
使用 Loki 收集 nginx 日志
之前日志服务用的较多的一般是ELK,EFK,graylog等,但这些日志由java编写,运行需要jdk,而且配置上面,还是有点复杂,比如需要对日志需要写grok将复杂的日志进行匹配,好在后面出了可以根据分隔符的方式进行日志的提取,也就是dissect插件,可以根据分隔符进行分割。
ELK在日志方面给我的感觉是大而全,查询匹配是杠杠的,Kibana图表非常丰富。但如果面对大量的数据,需要查询,在不堆机器的情况下,还是会比较疲软,查询比较慢,之前公司每当突发流量的时候,由于日志写入比较大,队列都在kafka,es消费慢,导致无法实时出数据。
Loki 受到了 prometheus启 发,对日志进行打标签的方式而非全文索引的方,而且也可以跟kubernetes集成。
Like Prometheus, but for logs!
1安装Loki(使用Local方式)
安装和运行
https://github.com/grafana/loki/releases/
找到要安装的版本,我采用的是v2.1.0
下载Loki和Promtail, (Loki为日志的引擎,通过Promtail来发送日志到Loki)
在本机找一个目录存放这两个2进制文件
下载两者的配置文件
wget https://raw.githubusercontent.com/grafana/loki/master/cmd/loki/loki-local-config.yaml
wget https://raw.githubusercontent.com/grafana/loki/master/cmd/promtail/promtail-local-config.yaml使用如下命令启动Loki
./loki-linux-amd64 -config.file=loki-local-config.yamlroot@test:~$cd /usr/local/loki/
root@test:/usr/local/loki$ls
loki-linux-amd64 loki-local-config.yaml promtail-linux-amd64 promtail-local-config.yaml
root@test:/usr/local/loki$./loki-linux-amd64 -config.file=loki-local-config.yaml
2尝试搜集nginx日志
所以首先对nginx默认的日志进行改造,让他以json的方式进行输出到目录,然后用Promtail对其进行读取。 读取使用LogQL的json方式去读取,这个LogQL内容填写在grafana中。
nginx的部分配置改造
虚拟server配置
server {
server_name loki.test.com; # 域名设置
listen 8888;
access_log /var/log/nginx/loki_access.log promtail_json;
location / {
return 200 "It's ok!";
}
}
promtail_json日志格式配置
log_format promtail_json '{"@timestamp":"$time_iso8601",'
'"@version":"Promtail json",'
'"server_addr":"$server_addr",'
'"remote_addr":"$remote_addr",'
'"host":"$host",'
'"uri":"$uri",'
'"body_bytes_sent":$body_bytes_sent,'
'"bytes_sent":$body_bytes_sent,'
'"request":"$request",'
'"request_length":$request_length,'
'"request_time":$request_time,'
'"status":"$status",'
'"http_referer":"$http_referer",'
'"http_user_agent":"$http_user_agent"'
'}';
访问127.0.0.1:8888,观察日志已经正常输出为json格式,请保证该json格式正确。
root@test:/etc/nginx/conf.d$tail -f /var/log/nginx/loki_access.log
{"@timestamp":"2021-03-06T01:54:42-05:00","@version":"Promtail json","server_addr":"127.0.0.1","remote_addr":"192.168.65.130","host":"127.0.0.1","uri":"/","body_bytes_sent":8,"bytes_sent":8,"request":"GET / HTTP/1.1","request_length":78,"request_time":0.000,"status":"200","http_referer":"-","http_user_agent":"curl/7.29.0"}
nginx日志改造完毕
Promtail配置文件修改
因为搜集日志是Promtail处理,所以自然而然是需要根据自己需求来配置Promtail的配置文件。
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/loki-positions.yaml # 记录pos点
sync_period: 5s # 5s一次将当前读取到的pos点同步至filename配置的文件内
clients:
- url: http://localhost:3100/loki/api/v1/push
scrape_configs:
- job_name: Loki
static_configs:
- labels: # 设定的部分标签
job: Loki-nginx
host: localhost
app: nginx
__path__: /var/log/nginx/loki_access.log # 待读取的nginx日志
LogQL json部分文档理解
json的提取分为两种方式,带参数和不带参数
不带参数的方式
使用 |json来提取日志的json内容,前提是json内容为有效json格式。嵌套的字段会用”_”将内外层的key进行拼接。 忽略数组。
看一下官网中不带参数方式的样例
{
"protocol": "HTTP/2.0",
"servers": ["129.0.1.1","10.2.1.3"],
"request": {
"time": "6.032",
"method": "GET",
"host": "foo.grafana.net",
"size": "55",
"headers": {
"Accept": "*/*",
"User-Agent": "curl/7.68.0"
}
},
"response": {
"status": 401,
"size": "228",
"latency_seconds": "6.031"
}
}
被json解后,得到如下:
"protocol" => "HTTP/2.0"
"request_time" => "6.032"
"request_method" => "GET"
"request_host" => "foo.grafana.net"
"request_size" => "55"
"response_status" => "401"
"response_size" => "228"
"response_size" => "228"
从输出能看到,原本request字段内容为嵌套,所以request里面的内容的key验证了如上第二点,使用”_”进行了拼接。同时servers由于是个数组,所以在解析后直接丢弃了servers这个key,验证了第三点。
带参数的方式
带参数的方式,json只会根据参数来解开需要的部分(当单条json数据比较大的时候应该能省很多资源)。 使用| json label=”expression”, another=”expression”的方式来编写该方法。可以存在多个参数
看一下官网中带参数方式的样例
使用| json first_server=”servers[0]”, ua=”request.headers["User-Agent"]进行提取
{
"protocol": "HTTP/2.0",
"servers": ["129.0.1.1","10.2.1.3"],
"request": {
"time": "6.032",
"method": "GET",
"host": "foo.grafana.net",
"size": "55",
"headers": {
"Accept": "*/*",
"User-Agent": "curl/7.68.0"
}
},
"response": {
"status": 401,
"size": "228",
"latency_seconds": "6.031"
}
}
输出结果为:
"first_server" => "129.0.1.1"
"ua" => "curl/7.68.0"
first_server和ua都为原先参数中指定的key
如果要提取整个对象,可以使用| json server_list=”servers”, headers=”request.headers
这样就能得到如下输出:
"server_list" => `["129.0.1.1","10.2.1.3"]`
"headers" => `{"Accept": "*/*", "User-Agent": "curl/7.68.0"}`
尝试写一条LogQL表达式
一条完整的LogQL表达式由两部分构成:
a log stream selector,可以理解为,通过设定的label去匹配要抓取哪些日志。 a log pipeline,可以理解为表达式。比如json的提取。
比如如下表达式
{container="query-frontend",namespace="tempo-dev"} |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500
`{container=”query-frontend”,namespace=”tempo-dev”}`` 部分为log stream selector,后面部分为log pipeline。
编写一个简单的nginx日志需求
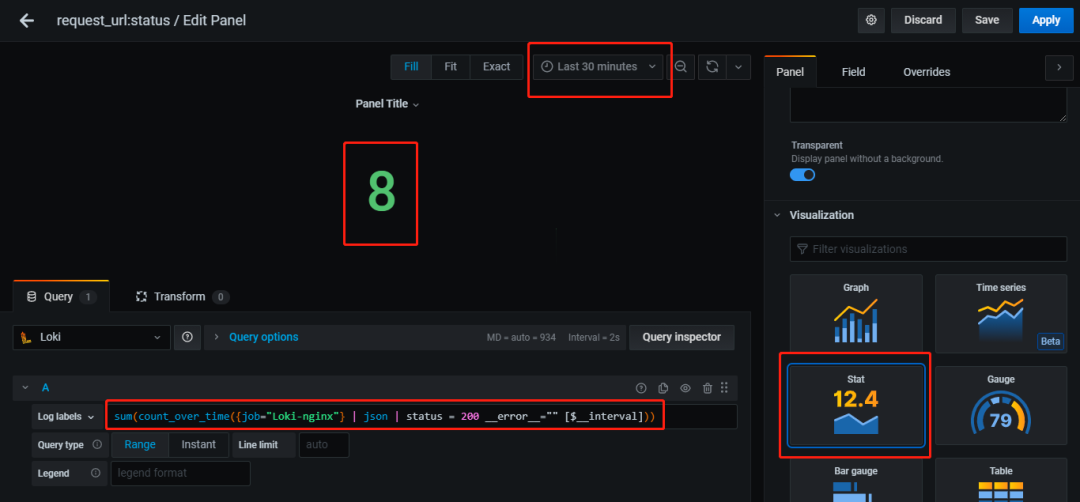
Loki-nginx日志中状态码为200的条数。 根据当前选定时间范围,自动调整。
思考:
如何指定Loki-nginx,可以使用log stream selector的表达式来选定。 nginx日志已经转变为了json,所以可以用 |json来提取。如何获取status字段的信息? |json后面直接跟随|status即可,即 |json|status。如何根据当前选定的时间范围?使用内置变量 [$\_\_interval]。条数该得用什么方法获得?LogQL有内置函数 count_over_time配合sum,这边需要注意的是count_over_time是根据指定时间范围返回日志条目的具体内容,所以还需要配合sum获得时间段内的总数。
编写:
首先选定Loki-nginx的日志, {job="Loki-nginx"}。使用count_over_time函数配合 [$\_\_interval]来获取总共的条数。count_over_time({job="Loki-nginx"}[$\_\_interval])过滤status字段,让其等于200,表达式 count_over_time({job="Loki-nginx"} | json | status = 200 [$\_\_interval]),此时会报错,因为status为字符串,可以添加__error__=””让其忽略转换出现的异常。得到count_over_time({job="Loki-nginx"} | json | status = 200 \_\_error\_\_="" [$\_\_interval])此时在grafana上显示为多条数据,配合sum得到单独一个数值。 最终的表达式为: sum(count_over_time({job="Loki-nginx"} | json | status = 200 __error__="" [$__interval]))
原文链接:https://kirakirazone.com/2021/03/06/Loki%E6%97%A5%E5%BF%97%E6%9C%8D%E5%8A%A101/