详解 CQRS 架构模式
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」

从一开始,软件系统就被用于各种用途,针对它们的需求也随着时间的推移而增长。需求的变更可能与业务逻辑、伸缩性或系统的其他方面有关。
为了满足这些相互矛盾或重叠的需求,工程师必须在设计系统时做出各种各样的权衡。问题在于,很多权衡在一开始并不是必需的,而当需要做出权衡时,系统已经演变成到无法做出权衡的地步。
在我看来,最有害的设计锁定通常发生在数据层。在设计典型的应用程序数据模型时,通常会结合考虑领域知识与性能因素。领域知识规定了实体是什么以及它们在逻辑上如何相互关联,性能因素决定了它们是如何在物理层面实现的(例如:采用关系型数据库还是 NoSQL 数据库、主键、索引等)。这两个方面的选型让应用程序能有效地为目标场景提供服务。

数据及其不同的视图
在拥有大量数据和复杂实体模型的大型应用程序中,一些实现细节随着时间推移变成了“核心”部分。有时候,这些东西是工程师在很明确的情况下完成的,但更多的是以一种隐式甚至是无意的方式发生。于是,新需求可能与现有的实现不一致,以至于根本无法很好地容纳它们。
这类问题在不同的情况下需要不同的解决方案。在本文中,我将重点关注一种情况,即从应用程序读取数据的方式与向系统写入数据的方式非常不同时所出现的问题。这里的不同点可以是指查询模式、输出格式或规模方面的不同。
我在这篇文章里写了自己所遇到的这种情况。我当时正在开发的订单管理系统使用了实体 ID (订单 ID、商品 ID 等),但是随着时间推移,出现了一些复杂的读取需求,我们的数据模型无法支持这些需求。问题出在两个方面:
一方面,现有的实现很难有效地满足新的查询模式。另一方面,订单数据的读取方希望有一种截然不同的数据模型。例如,电子商务平台上的卖家希望他们的大客户数据切片能以特定的方式来呈现,而面向客户的应用程序希望数据看起来与购物车中的样子一样。
这种情况并不少见,特别是对于拥有核心实体的系统。它们封装的数据被广泛使用,因此需要提供多种不同的格式。
那么,我们该如何弥合这一鸿沟?
CQRS
CQRS 是“命令查询责任分离”(Command Query Responsibility Segregation)的缩写。在基于 CQRS 的系统中,命令(写操作)和查询(读操作)所使用的数据模型是有区别的。命令模型用于有效地执行写/更新操作,而查询模型用于有效地支持各种读模式。通过领域事件或其他各种机制将命令模型中的变更传播到查询模型中,让两个模型之间的数据保持同步。
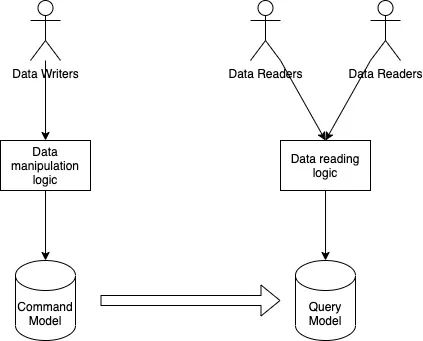
如果你觉得它们看起来就像是两个不同的微服务,那么我来说一说它们之间的一个细微区别。从物理实现层面来看,这两个数据模型可以作为两个独立的微服务,甚至可以用一个命令模型来支持多个查询模型。但是,微服务架构的一个关键构造是两个微服务通常代表两个独立的领域,而在 CQRS 中,无论运行时架构是怎样的,命令模型和查询模型都属于同一逻辑领域。如果查询模型对命令模型一无所知,就无法发挥作用。这里的耦合是预期的,不同于微服务之间的解耦行为。
CQRS 并没有规定这两个模型如何保持同步。同步可以通过同时更新两个模型来同步实现,也可以通过消息代理(如 Kafka)将命令从命令模型传输到查询模型来异步实现。后一种比较常用,因为它让系统更加可伸缩,尽管它需要在写操作和读操作的最终一致性方面做出权衡。

这不就是缓存吗?
只用于读取的数据模式看起来就像是一个缓存。事实上,查询模型可以使用 Redis 这样的缓存技术来实现。但是,CQRS 不只是为了分离数据的写入和读取,它的根本目的是为了实现数据的多重表示,每一种表示都能够满足某些用户的需求。CQRS 可能会有多种查询模式,每个模式可能使用不同的物理实现。有些可能使用数据库,有些可能使用 Redis,等等。
什么时候应该使用 CQRS
对于一部分场景,CQRS 是一种非常有用的架构模式。
第一个是我在前面已经提到过的。如果同一个数据模型不能有效地满足系统的读和写模式,那么通过应用 CQRS 来解耦读写是很有意义的。解耦后的数据模型可以满足特定的需求。CQRS 有效地将单个数据表示变成任意数量的(读)表示,所有这些表示都与负责处理所有更新的核心表示保持一致。
适用 CQRS 的第二个场景是将读负载与写负载分开。前面我讲了缓存和 CQRS 的区别,缓存并不是应用 CQRS 的目的。但是,通过分离命令模式和查询模式,就有了对单个模式进行伸缩的可能性。查询模型可以有自己的数据库和缓存,可以使用最适合某些特定场景的技术来实现。但不管怎样,命令模型的伸缩都不会受制于查询模型。我在这里需要重申的是,它们不是独立的系统,尽管它们之间有深度的耦合,但这不是问题。
什么时候不该使用 CQRS
在系统中使用 CQRS 会带来显著的认知负担和复杂性。开发人员必须面对至少两个数据模型和多种技术选择,所有这些都是不可忽略的负担。
第二个问题是如何保持命令模型和查询模型的数据同步。如果选择了异步方式,那么整个系统就要承担最终一致性所带来的后果。这可能非常麻烦,特别是当用户希望系统能够立即反映出他们的操作时,即使是单个一致性要求也会危及整个系统的设计。
如果我们选择让模型在任何时候都保持一致,就会有 CAP 和两阶段提交问题。如果两个模型使用同一个支持 ACID 的数据库,我们可以通过事务来保持它们的一致性,但 CQRS 的很多可伸缩性优势就发挥不出来了。如果要支持多个查询模型,写操作将会越来越慢,因为需要更新所有的查询模型。
因为这两个问题的存在,在选择是否使用 CQRS 时就要十分谨慎。如果使用得当,它可以极大提升应用程序的伸缩性。但是,支持多个数据模型并不是件容易的事,所以应该只在没有其他方法可以满足要求时才考虑这么做。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈