
漫谈C变量——关于对齐,这一篇就够了
来源:裸机思维
ID:bare-metal
整理:李肖遥
第一弹
谈起变量的访问(Access)就不得不谈到对齐(Alignment)的概念;谈论对齐,离开具体的计算机架构又会显得缺乏支撑,如同谈论空中楼阁一般。今天我们就以笔者熟悉的Cortex-M架构为蓝本,聊一聊变量访问的对齐问题。
1. What ?
在展开后续讨论之前,我们先来记住一个重要的结论,它是后续所有内容的立论之本:
编译器倾向于根据变量的大小(size)将其放置在与其大小对齐的偶数地址上
怎么理解这句话呢?举个例子,如果我们没有给出特别的指示,编译器会倾向于:
将uint32_t(4个字节)对齐到4字节地址上,0x0、0x4、0x8、0xC...,也就是我们常说的对齐到字(Word Aligned);
将uint16_t(2个字节)对齐到2字节地址上,0x0、0x2、0x4...也就是我们常说的对齐到半字(Half-word Aligned);
将uint64_t(8个字节)对齐到8个字节上,0x0、0x8... 也就是我们常说的对齐到双字(Double Word Aligned);
ARM的栈帧(Stack Frame)在Cortex-M3刚推出的时候要求“最好”对齐到双字,后来的Cortex-M4、Cortex-M0/M0+以及Cortex-M7干脆要求“一定要”对齐到双字了。
将uint8_t对齐到……好吧,byte没啥好对齐的,它已经是C语言变量的最小单位了——你可以认为对齐到字节(Byte Aligned)也就是对齐到任意地址。(爱抬杠的兄弟,不要跟我扯位域,那都是要靠编译器生成“读改写”操作来实现的)
2. Why ?
那么为什么编译器要做这么看似多此一举的事情呢?因为定义Cortex-M的硬件架构把处理器(Processor)对总线的访问(也就是对Memory的访问)分为两种:对齐访问(Aligned Access)和非对齐访问(Unaligned Access)。
那么为啥处理器要根据变量的地址把访问活生生的拆成对齐和非对齐两类呢?说的太复杂也没什么卵用,你只要记住:相对仅支持对齐访问的情况,实现非对齐的访问,处理器的需要消耗更多的逻辑,对应到空间上就是需要更多的逻辑门,进而占用更大的面积,最后消耗更多的能量。
属于ARMv6-M架构的处理器只支持对齐访问,例如大家熟悉的M0,M0+以及大家不太熟悉的M1;
属于ARMv7-M架构的处理器不仅两种方式都支持,还为不(pi)同(shi'er)需(tai)求(duo)的客户贴(duo)心(yu)的提供了一个选项——你可以通过某个系统寄存器关闭对非对齐访问的支持。这类处理器有,Cortex-M3/M4/M7...
一方面,我们常说,物质基础决定上层建筑,为处理器服务的编译器自然是把处理器的脾气摸的清清楚楚;另一方面,为了让自己生成的代码体现最大限度的兼容性,即便是为Cortex-M3/M4这样支持非对齐操作的处理器服务,编译器也会默认按照仅支持对齐操作的情况来生成代码。
进一步来说,ARM Cortex-M 是一个Load/Store 架构(看到L/S的同学不要激动,这和打游戏的L/S大法半毛钱关系都没有),意思是说,处理器的所有算术逻辑运算都只能使用寄存器页中的内容(R0~R15),并不能直接作用于保存在外部存储器中的变量上——这些变量的内容必须通过Load/Store指令在存储器和寄存器之间进行搬运才行。这就是所谓的Load/Store架构——ALU只能操作寄存器页里面的内容;Load/Store指令在寄存器页和外部存储器之间交换数据——是不是非常简单优雅?
Cortex-M 处理器支持哪些Load/Store指令呢?(这里,指令的缩写和名称不用记忆,只需要知道支持针对哪些数据类型的Load/Store指令即可)
LDR, LoaD Word to Register 读取单个Word到指定寄存器的指令
STR, STore Wore to Memory From Register 将指定单个寄存器的值以Word的形式保存到存储器
LDRH / STRH 上述指令的Half-word版本
LDRB / STRB 上述指令的Byte版本
LDRD / STRD 上述指令的Double-word版本
LDM / STM 上述指令的加强版本——可以搬运多个数据!
简单的说,在Cortex-M环境下,所谓非对齐操作就是:
LDR / STR 的目标地址没有对齐到Word
LDRH / STRH 的目标地址没有对齐到Half-Word
LDRD / STRD 的目标地址没有对齐到Double-Word的操作[注1]
LDM / STM 的目标地址没有对齐到Word[注2]
注意:
Cortex-M 在开启对非对齐操作的支持时,仅支持 LDRD / STRD 所有非对齐操作中 “未对齐到Double-Word但是对齐到Word” 的非对齐操作 ——对于其它情形是不支持的——一旦发生,立即触发异常(Exception)。
前面我们说过,ARMv7-M架构下的处理器支持非对齐操作,但LDM / STM特别任性——“管你支不支持非对齐操作,老子只支持对齐操作”——后面有个陷阱,很多人都栽在它的手上,这里暂时不表。
3. Then ?
于是我们就看到了以下的情况:
已知在一个C文件中,我们定义了四个全局变量:
uint8_t a;
uint16_t b;
uint8_t c;
uint32_t d;
你觉得编译器最终生成的变量排布(Layout)会是什么样子?
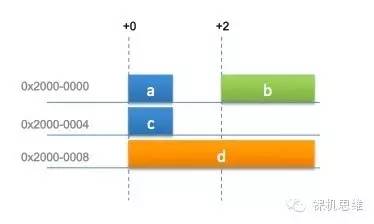
根据我们前面所学的知识,为了满足对齐访问的要求,很容易理解上述的排布,是不是觉得很浪费?等一等,编译器从来没有给你保证过,你声明变量的顺序就是它Layout变量的顺序哦,所以,实际上,真正的Layout是下面的形式:
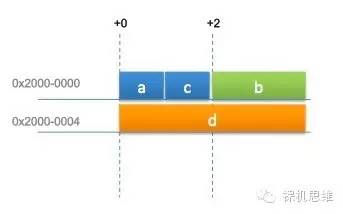
你看,通过改变变量的顺序,编译器成功的替我们节省了不少的存储器空间。
同样的情况对结构体来说就没有那么幸运了,假设我们有这样一个类似的结构体:
struct {
uint8_t a;
uint16_t b;
uint8_t c;
uint32_t d;
} Example;
由于结构体对Layout的顺序是有要求的,因此上述结构在内存中的Layout是第一种情况——浪费大量的空间;我们只能手工调节结构体成员的顺序才能得到第二种情况的结果。这里要小心哦。
性急的人已经开始考虑结构体的对齐问题了,这个我们下次再讲。结论是很清楚的:结构体无论选择何种对齐方式,都不会导致编译器产生错误的非对齐操作(Unaligned Access)
4. What If ?
“在ARMv6-M架构下以及关闭 非对齐操作支持 的ARMv7-M架构下使用非对齐操作会怎样?”
什么?太绕口,我们换种说法:
“在Cortex-M0/M0+或者关闭了 非对齐操作支持 的Cortex-M3/M4/M7 下使用非对齐操作会怎样?”
只有一个字——死!(哈哈,开个玩笑)真正的答案是:触发BusFault,其中由于ARMv6-M没有BusFault的概念,这类硬件错误最终都会归为HardFault;对于ARMv7-M在BusFault被人为屏蔽的情况下也会归为HardFault
——怎么样,看到这个名字是不是精神一震?HardFault !!!!!!!!!!!!!!!
你也许觉得很委屈,代码逻辑一点问题都没有,为什么C编译器还会产生会触发非对齐操作的机器码呢?
“你,对就是你!不要一脸无辜了,是你自己干的!”
第二弹
什么情况下会产生非对齐的操作呢?
在讨论这个问题之前,我们先要记住一个结论:
一般情况下,出于效率和兼容性的考虑,编译器会避免产生非对齐的操作。当且仅当编译器不知道(被蒙蔽)的情况下,才有可能产生隐性的非对齐的操作。
不知所云?让我们举一个简单的例子:
// 假设我们有一个函数,它要执行一个 32bit 的整数操作
extern void word_access ( uint32_t *pwTarget );
// 如果你这么用,显然是没有任何问题的
extern uint32_t wDemo;
...
word_access (&wDemo);
// 如果你这么做呢……
extern uint8_t chBuffer[16];
...
word_access ((uint32_t *)&chBuffer[1]);
不管你是否已经明白问题所在了,我们来简单分析下这段代码:
函数 word_access() 需要一个 uint32_t 型的指针作为形式参数
参考 上一篇文章 的内容,我们知道,对于 (uint32_t * ) 指针的操作,编译器会生成对齐到word的操作指令, 比如LDR和STR。我们可以下结论说,函数 word_access() 存在隐含要求,就是传入的指针必须是word对齐的。
最后一个例子中,数组chBuffer[] 很有可能被分配在一个对齐到 word 或者 halfword 的地址上,那么 &chBuffer[1] 几乎可以肯定是一个非对齐的地址
把一个非对齐的地址传给一个默认需要对齐的函数,结果不言自明。
可能有人会问:既然代码已经写的清清楚楚——“我们使用的是一个非对齐的地址”——为什么编译器仍然会假装不知道呢?其实编译器并非不知道,如果我们直接这么写:
word_access (&chBuffer[1]);
编译器立马就会报告Error:“指针的类型不符”。为了头疼医头,脚疼医脚的“屏蔽”这个Error,很多人会加入强制类型转换 (uint32_t *) 。实际上,从ANSI-C的标准来看,这个代码并没有任何问题,语法和逻辑上都讲得通。但是对齐是一个“潜规则”,你不遵守它,就会吃亏。这里,强制类型转换相当于直接给编译器蒙住了眼睛:“甭管之前看到了什么,反正现在这个指针,我说是对齐的就是对齐的!!!”
谁会写这么傻的代码呢?
也许你不会直接写出这么傻的代码,但是下面的“高级”用法的确更加稀松平常:
// 这是一个消息地图中常见的消息处理函数
void xxx_msg_handler( uint8_t *pchStream, uint16_t hwSize )
{
// offset 0x00: 1 BYTE Command / Message
uint8_t chCMD = pchStream[0];
// offset 0x01: 4 BYTE Serial Number of the frame
uint32_t wSN = *(uint32_t *)&pchStream[1];
...
}
对于通信数据帧解析来说,上述用法在常见不过了,怎么样踩地雷了吧?这只是举一个例子,只要用到指针强制类型转换的地方,都是在“蒙蔽”编译器,都有可能受到对齐潜规则的惩罚。
为什么我这么写了,代码执行的好好的?
因为 ARMv7-M 支持非对齐操作,具体请看 对齐(1)的内容,所以你幸免于难。但是,对如下的情况,你就绝无可能幸免:
如果 ARMv7-M 中关闭了对非对齐操作的支持(感觉是废话)
用的是 ARMv6-M,本身就不支持任何非对齐操作
如果编译器用的是STM、LDM,POP和PUSH这种完全不支持非对齐操作的指令
如果编译器用的是LDRD,STRD这类双字(DWORD)操作的指令,地址没有对齐到WORD或者DWORD
如果你操作的地址比 0xE0000000 大,简单说就是你在访问Processor的系统外设,比如NVIC,SysTick,SCB,MPU等等(不知道我在说啥也没关系,通常这类操作都是用CMSIS库实现的,不太可能出现非对齐操作)
非对齐操作有什么危害?
非对齐操作的危害主要有以下几点:
影响代码的可移植性。(比如:好好的工程,加入某个模块就立即异常……还没有源代码,只有.a,呵呵)
直接导致性能下降。尽管LDR/STR这样的指令支持非对齐操作,但其实我们的流水线是通过1)将这一非对齐的操作拆分成两个对齐的操作,最后2)再组装起来 实现的。
如果操作的目标地址上是一个“易失性”的寄存器,那么非对齐的操作被拆分了以后,会导致原本的一次操作变成了连续的两次。从而对操作的内容产生破坏性的后果。
注意:这里“易失性”意思就是,每次操作的时候:
要么操作本身会导致寄存器内容改变
比如,GPIO的Toggle寄存器,每次写操作都会导致对应的引脚翻转
比如,外设的中断状态寄存器,读取状态寄存器的操作本身就会清除标志
……
要么每次读取的内容都会不同
比如, Timer计数器,每次读取的时候计数器的内容都不同
比如,ADC的采样结果寄存器,读取顺序不同,很可能每次读取时候的值都会变化
……
如果操作的目标地址由多个Processor共享,甚至是与DMA共享,那么非对齐操作导致的连续两次操作,其原子性是没有保证的——其它Processor(总线Master)很有可能在你的两次操作中间插入进来——破坏了数据内容的完整性。这个很难调试,很难发现的哦!
是不是越听腿越哆嗦?啥?不哆嗦?莫装13,反正以后坑的是自己。珍爱生命,远离非对齐操作。
针对本文的例子,如何避免非对齐操作?
1、对第一个例子来说,要么避免给函数提供非对齐的地址,要么直接告诉编译器对应的函数处理的地址可能是非对齐的,直接修改函数原形即可:
// 假设我们有一个函数,它要执行一个 可能非对齐的 32bit 的整数操作
extern void word_access ( uint32_t __packed *pwTarget );
2、对第二个例子来说,由于数据帧的格式已经确定,因此,我们需要直接告诉编译器对目标数据的访问是非对齐的,对应的代码如下:
// 这是一个消息地图中常见的消息处理函数
void xxx_msg_handler( uint8_t *pchStream, uint16_t hwSize )
{
// offset 0x00: 1 BYTE Command / Message
uint8_t chCMD = pchStream[0];
// offset 0x01: 4 BYTE Serial Number of the frame
uint32_t wSN = *(uint32_t __packed*)&pchStream[1];
...
}
第三弹
前面的两篇文章,我们分别介绍了“为什么变量要对齐到它的尺寸大小”,“编译器会怎么处理内存的对齐问题”以及“非对齐是如何产生的和非对齐的后果”,感觉自己错过了重要内容的朋友可以发送关键字“对齐”来复习一下。下面我们来介绍几个关于对齐相关的问题:
1. 结构体的对齐
在ARM Compiler里面,结构体内的成员并不是简单的对齐到字(Word)或者半字(Half Word),更别提字节了(Byte),结构体的对齐使用以下规则:
整个结构体,根据结构体内最大的那个元素来对齐。比如,整个结构体内部最大的元素是WORD,那么整个结构体就默认对齐到4字节。
结构体内部,成员变量的排列顺序严格按照定义的顺序进行
结构体内部,成员变量自动对齐到自己的大小——这就会导致空隙的产生。
比如:
struct {
uint8_t a;
uint16_t b;
uint8_t c;
uint32_t d;
} Example;
结构体内部,成员变量可以单独指定对齐方式为byte,例如
struct {
uint8_t a;
uint16_t b __attribute__ ((packed));
uint8_t c;
uint32_t d;
} Example;
效果就会变成:
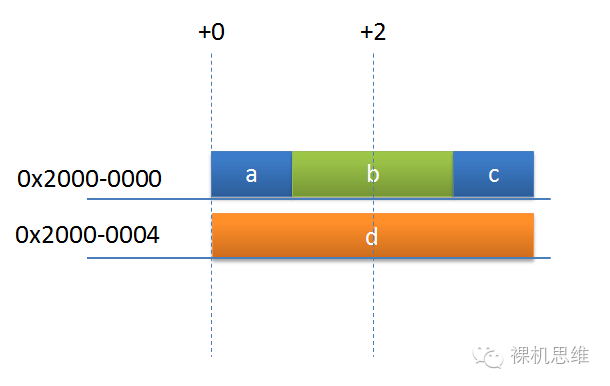
2. Cortex-M 中断向量表的对齐
Cortex-M中断向量表保存的都是32位的地址,每一个地址指向一个中断处理程序,因此中断向量表的大小必然是4的整倍数。理论上,你有n个中断,就因该有(n+1)*4 个字节大小的中断向量表。然而事情并非这么简单。为了硬件实现的方便:
中断向量表的大小必须是2^n (6
中断向量表的地址必须要对齐到它的大小,比如512Byte大小的中断向量表,其首地址必须要对齐到 0x0200(是0x200的整数倍)
为什么会存在这样的限制呢,原因很简单,假设向量号为x的中断被触发了,Cortex-M内核就会用这个x作为下标去访问这个uint32_t的数组,那么这个中断向量具体在内存里面的地址如何计算的呢?
我们认为是这样的:
中断向量地址 = 向量表基地址 + (x * 4)
然而,我们天真了,为了省事,这里的“+”运算被替换成了简单的"或"运算,也就是说,实际的硬件实现是这样的:
中断向量地址 = 向量表基地址 OR (x *4)
这意味着什么呢?加法运算是会进位的!或运算不会。举例来说:
0x01 OR 0x01 = 0x01
而
0x01 + 0x01 = 0x02
当硬件认为系统中向量表应该是512个字节大小时,如果向量表的基地址(通过SCB->VTOR寄存器设置)对齐到了0x0200,那么或运算的结果就与加法是等效的——原因很简单,(x * 4) 的部分不会超过0x0200,因而与加法等效。反之就有问题了。
又由于系统强制要求中断向量表必须最少对齐到128个字节,那么对一个512字节大小的向量表来说,如果仅对齐到128个字节会发生什么呢?——如果前31个中断(包括系统自己的异常)触发了,系统可以正常处理,从第32个中断开始,任何一个触发,系统一定会出错——中断向量的所在的位置算错啦!(注意不是中断处理程序的地址算错了,是保存中断处理程序地址的那个向量所在的内存地址被算错了)
3. Cortex-M MPU 受保护内存区块的对齐
MPU也许你听说过,但你多半没有用过,因为“太!难!用!拉!”,为了硬件实现的方便,MPU每一个Region的设置被加入了一个人为的限制:
Region的大小必须是 2^n (4
Region的基地址必须对齐到它的大小
又来!是的,就是这么坑,所以如果你想用MPU保护一个任意位置任意大小的Memory,比如stack,不好意思,你要用很多个Region一起来拼接……具体怎么拼,说起来都麻烦,何况用……算了不说了。
好消息是,最新的ARMv8-M终于改进了这个反人类的设计,允许用户通过起始地址+终止地址的方法设定任意大小任意位置的Region(当然Region大小必须是32的倍数,这个地址也必须是32的倍数)。可以好好松口气了。
如果你喜欢我的思维,欢迎订阅 裸机思维
嵌入式编程专辑 Linux 学习专辑 C/C++编程专辑 关注微信公众号『技术让梦想更伟大』,后台回复“m”查看更多内容,回复“加群”加入技术交流群。 长按前往图中包含的公众号关注