
视频隐身衣:物体移除、去水印、后期处理毫无痕迹
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


视频“擦除”,这个AI就够了





光流边缘引导修复算法

光流边缘(Flow edges):补全分段光滑流。(图1b) 非局部流(Non-local flow):连接不能通过传递流(transitive flow)到达的区域。(图1C) 无缝融合(Seamless blending):通过在梯度域中执行融合操作避免结果中的可见接缝(图1d)。 内存效率(Memory efficiency),处理4K分辨率的视频,其他方法由于GPU内存需求过大而无法实现。
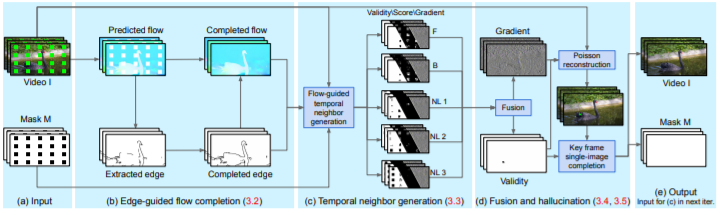


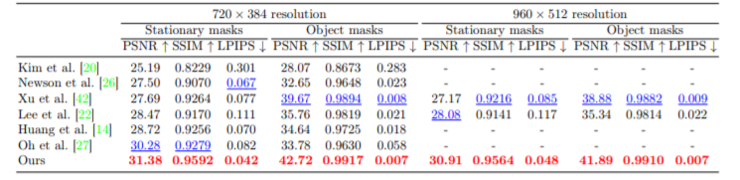
与先进算法相比,算法最佳


关于作者

评论