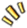使用 Node.js 实现文件流转存服务
作者:董天成
原文地址: https://zhuanlan.zhihu.com/p/25367269
Buffer
Stream
setTimeout/setInterval
promise
使用递归的Promise来进行流程控制
本文章所有的例子都采用 ES6 编写,可以直接用node version 6.x 以上直接运行,低版本的 node 可以使用 babel 或者 typescript 编译器编译之后再运行。
本文相关的转存服务代码,单元测试代码,以及测试服务代码都在文章底部。
什么是转存服务
相信很多同学都用过一个服务叫做图片转存服务:即向服务器发送一个图片的url地址,服务负责去将图片下载到服务器上,之后再将这个图片上传到存储服务,得到一个可以访问(通常情况都是CDN服务)的图片地址。
但是类似这样架构的服务有一个软肋—— 对于超大的文件,性能会明显不足。
转存服务在下载文件的时候,二进制会先写入本地硬盘上的缓存文件中,当文件下载完成之后,再进行上传操作。但是对于大文件上传和转存,这个过程将会非常耗时。而且,大文件如果直接一次性上传,也会导致非常高的失败率。
在上传这地方,业内通常是采用分片上传来进行解决。
分片上传一般是将一个大文件划分成多个分片,然后通过并行或者串行的方式依次上传至服务器端。
如果文件上传失败,只需要再重新上传失败的分片即可。
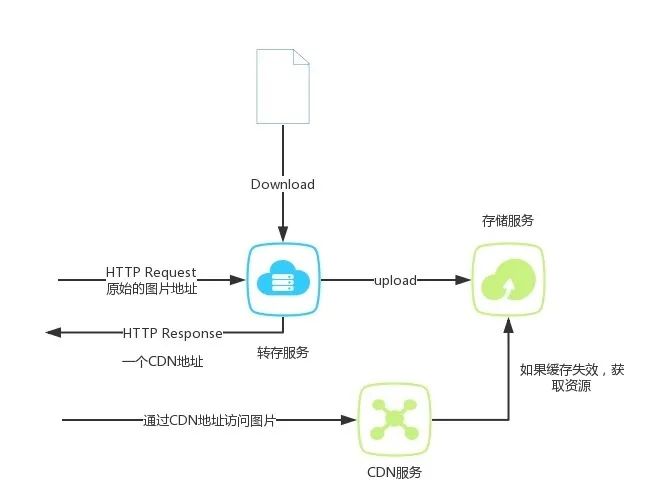
什么是文件流转存服务
分片上传解决了上传可靠性和性能上的问题,但是上传依然需要等待整个文件都下载完成才能触发,
而一个大文件的下载需要很多时间,这依然会造成转存一个大文件时间过长的问题。
如果能够在下载到的数据量满足上传一个分片的时候就直接将分片上传到接收分片的存储服务,那是不是就可以达到速度最快,实现文件流转存服务。
捕获下载到的数据内容
流转存服务实现的第一步即是捕获下载到的内容。Node.js中的stream模块可以很方便的进行文件的处理,Readable的Stream在接收到数据之后,会不断的触发data事件。通过监听Readable的Stream的data事件即可准确获取到每一次通过Stream进行传输的数据。
由于数据来源是通过网络下载,而且request模块返回的同样也是Readable的Stream对象。
当具备了Readable的Stream之后,只需要创建一个Writable就能数据流动起来,它们之间通过pipe函数进行联接。
'use strict';
let request = require('request');
let fs = require('fs');
let httpStream = request({
method: 'GET',
url: 'https://baobao-3d.bj.bcebos.com/16-0-205.shuimian.mp4'
});
// 由于不需要获取最终的文件,所以直接丢掉
let writeStream = fs.createWriteStream('/dev/null');
// 联接Readable和Writable
httpStream.pipe(writeStream);
let totalLength = 0;
// 当获取到第一个HTTP请求的响应获取
httpStream.on('response', (response) => {
console.log('response headers is: ', response.headers);
});
httpStream.on('data', (chunk) => {
totalLength += chunk.length;
console.log('recevied data size: ' + totalLength + 'KB');
});
// 下载完成
writeStream.on('close', () => {
console.log('download finished');
});
运行过程中会看到命令行不断刷出 recevied data size: xxx KB,直到文件下载完毕,触发close事件。
分片的缓冲
每次data事件的触发,获取到的chunk大小取决于当前的网络环境,假设我们设置分片上传的时候每个分片的固定大小为2MB。但是每次捕获到的分片有可能会大于2M,也有可能会远远小余2M。有的时候下载会比上传速度要快,如何能更稳定更可控的让上传能持续下去,而不会收到下载速度的影响。所以我们需要在上传和下载之间加一个缓冲区。
让下载到的数据无论大小,快慢,统统扔到缓冲区中。而上传只需要定时定量从缓冲区获取数据,
这样双方之间就互不影响了。
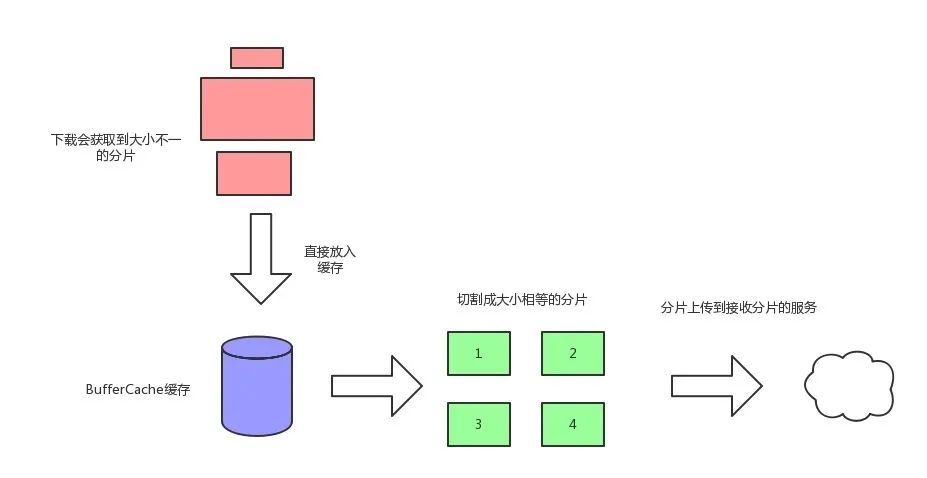
Node.js使用Buffer对象来描述一块数据对象,上一节中每次data事件触发的时候,回调函数的第一个参数的值就是一个Buffer对象。Buffer对象的prototype属性中有一些非常类型数据方法的函数,如slice,concat,使用方式也和数组方法类型。
于是我们可以实现下面这个类,用于控制缓冲区,方面塞入数据和获取切片。
/**
* @file 视频下载缓冲区
*/
class BufferCache {
constructor (cutSize = 2097152) {
this._cache = Buffer.alloc(0);
this.cutSize = cutSize;
this.readyCache = []; // 缓冲区
}
// 放入不同大小的buffer
pushBuf (buf) {
let cacheLength = this._cache.length;
let bufLength = buf.length;
this._cache = Buffer.concat([this._cache, buf], cacheLength + bufLength);
this.cut();
}
/**
* 切分分片,小分片拼成大分片,超大分片切成小分片
*/
cut () {
if (this._cache.length >= this.cutSize) {
let totalLen = this._cache.length;
let cutCount = Math.floor(totalLen / this.cutSize);
for (let i = 0; i < cutCount; i++) {
let newBuf = Buffer.alloc(this.cutSize);
this._cache.copy(newBuf, 0, i * this.cutSize, (i + 1) * this.cutSize);
this.readyCache.push(newBuf);
}
this._cache = this._cache.slice(cutCount * this.cutSize);
}
}
/**
* 获取等长的分片
* @returns {Array}
*/
getChunks () {
return this.readyCache;
}
/**
* 获取数据包的最后一小节
* @returns {*}
*/
getRemainChunks () {
if (this._cache.length <= this.cutSize) {
return this._cache;
}
else {
this.cut();
return this.getRemainChunks();
}
}
}
module.exports = BufferCache;
对于下载收到的不定长的buffer,都统统调用pushBuf方法保存,pushBuf方法每次都会将缓存拼接成一个原始的数据段,并每次调用cut方法,从整个数据段中切分出一块块规整的数据块,存储在一个栈中,等待获取。
如何连续写入缓存
由于Readable的Stream的data事件会在stream收到数据的时候反复进行触发,数据下载完毕又会触发close事件。所以我们通过Javascript的函数将捕获下载内容的代码封装成一个函数。
'use strict';
let request = require('request');
let fs = require('fs');
// 引入缓存模块
let BufferCache = require('./bufferCache');
const chunkSplice = 2097152; // 2MB
let bufferCache = new BufferCache(chunkSplice);
function getChunks(url, onStartDownload, onDownloading, onDownloadClose) {
'use strict';
let totalLength = 0;
let httpStream = request({
method: 'GET',
url: url
});
// 由于不需要获取最终的文件,所以直接丢掉
let writeStream = fs.createWriteStream('/dev/null');
// 联接Readable和Writable
httpStream.pipe(writeStream);
httpStream.on('response', (response) => {
onStartDownload(response.headers);
}).on('data', (chunk) => {
totalLength += chunk.length;
onDownloading(chunk, totalLength);
});
writeStream.on('close', () => {
onDownloadClose(totalLength);
});
}
function onStart(headers) {
console.log('start downloading, headers is :', headers);
}
function onData(chunk, downloadedLength) {
console.log('write ' + chunk.length + 'KB into cache');
// 都写入缓存中
bufferCache.pushBuf(chunk);
}
function onFinished(totalLength) {
let chunkCount = Math.ceil(totalLength / chunkSplice);
console.log('total chunk count is:' + chunkCount);
}
getChunks('https://baobao-3d.bj.bcebos.com/16-0-205.shuimian.mp4', onStart, onData, onFinished);
通过3个传入的回调函数,我们就能很容易的掌控:第一个收到请求时触发的操作,连续不断收到数据时触发的操作和下载完毕时触发的操作。有个这个函数,我们就只需要在接收数据的回调函数中将buffer都通过pushBuf函数写入缓存即可。
准备发送
目前下载数据包和缓存都已经准备就绪,接下来就是准备进行发送分片的操作了。但是,还依然存在以下问题:
如何连续不断的从缓存中获取分片
如何发送分片
单个分片如果上传失败,如何重试
如何在所有分片都上传完成之后触发一个回调
如何实现多个分片并行上传
下面将逐步讲解思路,并提供相关实现代码。
连续不断获取分片
连续不断的获取分片,实现上需要一个定时器来不断的从缓存中获取分片。
Javascript为我们提供好了简单易用的定时器,setTimeout和setInterval。每次回调函数的触发都是在上一个时间周期完成之后运行。这样的机制能保证每次触发setTimeout的时候,缓存中或少能塞进一部分数据进去。
当onStart函数触发时,就预示着下载已经开始了,这个时候就可以开始进行获取分片了。
通过setInterval,设定一个200ms的时间间隔,在每一次时间间隔内通过bufferCache.getChunks()方法获取已经切分好的分片。
最后一个分片是个特殊的情况,一个文件在经过多次相同大小的切割之后,总会遗留下小的一块分片,因此我们还需要对最后一个分片进行特殊处理。当readyCache的长度为0的时候,而且下载已经完成,不会再调用pushBuf函数,就是获取最后一段分片的时机。
function onStart(headers) {
console.log('start downloading, headers is :', headers);
let readyCache = bufferCache.getChunks();
let sendTimer = setInterval(() => {
if (readyCache.length > 0) {
let receivedChunk = readyCache.shift();
console.log('received Chunk', receivedChunk);
}
else if (isFinished) {
clearTimeout(sendTimer);
console.log('got last chunk');
let lastChunk = bufferCache.getRemainChunks();
console.log('the last chunk', lastChunk);
}
}, 200);
}
如何发送分片
使用HTTP进行文件上传,文件在传输过程中为一个byte序列,其content-type为multipart/form-data; boundary=----WebKitFormBoundarymqmPgKAUm2XuWnXu, boundary 是作为一个特殊的字符串来对发送的数据包进行分割。上传的数据中即可以包含二进制文件的byte流,也可以包含常规的字符串键值对。
在浏览器上,上传一个图片的数据格式:
同样,nodejs的request模块也实现了和浏览器一样的上传文件协议,所以我们可以先通过Promise封装一个上传函数
function upload(url, data) {
return new Promise((resolve, reject) => {
request.post({
url: url,
formData: data
}, function (err, response, body) {
if (!err && response.statusCode === 200) {
resolve(body);
}
else {
reject(err);
}
});
});
}
发送分片的时候,需要间歇不断的处理2件事情:
从缓存中拿出分片,直到拿完了,告知发送端已经到底了
发送分片,发送成功,还有分片,继续发送,直到分片都拿完了
对于这样的逻辑,我们可以考虑使用递归来发送分片,函数的参数传入readyCache的引用。
每次调用函数,都通过引用从readyCache中把队列最前面的分片拿出,再进行分片发送,如果分片上传成功,
再进行递归,依然传入readyCache的引用,直到readyCache的长度为0。
由于我们在发送的时候,使用了setInterval不断轮询,当前轮询的周期为200ms。
假设当前网络环境拥堵,会导致上传一个分片的时间 > 200ms, 200ms之后下一次轮询开始运行时,原先的分片还没上传完毕,由于没有一个状态值进行判断,依然会调用上传函数,又再一次进行分片上传,就会更加剧的网络拥堵环境,导致分片上传时间更短。如此反复,时间一长就会导致崩溃,造成分片上传全部大面积失败。
为了避免这样的情况,我们就需要一个变量来表示当前这个上传流程的状态,目前我们只关心单个流程进行上传,可以只需要保证最大同时上传的值为1即可。
function sendChunks() {
let chunkId = 0; // 给每个分片划分ID
let sending = 0; // 当前并行上传的数量
let MAX_SENDING = 1; // 最大并行上传数
function send(readyCache) {
// 在并行上传会用到,
if (readyCache.length === 0) {
return;
}
let chunk = readyCache.shift();
// 测试使用的服务,用于接收分片
let sendP = upload('http://localhost:3000', {
chunk: {
value: chunk,
options: {
// 在文件名称上添加chunkId,可以方便后端服务进行分片整理
filename: 'example.mp4_IDSPLIT_' + chunkId
}
}
});
sending++;
sendP.then((response) => {
sending--;
if (response.errno === 0 && readyCache.length > 0) {
// 成功上传,继续递归
send(readyCache);
}
});
chunkId++;
}
return new Promise((resolve, reject) => {
let readyCache = bufferCache.getChunks();
let sendTimer = setInterval(() => {
let readyCache = bufferCache.getChunks();
if (sending < MAX_SENDING && readyCache.length > 0) {
send(readyCache);
}
// 如果isFinished 不为true的话,有可能是正在下载分片
else if (isFinished && readyCache.length === 0) {
clearTimeout(sendTimer);
let lastChunk = bufferCache.getRemainChunks();
readyCache.push(lastChunk);
send(readyCache);
}
// 到这里是为分片正在下载,同时又正在上传
// 或者上传比下载快,已经下载好的分片都传完了,等待下载完成
}, 200);
});
}
function onStart(headers) {
// console.log('start downloading, headers is :', headers);
sendChunks();
}
单个分片如果上传失败,如何重试
到目前为止,分片上传已经初步完成,但仅仅是初步完成。因为如果上面的代码能连续稳定运行十几年不出bug,是建立在以下情况的:接收端超稳定,无论多少分片,多大速率,返回一律成功
但是现实是残酷的,当数量和频率增加的时候,总会有分片上传失败,从而导致正在文件都上传失败。
因此我们需要让分片上传都具备重试功能。
在发送分片的时候,send函数可以当成是发送单个分片的一个控制器,如果分片发送失败,最容易捕获并重试的地方就应该在send函数内部,所以当错误发生时,只需将原先的数据保存下来,然后再一次调用send函数就能进行重试操作。
这样的逻辑,我们可以简化成下面这段JS代码。
let max = 4;
function send() {
return new Promise((resolve, reject) => {
if (max > 2) {
reject(new Error('error!!'));
}
else {
resolve('ok');
}
}).catch(() => {
max--;
return send();
});
}
send().then(() => {
console.log('finished');
}).catch(() => {
console.log('error');
});
当Max > 2的时候,Promise就会返回异常,所以在最初的2次调用,Promise都会触发catch函数。不过在每次catch的时候,再递归函数,之前错误的Promise就能够被递归创建的新的Promise处理,直到这个Promise能够成功返回。我们只需简单控制max的值,就能控制处理错误的次数。这样就能将错误重试控制都包含在send函数内部。
所以我们也可以使用这样的逻辑来进行分片的发送,当请求出现错误的时候,在catch函数内判断重试次数,次数若大于0,则再返回一个递归的send函数,直到次数等于0,直接用Promise.reject将异常抛出Promise。
如果接收服务一直存在问题,导致多次上传全部失败的话,需要直接终止当前问题,于是我们还需要一个变量stopSend,用于在多次错误之后,直接停止上传。
function sendChunks() {
let chunkId = 0;
let sending = 0; // 当前并行上传的数量
let MAX_SENDING = 1; // 最大并行上传数
let stopSend = false;
function send(options) {
let readyCache = options.readyCache;
let fresh = options.fresh;
let retryCount = options.retry;
let chunkIndex;
let chunk = null;
// 新的数据
if (fresh) {
if (readyCache.length === 0) {
return;
}
chunk = readyCache.shift();
chunkIndex = chunkId;
chunkId++;
}
// 失败重试的数据
else {
chunk = options.data;
chunkIndex = options.index;
}
sending++;
let sendP = upload('http://localhost:3000', {
chunk: {
value: chunk,
options: {
filename: 'example.mp4_IDSPLIT_' + chunkIndex
}
}
}).then((response) => {
sending--;
let json = JSON.parse(response);
if (json.errno === 0 && readyCache.length > 0) {
return send({
retry: RETRY_COUNT,
fresh: true,
readyCache: readyCache
});
}
// 这里一直返回成功
return Promise.resolve(json);
}).catch(err => {
if (retryCount > 0) {
// 这里递归下去,如果成功的话,就等同于错误已经处理
return send({
retry: retryCount - 1,
index: chunkIndex,
fresh: false,
data: chunk,
readyCache: readyCache
});
}
else {
console.log(`upload failed of chunkIndex: ${chunkIndex}`);
// 停止上传标识,会直接停止上传
stopSend = true;
// 返回reject,异常抛出
return Promise.reject(err);
}
});
}
return new Promise((resolve, reject) => {
let readyCache = bufferCache.getChunks();
let sendTimer = setInterval(() => {
if (sending < MAX_SENDING && readyCache.length > 0) {
// 改用传入对象
send({
retry: 3, // 最大重试3次
fresh: true, // 用这个字段来区分是新的分片,还是由于失败重试的
readyCache: readyCache
}).catch(err => {
console.log('upload failed, errmsg: ', err);
});
}
else if (isFinished && readyCache.length === 0 || stopSend) {
clearTimeout(sendTimer);
// 已经成功走到最后一个分片了。
if (!stopSend) {
let lastChunk = bufferCache.getRemainChunks();
readyCache.push(lastChunk);
send({
retry: 3,
fresh: true,
readyCache: readyCache
}).catch(err => {
console.log('upload failed, errmsg: ', err);
});
}
}
// 到这里是为分片正在下载,同时又正在上传
// 或者上传比下载快,已经下载好的分片都传完了,等待下载完成
}, 200);
});
}
在错误模拟上面,我们可以在在测试的server上加了几行代码来模拟上传失败的情况,当第二个分片到达的时候,一定会失败。之后我们得到的日志如下:
// 错误处理测试使用
if (chunkIndex == 1) {
console.log(`set failed of ${chunkIndex}`);
this.status = 500;
return;
}
server端得到的日志如下:
<-- POST /
uploading example.mp4_IDSPLIT_0 -> /Users/baidu/baiduYun/learn/koa-example/receive/example.mp4/0
--> POST / 200 93ms 25b
<-- POST /
set failed of 1
--> POST / 500 9ms -
<-- POST /
set failed of 1
--> POST / 500 15ms -
<-- POST /
set failed of 1
--> POST / 500 7ms -
<-- POST /
set failed of 1
--> POST / 500 14ms -
可见,在上传失败之后,当前分片会自动进行重试上传,直到超出重试次数,再直接抛出异常。
如何在所有分片都上传完成之后触发一个回调
到目前为止,整个服务的核心部分已经差不多了,send函数无论怎么调用,都会返回Promise对象,所以在所有分片都上传完成之后触发一个回调也就很容易了,只需要将所有的send函数返回的Promise对象放进数组,然后通过Promise.all函数来捕获即可,可见,基建搭的好,上层建筑建设也就轻而易举了。
所以我们只需要更改sendTimer这个定时器内部的代码即可。
let readyCache = bufferCache.getChunks();
let sendPromise = [];
let sendTimer = setInterval(() => {
if (sending < MAX_SENDING && readyCache.length > 0) {
// 把Promise塞进数组
sendPromise.push(send({
retry: RETRY_COUNT,
fresh: true,
readyCache: readyCache
}));
}
else if ((isFinished && readyCache.length === 0) || stopSend) {
clearTimeout(sendTimer);
if (!stopSend) {
console.log('got last chunk');
let lastChunk = bufferCache.getRemainChunks();
readyCache.push(lastChunk);
// 把Promise塞进数组
sendPromise.push(send({
retry: RETRY_COUNT,
fresh: true,
readyCache: readyCache
}));
}
// 当所有的分片都发送之后触发,
Promise.all(sendPromise).then(() => {
console.log('send success');
}).catch(err => {
console.log('send failed');
});
}
// not ready, wait for next interval
}, 200);
如何实现多个分片并行上传
Node.js提供事件驱动和非阻塞I/O可不是用来写callbackHell的。有了这2个利器,我们可以轻松在一个进程上使用一个线程调度,控制多个I/O操作。这样的设计就无需使用多线程编程,也就不用关心锁之类的东西了。
实现多个分片上传,所以只需要直接创建多个HTTP连接进行上传,多个上传操作同享一个readyCache。
而目前我们实现的send函数可以让一个分片上传自我控制,同样,同时调用多次send函数也就等同于让多个分片进行自我控制。而且多个send函数运行在同一个node.js进程上,所以对共享的reayCache的获取是一个串行的操作(nodejs进程在一个事件轮询周期中会依次执行多个send函数)。也就不可能出现多个send函数对readyCache的竞争造成死锁这样的情况。
可见,单进程异步轮询这样的设计方案,能完全避免死锁这样的情况。
所以直接把调用send函数平行扩展:
let readyCache = bufferCache.getChunks();
let threadPool = [];
let sendTimer = setInterval(() => {
if (sending < MAX_SENDING && readyCache.length > 0) {
// 这个例子同时开启4个分片上传
for (let i = 0; i < MAX_SENDING; i++) {
let thread = send({
retry: RETRY_COUNT,
fresh: true,
readyCache: readyCache
});
threadPool.push(thread);
}
}
else if ((isFinished && readyCache.length === 0) || stopSend) {
clearTimeout(sendTimer);
if (!stopSend) {
console.log('got last chunk');
let lastChunk = bufferCache.getRemainChunks();
readyCache.push(lastChunk);
threadPool.push(send({
retry: RETRY_COUNT,
fresh: true,
readyCache: readyCache
}));
}
Promise.all(threadPool).then(() => {
console.log('send success');
}).catch(err => {
console.log('send failed');
});
}
// not ready, wait for next interval
}, 200);
测试
不能稳定运行的代码不是好代码,写不出稳定运行的程序员不是好的程序员。保证软件质量稳定可靠,测试是必不可少的。
文件流转存服务的单元测试需要覆盖2个方面:
BufferCache的单元测试
将文件都上传到测试服务,并验证上传前和上传后的md5值。
BufferCache.js单元测试
BufferCache最主要的目的就是进行分片的缓存与切割,所以我们可以在测试内制造一些测试数据。
由于缓存和获取是同步进行的,所以我们可以用2个setInterval函数来同步插入和获取。设置一个时间长度,来让setInterval停下来。最后再将没有push到bufferCache内的数据和从push到bufferCache内的数据值进行对比。
it('bufferCache Test', function (done) {
let bufferCache = new BufferCache(1024 * 10);
var startTime = Date.now();
var originalBuffer = []; // 保存生成的数据,不放进bufferCache
let compiledBuffer = []; // 保存从bufferCache取出的数据
let isFinished = false; // 是否结束
// 写入的定时器
let pushTimer = setInterval(() => {
var randomString = [];
// 构造模拟数据
for (let i = 0; i < 1024; i ++) {
let arr = [];
for (let j = 0; j < 1024; j ++) {
arr.push(j % 10);
}
randomString.push(arr.join(''));
}
let buffer = Buffer.from(randomString.join(''));
// 拷贝buffer对象,消除对象引用
let bufferCopy = Buffer.alloc(buffer.length);
buffer.copy(bufferCopy);
originalBuffer.push(bufferCopy);
bufferCache.pushBuf(buffer);
// 该停下来了
if (Date.now() - startTime > 1000) {
isFinished = true;
clearTimeout(pushTimer);
}
}, 5);
// 读取的定时器
let outputTimer = setInterval(() => {
let readyCache = bufferCache.getChunks();
while (readyCache.length > 0) {
let chunk = readyCache.shift();
compiledBuffer.push(chunk);
}
if (isFinished) {
let lastChunk = bufferCache.getRemainChunks();
compiledBuffer.push(lastChunk);
clearTimeout(outputTimer);
// 把2个buffer都合并
let originBuf = originalBuffer.reduce((total, next) => {
return Buffer.concat([total, next], total.length + next.length);
}, Buffer.alloc(0));
let compiledBuf = compiledBuffer.reduce((total, next) => {
return Buffer.concat([total, next], total.length + next.length);
}, Buffer.alloc(0));
assert.equal(originBuf.length, compiledBuf.length);
assert.equal(originBuf.compare(compiledBuf), 0);
done();
}
}, 10);
});
批量上传测试
bluebird模块的Promise.map函数可以同时执行多条异步任务,所以只需要简单使用Promise.map函数,就能批量调用getChunks函数,将数据发送到测试server。
it('upload test', function(done) {
Promise.map(exampleData, (item, index) => {
let md5 = item.md5;
let url = item.url;
return getChunks(url, uploadURL, md5);
}).then(() => {
done();
}).catch(err => {
done(err);
});
});
文件完整性验证
为了验证文件合法性,我在测试server上专门实现了一个接口,传入上传时附带的filename参数,就能按照分片顺序将多个分片合并,并返回整个文件的md5值。
通过这个接口,测试只需要对比发送之前的md5和获取到的md5是否相同就能判断文件有没有在上传时候出错误。
所以测试用例就只需要连续调接口获取数据即可:
// 用Promise把request包装一下
function getData(url, data) {
return new Promise((resolve, reject) => {
request({
url: url,
method: 'POST',
form: data
}, function (err, response, data) {
if (!err && response.statusCode === 200) {
resolve(data);
}
else {
reject(data);
}
});
});
}
it('download data md5sum test', (done) => {
Promise.each(exampleData, (item, index) => {
let md5 = item.md5;
let url = item.url;
return getData(getMD5URL, {
filename: md5
}).then((serverResponse) => {
serverResponse = JSON.parse(serverResponse);
let serverMd5 = serverResponse.data;
assert.equal(serverMd5, md5);
});
}).then(() => {
done();
}).catch(err => {
done(err);
})
});
server端源码
总结
通过灵活使用Promise和递归,我们就能够很轻松实现一些非异步模型看来很复杂的事情。
没有了多线程编程,也就没有了线程调度,线程状态监控,死锁监控,读写锁设计等复杂的功能。不过,能做到这一切也都得归功于Node.js出色的设计以及Node.js的幕后英雄 —— libuv 跨平台异步I/O库
本文章所涉及的源代码:GitHub - andycall/file-stream-upload-example
本文章测试需要的服务端源码: GitHub - andycall/file-upload-example-server
最后
欢迎加我微信(winty230),拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...