
终于用上分库分表了!
1、腾讯可视化, 低代码生成器,正式开源! 2、一行代码解决缓存击穿的问题 3、Java反射到底慢在哪? 4、比 MyBatis 快 100 倍,天生支持联表! 5、这份Java日志格式规范,强啊!
前言
大家好,今天跟大家聊聊分库分表。
什么是分库分表
为什么需要分库分表
如何分库分表
什么时候开始考虑分库分表
分库分表会导致哪些问题
分库分表中间件简介
1. 什么是分库分表
分库:就是一个数据库分成多个数据库,部署到不同机器。
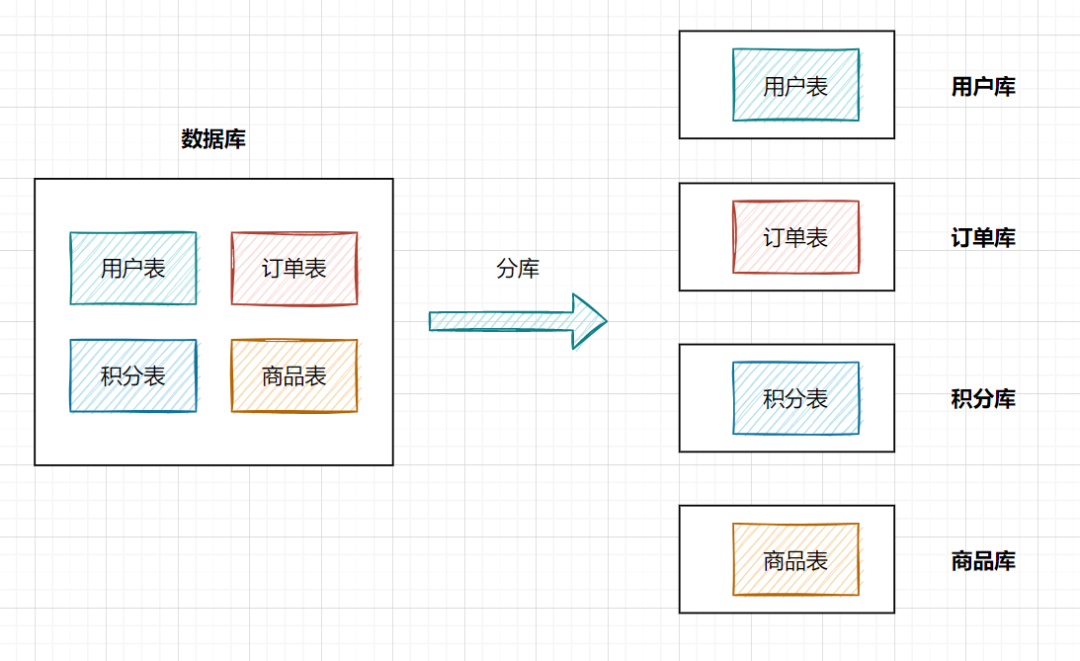
分表:就是一个数据库表分成多个表。

2. 为什么需要分库分表
2.1 为什么需要分库呢?
如果业务量剧增,数据库可能会出现性能瓶颈,这时候我们就需要考虑拆分数据库。从这几方面来看:
磁盘存储
业务量剧增,MySQL单机磁盘容量会撑爆,拆成多个数据库,磁盘使用率大大降低。
并发连接支撑
我们知道数据库连接是有限的。在高并发的场景下,大量请求访问数据库,MySQL单机是扛不住的!当前非常火的微服务架构出现,就是为了应对高并发。它把订单、用户、商品等不同模块,拆分成多个应用,并且把单个数据库也拆分成多个不同功能模块的数据库(订单库、用户库、商品库),以分担读写压力。
2.2 为什么需要分表?
数据量太大的话,SQL的查询就会变慢。如果一个查询SQL没命中索引,千百万数据量级别的表可能会拖垮整个数据库。
即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,查询就变慢啦。
小伙伴们是否还记得,MySQL的B+树的高度怎么计算的呢? 顺便复习一下吧
InnoDB存储引擎最小储存单元是页,一页大小就是16k。B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据,B+树结构图如下:
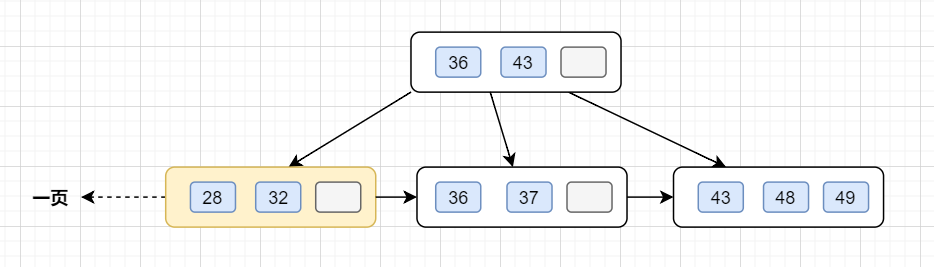
假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。
如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数
=16k/1k =16.非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(面试官问你int类型,一个int就是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是
8+6=14字节,16k/14B =16*1024B/14B = 1170
因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,大概可以存放两千万左右的记录。B+树高度一般为1-3层,如果B+到了4层,查询的时候会多查磁盘的次数,SQL就会变慢。
因此单表数据量太大,SQL查询会变慢,所以就需要考虑分表啦。
3. 如何分库分表
3.1 垂直拆分
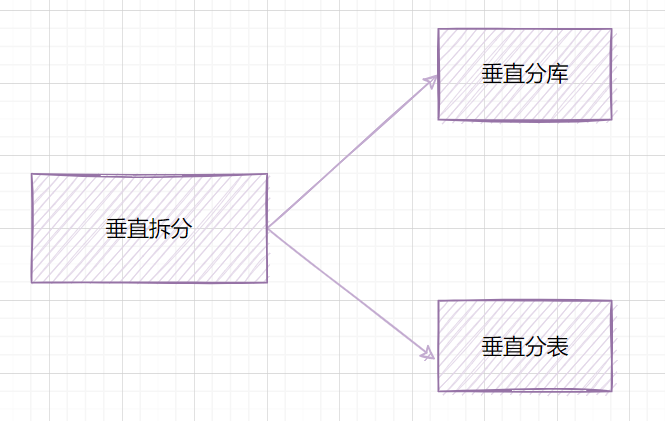
3.1.1 垂直分库
在业务发展初期,业务功能模块比较少,为了快速上线和迭代,往往采用单个数据库来保存数据。数据库架构如下:
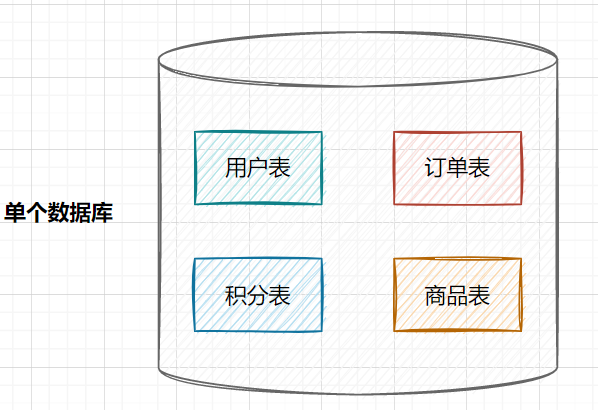
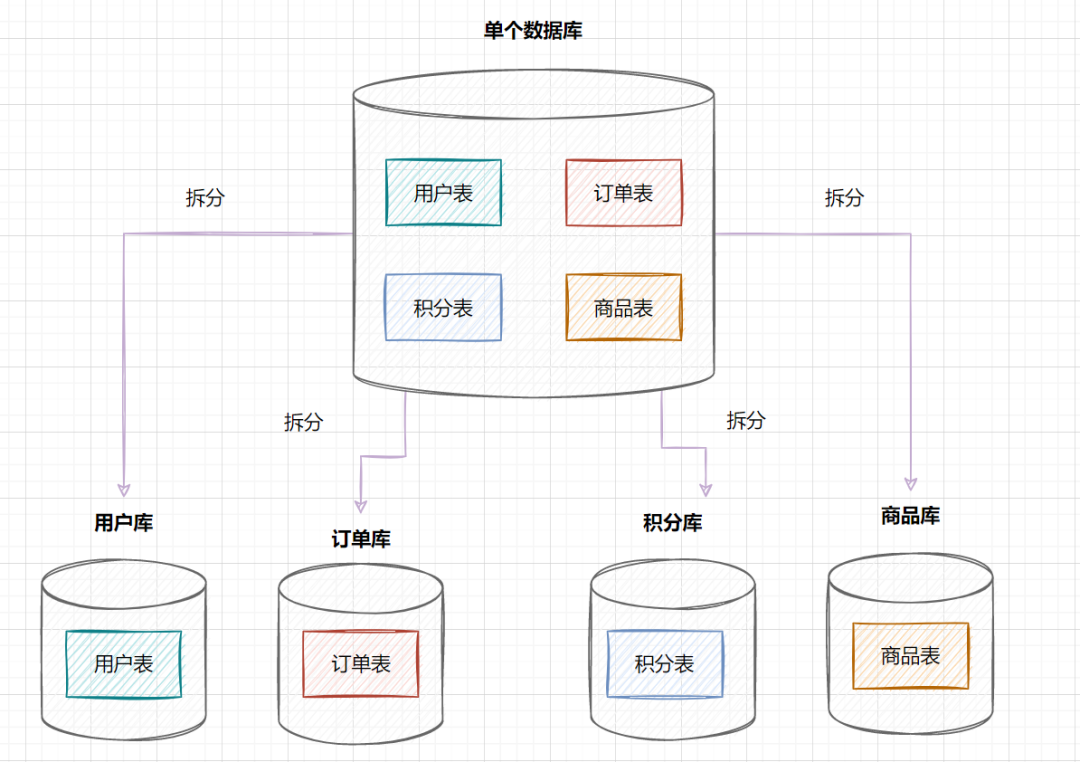
但是随着业务蒸蒸日上,系统功能逐渐完善。这时候,可以按照系统中的不同业务进行拆分,比如拆分成用户库、订单库、积分库、商品库,把它们部署在不同的数据库服务器,这就是垂直分库。
垂直分库,将原来一个单数据库的压力分担到不同的数据库,可以很好应对高并发场景。数据库垂直拆分后的架构如下:
3.1.2 垂直分表
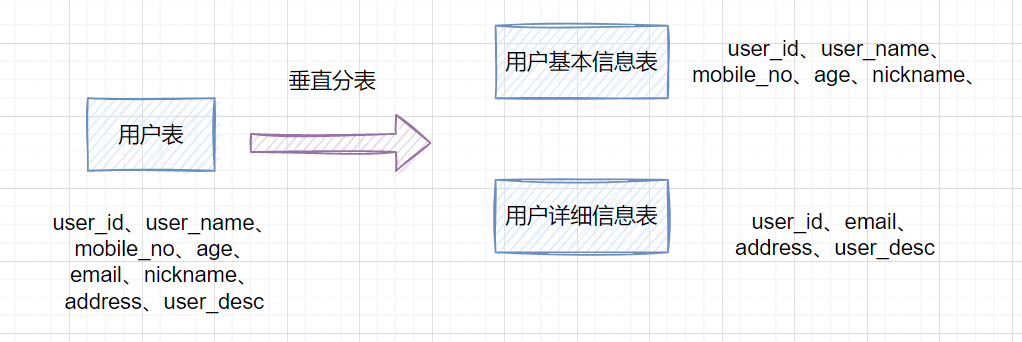
如果一个单表包含了几十列甚至上百列,管理起来很混乱,每次都select *的话,还占用IO资源。这时候,我们可以将一些不常用的、数据较大或者长度较长的列拆分到另外一张表。
比如一张用户表,它包含user_id、user_name、mobile_no、age、email、nickname、address、user_desc,如果email、address、user_desc等字段不常用,我们可以把它拆分到另外一张表,命名为用户详细信息表。这就是垂直分表
3.2 水平拆分
3.2.1 水平分库
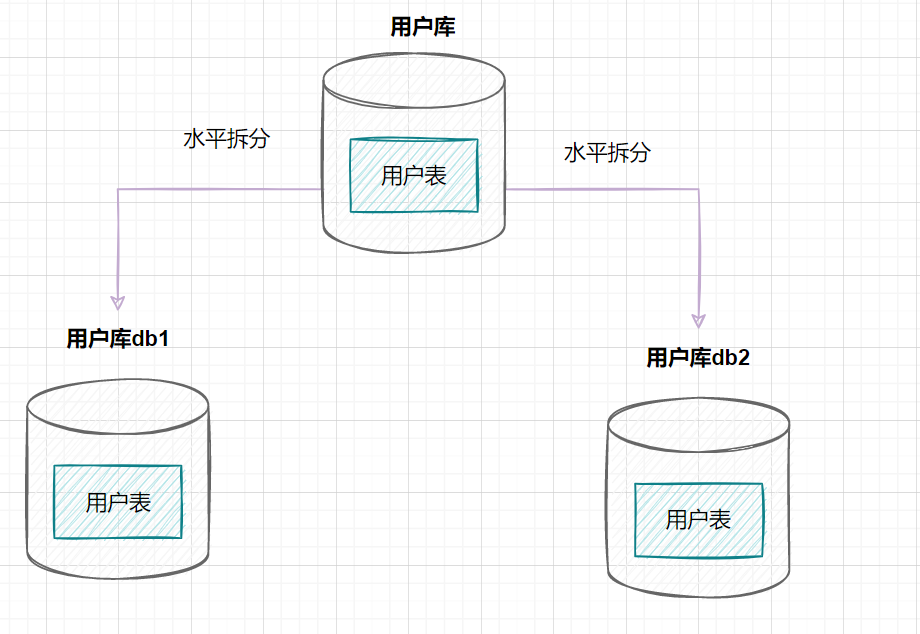
水平分库是指,将表的数据量切分到不同的数据库服务器上,每个服务器具有相同的库和表,只是表中的数据集合不一样。它可以有效的缓解单机单库的性能瓶颈和压力。
用户库的水平拆分架构如下:
3.2.2 水平分表
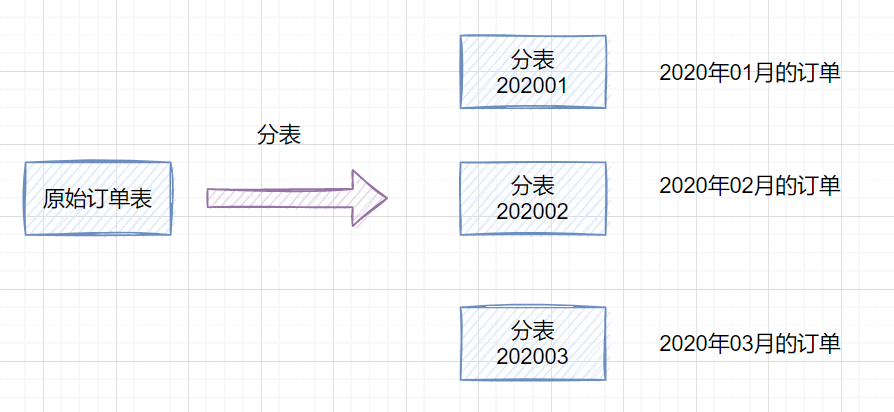
如果一个表的数据量太大,可以按照某种规则(如hash取模、range),把数据切分到多张表去。
一张订单表,按时间range拆分如下:
3.3. 水平分库分表策略
分库分表策略一般有几种,使用与不同的场景:
range范围
hash取模
range+hash取模混合
3.3.1 range范围
range,即范围策略划分表。比如我们可以将表的主键,按照从0~1000万的划分为一个表,1000~2000万划分到另外一个表。如下图:
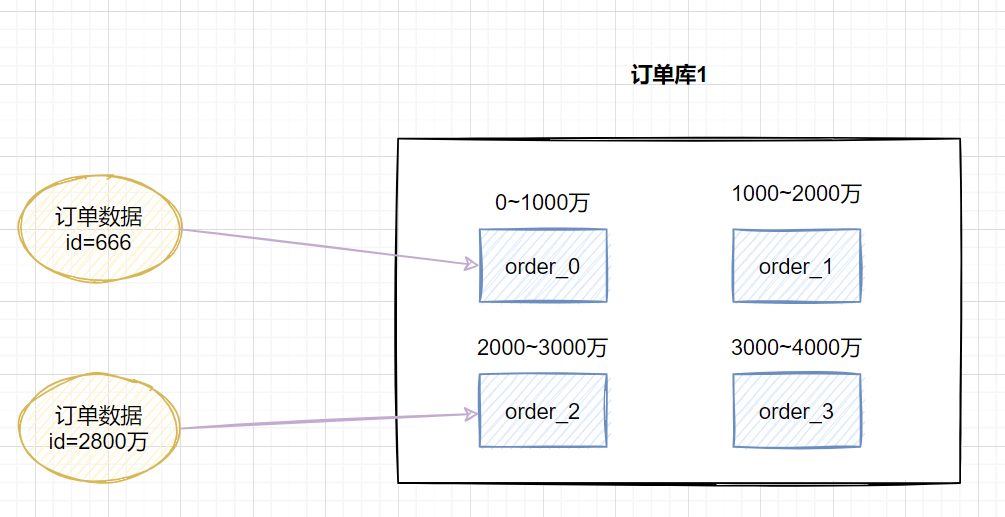
当然,有时候我们也可以按时间范围来划分,如不同年月的订单放到不同的表,它也是一种range的划分策略。
这种方案的优点:
这种方案有利于扩容,不需要数据迁移。假设数据量增加到5千万,我们只需要水平增加一张表就好啦,之前
0~4000万的数据,不需要迁移。
缺点:
这种方案会有热点问题,因为订单id是一直在增大的,也就是说最近一段时间都是汇聚在一张表里面的。比如最近一个月的订单都在
1000万~2000万之间,平时用户一般都查最近一个月的订单比较多,请求都打到order_1表啦,这就导致数据热点问题。
3.3.2 hash取模
hash取模策略:指定的路由key(一般是user_id、订单id作为key)对分表总数进行取模,把数据分散到各个表中。
比如原始订单表信息,我们把它分成4张分表:
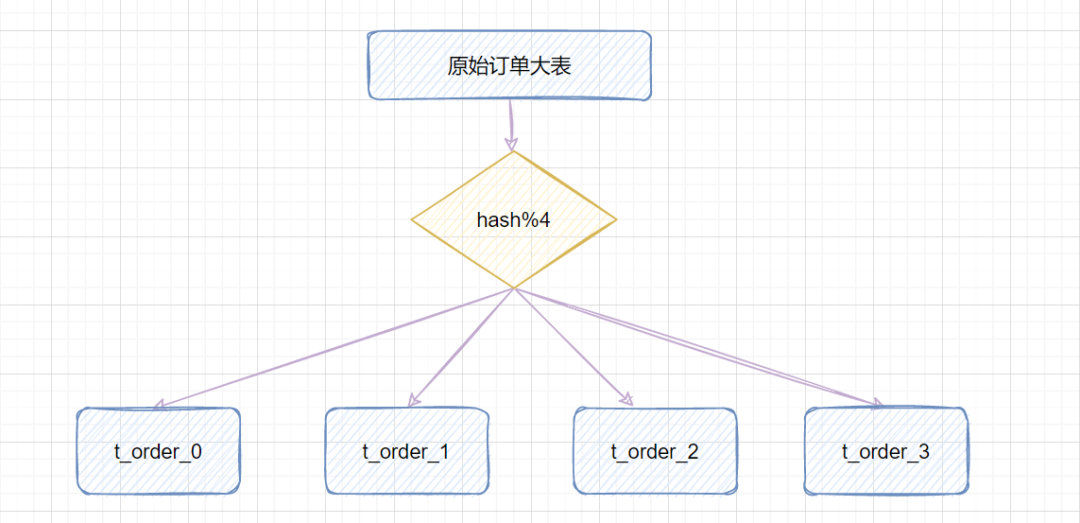
比如id=1,对4取模,就会得到1,就把它放到
t_order_1;id=3,对4取模,就会得到3,就把它放到
t_order_3;
这种方案的优点:
hash取模的方式,不会存在明显的热点问题。
缺点:
如果一开始按照hash取模分成4个表了,未来某个时候,表数据量又到瓶颈了,需要扩容,这就比较棘手了。比如你从4张表,又扩容成
8张表,那之前id=5的数据是在(5%4=1,即t_order_1),现在应该放到(5%8=5,即t_order_5),也就是说历史数据要做迁移了。
3.3.3 range+hash取模混合
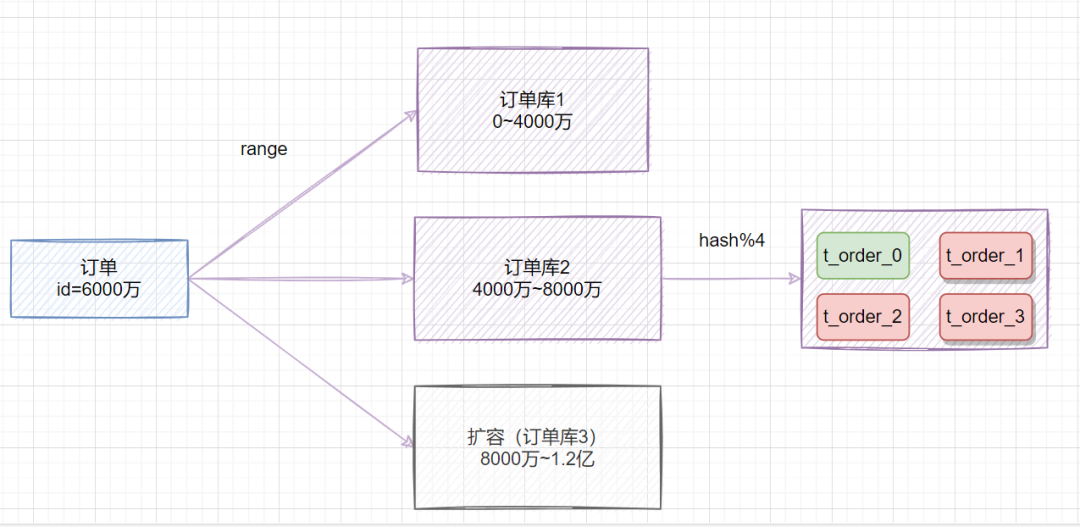
既然range存在热点数据问题,hash取模扩容迁移数据比较困难,我们可以综合两种方案一起嘛,取之之长,弃之之短。
比较简单的做法就是,在拆分库的时候,我们可以先用range范围方案,比如订单id在0~4000万的区间,划分为订单库1;id在4000万~8000万的数据,划分到订单库2,将来要扩容时,id在8000万~1.2亿的数据,划分到订单库3。然后订单库内,再用hash取模的策略,把不同订单划分到不同的表。
4. 什么时候才考虑分库分表呢?
4.1 什么时候分表?
如果你的系统处于快速发展时期,如果每天的订单流水都新增几十万,并且,订单表的查询效率明变慢时,就需要规划分库分表了。一般B+树索引高度是2~3层最佳,如果数据量千万级别,可能高度就变4层了,数据量就会明显变慢了。不过业界流传,一般500万数据就要考虑分表了。
4.2 什么时候分库
业务发展很快,还是多个服务共享一个单体数据库,数据库成为了性能瓶颈,就需要考虑分库了。比如订单、用户等,都可以抽取出来,新搞个应用(其实就是微服务思想),并且拆分数据库(订单库、用户库)。
5. 分库分表会导致哪些问题
分库分表之后,也会存在一些问题:
事务问题
跨库关联
排序问题
分页问题
分布式ID
5.1 事务问题
分库分表后,假设两个表在不同的数据库,那么本地事务已经无效啦,需要使用分布式事务了。
5.2 跨库关联
跨节点Join的问题:解决这一问题可以分两次查询实现
5.3 排序问题
跨节点的count,order by,group by以及聚合函数等问题:可以分别在各个节点上得到结果后在应用程序端进行合并。
5.4 分页问题
方案1:在个节点查到对应结果后,在代码端汇聚再分页。
方案2:把分页交给前端,前端传来pageSize和pageNo,在各个数据库节点都执行分页,然后汇聚总数量前端。这样缺点就是会造成空查,如果分页需要排序,也不好搞。
5.5 分布式ID
数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID,或者使用雪花算法生成分布式ID。
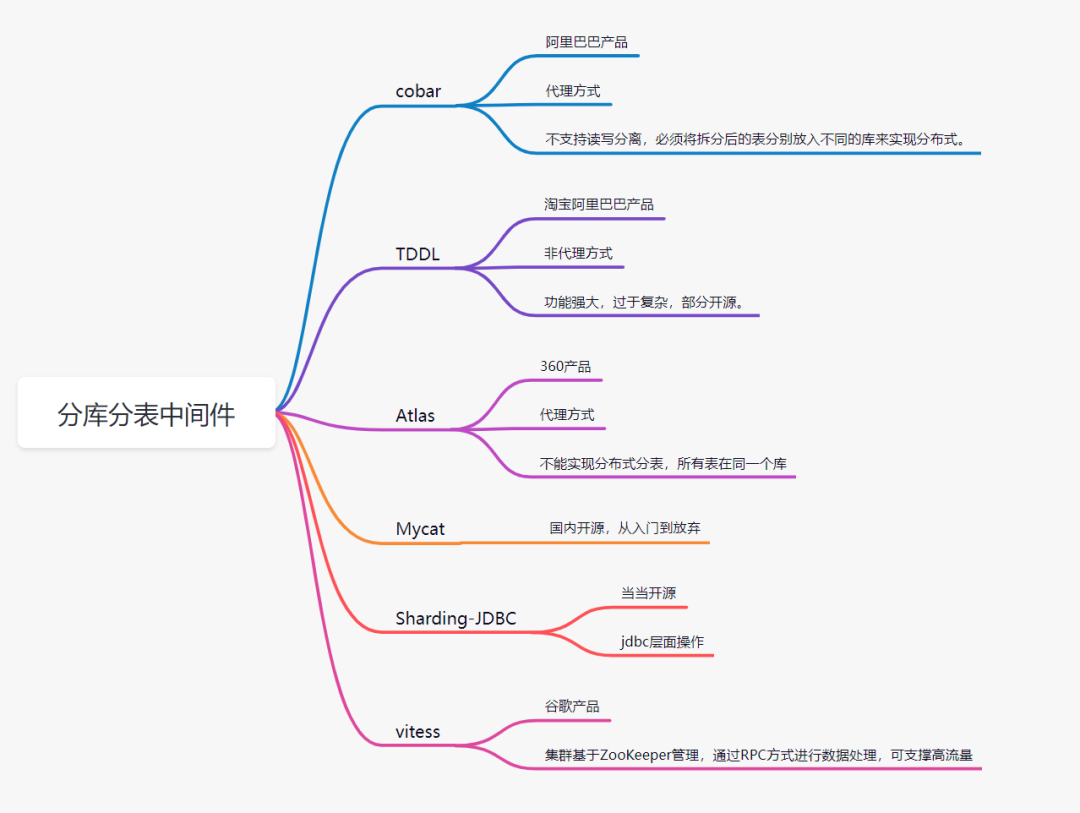
6. 分库分表中间件
目前流行的分库分表中间件比较多:
cobar
Mycat
Sharding-JDBC
Atlas
TDDL(淘宝)
vitess
往期热门文章:
1、巨坑,常见的 update 语句很容易造成Bug 2、完爆90%的数据库性能毛病! 3、Spring Boot性能太差,教你几招轻松搞定 4、Fastjson 2 来了,性能继续提升,还能再战十年 5、笑死!程序员延寿指南开源了 6、用 Dubbo 传输文件?被老板一顿揍! 7、45 个 Git 经典操作场景,专治不会合代码! 8、@Transactional 注解失效的3种原因及解决办法 9、小学生们在B站讲算法,网友:我只会阿巴阿巴 10、Spring爆出比Log4j2还大的漏洞?