
万字长文Python面试题,找工作就靠这了
点废话不多说,找工作,就靠这些啦!
基础篇(一)
1. 为什么学习 Python
Python 语言简单易懂,上手容易,随着 AI 风潮,越来越火。
2. 解释型和编译型语言的区别
编译型语言:把做好的源程序全部编译成二进制的可运行程序。然后,可直接运行这个程序。如:C,C++
解释型语言:把做好的源程序翻译一句,然后执行一句,直至结束!如:Python,
(Java 有些特殊,java程序也需要编译,但是没有直接编译称为机器语言,而是编译称为字节码,然后用解释方式执行字节码。)
3. 简述下 Python 中的字符串、列表、元组和字典
字符串(str):字符串是用引号括起来的任意文本,是编程语言中最常用的数据类型。
列表(list):列表是有序的集合,可以向其中添加或删除元素。
元组(tuple):元组也是有序集合,但是是无法修改的。即元组是不可变的。
字典(dict):字典是无序的集合,是由 key-value 组成的。
集合(set):是一组 key 的集合,每个元素都是唯一,不重复且无序的。
4. 简述上述数据类型的常用方法
字符串
切片
mystr='luobodazahui'
mystr[1:3]
output
'uo'
format
mystr2 = "welcome to luobodazahui, dear {name}"
mystr2.format(name="baby")
output
'welcome to luobodazahui, dear baby'
join
可以用来连接字符串,将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串。
mylist = ['luo', 'bo', 'da', 'za', 'hui']
mystr3 = '-'.join(mylist)
print(mystr3)
outout
'luo-bo-da-za-hui'
replace
String.replace(old,new,count) 将字符串中的 old 字符替换为 New 字符,count 为替换的个数
mystr4 = 'luobodazahui-haha'
print(mystr4.replace('haha', 'good'))
output
luobodazahui-good
split
切割字符串,得到一个列表。
mystr5 = 'luobo,dazahui good'
# 以空格分割
print(mystr5.split())
# 以h分割
print(mystr5.split('h'))
# 以逗号分割
print(mystr5.split(','))
output
['luobo,dazahui', 'good']
['luobo,daza', 'ui good']
['luobo', 'dazahui good']
列表
切片
同字符串
append 和 extend
向列表中国添加元素
mylist1 = [1, 2]
mylist2 = [3, 4]
mylist3 = [1, 2]
mylist1.append(mylist2)
print(mylist1)
mylist3.extend(mylist2)
print(mylist3)
outout
[1, 2, [3, 4]]
[1, 2, 3, 4]
删除元素
del:根据下标进行删除
pop:删除最后一个元素
remove:根据元素的值进行删除
mylist4 = ['a', 'b', 'c', 'd']
del mylist4[0]
print(mylist4)
mylist4.pop()
print(mylist4)
mylist4.remove('c')
print(mylist4)
output
['b', 'c', 'd']
['b', 'c']
['b']
元素排序
sort:是将list按特定顺序重新排列,默认为由小到大,参数 reverse=True 可改为倒序,由大到小。
reverse:是将list逆置。
mylist5 = [1, 5, 2, 3, 4]
mylist5.sort()
print(mylist5)
mylist5.reverse()
print(mylist5)
output
[1, 2, 3, 4, 5]
[5, 4, 3, 2, 1]
字典
清空字典
dict.clear()
dict1 = {'key1':1, 'key2':2}
dict1.clear()
print(dict1)
output
{}
指定删除
使用 pop 方法来指定删除字典中的某一项
dict1 = {'key1':1, 'key2':2}
d1 = dict1.pop('key1')
print(d1)
print(dict1)
output
1
{'key2': 2}
遍历字典
dict2 = {'key1':1, 'key2':2}
mykey = [key for key in dict2]
print(mykey)
myvalue = [value for value in dict2.values()]
print(myvalue)
key_value = [(k, v) for k, v in dict2.items() ]
print(key_value)
output
['key1', 'key2']
[1, 2]
[('key1', 1), ('key2', 2)]
fromkeys
用于创建一个新字典,以序列中元素做字典的键,value 为字典所有键对应的初始值
keys = ['zhangfei', 'guanyu', 'liubei', 'zhaoyun']
dict.fromkeys(keys, 0)
output
{'zhangfei': 0, 'guanyu': 0, 'liubei': 0, 'zhaoyun': 0}
5. 简述 Python 中的字符串编码
计算机在最初的设计中,采用了8个比特(bit)作为一个字节(byte)的方式。一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。
最早,计算机只有 ASCII 编码,即只包含大小写英文字母、数字和一些符号,这些对于其他语言,如中文,日文显然是不够用的。后来又发明了Unicode,Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。UTF-8 是隶属于 Unicode 的可变长的编码方式。
在 Python 中,以 Unicode 方式编码的字符串,可以使用 encode() 方法来编码成指定的 bytes,也可以通过 decode() 方法来把 bytes 编码成字符串。
encode
"中文".encode('utf-8')
output
b'\xe4\xb8\xad\xe6\x96\x87'
decode
b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
output
'中文'
6. 一行代码实现数值交换
a = 1
b = 2
a, b = b, a
print(a, b)
output
2 1
7. is和==的区别
先来看个例子
c = d = [1,2]
e = [1,2]
print(c is d)
print(c == d)
print(c is e)
print(c == e)
output
True
True
False
True
== 是比较操作符,只是判断对象的值(value)是否一致,而 is 则判断的是对象之间的身份(内存地址)是否一致。对象的身份,可以通过 id() 方法来查看。
id(c)
id(d)
id(e)
output
188748080
288748080
388558288
可以看出,只有 id 一致时,is 比较才会返回 True,而当 value 一致时,== 比较就会返回 True
8. Python 函数中的参数类型
位置参数,默认参数,可变参数,关键字参数
9. arg和*kwarg作用
允许我们在调用函数的时候传入多个实参
def test(*arg, **kwarg):
if arg:
print("arg:", arg)
if kwarg:
print("kearg:", kwarg)
test('ni', 'hao', key='world')
output
arg: ('ni', 'hao')
kearg: {'key': 'world'}
可以看出,
*arg会把位置参数转化为tuple
**kwarg会把关键字参数转化为dict
10. 一行代码实现1-100之和
sum(range(1, 101))
11. 获取当前时间
import time
import datetime
print(datetime.datetime.now())
print(time.strftime('%Y-%m-%d %H:%M:%S'))
output
12019-06-07 18:12:11.165330
22019-06-07 18:12:11
12. PEP8 规范
简单列举10条:
尽量以免单独使用小写字母'l',大写字母'O',以及大写字母'I'等容易混淆的字母。
函数命名使用全部小写的方式,可以使用下划线。
常量命名使用全部大写的方式,可以使用下划线。
使用 has 或 is 前缀命名布尔元素,如: is_connect = True; has_member = False
不要在行尾加分号, 也不要用分号将两条命令放在同一行。
不要使用反斜杠连接行。
顶级定义之间空2行, 方法定义之间空1行,顶级定义之间空两行。
如果一个类不继承自其它类, 就显式的从 object 继承。
内部使用的类、方法或变量前,需加前缀'_'表明此为内部使用的。
要用断言来实现静态类型检测。
13. Python 的深浅拷贝
浅拷贝
import copy
list1 = [1, 2, 3, [1, 2]]
list2 = copy.copy(list1)
list2.append('a')
list2[3].append('a')
print(list1, list2)
output
[1, 2, 3, [1, 2, 'a']] [1, 2, 3, [1, 2, 'a'], 'a']
能够看出,浅拷贝只成功”独立“拷贝了列表的外层,而列表的内层列表,还是共享的
深拷贝
import copy
list1 = [1, 2, 3, [1, 2]]
list3 = copy.deepcopy(list1)
list3.append('a')
list3[3].append('a')
print(list1, list3)
output
[1, 2, 3, [1, 2]] [1, 2, 3, [1, 2, 'a'], 'a']
深拷贝使得两个列表完全独立开来,每一个列表的操作,都不会影响到另一个。
14. 查看下面代码的输出
def num():
return [lambda x:i*x for i in range(4)]
print([m(1) for m in num()])
output
[3, 3, 3, 3]
通过运行结果,可以看出 i 的取值为3,很神奇
15. 可变类型与不可变类型
可变数据类型:list、dict、set
不可变数据类型:int/float、str、tuple
16. 打印九九乘法表
for i in range(1, 10):
for j in range(1, i+1):
print("%s*%s=%s " %(i, j, i*j), end="")
print()
output
11*1=1
22*1=2 2*2=4
33*1=3 3*2=6 3*3=9
44*1=4 4*2=8 4*3=12 4*4=16
55*1=5 5*2=10 5*3=15 5*4=20 5*5=25
66*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36
77*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49
88*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64
99*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
print 函数,默认是会换行的,其有一个默认参数 end,如果像例子中,我们把 end 参数显示的置为"",那么 print 函数执行完后,就不会换行了,这样就达到了九九乘法表的效果了。
17. filter、map、reduce 的作用
filter 函数用于过滤序列,它接收一个函数和一个序列,把函数作用在序列的每个元素上,然后根据返回值是True还是False决定保留还是丢弃该元素。
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
list(filter(lambda x: x%2 == 1, mylist))
output
[1, 3, 5, 7, 9]
保留奇数列表
map 函数传入一个函数和一个序列,并把函数作用到序列的每个元素上,返回一个可迭代对象
mylist = [1, 2, 3, 4, 5, 6, 7, 8, 9]
list(map(lambda x: x*2, mylist))
output
[2, 4, 6, 8, 10, 12, 14, 16, 18]
reduce 函数用于递归计算,同样需要传入一个函数和一个序列,并把函数和序列元素的计算结果与下一个元素进行计算。
from functools import reduce
reduce(lambda x, y: x+y, range(101))
output
15050
可以看出,上面的三个函数与匿名函数相结合使用,可以写出强大简洁的代码。
18. re 的 match 和 search 区别
match()函数只检测要匹配的字符是不是在 string 的开始位置匹配,search()会扫描整个 string 查找匹配
19. 面向对象中new__ 和__init 区别
new是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例对象,是个静态方法。
init是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值,通常用在初始化一个类实例的时候。是一个实例方法。
1、new至少要有一个参数 cls,代表当前类,此参数在实例化时由 Python 解释器自动识别。
2、new__必须要有返回值,返回实例化出来的实例,这点在自己实现_new_时要特别注意,可以 return 父类(通过 super(当前类名, cls))_new_出来的实例,或者直接是 object 的__new出来的实例。
3、init__有一个参数 self,就是这个_new_返回的实例,_init_在_new_的基础上可以完成一些其它初始化的动作,__init不需要返回值。
4、如果new__创建的是当前类的实例,会自动调用_init_函数,通过 return 语句里面调用的_new_函数的第一个参数是 cls 来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的_init_函数,也不会调用其他类的__init函数。
20. 三元运算规则
a, b = 1, 2
# 若果 a>b 成立 就输出 a-b 否则 a+b
h = a-b if a>b else a+b
output
13
21. 生成随机数
print(random.random())
print(random.randint(1, 100))
print(random.uniform(1,5))
output
10.03765019937131564
218
31.8458555362279228
22. zip 函数用法
zip() 函数将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
list1 = ['zhangfei', 'guanyu', 'liubei', 'zhaoyun']
list2 = [0, 3, 2, 4]
list(zip(list1, list2))
output
[('zhangfei', 0), ('guanyu', 3), ('liubei', 2), ('zhaoyun', 4)]
23. range 和 xrange 的区别
range([start,] stop[, step]),根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个序列。
而 xrange 生成一个生成器,可以很大的节约内存。
24. with 方法打开文件的作用
开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的 f.open 写法,我们需要 try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行 finally f.close() 关闭文件,with 方法帮我们实现了 finally 中 f.close。
25. 什么是正则的贪婪匹配
Python 中默认是贪婪匹配模式。
贪婪模式:正则表达式一般趋向于最大长度匹配。
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配。
26. 为什么不建议函数的默认参数传入可变对象
例如:
def test(L=[]):
L.append('test')
print(L)
output
test() # ['test']
test() # ['test', 'test']
默认参数是一个列表,是可变对象[],Python 在函数定义的时候,默认参数 L 的值就被计算出来了,是[],每次调用函数,如果 L 的值变了,那么下次调用时,默认参数的值就已经不再是[]了。
27. 字符串转列表
mystr = '1,2,3'
mystr.split(',')
output
['1', '2', '3']
28. 字符串转整数
mylist = ['1', '2', '3']
list(map(lambda x: int(x), mylist))
output
[1, 2, 3]
29. 删除列表中的重复值
mylist = [1, 2, 3, 4, 5, 5]
list(set(mylist))
30. 字符串单词统计
from collections import Counter
mystr = 'sdfsfsfsdfsd,were,hrhrgege.sdfwe!sfsdfs'
Counter(mystr)
output
Counter({'s': 9,
'd': 5,
'f': 7,
',': 2,
'w': 2,
'e': 5,
'r': 3,
'h': 2,
'g': 2,
'.': 1,
'!': 1})
31. 列表推导,求奇偶数
[x for x in range(10) if x%2 == 1]
output
[1, 3, 5, 7, 9]
32. 一行代码展开列表
list1 = [[1,2],[3,4],[5,6]]
[j for i in list1 for j in i]
output
[1, 2, 3, 4, 5, 6]
33. 实现二分法查找函数
二分查找算法也称折半查找,基本思想就是折半,对比大小后再折半查找,必须是有序序列才可以使用二分查找。
递归算法
def binary_search(data, item):
# 递归
n = len(data)
if n > 0:
mid = n // 2
if data[mid] == item:
return True
elif data[mid] > item:
return binary_search(data[:mid], item)
else:
return binary_search(data[mid+1:], item)
return False
list1 = [1,4,5,66,78,99,100,101,233,250,444,890]
binary_search(list1, 999)
非递归算法
def binary_search(data, item):
# 非递归
n = len(data)
first = 0
last = n - 1
while first <= last:
mid = (first + last)//2
if data[mid] == item:
return True
elif data[mid] > item:
last = mid - 1
else:
first = mid + 1
return False
list1 = [1,4,5,66,78,99,100,101,233,250,444,890]
binary_search(list1, 99)
34. 字典和 json 转换
字典转 json
import json
dict1 = {'zhangfei':1, "liubei":2, "guanyu": 4, "zhaoyun":3}
myjson = json.dumps(dict1)
myjson
output
'{"zhangfei": 1, "liubei": 2, "guanyu": 4, "zhaoyun": 3}'
json 转字典
mydict = json.loads(myjson)
mydict
output
{'zhangfei': 1, 'liubei': 2, 'guanyu': 4, 'zhaoyun': 3}
35. 列表推导式、字典推导式和生成器
import random
td_list=[i for i in range(10)]
print("列表推导式", td_list, type(td_list))
ge_list = (i for i in range(10))
print("生成器", ge_list)
dic = {k:random.randint(4, 9)for k in ["a", "b", "c", "d"]}
print("字典推导式",dic,type(dic))
output
列表推导式 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] <class 'list'>
生成器 <generator object <genexpr> at 0x0139F070>
字典推导式 {'a': 6, 'b': 5, 'c': 8, 'd': 9} <class 'dict'>
36. 简述 read、readline、readlines 的区别
read 读取整个文件
readline 读取下一行,使用生成器方法
readlines 读取整个文件到一个迭代器以供我们遍历
37. 打乱一个列表
list2 = [1, 2, 3, 4, 5, 6]
random.shuffle(list2)
print(list2)
output
[4, 6, 5, 1, 2, 3]
38. 反转字符串
str1 = 'luobodazahui'
str1[::-1]
output
'iuhazadoboul'
39. 单下划线和双下划线的作用
__foo__:一种约定,Python 内部的名字,用来区别其他用户自定义的命名,以防冲突,就是例如init__()和_del_()及__call()这些特殊方法。
_foo:一种约定,用来指定变量私有。不能用 from module import * 导入,其他方面和公有变量一样访问。
__foo:这个有真正的意义:解析器用classname__foo 来代替这个名字,以区别和其他类相同的命名,它无法直接像公有成员一样随便访问,通过对象名.类名__xxx 这样的方式可以访问。
40. 新式类和旧式类
a. 在 python 里凡是继承了 object 的类,都是新式类
b. Python3 里只有新式类
c. Python2 里面继承 object 的是新式类,没有写父类的是经典类
d. 经典类目前在 Python 里基本没有应用
41. Python 面向对象中的继承有什么特点
a. 同时支持单继承与多继承,当只有一个父类时为单继承,当存在多个父类时为多继承。
b. 子类会继承父类所有的属性和方法,子类也可以覆盖父类同名的变量和方法。
c. 在继承中基类的构造(__init__())方法不会被自动调用,它需要在其派生类的构造中专门调用。
d. 在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别于在类中调用普通函数时并不需要带上 self 参数。
42. super 函数的作用
super() 函数是用于调用父类(超类)的一个方法。
class A():
def funcA(self):
print("this is func A")
class B(A):
def funcA_in_B(self):
super(B, self).funcA()
def funcC(self):
print("this is func C")
ins = B()
ins.funcA_in_B()
ins.funcC()
output
this is func A
this is func C
43. 类中的各种函数
主要分为实例方法、类方法和静态方法
实例方法:
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类方法:
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:实例对象和类对象都可以调用。
静态方法:
定义:使用装饰器@staticmethod。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:实例对象和类对象都可以调用。
静态方法是类中的函数,不需要实例。静态方法主要是用来存放逻辑性的代码,主要是一些逻辑属于类,但是和类本身没有交互。即在静态方法中,不会涉及到类中的方法和属性的操作。可以理解为将静态方法存在此类的名称空间中。
类方法是将类本身作为对象进行操作的方法。他和静态方法的区别在于:不管这个方式是从实例调用还是从类调用,它都用第一个参数把类传递过来。
44. 如何判断是函数还是方法
与类和实例无绑定关系的 function 都属于函数(function)
与类和实例有绑定关系的 function 都属于方法(method)
普通函数:
def func1():
pass
print(func1)
output
<function func1 at 0x01379348>
类中的函数:
class People(object):
def func2(self):
pass
@staticmethod
def func3():
pass
@classmethod
def func4(cls):
pass
people = People()
print(people.func2)
print(people.func3)
print(people.func4)
output
<bound method People.func2 of <__main__.People object at 0x013B8C90>>
<function People.func3 at 0x01379390>
<bound method People.func4 of <class '__main__.People'>>
45. isinstance 的作用以及与 type()的区别
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
class A(object):
pass
class B(A):
pass
a = A()
b = B()
print(isinstance(a, A))
print(isinstance(b, A))
print(type(a) == A)
print(type(b) == A)
output
True
True
True
False
46. 单例模式与工厂模式
单例模式:主要目的是确保某一个类只有一个实例存在。
工厂模式:包涵一个超类,这个超类提供一个抽象化的接口来创建一个特定类型的对象,而不是决定哪个对象可以被创建。
47. 查看目录下的所有文件
import os
print(os.listdir('.'))
48. 计算1到5组成的互不重复的三位数
# 1到5组成的互不重复的三位数
k = 0
for i in range(1, 6):
for j in range(1, 6):
for z in range(1, 6):
if (i != j) and (i != z) and (j != z):
k += 1
if k%6:
print("%s%s%s" %(i, j, z), end="|")
else:
print("%s%s%s" %(i, j, z))
output
1123|124|125|132|134|135
2142|143|145|152|153|154
3213|214|215|231|234|235
4241|243|245|251|253|254
5312|314|315|321|324|325
6341|342|345|351|352|354
7412|413|415|421|423|425
8431|432|435|451|452|453
9512|513|514|521|523|524
10531|532|534|541|542|543
49. 去除字符串首尾空格
str1 = " hello nihao "
str1.strip()
output
'hello nihao'
50. 去除字符串中间的空格
str2 = "hello you are good"
print(str2.replace(" ", ""))
"".join(str2.split(" "))
output
helloyouaregood
'helloyouaregood'
基础篇(二)
51. 字符串格式化方式
1. 使用 % 操作符
print("This is for %s" % "Python")
print("This is for %s, and %s" %("Python", "You"))
output
This is for Python
This is for Python, and You
2. str.format
在 Python3 中,引入了这个新的字符串格式化方法。
print("This is my {}".format("chat"))
print("This is {name}, hope you can {do}".format(name="zhouluob", do="like"))
output
This is my chat
This is zhouluob, hope you can like
3. f-strings
在 Python3-6 中,引入了这个新的字符串格式化方法。
name = "luobodazahui"
print(f"hello {name}")
output
hello luobodazahui
一个复杂些的例子:
def mytest(name, age):
return f"hello {name}, you are {age} years old!"
people = mytest("luobo", 20)
print(people)
output
hello luobo, you are 20 years old!
52. 将"hello world"转换为首字母大写"Hello World"(不使用 title 函数)
str1 = "hello world"
print(str1.title())
" ".join(list(map(lambda x: x.capitalize(), str1.split(" "))))
output
Hello World
'Hello World'
53. 一行代码转换列表中的整数为字符串
如:[1, 2, 3] -> ["1", "2", "3"]
list1 = [1, 2, 3]
list(map(lambda x: str(x), list1))
output
['1', '2', '3']
54. 合并两个元组到字典
如:("zhangfei", "guanyu"),(66, 80) -> {'zhangfei': 66, 'guanyu': 80}
a = ("zhangfei", "guanyu")
b = (66, 80)
dict(zip(a,b))
output
{'zhangfei': 66, 'guanyu': 80}
55. 给出如下代码的输出,并简单解释
例子1:
a = (1,2,3,[4,5,6,7],8)
a[3] = 2
output
TypeError Traceback (most recent call last)
<ipython-input-35-59469d550eb0> in <module>
1 a = (1,2,3,[4,5,6,7],8)
----> 2 a[3] = 2
3 #a
TypeError: 'tuple' object does not support item assignment
例子2:
a = (1,2,3,[4,5,6,7],8)
a[3][2] = 2
a
output
(1, 2, 3, [4, 5, 2, 7], 8)
从例子1的报错中也可以看出,tuple 是不可变类型,不能改变 tuple 里的元素,例子2中,list 是可变类型,改变其元素是允许的。
56. Python 中的反射
反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块寻找指定函数,并执行。利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
简单理解就是用来判断某个字符串是什么,是变量还是方法
class NewClass(object):
def __init__(self, name, male):
self.name = name
self.male = male
def myname(self):
print(f'My name is {self.name}')
def mymale(self):
print(f'I am a {self.male}')
people = NewClass('luobo', 'boy')
print(hasattr(people, 'name'))
print(getattr(people, 'name'))
setattr(people, 'male', 'girl')
print(getattr(people, 'male'))
output
True
luobo
girl
getattr,hasattr,setattr,delattr 对模块的修改都在内存中进行,并不会影响文件中真实内容。
57. 实现一个简单的 API
使用 flask 构造 web 服务器
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=['POST'])
def simple_api():
result = request.get_json()
return result
if __name__ == "__main__":
app.run()
58. metaclass 元类
类与实例:
首先定义类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
类与元类:
先定义元类, 根据 metaclass 创建出类,所以:先定义 metaclass,然后创建类。
class MyMetaclass(type):
def __new__(cls, class_name, class_parents, class_attr):
class_attr['print'] = "this is my metaclass's subclass %s" %class_name
return type.__new__(cls, class_name, class_parents, class_attr)
class MyNewclass(object, metaclass=MyMetaclass):
pass
myinstance = MyNewclass()
myinstance.print
output
"this is my metaclass's subclass MyNewclass"
59. sort 和 sorted 的区别
sort() 是可变对象列表(list)的方法,无参数,无返回值,sort() 会改变可变对象.
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(list1.sort())
list1
output
None
[1, 2, 3]
sorted() 是产生一个新的对象。sorted(L) 返回一个排序后的L,不改变原始的L。sorted() 适用于任何可迭代容器。
dict1 = {'test1':1, 'test2':2}
list1 = [2, 1, 3]
print(sorted(dict1))
print(sorted(list1))
output
['test1', 'test2']
[1, 2, 3]
60. Python 中的 GIL
GIL 是 Python 的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行 Python 程序的时候会占用 Python 解释器(加了一把锁即 GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
61. 产生8位随机密码
import random
"".join(random.choice(string.printable[:-7]) for i in range(8))
output
'd5^NdNJp'
62. 输出原始字符
print('hello\nworld')
print(b'hello\nworld')
print(r'hello\nworld')
output
hello
world
b'hello\nworld'
hello\nworld
63. 列表内,字典按照 value 大小排序
list1 = [{'name': 'guanyu', 'age':29},
{'name': 'zhangfei', 'age': 28},
{'name': 'liubei', 'age':31}]
sorted(list1, key=lambda x:x['age'])
output
[{'name': 'zhangfei', 'age': 28},
{'name': 'guanyu', 'age': 29},
{'name': 'liubei', 'age': 31}]
64. 简述 any() 和 all() 方法
all 如果存在 0 Null False 返回 False,否则返回 True;
any 如果都是 0,None,False,Null 时,返回 True。
print(all([1, 2, 3, 0]))
print(all([1, 2, 3]))
print(any([1, 2, 3, 0]))
print(any([0, None, False]))
output
False
True
True
False
65. 反转整数
def reverse_int(x):
if not isinstance(x, int):
return False
if -10 < x < 10:
return x
tmp = str(x)
if tmp[0] != '-':
tmp = tmp[::-1]
return int(tmp)
else:
tmp = tmp[1:][::-1]
x = int(tmp)
return -x
reverse_int(-23837)
output
-73832
首先判断是否是整数,再判断是否是一位数字,最后再判断是不是负数
66. 函数式编程
函数式编程是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。由于 Python 允许使用变量,因此,Python 不是纯函数式编程语言。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
函数作为返回值例子:
def sum(*args):
def inner_sum():
tmp = 0
for i in args:
tmp += i
return tmp
return inner_sum
mysum = sum(2, 4, 6)
print(type(mysum))
mysum()
output
<class 'function'>
12
67. 简述闭包
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure)。
附上函数作用域图片
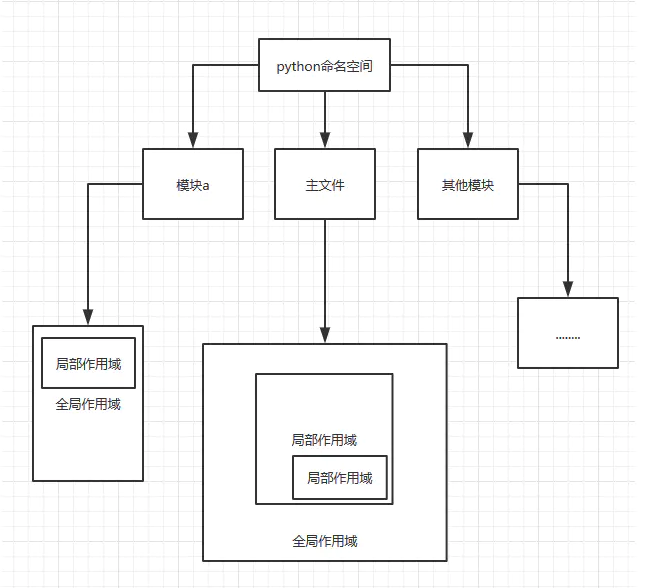
闭包特点
1.必须有一个内嵌函数
2.内嵌函数必须引用外部函数中的变量
3.外部函数的返回值必须是内嵌函数
68. 简述装饰器
装饰器是一种特殊的闭包,就是在闭包的基础上传递了一个函数,然后覆盖原来函数的执行入口,以后调用这个函数的时候,就可以额外实现一些功能了。
一个打印 log 的例子:
import time
def log(func):
def inner_log(*args, **kw):
print("Call: {}".format(func.__name__))
return func(*args, **kw)
return inner_log
@log
def timer():
print(time.time())
timer()
output
Call: timer
1560171403.5128365
本质上,decorator就是一个返回函数的高阶函数
69. 协程的优点
子程序切换不是线程切换,而是由程序自身控制
没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显
不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁
70. 实现一个斐波那契数列
斐波那契数列:
又称黄金分割数列,指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递归的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
生成器法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n): # 判断是正整数
return False
a, b = 0, 1
while n:
a, b = b, a+b
n -= 1
yield a
[i for i in fib(10)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
递归法:
def fib(n):
if n == 0:
return False
if not isinstance(n, int) or (abs(n) != n):
return False
if n <= 1:
return n
return fib(n-1)+ fib(n-2)
[fib(i) for i in range(1, 11)]
output
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
71. 正则切分字符串
import re
str1 = 'hello world:luobo dazahui'
result = re.split(r":| ", str1)
print(result)
output
['hello', 'world', 'luobo', 'dazahui']
72. yield 用法
yield 是用来生成迭代器的语法,在函数中,如果包含了 yield,那么这个函数就是一个迭代器。当代码执行至 yield 时,就会中断代码执行,直到程序调用 next() 函数时,才会在上次 yield 的地方继续执行
def foryield():
print("start test yield")
while True:
result = yield 5
print("result:", result)
g = foryield()
print(next(g))
print("*"*20)
print(next(g))
output
start test yield
5
********************
result: None
5
可以看到,第一个调用 next() 函数,程序只执行到了 "result = yield 5" 这里,同时由于 yield 中断了程序,所以 result 也没有被赋值,所以第二次执行 next() 时,result 是 None。
73. 冒泡排序
list1 = [2, 5, 8, 9, 3, 11]
def paixu(data, reverse=False):
if not reverse:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] > data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
else:
for i in range(len(data) - 1):
for j in range(len(data) - 1 - i):
if data[j] < data[j+1]:
data[j], data[j+1] = data[j+1], data[j]
return data
print(paixu(list1, reverse=True))
output
[11, 9, 8, 5, 3, 2]
74. 快速排序
快排的思想:首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序,之后再递归排序两边的数据。
挑选基准值:从数列中挑出一个元素,称为"基准"(pivot);
分割:重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(与基准值相等的数可以到任何一边)。在这个分割结束之后,对基准值的排序就已经完成;
递归排序子序列:递归地将小于基准值元素的子序列和大于基准值元素的子序列排序。
list1 = [8, 5, 1, 3, 2, 10, 11, 4, 12, 20]
def partition(arr,low,high):
i = ( low-1 ) # 最小元素索引
pivot = arr[high]
for j in range(low , high):
# 当前元素小于或等于 pivot
if arr[j] <= pivot:
i = i+1
arr[i],arr[j] = arr[j],arr[i]
arr[i+1],arr[high] = arr[high],arr[i+1]
return ( i+1 )
def quicksort(arr,low,high):
if low < high:
pi = partition(arr,low,high)
quicksort(arr, low, pi-1)
quicksort(arr, pi+1, high)
quicksort(list1, 0, len(list1)-1)
print(list1)
output
[1, 2, 3, 4, 5, 8, 10, 11, 12, 20]
一个更加简单的快排写法
def quick_sort(arr):
if arr == []:
return []
else:
first = arr[0]
left = quick_sort([l for l in arr[1:] if l < first])
right = quick_sort([r for r in arr[1:] if r >= first])
return left + [first] + right
arr = [1, 4, 5, 2, 0, 8, 11, 6]
result = quick_sort(arr)
print(result)
output
[0, 1, 2, 4, 5, 6, 8, 11]
75. requests 简介
该库是发起 HTTP 请求的强大类库,调用简单,功能强大。
import requests
url = "http://www.luobodazahui.top"
response = requests.get(url) # 获得请求
response.encoding = "utf-8" # 改变其编码
html = response.text # 获得网页内容
binary__content = response.content # 获得二进制数据
raw = requests.get(url, stream=True) # 获得原始响应内容
headers = {'user-agent': 'my-test/0.1.1'} # 定制请求头
r = requests.get(url, headers=headers)
cookies = {"cookie": "# your cookie"} # cookie的使用
r = requests.get(url, cookies=cookies)
76. 比较两个 json 数据是否相等
dict1 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
dict2 = {"zhangfei": 12, "guanyu": 13, "liubei": 18}
def compare_dict(dict1, dict2):
issame = []
for k in dict1.keys():
if k in dict2:
if dict1[k] == dict2[k]:
issame.append(1)
else:
issame.append(2)
else:
issame.append(3)
print(issame)
sum_except = len(issame)
sum_actually = sum(issame)
if sum_except == sum_actually:
print("this two dict are same!")
return True
else:
print("this two dict are not same!")
return False
test = compare_dict(dict1, dict2)
output
[1, 1, 1]
this two dict are same!
77. 读取键盘输入
input() 函数
def forinput():
input_text = input()
print("your input text is: ", input_text)
forinput()
output
hello
your input text is: hello
78. enumerate
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
data1 = ['one', 'two', 'three', 'four']
for i, enu in enumerate(data1):
print(i, enu)
output
0 one
1 two
2 three
3 four
79. pass 语句
pass 是空语句,是为了保持程序结构的完整性。pass 不做任何事情,一般用做占位语句。
def forpass(n):
if n == 1:
pass
else:
print('not 1')
forpass(1)
80. 正则匹配邮箱
import re
email_list= ["test01@163.com","test02@163.123", ".test03g@qq.com", "test04@gmail.com" ]
for email in email_list:
ret = re.match("[\w]{4,20}@(.*)\.com$",email)
if ret:
print("%s 是符合规定的邮件地址,匹配后结果是:%s" % (email,ret.group()))
else:
print("%s 不符合要求" % email)
output
test01@163.com 是符合规定的邮件地址,匹配后结果是:test01@163.com
test02@163.123 不符合要求
.test03g@qq.com 不符合要求
test04@gmail.com 是符合规定的邮件地址,匹配后结果是:test04@gmail.com
81. 统计字符串中大写字母的数量
str2 = 'werrQWSDdiWuW'
counter = 0
for i in str2:
if i.isupper():
counter += 1
print(counter)
output
6
82. json 序列化时保留中文
普通序列化:
import json
dict1 = {'name': '萝卜', 'age': 18}
dict1_new = json.dumps(dict1)
print(dict1_new)
output
{"name": "\u841d\u535c", "age": 18}
保留中文
import json
dict1 = {'name': '萝卜', 'age': 18}
dict1_new = json.dumps(dict1, ensure_ascii=False)
print(dict1_new)
output
{"name": "萝卜", "age": 18}
83. 简述继承
一个类继承自另一个类,也可以说是一个孩子类/派生类/子类,继承自父类/基类/超类,同时获取所有的类成员(属性和方法)。
继承使我们可以重用代码,并且还可以更方便地创建和维护代码。
Python 支持以下类型的继承:
单继承- 一个子类类继承自单个基类
多重继承- 一个子类继承自多个基类
多级继承- 一个子类继承自一个基类,而基类继承自另一个基类
分层继承- 多个子类继承自同一个基类
混合继承- 两种或两种以上继承类型的组合
84. 什么是猴子补丁
猴子补丁是指在运行时动态修改类和模块。
猴子补丁主要有以下几个用处:
在运行时替换方法、属性等
在不修改第三方代码的情况下增加原来不支持的功能
在运行时为内存中的对象增加 patch 而不是在磁盘的源代码中增加
85. help() 函数和 dir() 函数
help() 函数返回帮助文档和参数说明:
help(dict)
output
Help on class dict in module builtins:
class dict(object)
| dict() -> new empty dictionary
| dict(mapping) -> new dictionary initialized from a mapping object's
| (key, value) pairs
| dict(iterable) -> new dictionary initialized as if via:
| d = {}
| for k, v in iterable:
| d[k] = v
| dict(**kwargs) -> new dictionary initialized with the name=value pairs
| in the keyword argument list. For example: dict(one=1, two=2)
......
dir() 函数返回对象中的所有成员 (任何类型)
dir(dict)
output
['__class__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
......
86. 解释 Python 中的//,%和**运算符
// 运算符执行地板除法,返回结果的整数部分 (向下取整)
% 是取模符号,返回除法后的余数
** 符号表示取幂. a**b 返回 a 的 b 次方
print(5//3)
print(5/3)
print(5%3)
print(5**3)
output
1
1.6666666666666667
2
125
87. 主动抛出异常
使用 raise
def test_raise(n):
if not isinstance(n, int):
raise Exception('not a int type')
else:
print('good')
test_raise(8.9)
output
Exception Traceback (most recent call last)
<ipython-input-262-b45324f5484e> in <module>
4 else:
5 print('good')
----> 6 test_raise(8.9)
<ipython-input-262-b45324f5484e> in test_raise(n)
1 def test_raise(n):
2 if not isinstance(n, int):
----> 3 raise Exception('not a int type')
4 else:
5 print('good')
Exception: not a int type
88. tuple 和 list 转换
tuple1 = (1, 2, 3, 4)
list1 = list(tuple1)
print(list1)
tuple2 = tuple(list1)
print(tuple2)
output
[1, 2, 3, 4]
(1, 2, 3, 4)
89. 简述断言
Python 的断言就是检测一个条件,如果条件为真,它什么都不做;反之它触发一个带可选错误信息的 AssertionError。
def testassert(n):
assert n == 2, "n is not 2"
print('n is 2')
testassert(1)
output
AssertionError Traceback (most recent call last)
<ipython-input-268-a9dfd6c79e73> in <module>
2 assert n == 2, "n is not 2"
3 print('n is 2')
----> 4 testassert(1)
<ipython-input-268-a9dfd6c79e73> in testassert(n)
1 def testassert(n):
----> 2 assert n == 2, "n is not 2"
3 print('n is 2')
4 testassert(1)
AssertionError: n is not 2
90. 什么是异步非阻塞
同步异步指的是调用者与被调用者之间的关系。
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回,一旦调用返回,就得到了返回值。
异步的概念和同步相对。调用在发出之后,这个调用就直接返回了,所以没有返回结果。当该异步功能完成后,被调用者可以通过状态、通知或回调来通知调用者。
阻塞非阻塞是线程或进程之间的关系。
阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到io操作)。调用线程只有在得到结果之后才会返回。函数只有在得到结果之后才会将阻塞的线程激活。
非阻塞和阻塞的概念相对应,非阻塞调用指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程。
91. 什么是负索引
Python 中的序列是有索引的,它由正数和负数组成。正的数字使用'0'作为第一个索引,'1'作为第二个索引,以此类推。
负数的索引从'-1'开始,表示序列中的最后一个索引,' - 2'作为倒数第二个索引,依次类推。
92. 退出 Python 后,内存是否全部释放
不是的,那些具有对象循环引用或者全局命名空间引用的变量,在 Python 退出时往往不会被释放。
另外不会释放 C 库保留的部分内容。
93. Flask 和 Django 的异同
Flask 是 “microframework”,主要用来编写小型应用程序,不过随着 Python 的普及,很多大型程序也在使用 Flask。同时,在 Flask 中,我们必须使用外部库。
Django 适用于大型应用程序。它提供了灵活性,以及完整的程序框架和快速的项目生成方法。可以选择不同的数据库,URL结构,模板样式等。
94. 创建删除操作系统上的文件
import os
f = open('test.txt', 'w')
f.close()
os.listdir()
os.remove('test.txt')
95. 简述 logging 模块
logging 模块是 Python 内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级、日志保存路径、日志文件回滚等;相比 print,具备如下优点:
可以通过设置不同的日志等级,在 release 版本中只输出重要信息,而不必显示大量的调试信息;
print 将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据;logging 则可以由开发者决定将信息输出到什么地方,以及怎么输出。
简单配置:
import logging
logging.debug("debug log")
logging.info("info log")
logging.warning("warning log")
logging.error("error log")
logging.critical("critica log")
output
WARNING:root:warning log
ERROR:root:error log
CRITICAL:root:critica log
默认情况下,只显示了大于等于WARNING级别的日志。logging.basicConfig()函数调整日志级别、输出格式等。
96. 统计字符串中单词出现次数
from collections import Counter
str1 = "nihsasehndciswemeotpxc"
print(Counter(str1))
output
Counter({'s': 3, 'e': 3, 'n': 2, 'i': 2, 'h': 2, 'c': 2, 'a': 1, 'd': 1, 'w': 1, 'm': 1, 'o': 1, 't': 1, 'p': 1, 'x': 1})
97. 正则 re.complie 的作用
re.compile 是将正则表达式编译成一个对象,加快速度,并重复使用。
98. try except else finally 的意义
try..except..else 没有捕获到异常,执行 else 语句
try..except..finally 不管是否捕获到异常,都执行 finally 语句
100. 字符串中数字替换
使用 re 正则替换
import re
str1 = '我是周萝卜,今年18岁'
result = re.sub(r"\d+","20",str1)
print(result)
output
我是周萝卜,今年20岁
网络编程篇
1. 简述 OSI 七层协议
是网络传输协议,人为的把网络传输的不同阶段划分成不同的层次。
七层划分为:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。
五层划分为:应用层、传输层、网络层、数据链路层、物理层。
物理层:网线,电缆等物理设备
数据链路层:Mac 地址
网络层:IP 地址
传输层:TCP,UDP 协议
应用层:FTP 协议,Email,WWW 等
2. 三次握手、四次挥手的流程
都发生在传输层
三次握手:
TCP 协议是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接。
TCP 标志位(位码),有6种标示:SYN(synchronous建立联机) ACK(acknowledgement 确认) PSH(push传送) FIN(finish结束) RST(reset重置) URG(urgent紧急)
Sequence number(顺序号码) Acknowledge number(确认号码)
第一次握手:主机 A 发送位码为 syn=1,随机产生 seq number=1234567 的数据包到服务器,并进入 SYN_SEND 状态,主机 B 由 SYN=1 知道,A 要求建立联机;
第二次握手:主机 B 收到请求后要确认联机信息,向 A 发送 ack number=(主机 A 的 seq+1),syn=1,ack=1,随机产生 seq=7654321 的包,并进入 SYN_RECV 状态;
第三次握手:主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码 ack 是否为 1,若正确,主机 A 会再发送 ack number=(主机 B 的 seq+1),ack=1,主机 B 收到后确认 seq 值与 ack=1 则连接建立成功,两个主机均进入 ESTABLISHED 状态。
以上完成三次握手,主机 A 与主机 B 开始传送数据。
四次挥手:
因为 TCP 连接是全双工的,因此每个方向都必须单独进行关闭。这个原则是当一方完成它的数据发送任务后就能发送一个 FIN 来终止这个方向的连接。收到一个 FIN 只意味着这一方向上没有数据流动,一个 TCP 连接在收到一个 FIN 后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
服务器 A 发送一个 FIN,用来关闭 A 到服务器 B 的数据传送。
服务器 B 收到这个 FIN,它发回一个 ACK,确认序号为收到的序号加1。和 SYN 一样,一个 FIN 将占用一个序号。
服务器 B 关闭与服务器 A 的连接,发送一个 FIN 给服务器 A。
服务器 A 发回 ACK 报文确认,并将确认序号设置为收到序号加1。
3. 什么是C/S和B/S架构
B/S 又称为浏览器/服务器模式。比如各种网站,jupyter notebook 等。
优点:零安装,维护简单,共享性好。
缺点:安全性较差,个性化不足。
C/S 又称为客户端/服务器模式。比如微信客户端,Oracle 客户端等。
优点:安全性好,数据传输较快,稳定。
缺点:对 PC 机操作系统等有要求,当客户端较多时,服务器端负载较大。
4. TCP和UDP的区别
TCP 和 UDP 都是 OSI 模型中运输层的协议。TCP 提供可靠的通信传输,而 UDP 则常被用于广播和细节控制交给应用的通信传输。
UDP 不提供复杂的控制机制,利用 IP 提供面向无连接的通信服务。
TCP 充分实现了数据传输时各种控制功能,可以进行丢包的重发控制,还可以对次序乱掉的分包进行顺序控制。
TCP 应用:FTP 传输,点对点短信等。
UDP 应用:媒体流等。
5. 局域网和广域网
广域网(WAN,Wide Area Network)也称远程网(long haul network )。通常跨接很大的物理范围,所覆盖的范围从几十公里到几千公里,它能连接多个城市或国家,或横跨几个洲并能提供远距离通信,形成国际性的远程网络。
局域网(Local Area Network,LAN)是指在某一区域内由多台计算机互联成的计算机组。一般是方圆几千米以内。局域网可以实现文件管理、应用软件共享、打印机共享、工作组内的日程安排、电子邮件和传真通信服务等功能。局域网是封闭型的,可以由办公室内的两台计算机组成,也可以由一个公司内的上千台计算机组成。
6. arp 协议
ARP(Address Resolution Protocol)即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,即询问目标 IP 对应的 MAC 地址。
7. 什么是 socket?简述基于 TCP 协议的套接字通信流程。
socket 是对 TCP/IP 协议的封装,它的出现只是使得程序员更方便地使用 TCP/IP 协议栈而已。socket 本身并不是协议,它是应用层与 TCP/IP 协议族通信的中间软件抽象层,是一组调用接口(TCP/IP网络的API函数)。
“TCP/IP 只是一个协议栈,就像操作系统的运行机制一样,必须要具体实现,同时还要提供对外的操作接口。
这个就像操作系统会提供标准的编程接口,比如win32编程接口一样。TCP/IP 也要提供可供程序员做网络开发所用的接口,这就是 Socket 编程接口。”
Server:
import socket
import threading
def tcplink(sock, addr):
print('Accept new connection from %s:%s...' % addr)
sock.send(b'Welcome!')
while True:
data = sock.recv(1024)
time.sleep(1)
if not data or data.decode('utf-8') == 'exit':
break
sock.send(('Hello, %s!' % data.decode('utf-8')).encode('utf-8'))
sock.close()
print('Connection from %s:%s closed.' % addr)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 监听端口:
s.bind(('127.0.0.1', 9999))
s.listen(5)
print('Waiting for connection...')
while True:
# 接受一个新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=tcplink, args=(sock, addr))
t.start()
Client:
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 建立连接:
s.connect(('127.0.0.1', 9999))
# 接收欢迎消息:
print(s.recv(1024).decode('utf-8'))
for data in [b'Michael', b'Tracy', b'Sarah']:
# 发送数据:
s.send(data)
print(s.recv(1024).decode('utf-8'))
s.send(b'exit')
s.close()
例子来源于廖雪峰的官网
8. 简述 进程、线程、协程的区别以及应用场景
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。
多进程:密集 CPU 任务,需要充分使用多核 CPU 资源(服务器,大量的并行计算)的时候,用多进程。
缺陷:多个进程之间通信成本高,切换开销大。
多线程:密集 I/O 任务(网络 I/O,磁盘 I/O,数据库 I/O)使用多线程合适。
缺陷:同一个时间切片只能运行一个线程,不能做到高并行,但是可以做到高并发。
协程:又称微线程,在单线程上执行多个任务,用函数切换,开销极小。不通过操作系统调度,没有进程、线程的切换开销。
缺陷:单线程执行,处理密集 CPU 和本地磁盘 IO 的时候,性能较低。处理网络 I/O 性能还是比较高。
多线程请求返回是无序的,哪个线程有数据返回就处理哪个线程,而协程返回的数据是有序的。
9. 如何使用线程池和进程池
池的功能是限制启动的进程数或线程数。当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时,就应该用池的概念将开启的进程数或线程数限制在计算机可承受的范围内。
多进程
from multiprocessing import Pool
import os
import time
import random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
def test_pool():
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
if __name__ == '__main__':
test_pool()
output
Parent process 32432.
Waiting for all subprocesses done...
Run task 0 (15588)...
Run task 1 (32372)...
Run task 2 (12440)...
Run task 3 (18956)...
Task 2 runs 0.72 seconds.
Run task 4 (12440)...
Task 3 runs 0.82 seconds.
Task 1 runs 1.21 seconds.
Task 0 runs 3.00 seconds.
Task 4 runs 2.95 seconds.
All subprocesses done.
apply_async(func[, args[, kwds]]) :使用非阻塞方式调用 func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args 为传递给 func 的参数列表,kwds 为传递给 func 的关键字参数列表;
close():关闭 Pool,使其不再接受新的任务;
terminate():不管任务是否完成,立即终止;
join():主进程阻塞,等待子进程的退出, 必须在 close 或 terminate 之后使用;
也可以使用 concurrent.futures 模块提供的功能来实现
def test_future_process():
print('Parent process %s.' % os.getpid())
p = ProcessPoolExecutor(4)
for i in range(5):
p.submit(long_time_task, i)
p.shutdown(wait=True)
print('Finish')
if __name__ == '__main__':
# test_pool()
test_future_process()
output
Parent process 29368.
Run task 0 (32148)...
Run task 1 (31552)...
Run task 2 (24012)...
Run task 3 (29408)...
Task 2 runs 0.52 seconds.
Run task 4 (24012)...
Task 3 runs 0.86 seconds.
Task 1 runs 1.81 seconds.
Task 0 runs 1.83 seconds.
Task 4 runs 1.69 seconds.
Finish
多线程
def sayhello(a):
print("hello: " + a)
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (a, (end - start)))
def test_future_thread():
seed = ["a", "b", "c", "d"]
start = time.time()
with ThreadPoolExecutor(3) as executor:
for i in seed:
executor.submit(sayhello, i)
end = time.time()
print("Thread Run Time: " + str(end - start))
output
hello: a
hello: b
hello: c
Task a runs 0.40 seconds.
hello: d
Task b runs 0.56 seconds.
Task d runs 1.70 seconds.
Task c runs 2.92 seconds.
Thread Run Time: 2.9195945262908936
可以看出,由于是创建了限制为3的线程池,所以只有三个任务在同时执行。
10. 进程之间如何进行通信
def write(q):
print("write(%s), 父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "Python":
print("Put %s to Queue" % i)
q.put(i)
def read(q):
print("read(%s), 父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("read 从 Queue 获取到消息: %s" % q.get(True))
def test_commun():
print("(%s) start" % os.getpid())
q = Manager().Queue()
pw = Process(target=write, args=(q, ))
pr = Process(target=read, args=(q, ))
pw.start()
pr.start()
pw.join()
pr.terminate()
output
(23544) start
write(29856), 父进程为(23544)
Put P to Queue
Put y to Queue
Put t to Queue
Put h to Queue
Put o to Queue
Put n to Queue
read(25016), 父进程为(23544)
read 从 Queue 获取到消息:P
read 从 Queue 获取到消息:y
read 从 Queue 获取到消息:t
read 从 Queue 获取到消息:h
read 从 Queue 获取到消息:o
read 从 Queue 获取到消息:n
Python 的 multiprocessing 模块包装了底层的机制,提供了 Queue、Pipes 等多种方式来交换数据。
11. 进程锁和线程锁
进程锁:是为了控制同一操作系统中多个进程访问一个共享资源,只是因为程序的独立性,各个进程是无法控制其他进程对资源的访问的,但是可以使用本地系统的信号量控制。
信号量(Semaphore),有时被称为信号灯,是在多线程环境下使用的一种设施,是可以用来保证两个或多个关键代码段不被并发调用。
线程锁:当多个线程几乎同时修改一个共享数据的时候,需要进行同步控制,线程同步能够保证多个线程安全的访问竞争资源(全局内容),最简单的同步机制就是使用互斥锁。
某个线程要更改共享数据时,先将其锁定,此时资源的状态为锁定状态,其他线程就能更改,直到该线程将资源状态改为非锁定状态,也就是释放资源,其他的线程才能再次锁定资源。互斥锁保证了每一次只有一个线程进入写入操作。从而保证了多线程下数据的安全性。
12. 什么是并发和并行
并行:多个 CPU 核心,不同的程序就分配给不同的 CPU 来运行。可以让多个程序同时执行。
并发:单个 CPU 核心,在一个时间切片里一次只能运行一个程序,如果需要运行多个程序,则串行执行。
13. threading.local 的作用
ThreadLocal 叫做线程本地变量,ThreadLocal 在每一个变量中都会创建一个副本,每个线程都可以访问自己内部的副本变量,对其他线程时不可见的,修改之后也不会影响到其他线程。
14. 什么是域名解析
域名解析是指将域名解析为 IP 地址。也有反向的“逆解析”,将 IP 通过 DNS 服务器查找到对应的域名地址。
DNS 是域名系统 (Domain Name System),域名系统为因特网上的主机分配域名地址和 IP 地址。用户使用域名地址,该系统就会自动把域名地址转为 IP 地址。
15. LVS 是什么及作用
LVS 是 Linux Virtual Server 的简写,意即 Linux 虚拟服务器,是一个虚拟的服务器集群系统,即负载均衡服务器。
LVS 工作模式分为 NAT 模式、TUN 模式、以及 DR 模式。
16. Nginx 的作用
Nginx 主要功能:1、反向代理 2、负载均衡 3、HTTP 服务器(包含动静分离) 4、正向代理
正向代理:某些情况下,代理用户去访问服务器,需要手动设置代理服务器的 IP 和端口号。
反向代理:是用来代理服务器的,代理要访问的目标服务器。代理服务器接受请求,然后将请求转发给内部网络的服务器(集群化),并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个服务器。
负载均衡服务器类似于 LVS
HTTP 服务器类似于 Tomcat 等。
17. keepalived 及 HAProxy
HAProxy 提供高可用性、负载均衡,以及基于 TCP 和 HTTP 的应用程序代理。
keepalived 是集群管理中保证集群高可用的一个服务软件,其功能类似于 heartbeat,用来防止单点故障。
18. 什么是 rpc
RPC 是指远程过程调用,也就是说两台服务器 A,B,一个应用部署在 A 服务器上,想要调用 B 服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
19. 从浏览器输入一个网址到展示网址页面的过程
浏览器通过 DNS 服务器查找到域名对应的 IP 地址
浏览器给 IP 对应的 web 服务器发送 HTTP 请求
web 服务器接收到 HTTP 请求后,返回响应给浏览器
浏览器接收到响应后渲染页面
20. 什么是cdn
CDN 的全称是 Content Delivery Network,即内容分发网络。CDN 是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN 的关键技术主要有内容存储和分发技术。
数据库和框架篇
21. 列举常见的数据库
关系型数据库:MySQL,Oracle,SQLServer,SQLite,DB2
非关系型数据库:MongoDB,Redis,HBase,Neo4j
22. 数据库设计三大范式
建立科学的,规范的的数据库是需要满足一些规范的,以此来优化数据数据存储方式,在关系型数据库中这些规范就可以称为范式。
第一范式:当关系模式 R 的所有属性都不能在分解为更基本的数据单位时,称 R 是满足第一范式的,简记为 1NF。
关系模式R的所有属性不能再分解
第二范式:如果关系模式 R 满足第一范式,并且 R 的所有非主属性都完全依赖于 R 的每一个候选关键属性,称 R 满足第二范式,简记为 2NF。
非主属性都要依赖于每一个关键属性
三范式:设 R 是一个满足第一范式条件的关系模式,X 是 R 的任意属性集,如果 X 非传递依赖于 R 的任意一个候选关键字,称 R 满足第三范式,简记为 3NF。
数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系
23. 什么是数据库事务
事务(Transaction)是并发控制的基本单位。所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
在关系数据库中,一个事务可以是一条 SQL 语句、一组 SQL 语句或整个程序。
四个属性:原子性,一致性,隔离性和持久性。
24. MySQL 索引种类
MySQL 目前主要有以下几种索引类型:
普通索引
唯一索引
主键索引
组合索引
全文索引
25. 数据库设计中一对多和多对多的应用场景
一对一关系示例:
一个学生对应一个学生档案材料,或者每个人都有唯一的身份证编号。
一对多关系示例:
一个学生只属于一个班,但是一个班级有多名学生。
多对多关系示例:
一个学生可以选择多门课,一门课也有多名学生。
26. 简述触发器、函数、视图、存储过程
触发器:触发器是一个特殊的存储过程,它是数据库在 insert、update、delete 的时候自动执行的代码块。
函数:数据库中提供了许多内置函数,还可以自定义函数,实现 sql 逻辑。
视图:视图是由查询结果形成的一张虚拟表,是表通过某种运算得到的一个投影。
存储过程:把一段代码封装起来,当要执行这一段代码的时候,可以通过调用该存储过程来实现(经过第一次编译后再次调用不需要再次编译,比一个个执行 sql 语句效率高)
27. 常用 SQL 语句
DML(数据操作语言)
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT INTO - 向数据库表中插入数据
DDL(数据定义语言)
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
28. 主键和外键的区别
定义主键和外键主要是为了维护关系数据库的完整性
主键是能确定一条记录的唯一标识。不能重复,不允许为空。
外键用于与另一张表关联。是能确定另一张表记录的字段,用于保持数据的一致性。
| 主键 | 外键 | 索引 | |
|---|---|---|---|
| 定义 | 唯一标识一条记录,不能重复,不允许为空 | 表的外键是另一表的主键,外键可以重复,可以是空值 | 该字段没有重复值,但可以有空值 |
| 作用 | 用来保证数据完整性 | 用来和其他表建立联系 | 提高查询排序的速度 |
| 个数 | 只能有一个 | 可有多个 | 可有多个 |
29. 如何开启 MySQL 慢日志查询
修改配置文件,然后重启服务生效
在linux下,vim /etc/my.cnf,在[mysqld]内容项下增加:
slow_query_log = ON
long_query_time = 2 # 查询超过2秒的就会记录命令行,但是重启服务后会失效
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 2;
30. MySQL 数据库备份命令
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
31. char 和 varchar 的区别
char:存储定长数据很方便,CHAR 字段上的索引效率级高,必须在括号里定义长度,可以有默认值,比如定义 char(10)。
varchar:存储变长数据,但存储效率没有 CHAR 高,必须在括号里定义长度,可以有默认值。
32. 最左前缀原则
mysql 建立多列索引(联合索引)有最左前缀的原则,即最左优先,如:
如果有一个2列的索引(col1,col2),则已经对(col1)、(col1,col2)上建立了索引;
如果有一个3列索引(col1,col2,col3),则已经对(col1)、(col1,col2)、(col1,col2,col3)上建立了索引;
33. 无法命中索引的情况
使用or关键字会导致无法命中索引
左前导查询会导致无法命中索引,如 like '%a' 或者 like '%a%'
单列索引的索引列为 null 时全值匹配会使索引失效,组合索引全为 null 时索引失效
组合索引不符合左前缀原则的列无法命中索引,如我们有4个列 a、b、c、d,我们创建一个组合索引 INDEX(
a,b,c,d),那么能命中索引的查询为 a,ab,abc,abcd,除此之外都无法命中索引强制类型转换会导致索引失效
负向查询条件会导致无法使用索引,比如 NOT IN,NOT LIKE,!= 等
如果 mysql 估计使用全表扫描要比使用索引快,则不使用索引
34. 数据库读写分离
读写分离,就是将数据库分为了主从库,一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过某种机制进行数据的同步,是一种常见的数据库架构。
35. 数据库分库分表
数据库水平切分,是一种常见的数据库架构,是一种通过算法,将数据库进行分割的架构。一个水平切分集群中的每个数据库,通常称为一个“分片”。每一个分片中的数据没有重合,所有分片中的数据并集组成全部数据。
水平切分分为库内分表和分库分表,是根据表内数据内在的逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小,达到分布式的效果。
36. redis 和 memcached 比较
redis 和 memcached 都是将数据存放在内存中,都是内存数据库。不过 memcached 还可用于缓存其他东西,例如图片、视频等等。
redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,hash 等数据结构的存储。
分布式设定, 都可以做一主多从或一主一从 。
存储数据安全,memcached 挂掉后,数据完全丢失;redis 可以定期保存到磁盘(持久化)。
灾难恢复,memcached 挂掉后,数据不可恢复; redis 数据丢失后可以通过 aof 恢复。
37. redis中数据库默认是多少个 db 及作用
redis 默认有16个数据库,每个数据库中的数据都是隔离的,这样,在存储数据的时候,就可以指定把不同的数据存储到不同的数据库中。
且只有单机才有,如果是集群就没有数据库的概念。
38. redis 有哪几种持久化策略
RDB 持久化:是将 Reids 在内存中的数据库记录定时 dump 到磁盘上的持久化
AOF(append only file)持久化:将 Reids 的操作日志以追加的方式写入文件
39. redis 支持的过期策略
通用的三种过期策略
定时删除
在设置 key 的过期时间的同时,为该 key 创建一个定时器,让定时器在 key 的过期时间来临时,对 key 进行删除惰性删除
key 过期的时候不删除,每次从数据库获取 key 的时候去检查是否过期,若过期,则删除,返回 null。定期删除
每隔一段时间执行一次删除过期 key 操作
redis 采用惰性删除+定期删除策略
40. 如何保证 redis 中的数据都是热点数据
限定 Redis 占用的内存,Redis 会根据自身数据淘汰策略,加载热数据到内存。
所以,计算一下所有热点数据大约占用的内存,然后设置一下 Redis 内存限制即可。
41. Python 操作 redis
使用 redis 第三方库来操作
import redis
# 创建一个 redis 连接池
def redis_conn_pool():
pool = redis.ConnectionPool(host='redis-host', port=redis-port,
decode_responses=True, password='redis-pwd')
r = redis.Redis(connection_pool=pool)
return r
42. 基于 redis 实现发布和订阅
订阅者
if __name__ == "__main__":
conn = redis.Redis(host='',
port=12143, password='')
ps = conn.pubsub()
ps.subscribe('chat') # 从 chat 订阅消息
for item in ps.listen(): # 监听状态:有消息发布了就拿过来
if item['type'] == 'message':
print(item)
print(item['channel'])
print(item['data'])
发布者
if __name__ == "__main__":
number_list = ['300033', '300032', '300031', '300030']
signal = ['1', '-1', '1', '-1']
pool = redis.ConnectionPool(host='redis-12143.c8.us-east-1-3.ec2.cloud.redislabs.com', port=12143,
decode_responses=True, password='pkAWNdYWfbLLfNOfxTJinm9SO16eSJFx')
r = redis.Redis(connection_pool=pool)
for i in range(len(number_list)):
value_new = str(number_list[i]) + ' ' + str(signal[i])
print(value_new)
r.publish("chat", value_new)
43. 如何高效的找到 redis 中的某个 KEY
import redis
con = redis.Redis()
con.keys(pattern='key*') # *代表通配符
44. 基于 redis 实现先进先出、后进先出及优先级队列
class Zhan:
def __init__(self,conn):
self.conn = conn
def push(self,val):
self.conn.rpush('aaa',val)
def pop(self):
return self.conn.rpop('aaa')
class Dui:
def __init__(self,conn):
self.conn = conn
def push(self,val):
self.conn.rpush('bbb',val)
def get(self):
return self.conn.lpop('bbb')
class Xu:
def __init__(self,conn):
self.conn = conn
def push(self,val,count):
self.conn.zadd('ccc',val,count)
def get(self):
a = self.conn.zrange('ccc', 0, 0)[0]
self.conn.zrem('ccc', a)
return a
45. redis 如何实现主从复制
在从服务器中配置 SLAVEOF 127.0.0.1 6380 # 主服务器 IP,端口
46. 循环获取 redis 中某个非常大的列表数据
def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index)
47. redis 中的 watch 的命令的作用
watch 用于在进行事务操作的最后一步也就是在执行 exec 之前对某个 key 进行监视,如果这个被监视的 key 被改动,那么事务就被取消,否则事务正常执行。
48. redis 分布式锁
为 redis 集群设计的锁,防止多个任务同时修改数据库,其本质就是为集群中的每个主机设置一个会超时的字符串,当集群中有一半多的机器设置成功后就认为加锁成功,直至锁过期或解锁不会有第二个任务加锁成功。
49. http 协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。HTTP 是一个客户端和服务器端请求和应答的标准。客户端是终端用户,服务器端是网站。一般由 HTTP 客户端发起一个请求,建立一个到服务器指定端口(默认是80端口)的 TCP 连接,HTTP 服务器则在那个端口监听客户端发送过来的请求,并给与响应。
50. uwsgi,uWSGI 和 WSGI 的区别
WSGI:全称是 Web Server Gateway Interface,是一种描述 web server 如何与 web application 通信的规范。django,flask 等都遵循该协议。
uwsgi:是服务器和服务端应用程序的一种协议,规定了怎么把请求转发给应用程序和返回; uwsgi 是一种线路协议而不是通信协议,在此常用于在 uWSGI 服务器与其他网络服务器的数据通信。
uWSGI:是一个 Web 服务器,它实现了 WSGI 协议、uwsgi、http 等协议。Nginx 中 HttpUwsgiModule 的作用是与 uWSGI 服务器进行交换。
51. HTTP 状态码
1xx: 信息
2xx:成功
3xx:重定向
4xx:客户端错误
5xx:服务器错误
52. HTTP常见请求方式
GET,POST,PUT,DELETE,PATCH 等
53. 响应式布局
响应式布局是 Ethan Marcotte 在2010年5月份提出的一个概念,简而言之,就是一个网站能够兼容多个终端——而不是为每个终端做一个特定的版本。
54. 实现一个简单的 AJAX 请求
AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。
AJAX = 异步 JavaScript 和 XML
$(function(){
$('#send').click(function(){
$.ajax({
type: "GET",
url: "test.json",
data: {username:$("#username").val(), content:$("#content").val()},
dataType: "json",
success: function(data){
$('#resText').empty(); //清空resText里面的所有内容
var html = '';
$.each(data, function(commentIndex, comment){
html += '<div class="comment"><h6>' + comment['username']
+ ':</h6><p class="para"' + comment['content']
+ '</p></div>';
});
$('#resText').html(html);
}
});
});
});
55. 同源策略
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。
如果两个页面的协议,端口(如果有指定)和主机都相同,则两个页面具有相同的源。我们也可以把它称为“协议/主机/端口 tuple”,或简单地叫做“tuple". ("tuple" ,“元”,是指一些事物组合在一起形成一个整体,比如(1,2)叫二元,(1,2,3)叫三元)
56. 什么是 CORS
CORS 全称是跨域资源共享(Cross-Origin Resource Sharing),是一种 AJAX 跨域请求资源的方式,支持现代浏览器。
57. 什么是 CSRF
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。
58. 前端实现轮询、长轮询
轮询
var xhr = new XMLHttpRequest();
setInterval(function(){
xhr.open('GET','/user');
xhr.onreadystatechange = function(){
};
xhr.send();
},1000)
长轮询
function ajax(){
var xhr = new XMLHttpRequest();
xhr.open('GET','/user');
xhr.onreadystatechange = function(){
ajax();
};
xhr.send();
}
59. 简述 MVC 和 MTV
所谓 MVC 就是把 web 应用分为模型(M),控制器(C),视图(V)三层,他们之间以一种插件似的,松耦合的方式连接在一起。
模型负责业务对象与数据库的对象(ORM),视图负责与用户的交互(页面),控制器(C)接受用户的输入调用模型和视图完成用户的请求。
Django 中的 MTV 模式:Model(模型):负责业务对象与数据库的对象(ORM),Template(模版):负责如何把页面展示给用户,View(视图):负责业务逻辑,并在适当的时候调用 Model 和 Template,本质上与 MVC 相同。
60. 接口的幂等性
接口幂等性就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
61. Flask 框架的优势
简洁,轻巧,扩展性强,自由度高。
62. 什么是 ORM
ORM 的全称是 Object Relational Mapping,即对象关系映射。它的实现思想就是将关系数据库中表的数据映射成为对象,以对象的形式展现,这样开发人员就可以把对数据库的操作转化为对这些对象的操作。
63. PV、UV 的含义
PV:是(page view)访问量,页面浏览量或点击量,衡量网站用户访问的网页数量。在一定统计周期内用户每打开或刷新一个页面就记录1次,多次打开或刷新同一页面则浏览量累计。
UV:是(Unique Visitor)独立访客,统计一段时间内访问某站点的用户数(以cookie为依据)。
64. supervisor 的作用
supervisor 管理进程,是通过 fork/exec 的方式将这些被管理的进程当作 supervisor 的子进程来启动,所以我们只需要将要管理进程的可执行文件的路径添加到 supervisor 的配置文件中即可。
65. 使用 ORM 和原生 SQL 的优缺点
优点:
方便的使用面向对象,语句清晰;
有效的防止 SQL 注入;
方便动态构造语句,对于不同的表的相同操作采用多态实现更优雅;
一定程度上方便重构数据层
方便设置设置钩子函数
缺点:
不太容易处理复杂查询语句
性能较直接用 SQL 差
66. 列举一些 django 的内置组件
Admin 组件:是对 model 中对应的数据表进行增删改查提供的组件
model 组件:负责操作数据库
form 组件:生成 HTML 代码;数据有效性校验;校验信息返回并展示
ModelForm 组件:用于数据库操作,也可用于用户请求的验证
67. 列举 Django 中执行原生 sql 的方法
使用 execute 执行自定义的 SQL
直接执行 SQL 语句(类似于 pymysql 的用法)
from django.db import connection
cursor = connection.cursor()
cursor.execute("SELECT DATE_FORMAT(create_time, '%Y-%m') FROM blog_article;")
ret = cursor.fetchall()
print(ret)
使用 extra 方法:queryset.extra(select={"key": "原生的SQL语句"})
使用 raw 方法
执行原始 sql 并返回模型
依赖于 model 模型,多用于查询操作
68. cookie 和 session 的区别
cookie 是保存在浏览器端的键值对,可以用来做用户认证。
sesseion 是将用户的会话信息保存在服务端,key 值是随机产生的字符串,value 值是 session 的内容,依赖于 cookie 将每个用户的随机字符串保存到用户浏览器中。
69. beautifulsoup 模块的作用
BeautifulSoup 库是解析、遍历、维护“标签树”的功能库。
url = "http://www.baidu.com/"
request = requests.get(url)
html = request.content
soup = BeautifulSoup(html, "html.parser", from_encoding="utf-8")
70. Selenium 模块简述
Selenium 是模拟操作浏览器的库,可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生等。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source) # browser.page_source 是获取网页的全部 html
browser.close()
The End!
怎么样,今天的货是不是很干啊,还不给个“在看”嘛!

人生苦短,我用python