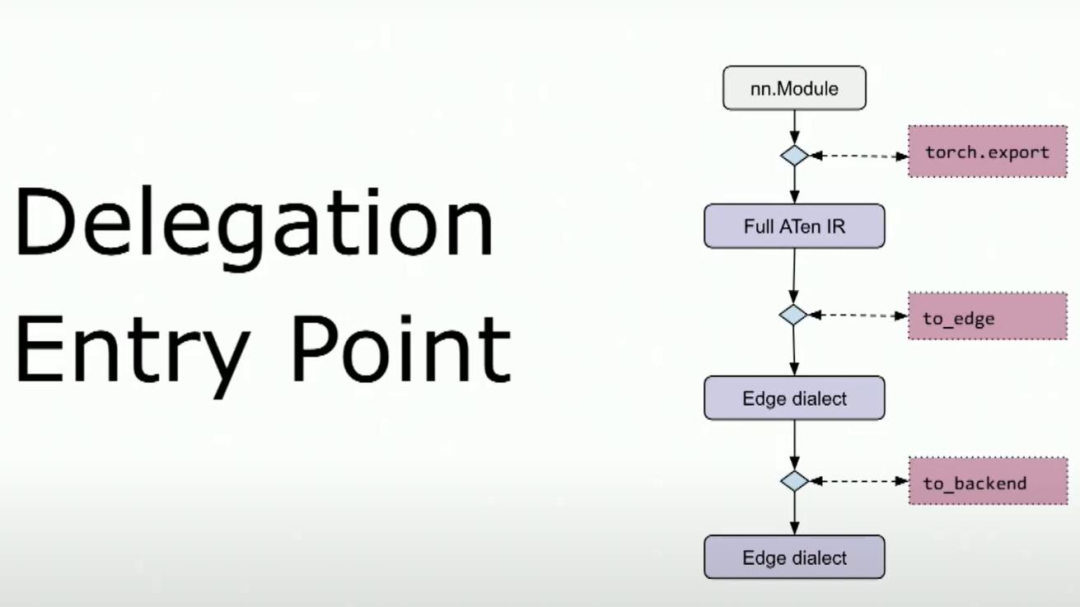
这是合作伙伴的第二个入口点,后端委托。这发生在to-edge上,针对on-edge方言。在深入讨论委派入口点之前,让我们退一步。什么是后端委派(delegation)?后端委派是执行PyTorch程序的框架,位于标准PyTorch运行时之外。每个后端都有自己的世界。它有自己的优化、编译器和序列化方式。但我们要确保标准运行时的干净和精简。这就是为什么我们有了后端委派。
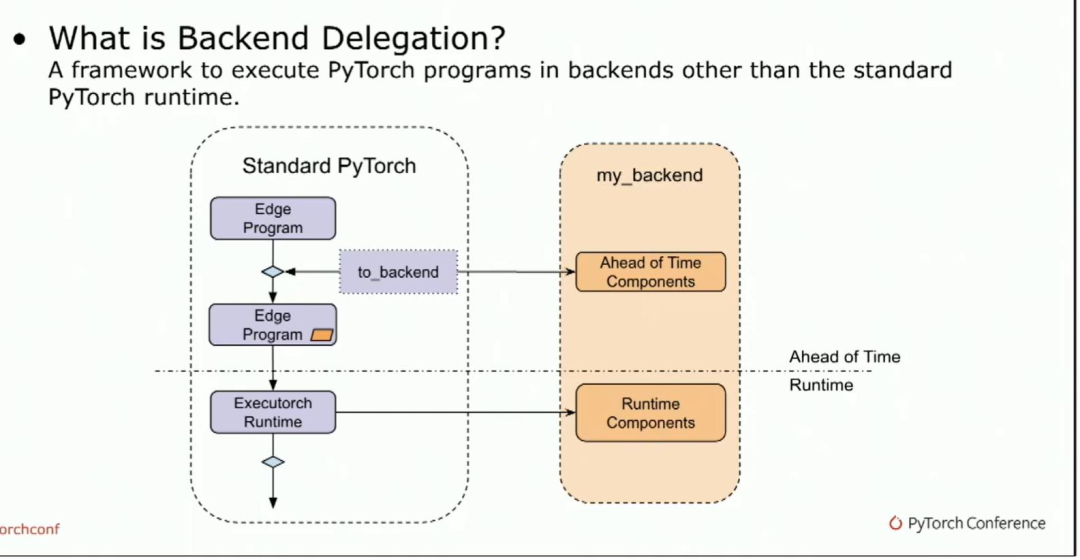
从高层来说,它的工作方式是用户调用两个后端API,这将调用后端提供的预先组件。它将将一个委派的payload嵌入到.pte文件中,在执行器运行时,该委派的负载将被发送到后端以调用运行时组件。我们什么时候需要委派呢?通常,如果我们想在特定硬件上启用某些功能,在特定的后端上使其更高效率。后端可以是硬件或软件堆栈。让我们从AOT部分开始。另外,我们再回到这个例子。
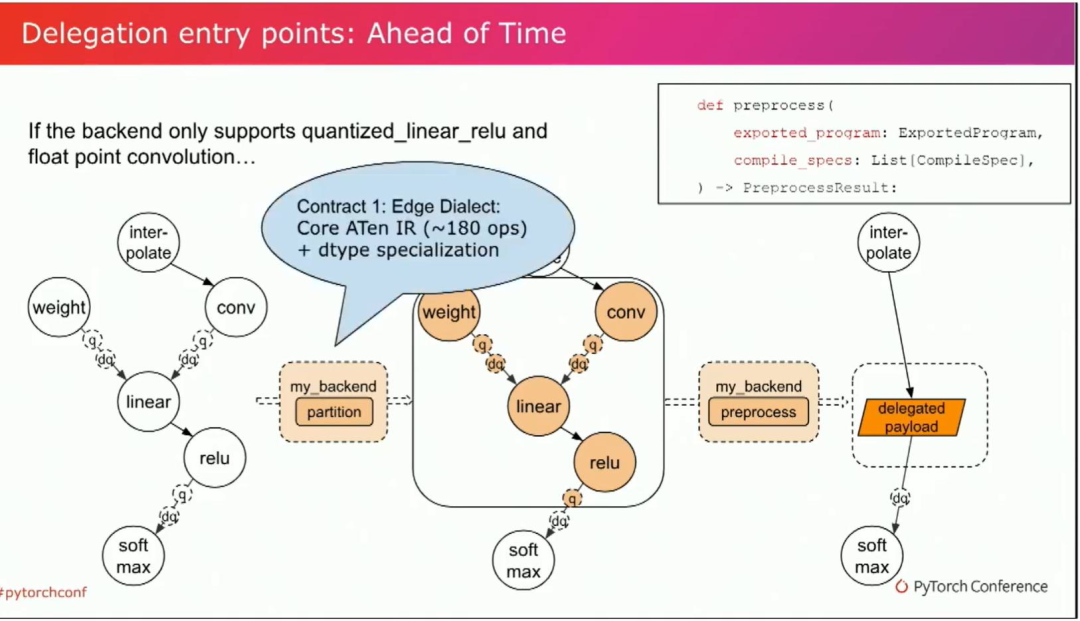
在获得量化模型之后,后端支持量化linear relu作为一个kernel,也支持浮点数卷积。后端将提供一个partition函数。它的作用是标记我们希望再后端运行的节点。然后,这些标记节点将被发送到后端预处理函数并编译为委托载荷。这个委托payload将作为ExecuTorch pte file的一部分嵌入其中,而且这个委托payload便于把子图关联回原始模型,本机sdk也给每个annotate提供了足够的信息,以便我们可以把他链接回python代码。
这是我们的委托入口点,目标IR是edge dialect,它是core aten IR。它有大约180个操作符和类型。edge dialect非常易于使用。它使得一些无法在操作符集中进行lower的情况成为为可能。
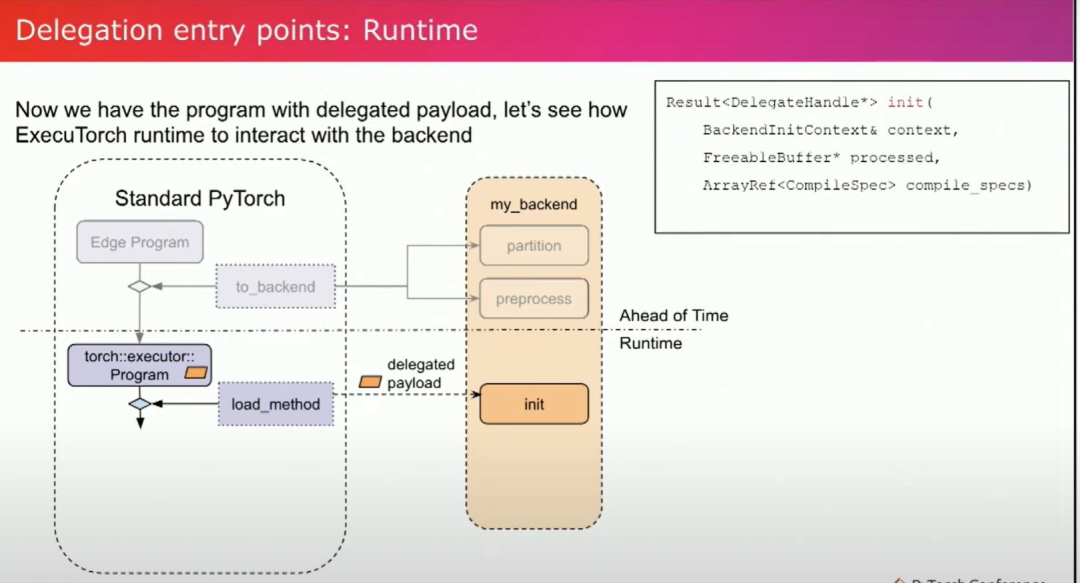
在提前完成并获得一个委托负载的ExecuTorch pte file之后,让我们来看一下运行时部分的内容。在runtime时,委托负载将被发送到后端的初始化函数中。这个加载部分只会发生一次。初始化是为了进一步初始化委托负载,通常用于需要在运行时获得的信息的部分。在初始化函数中,我们将接收委托负载,然后返回一个初始化的句柄。这个句柄将在执行过程中发送给后端,后端可以进行计算。现在我们完成了执行过程。
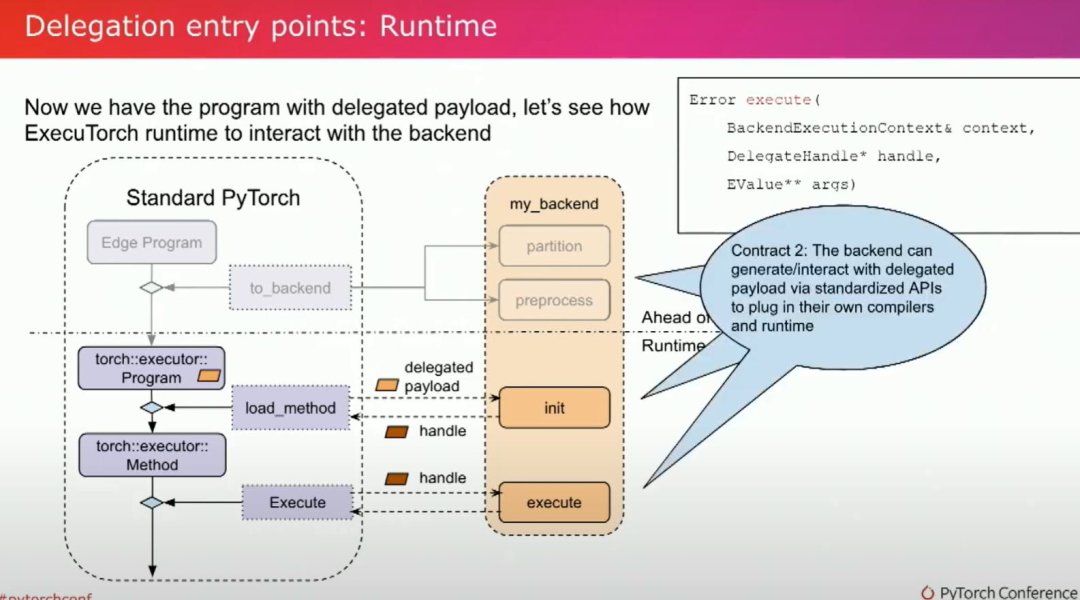
让我们来看一下第二个contract。后端将使用一套标准化的API生成并与委托负载进行交互,以插入后端自己的编译器和运行时。
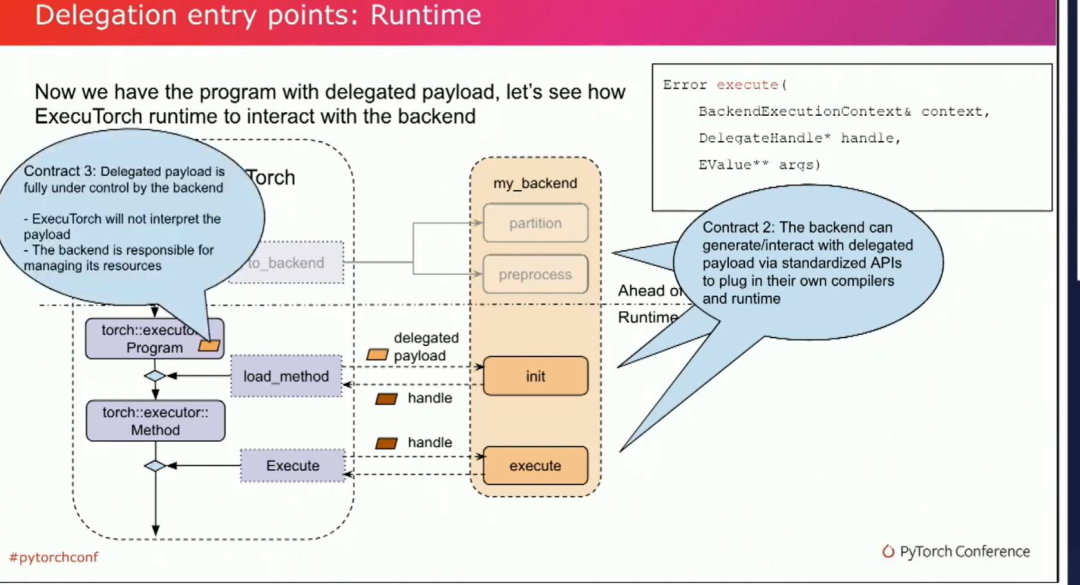
第三个contract中,委托负载完全由后端控制。Exitwatch不会对其进行解释,同时后端也负责管理其资源。至此,我们介绍完了一整套标准化API。
我们是否遗漏了什么?现在,子图已经被压缩到了一个不透明的东西。如果发生了什么问题怎么办?如果它失败了怎么办?如果它运行得非常慢怎么办?
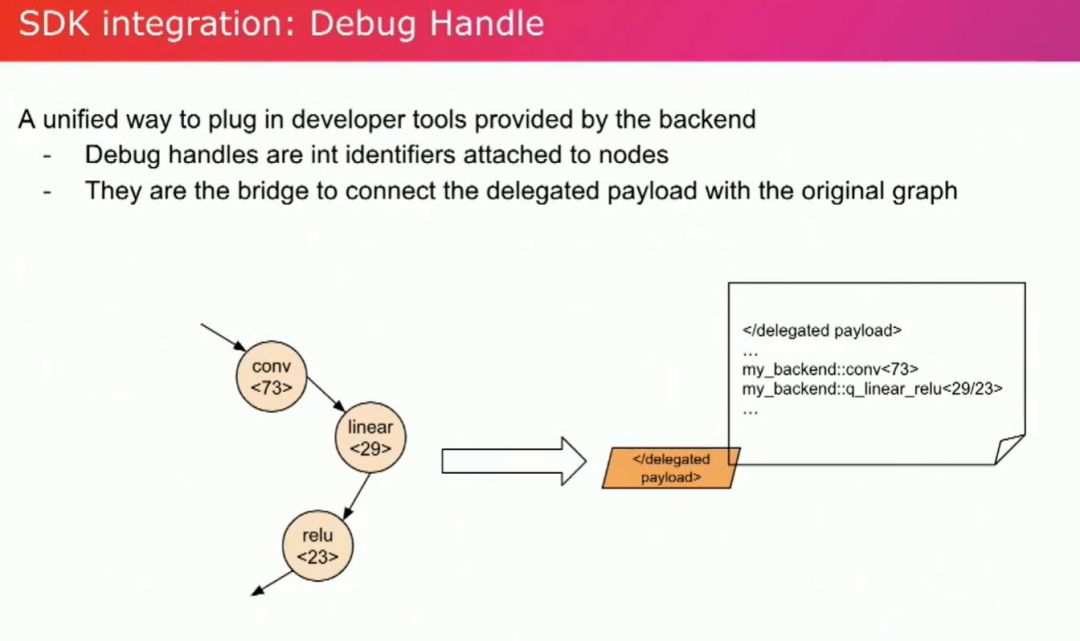
在这里,SDK集成是我们所需要的。后端通常会提供自己的开发工具,而我们提供了一种统一的方式来接入这些开发工具。debug handler就是桥梁。通过把子图编译成最后单个的二进制文件,我们丢失了 graph信息,debug handler可以帮我们把编译后的委托 payload 回到 python 和graph。
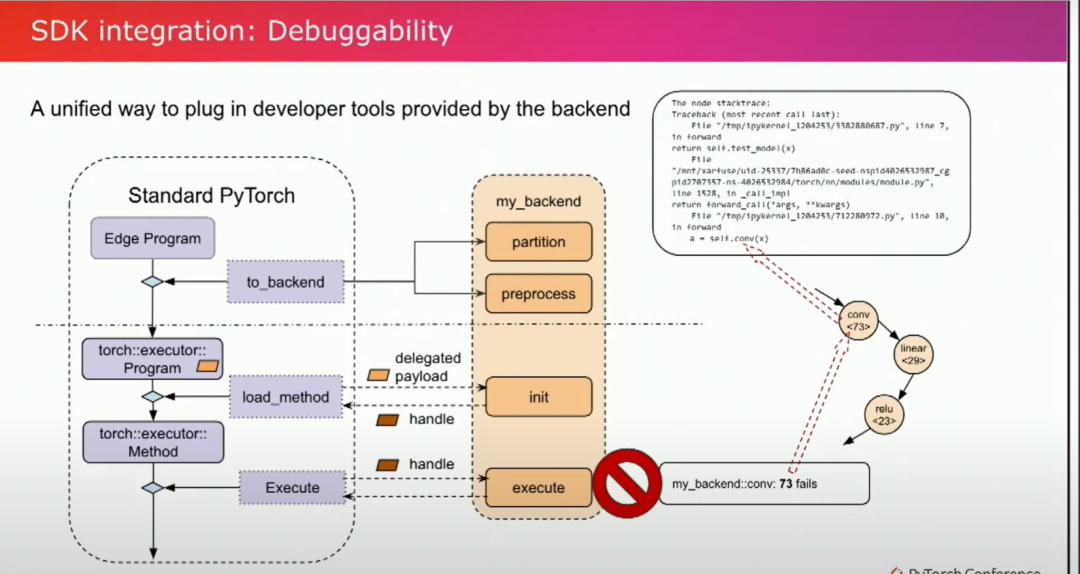
举个例子,例如,如果执行过程中出现了错误,比如在这个graph中......卷积在这里失败了。调试句柄 73 出现了问题。通过这个调试句柄......我们可以找出问题所在。在图中非常准确。它会指向具体的 Python 代码行。通过利用调试句柄,我们还可以在委托负载内进行性能分析。
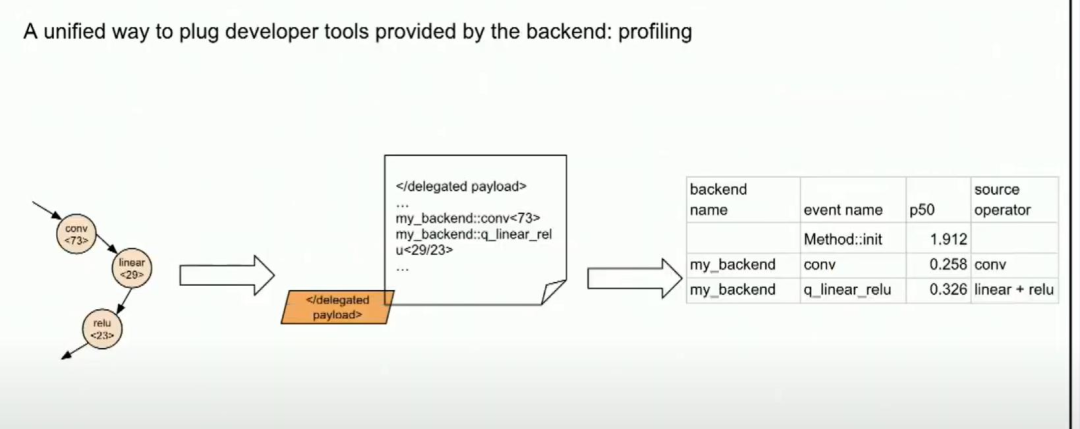
如果后端支持性能分析,我们可以提供。如果它提供了性能分析器开发工具,通过利用调试句柄,我们可以在委托负载中启用更详细的性能分析。
我们在过去的几年中与苹果、Arm和高通等行业领导者合作,具体请请访问ExecuTorch网站上的教程和演示,谢谢。