
6000字!SQL窗口函数详解。
今天想重提窗口函数。原因是前几天在群里提起了这个名字,忘了是什么缘由提起的,但令我吃惊的是,竟还有同学想从事数据分析却不知道窗口函数!那感觉就仿佛用勺子吃面条不知道有筷子这种好东西一样。
他问:“有没有大佬简单说下窗口函数是个什么东西?”
胖里:不减少原表行数情况下,对数据进行分组排序。
阿鑫:在SQL中窗口函数可以对数据进行同步处理,where和group by处理后进行操作,只能写在select子句中。
其他:百度吧,知乎看一下。
然后我去翻了翻公众号之前关于窗口函数的文章,我以为自己对这部分内容已经了解和解释的挺清楚了,无论是用法还是实例。但我翻完才发现,好像并没有对窗口函数下定义,其他人的很多文章也大都没对窗口函数的定义进行描述,都从窗口函数有什么用,怎么用,举例子开始。
窗口函数到底是什么呢?
01
窗口函数是什么
我拿这个问题去问交流群里的小伙伴,得到了如下一些回答。
A:处理分析的函数,类似于聚合函数?
B:用于解决组内排序、聚合等运算且只能写在select字句中的函数。
C:窗口函数可以切分小组,并在小组内实现排序、聚合等数据处理操作。
D:窗口函数的含义就像它的名字,开一个窗子,在不影响房屋原来结构的基础上从自己想要的角度观察内部关系。
E:窗口函数类似于聚合函数。区别是聚合函数对每组只返回一个值,窗口函数返回多个值,也就是说对组里的每条记录都会产生返回值~
每个人都讲出了自己的理解,每个人理解的也都没什么问题。在我看来,窗口函数无非就是一种略高级的操作,能划分范围(组),对这一范围内的数据进行某种处理,可以是聚合,可以是排序、也可以是求第一个记录、最后一个记录等。它有其高级之处,也有用法上的某些限制。
窗口函数,也称为OLAP(Online Analytical Processing)函数,之所以叫窗口函数是为了便于形成直观印象,易于理解(虽然可能对一些同学而言,并没有那么容易理解。)
如上便是窗口函数的定义,要想理解窗口函数从定义上是远远不够的,最好能从窗口函数的语法及其实例来理解。
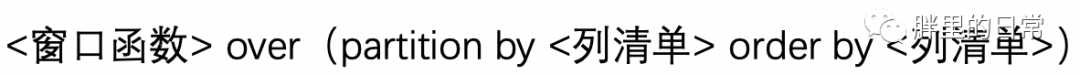
上图便是窗口函数的语法了,你可以将其看作一种固定搭配,填充进去不同的窗口函数、指定列,即可实现对应函数能实现的操作。
这其中最重要的关键字便是partition by和order by,partition by用来圈定所要进行操作的对象的范围,order by用来指定按照哪列、何种顺序进行排序。通过partition by分组后的记录集合叫做窗口,此处的窗口表示范围,这也是窗口函数名字的由来。
但partition by并非必需,不使用partition by也可正常使用窗口函数,只不过此时等于不分组,将整张表作为一个大窗口而已。
02
窗口函数的分类
说完窗口函数的语法,不妨来看看常用/常见的一些窗口函数及其分类。
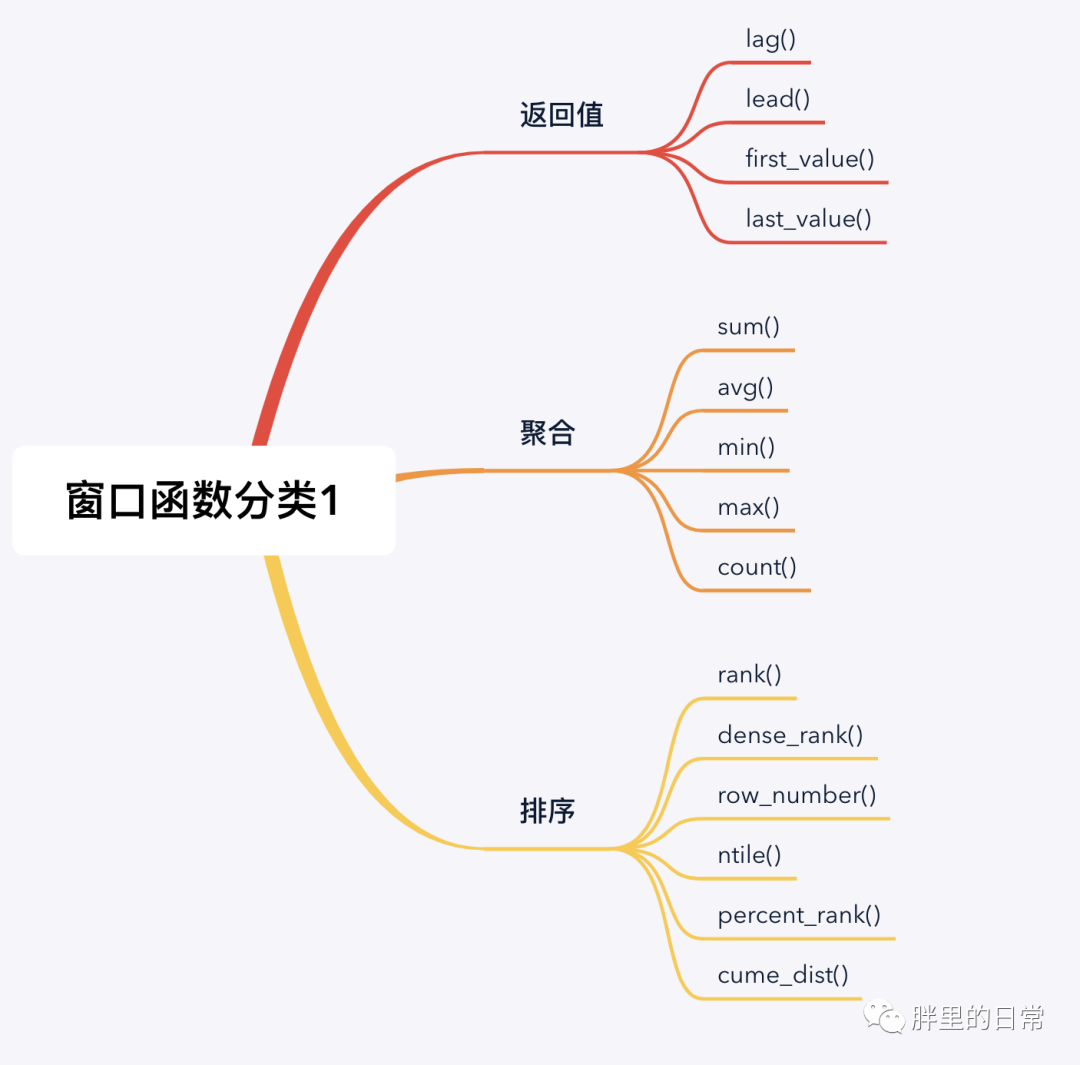
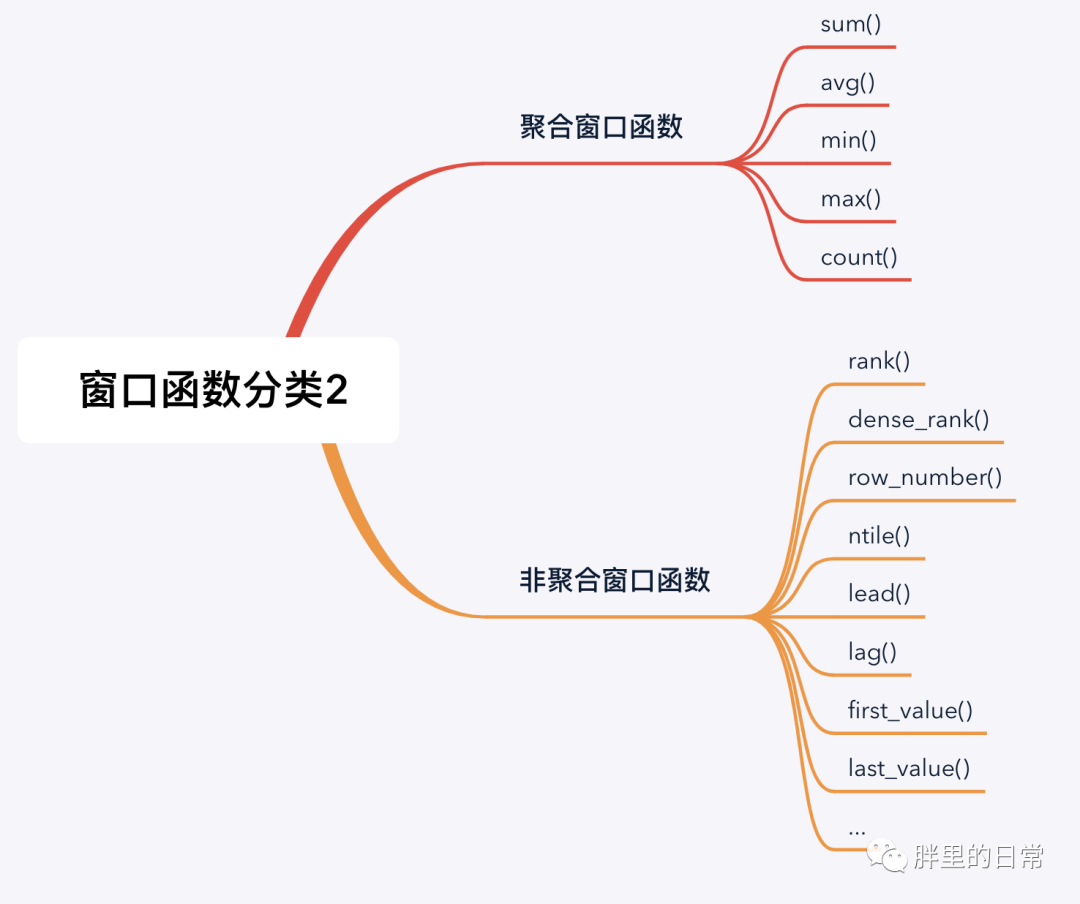
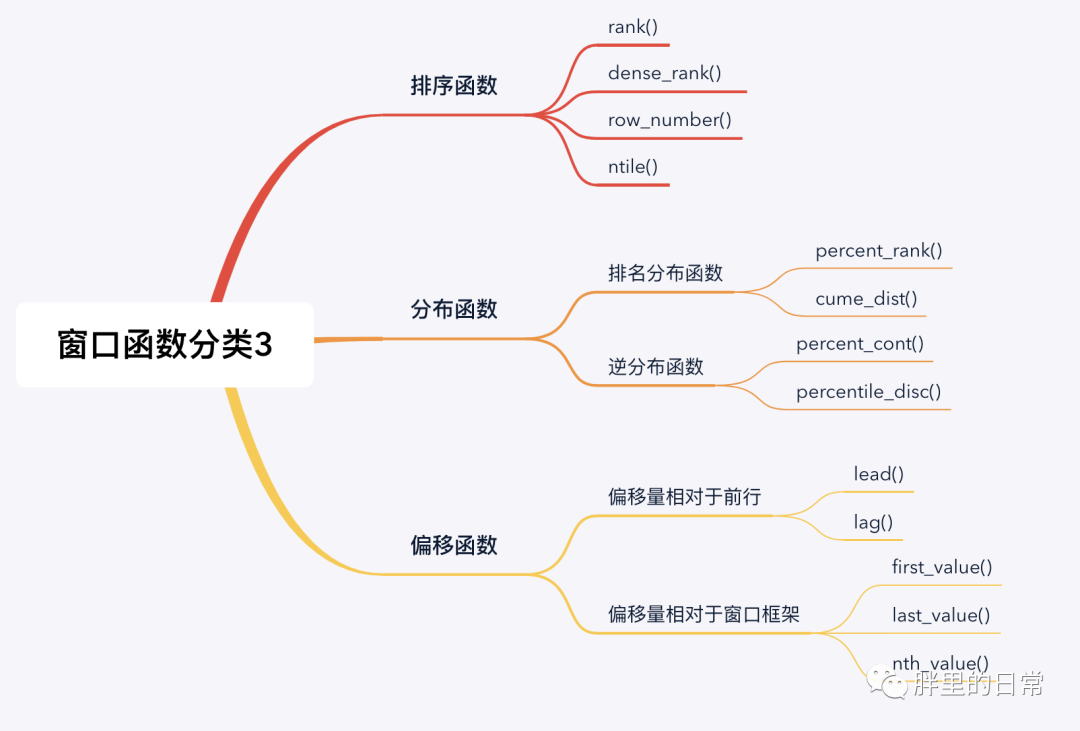
下图中罗列了三种窗口函数的分类,其实分类这种东西,都是主观上按照某些客观规则划分的,划分的人不一样也就形成了不同或不同粒度的规则。
窗口函数可归为两大类,聚合类窗口函数和非聚合类窗口函数(也可称为专用窗口函数)。聚合类窗口函数是将我们常用的聚合函数作为窗口函数使用,非聚合类窗口函数指一些规定好的窗口函数,按照其不同的功能进行定义和划分,如常见的排序函数、分布函数和偏移函数。
注意,有的窗口函数是带参数的,有的不带参数,如sum(amt)、lead(time)、rank()、row_number()。
其实我们可能并不需要知道所有的窗口函数,我这水平目前也只知道聚合、排序、返回值的几个函数,一些是因为面试常考他们的相同和不同点,一些是业务或笔试题中会用得到。这些函数基本懂一部分就够用了,其他需要的可以根据需求再进行查询、学习和使用。
03
窗口函数的应用
笼统地介绍完一些常见的窗口函数,还是好好说说其中一些函数的用法吧。
先来几个简单的示例,初步了解下窗口函数的使用。
下表为某公司在各地区不同月份的销售额记录表,sales_table(虚构数据)。
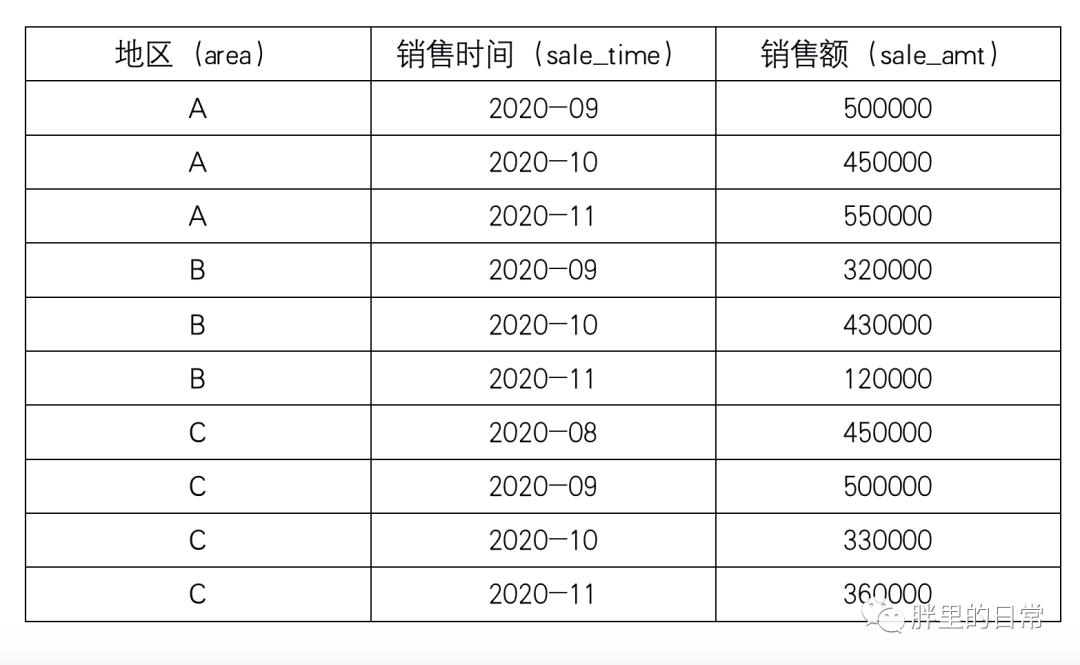
题目1:求取每个地区的销售额(以表内所示月份为例)
select area,sum(sale_amt) -- 每地区总销售额from sales_tablegroup by area;
这个题目算是在学习SQL基础的时候比较简单且常见的题目了吧,毫无难度的那种,求某个分组的和,group by,sum()一下就OK了。
题目2:求每个地区每月销售额占比,以及月累积销售额占比
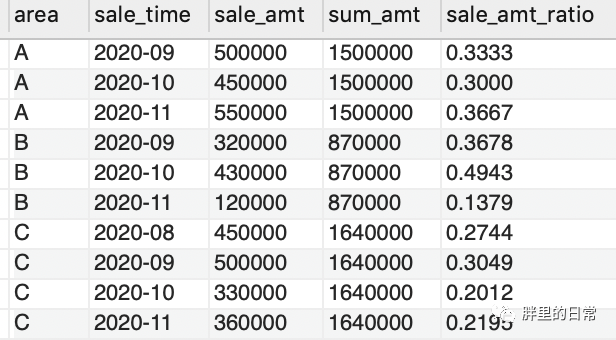
按之前分组求sum(),只能得到每个地区对应的总销售额,分别为1500000、870000、1640000,而每个地区每月销售额占比就得实现500000/1500000,450000/1500000等操作了,此结果也可通过先求每地区的总销售额然后表关联进行字段间的除法操作,不过有了窗口函数,一切便变得简单了些。
select *,sale_amt/sum_amt as sale_amt_ratio -- 每地区每月销售额占比from(select *,sum(sale_amt) over(partition by area order by area) as sum_amtfrom sales_table)as t
用sum()聚合函数作为窗口函数,使用partition by area将地区作为分组,在地区内求得每个地区的总销售额,此处order by由于语法原因,不可缺,但由于分组后的地区只有自己本身这个地区,所以此处的order by无实际意义。
结果如下所示,求得了每个地区每月销售额占比:
那累积销售额占比呢?还是可以用sum()聚合函数做窗口函数,分组依旧是按照地区进行分组,但累积销售额就牵扯到时间先后了,因此要学会善用order by对日期进行排序,才能求得真正时间顺序上的累积销售额。
select *,agg_amt/sum_amt as agg_sale_amt_ratio -- 每地区月累积销售额占比from(select *,sum(sale_amt) over(partition by area order by sale_time) as agg_amt -- 每地区月累积销售额,sum(sale_amt) over(partition by area order by area) as sum_amt -- 每地区总销售额from sales_table)as t
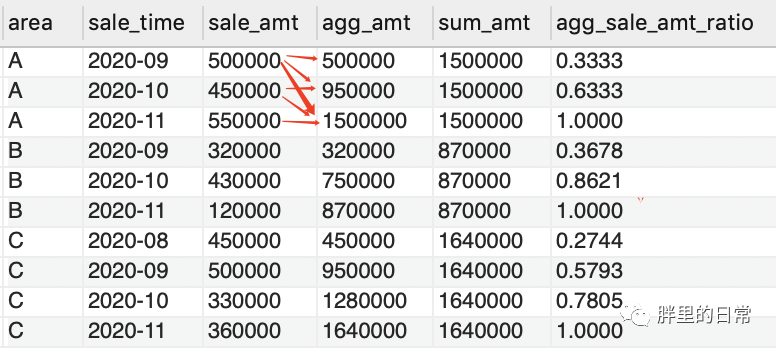
经过上述这番操作,应该初步认识到窗口函数所谓的高级及实用之处了吧,无非就是将原先需要各种分别求取再join的操作,通过窗口函数的应用在多个子查询中实现。上述的两个sum()窗口函数能同时求取,放在一个子查询内,也就是说一个select子句中可有多个窗口函数。
注意:求累积的时候不仅可以实现上述的按月累积,也可实现限定的按前/后/前后几个月累积,毕竟有时候有些需求是从头到尾累积,而有的是要求前后共三个月的累积。
这时候用来在窗口中指定更加详细汇总范围的功能便出现了,此功能中的汇总范围叫做框架,使用方法就是在order by子句后使用用来指定范围的关键字following和preceding。
举个小例子。
select *,sum(sale_amt) over(partition by area order by sale_time rows between 1 preceding and 1 following) as agg_amt -- 当前行及其前一行和后一行from sales_table;select *,sum(sale_amt) over(partition by area order by sale_time rows 1 preceding) as agg_amt -- 当前行及其前一行from sales_table;-- mysql单独运行following时报错,未解,但可使用rows between 0 preceding and 1 following来替代select *,sum(sale_amt) over(partition by area order by sale_time rows 1 following) as agg_amt -- 当前行及其后一行from sales_table;
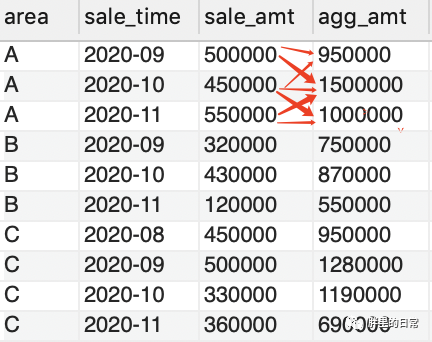
上述例子即为指定更详细的汇总范围了,preceding指前多少行,following指后多少行,然后再加上当前的行,如rows between 1 preceding and 1 following 表示前一行、后一行加当前行,共三行。
题目3:求每个地区各个月销售额排名情况
说到排名,应该能想到排序吧,如果没接触过窗口函数想要比较大小,你们都会用什么方法呢?对于排序,我首先想到的就是order by了,order by不就是用来排序的吗?能实现顺序排列,但只是不打标,记录数太多可能就不知道有多少名了,除此之外我满脑子都是各种表的关联、对比。
不想那么复杂的话,就试试窗口函数中用于排序的函数吧。说到排序的窗口函数,不少人应该都知道rank(),dense_rank(),row_number(),除了在笔试题中考到用他们来排序,面试也常问这三者的区别是什么。
select *,row_number() over(partition by area order by sale_amt desc) as rnkfrom sales_table;
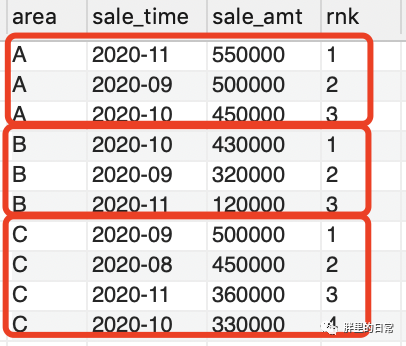
使用窗口函数,轻松实现按地区分组,对每个月的销售额进行排序打标,一目了然,不仅可以排序,设想一下这种情况,你们公司的数据库表里不仅只有这10条数据,而是有成百上千甚至上万条数据,老板让你看看每个地区销售额最高的2个月份是哪两个,你总不至于分别求取吧,一个排序窗口函数就能解决的问题,何乐而不为?
此处我只用了我最常用的row_number()来实现,针对不同的排序要求,可选择不一样的排序函数,这三种排序函数不太清楚的自己回去反思吧。
有一张表log_table,其中包括用户id(user_id)及访问时间(visit_time)两个字段。
题目4:每天随机取1000个用户
select user_id,visit_timefrom(select user_id,visit_time,row_number() over(partition by visit_time order by rand()) as rnkfrom log_table)as twhere rnk <= 1000;
当然,这个题目,不使用窗口函数依旧也可以通过order by rand()实现。
题目5:每天随机取10%个用户
select user_id,visit_timefrom(select user_id,visit_time,percent_rank() over(partition by visit_time order by rand()) as rnk_ratiofrom log_table)as twhere rnk_ratio <= 0.1;
当然,这个题目也可以不用窗口函数,通过计算用户总数,再随机取用户总数的10%。
不尽兴的话,可以再来一张用户表user_table,里面存储了某平台某天的活跃用户user_id,且不重复。
题目6:将用户随机分成10组,每组取1000个用户。
select user_idfrom(select user_id,n_rnk,row_number() over(partition by n_rnk order by rand()) as rnkfrom(select user_id,ntile(10) over(order by rand()) as n_rnkfrom user_table)as t1)as t2where rnk <= 1000;
随机分十组,用窗口函数的ntile()可以实现分桶(分组功能),再使用一次排序,随机从每组中选出1000个用户。
题目7:将用户随机分成100组,每组取10%个用户
这个题目的答案就显而易见了吧。
上述几个简单的示例是为了说明窗口函数的用法及其意义所在,使用窗口函数可能会使解决问题的过程变得更简单,对窗口函数的熟悉和理解可以帮助我们在之后遇到问题的时候,虽然是取数,但可以更有针对性、更高效地取数。
除上述一些简单示例外,笔面试中常考的需要用窗口函数解决的问题一般包括topn问题、连续登录问题。这两种题目面试中问到的频率特别高,前几天群里有个小伙伴就说被问到了,但一时想不出如何解。
想来还是对窗口函数不熟悉吧,哪一类的问题涉及到什么关键字,应该用哪种函数解决,这些虽然在各种文章中频被提及,但你如何理解,是否真正理解且能应用,就是个人的问题了。
这些题目我就不多提了,之前转的宝器的这篇文章中早就讲过一遍了,文章在这:解一下TMD几道热门数据分析面试题。

推荐阅读
欢迎长按扫码关注「数据管道」