
虚拟DOM到底是什么?
是什么?
虚拟 DOM (Virtual DOM )这个概念相信大家都不陌生,从 React 到 Vue ,虚拟 DOM 为这两个框架都带来了跨平台的能力(React-Native 和 Weex)。因为很多人是在学习 React 的过程中接触到的虚拟 DOM ,所以为先入为主,认为虚拟 DOM 和 JSX 密不可分。其实不然,虚拟 DOM 和 JSX 固然契合,但 JSX 只是虚拟 DOM 的充分不必要条件,Vue 即使使用模版,也能把虚拟 DOM 玩得风生水起,同时也有很多人通过 babel 在 Vue 中使用 JSX。
很多人认为虚拟 DOM 最大的优势是 diff 算法,减少 JavaScript 操作真实 DOM 的带来的性能消耗。虽然这一个虚拟 DOM 带来的一个优势,但并不是全部。虚拟 DOM 最大的优势在于抽象了原本的渲染过程,实现了跨平台的能力,而不仅仅局限于浏览器的 DOM,可以是安卓和 IOS 的原生组件,可以是近期很火热的小程序,也可以是各种GUI。
回到最开始的问题,虚拟 DOM 到底是什么,说简单点,就是一个普通的 JavaScript 对象,包含了 tag、props、children 三个属性。
<div id="app">
<p class="text">hello world!!!</p>
</div>
上面的 HTML 转换为虚拟 DOM 如下:
{
tag: 'div',
props: {
id: 'app'
},
chidren: [
{
tag: 'p',
props: {
className: 'text'
},
chidren: [
'hello world!!!'
]
}
]
}
该对象就是我们常说的虚拟 DOM 了,因为 DOM 是树形结构,所以使用 JavaScript 对象就能很简单的表示。而原生 DOM 因为浏览器厂商需要实现众多的规范(各种 HTML5 属性、DOM事件),即使创建一个空的 div 也要付出昂贵的代价。虚拟 DOM 提升性能的点在于 DOM 发生变化的时候,通过 diff 算法比对 JavaScript 原生对象,计算出需要变更的 DOM,然后只对变化的 DOM 进行操作,而不是更新整个视图。
那么我们到底该如何将一段 HTML 转换为虚拟 DOM 呢?
从 h 函数说起
观察主流的虚拟 DOM 库(snabbdom、virtual-dom),通常都有一个 h 函数,也就是 React 中的 React.createElement,以及 Vue 中的 render 方法中的 createElement,另外 React 是通过 babel 将 jsx 转换为 h 函数渲染的形式,而 Vue 是使用 vue-loader 将模版转为 h 函数渲染的形式(也可以通过 babel-plugin-transform-vue-jsx 插件在 vue 中使用 jsx,本质还是转换为 h 函数渲染形式)。
我们先使用 babel,将一段 jsx 代码,转换为一段 js 代码:
安装 babel 依赖
npm i -D @babel/cli @babel/core @babel/plugin-transform-react-jsx
配置 .babelrc
{
"plugins": [
[
"@babel/plugin-transform-react-jsx",
{
"pragma": "h", // default pragma is React.createElement
}
]
]
}
转译 jsx
在目录下新建一个 main.jsx
function getVDOM() {
return (
<div id="app">
<p className="text">hello world!!!</p>
</div>
)
}
使用如下命令进行转译:
npx babel main.jsx --out-file main-compiled.js
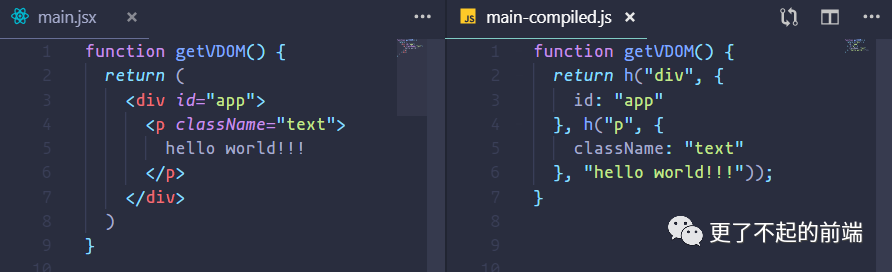
可以看到,最终 HTML 代码会被转译成 h 函数的渲染形式。h 函数接受是三个参数,分别代表是 DOM 元素的标签名、属性、子节点,最终返回一个虚拟 DOM 的对象。
function h(tag, props, ...children) {
return {
tag,
props: props || {},
children: children.flat()
}
}
渲染虚拟 DOM
虽然虚拟 DOM 可以渲染到多个平台,但是这里讲一下在浏览器环境下如何渲染虚拟 DOM。
function render(vdom) {
// 如果是字符串或者数字,创建一个文本节点
if (typeof vdom === 'string' || typeof vdom === 'number') {
return document.createTextNode(vdom)
}
const { tag, props, children } = vdom
// 创建真实DOM
const element = document.createElement(tag)
// 设置属性
setProps(element, props)
// 遍历子节点,并获取创建真实DOM,插入到当前节点
children
.map(render)
.forEach(element.appendChild.bind(element))
// 虚拟 DOM 中缓存真实 DOM 节点
vdom.dom = element
// 返回 DOM 节点
return element
}
function setProps (element, props) {
Object.entries(props).forEach(([key, value]) => {
setProp(element, key, value)
})
}
function setProp (element, key, vlaue) {
element.setAttribute(
// className使用class代替
key === 'className' ? 'class' : key,
vlaue
)
}
将虚拟 DOM 渲染成真实 DOM 后,只需要插入到对应的根节点即可。
const vdom = <div>hello world!!!</div> // h('div', {}, 'hello world!!!')
const app = document.getElementById('app')
const ele = render(vdom)
app.appendChild(ele)
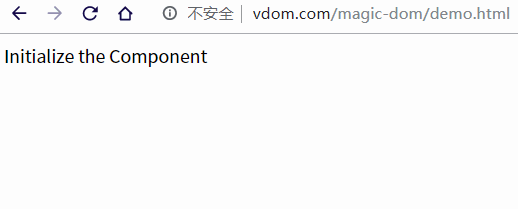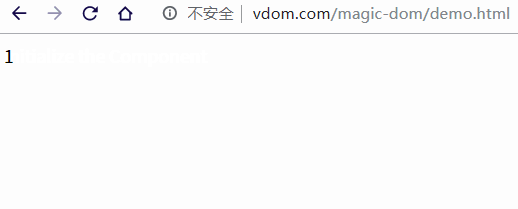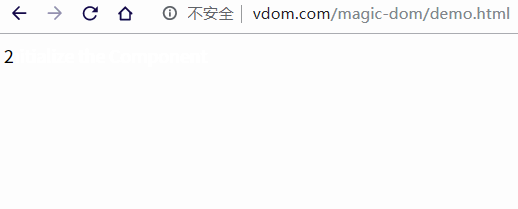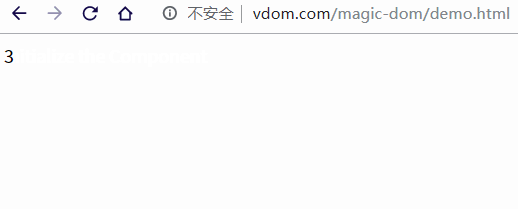
当然在现代化的框架中,一般会有一个组件文件专门用来构造虚拟 DOM,我们模仿 React 使用 class 的方式编写组件,然后渲染到页面中。
class Component {
vdom = null // 组件的虚拟DOM表示
$el = null // 虚拟DOM生成的真实节点
state = {
text: 'Initialize the Component'
}
render() {
const { text } = this.state
return (
<div>{ text }</div>
)
}
}
function createElement (app, component) {
const vdom = component.render()
component.vdom = vdom
component.$el = render(vdom) // 将虚拟 DOM 转换为真实 DOM
app.appendChild(component.$el)
}
const app = document.getElementById('app')
const component = new Component
createElement(app, component)
diff 算法
diff 算法,顾名思义,就是比对新老 VDOM 的变化,然后将变化的部分更新到视图上。对应到代码上,就是一个 diff 函数,返回一个 patches (补丁)。
const before = h('div', {}, 'before text')
const after = h('div', {}, 'after text')
const patches = diff(before, after)
修改我们之前的组件,增加 setState 方法,用于修改组件的内部状态。
class Component {
vdom = null // 组件的虚拟DOM表示
$el = null // 虚拟DOM生成的真实节点
state = {
text: 'Initialize the Component'
}
// 手动修改组件state
setState(newState) {
this.state = {
...this.state,
...newState
}
const newVdom = this.render()
const patches = diff(this.vdom, newVdom)
patch(this.$el, patches)
}
changeText(text) {
this.setState({
text
})
}
render() {
const { text } = this.state
return (
<div>{ text }</div>
)
}
}
当我们调用 setState 时,state 内部状态发生变动,再次调用 render 方法就会生成一个新的虚拟 DOM 树,这样我们就能使用 diff 方法计算出新老虚拟 DOM 发送变化的部分,最后使用 patch 方法,将变动渲染到视图中。
const app = document.getElementById('app')
const component = new Component
createElement(app, component)
// 将文本更改为数字,每秒 +1
let count = 0
setInterval(() => {
component.changeText(++count)
}, 1000);
diff 算法的进化
关于 diff 算法的最经典的就是 Matt Esch 的 virtual-dom,以及 snabbdom(被整合进 vue 2.0中)。
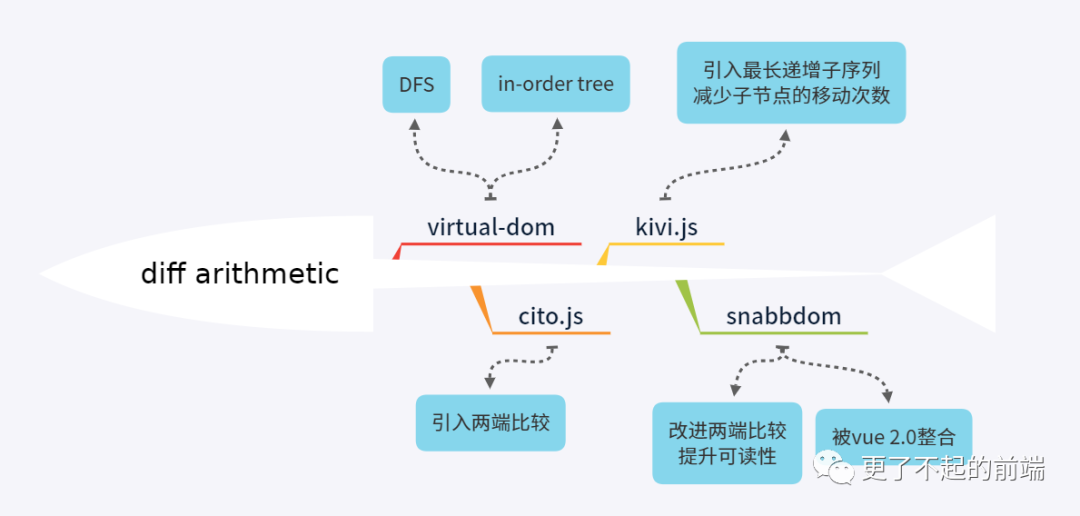
“最开始出现的是 virtual-dom 这个库,是大家好奇 React 为什么这么快而搞鼓出来的。它的实现是非常学院风格,通过深度优先搜索与 in-order tree 来实现高效的 diff 。它与 React 后来公开出来的算法是很不一样。然后是 cito.js 的横空出世,它对今后所有虚拟 DOM 的算法都有重大影响。它采用两端同时进行比较的算法,将 diff 速度拉高到几个层次。紧随其后的是 kivi.js,在 cito.js 的基出提出两项优化方案,使用 key 实现移动追踪以及及基于 key 的最长自增子序列算法应用(算法复杂度 为O(n^2))。但这样的 diff 算法太过复杂了,于是后来者 snabbdom 将 kivi.js 进行简化,去掉编辑长度矩离算法,调整两端比较算法。速度略有损失,但可读性大大提高。再之后,就是著名的vue2.0 把sanbbdom整个库整合掉了。
“引用自司徒正美的文章 去哪儿网迷你React的研发心得
下面我们就来讲讲这几个虚拟 DOM 库 diff 算法的具体实现:
1️⃣ virtual-dom
virtual-dom 作为虚拟 DOM 开天辟地的作品,采用了对 DOM 树进行了深度优先的遍历的方法。
DOM 树的遍历
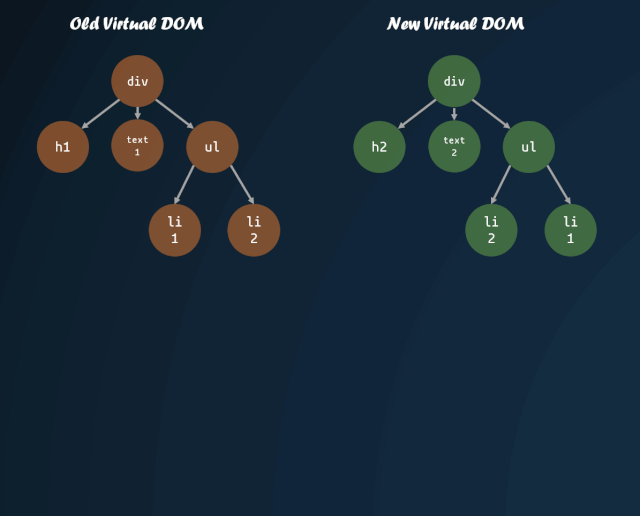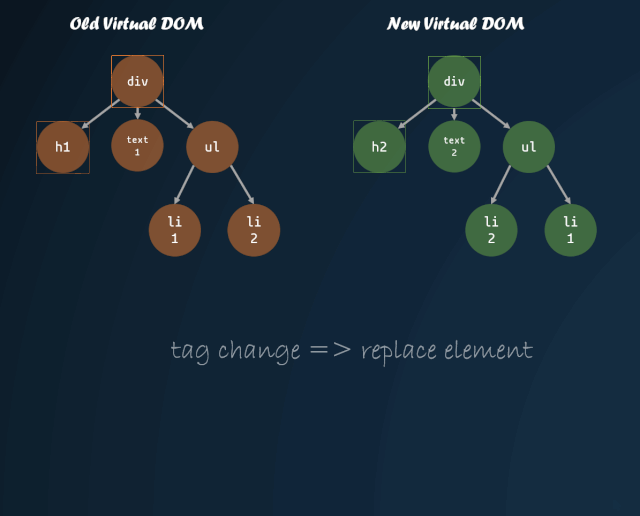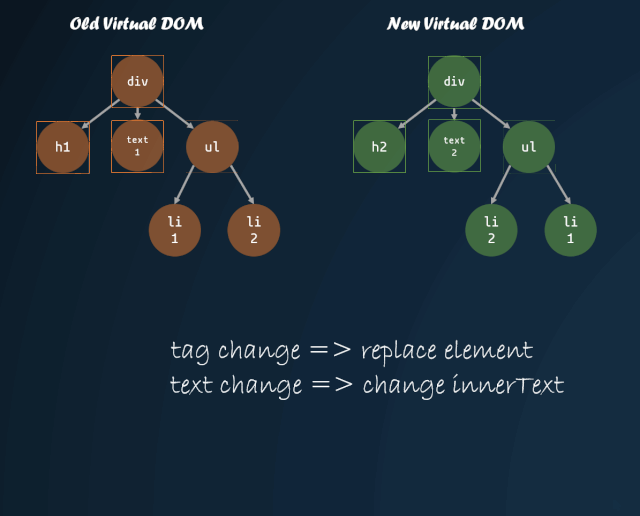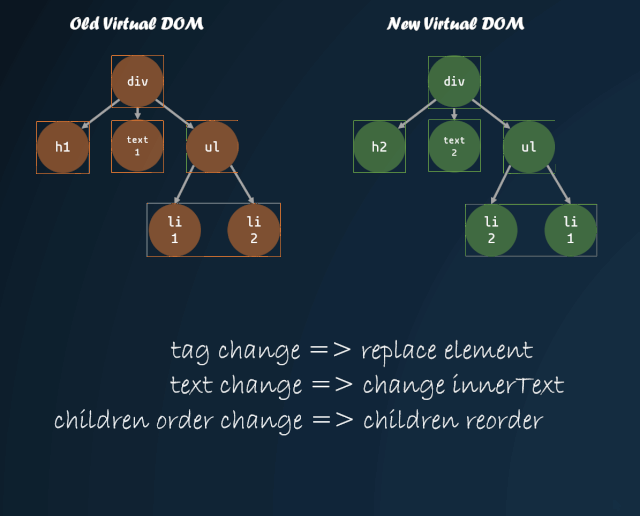
体现到代码上:
function diff (oldNode, newNode) {
const patches = []
walk(oldNode, newNode, patches, 0) // 进行深度优先遍历
return patches
}
function walk(oldNode, newNode, patches, index) {
if (newNode === oldNode) {
return
}
const patch = { type: 'update', vNode: newNode }
const oldChildren = oldNode.children
const newChildren = newNode.children
const oldLen = oldChildren.length
const newLen = newChildren.length
const len = oldLen > newLen ? oldLen : newLen
// 找到对应位置的子节点进行比对
for (let i = 0; i < len; i++) {
const oldChild = oldChildren[i]
const newChild = newChildren[i]
index++
// 相同节点进行比对
walk(oldChild, newChild, patches, index)
if (isArray(oldChild.children)) {
index += oldChild.children.length
}
}
if (patch) {
patches[index] = patch
}
}
VDOM 节点的对比
上面代码只是对 VDOM 进行了简单的深度优先遍历,在遍历中,还需要对每个 VDOM 进行一些对比,具体分为以下几种情况:
旧节点不存在,插入新节点;新节点不存在,删除旧节点 新旧节点如果都是 VNode,且新旧节点 tag 相同 对比新旧节点的属性 对比新旧节点的子节点差异,通过 key 值进行重排序,key 值相同节点继续向下遍历 新旧节点如果都是 VText,判断两者文本是否发生变化 其他情况直接用新节点替代旧节点
import { isVNode, isVText, isArray } from '../utils/type'
function walk(oldNode, newNode, patches, index) {
if (newNode === oldNode) {
return
}
let patch = patches[index]
if (!oldNode) {
// 旧节点不存在,直接插入
patch = appendPatch(patch, {
type: PATCH.INSERT,
vNode: newNode,
})
} else if (!newNode) {
// 新节点不存在,删除旧节点
patch = appendPatch(patch, {
type: PATCH.REMOVE,
vNode: null,
})
} else if (isVNode(newNode)) {
if (isVNode(oldNode)) {
// 相同类型节点的 diff
if (newNode.tag === oldNode.tag && newNode.key === oldNode.key) {
// 新老节点属性的对比
const propsPatch = diffProps(newNode.props, oldNode.props)
if (propsPatch && propsPatch.length > 0) {
patch = appendPatch(patch, {
type: PATCH.PROPS,
patches: propsPatch,
})
}
// 新老节点子节点的对比
patch = diffChildren(oldNode, newNode, patches, patch, index)
}
} else {
// 新节点替换旧节点
patch = appendPatch(patch, {
type: PATCH.REPLACE,
vNode: newNode,
})
}
} else if (isVText(newNode)) {
if (!isVText(oldNode)) {
// 将旧节点替换成文本节点
patch = appendPatch(patch, {
type: PATCH.VTEXT,
vNode: newNode,
})
} else if (newNode.text !== oldNode.text) {
// 替换文本
patch = appendPatch(patch, {
type: PATCH.VTEXT,
vNode: newNode,
})
}
}
if (patch) {
// 将补丁放入对应位置
patches[index] = patch
}
}
// 一个节点可能有多个 patch
// 多个patch时,使用数组进行存储
function appendPatch(patch, apply) {
if (patch) {
if (isArray(patch)) {
patch.push(apply)
} else {
patch = [patch, apply]
}
return patch
} else {
return apply
}
}
属性的对比
function diffProps(newProps, oldProps) {
const patches = []
const props = Object.assign({}, newProps, oldProps)
Object.keys(props).forEach(key => {
const newVal = newProps[key]
const oldVal = oldProps[key]
if (!newVal) {
patches.push({
type: PATCH.REMOVE_PROP,
key,
value: oldVal,
})
}
if (oldVal === undefined || newVal !== oldVal) {
patches.push({
type: PATCH.SET_PROP,
key,
value: newVal,
})
}
})
return patches
}
子节点的对比
这一部分可以说是 diff 算法中,变动最多的部分,因为前面的部分,各个库对比的方向基本一致,而关于子节点的对比,各个仓库都在前者基础上不断得进行改进。
首先需要明白,为什么需要改进子节点的对比方式。如果我们直接按照深度优先遍历的方式,一个个去对比子节点,子节点的顺序发生改变,那么就会导致 diff 算法认为所有子节点都需要进行 replace,重新将所有子节点的虚拟 DOM 转换成真实 DOM,这种操作是十分消耗性能的。
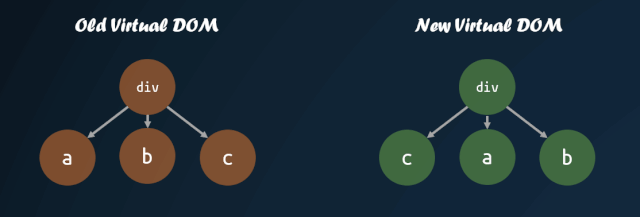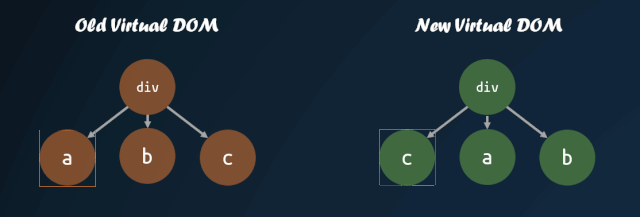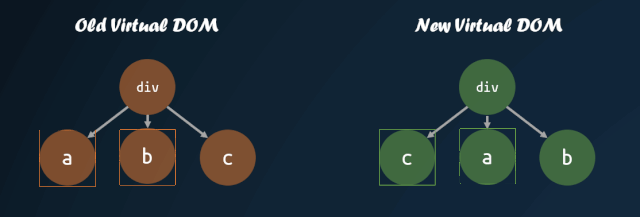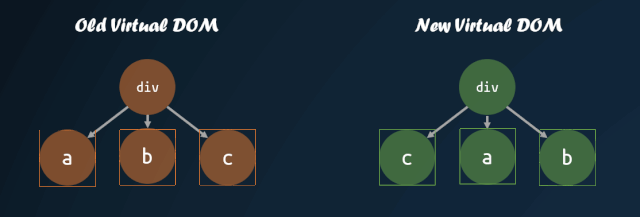
但是,如果我们能够找到新旧虚拟 DOM 对应的位置,然后进行移动,那么就能够尽量减少 DOM 的操作。
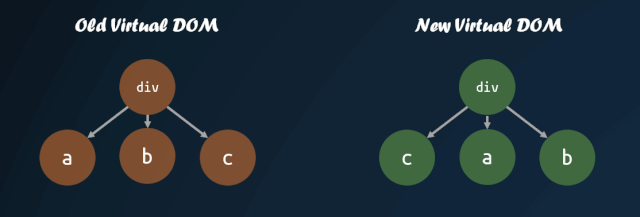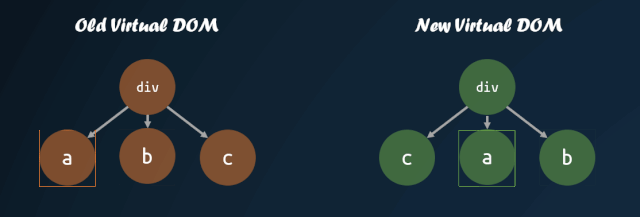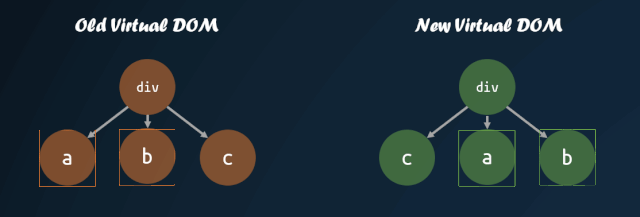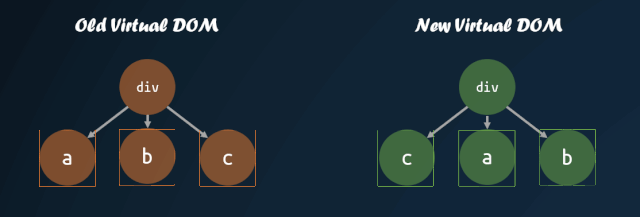
virtual-dom 在一开始就进行了这方面的尝试,对子节点添加 key 值,通过 key 值的对比,来判断子节点是否进行了移动。通过 key 值对比子节点是否移动的模式,被各个库沿用,这也就是为什么主流的视图库中,子节点如果缺失 key 值,会有 warning 的原因。

具体是怎么对比的,我们先看代码:
function diffChildren(oldNode, newNode, patches, patch, index) {
const oldChildren = oldNode.children
// 新节点按旧节点的顺序重新排序
const sortedSet = sortChildren(oldChildren, newNode.children)
const newChildren = sortedSet.children
const oldLen = oldChildren.length
const newLen = newChildren.length
const len = oldLen > newLen ? oldLen : newLen
for (let i = 0; i < len; i++) {
var leftNode = oldChildren[i]
var rightNode = newChildren[i]
index++
if (!leftNode) {
if (rightNode) {
// 旧节点不存在,新节点存在,进行插入操作
patch = appendPatch(patch, {
type: PATCH.INSERT,
vNode: rightNode,
})
}
} else {
// 相同节点进行比对
walk(leftNode, rightNode, patches, index)
}
if (isVNode(leftNode) && isArray(leftNode.children)) {
index += leftNode.children.length
}
}
if (sortedSet.moves) {
// 最后进行重新排序
patch = appendPatch(patch, {
type: PATCH.ORDER,
moves: sortedSet.moves,
})
}
return patch
}
这里首先需要对新的子节点进行重排序,先进行相同节点的 diff ,最后把子节点按照新的子节点顺序重新排列。
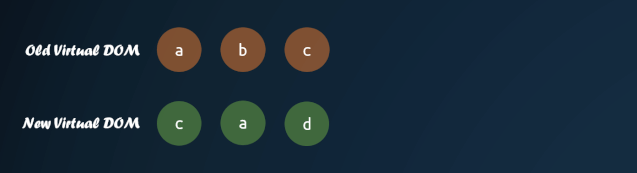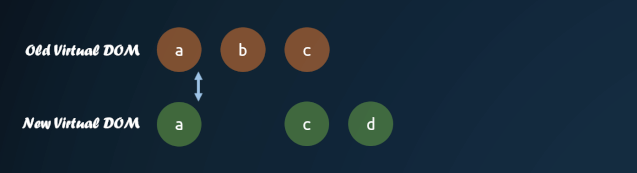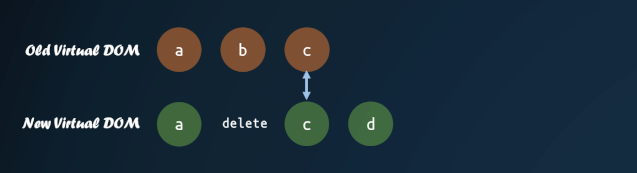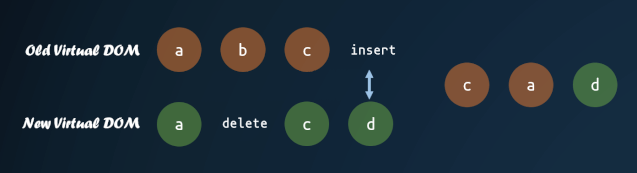
这里有个较复杂的部分,就是对子节点的重新排序。
function sortChildren(oldChildren, newChildren) {
// 找出变化后的子节点中带 key 的 vdom (keys),和不带 key 的 vdom (free)
const newChildIndex = keyIndex(newChildren)
const newKeys = newChildIndex.keys
const newFree = newChildIndex.free
// 所有子节点无 key 不进行对比
if (newFree.length === newChildren.length) {
return {
children: newChildren,
moves: null,
}
}
// 找出变化前的子节点中带 key 的 vdom (keys),和不带 key 的 vdom (free)
const oldChildIndex = keyIndex(oldChildren)
const oldKeys = oldChildIndex.keys
const oldFree = oldChildIndex.free
// 所有子节点无 key 不进行对比
if (oldFree.length === oldChildren.length) {
return {
children: newChildren,
moves: null,
}
}
// O(MAX(N, M)) memory
const shuffle = []
const freeCount = newFree.length
let freeIndex = 0
let deletedItems = 0
// 遍历变化前的子节点,对比变化后子节点的 key 值
// 并按照对应顺序将变化后子节点的索引放入 shuffle 数组中
for (let i = 0; i < oldChildren.length; i++) {
const oldItem = oldChildren[i]
let itemIndex
if (oldItem.key) {
if (newKeys.hasOwnProperty(oldItem.key)) {
// 匹配到变化前节点中存在的 key
itemIndex = newKeys[oldItem.key]
shuffle.push(newChildren[itemIndex])
} else {
// 移除变化后节点不存在的 key 值
deletedItems++
shuffle.push(null)
}
} else {
if (freeIndex < freeCount) {
// 匹配变化前后的无 key 子节点
itemIndex = newFree[freeIndex++]
shuffle.push(newChildren[itemIndex])
} else {
// 如果变化后子节点中已经不存在无 key 项
// 变化前的无 key 项也是多余项,故删除
deletedItems++
shuffle.push(null)
}
}
}
const lastFreeIndex =
freeIndex >= newFree.length ? newChildren.length : newFree[freeIndex]
// 遍历变化后的子节点,将所有之前不存在的 key 对应的子节点放入 shuffle 数组中
for (let j = 0; j < newChildren.length; j++) {
const newItem = newChildren[j]
if (newItem.key) {
if (!oldKeys.hasOwnProperty(newItem.key)) {
// 添加所有新的 key 值对应的子节点
// 之后还会重新排序,我们会在适当的地方插入新增节点
shuffle.push(newItem)
}
} else if (j >= lastFreeIndex) {
// 添加剩余的无 key 子节点
shuffle.push(newItem)
}
}
const simulate = shuffle.slice()
const removes = []
const inserts = []
let simulateIndex = 0
let simulateItem
let wantedItem
for (let k = 0; k < newChildren.length; ) {
wantedItem = newChildren[k] // 期待元素: 表示变化后 k 的子节点
simulateItem = simulate[simulateIndex] // 模拟元素: 表示变化前 k 位置的子节点
// 删除在变化后不存在的子节点
while (simulateItem === null && simulate.length) {
removes.push(remove(simulate, simulateIndex, null))
simulateItem = simulate[simulateIndex]
}
if (!simulateItem || simulateItem.key !== wantedItem.key) {
// 期待元素的 key 值存在
if (wantedItem.key) {
if (simulateItem && simulateItem.key) {
// 如果一个带 key 的子元素没有在合适的位置,则进行移动
if (newKeys[simulateItem.key] !== k + 1) {
removes.push(remove(simulate, simulateIndex, simulateItem.key))
simulateItem = simulate[simulateIndex]
// if the remove didn't put the wanted item in place, we need to insert it
if (!simulateItem || simulateItem.key !== wantedItem.key) {
inserts.push({ key: wantedItem.key, to: k })
}
// items are matching, so skip ahead
else {
simulateIndex++
}
} else {
inserts.push({ key: wantedItem.key, to: k })
}
} else {
inserts.push({ key: wantedItem.key, to: k })
}
k++
}
// 该位置期待元素的 key 值不存在,且模拟元素存在 key 值
else if (simulateItem && simulateItem.key) {
// 变化前该位置的元素
removes.push(remove(simulate, simulateIndex, simulateItem.key))
}
} else {
// 如果期待元素和模拟元素 key 值相等,跳到下一个子节点比对
simulateIndex++
k++
}
}
// 移除所有的模拟元素
while (simulateIndex < simulate.length) {
simulateItem = simulate[simulateIndex]
removes.push(
remove(simulate, simulateIndex, simulateItem && simulateItem.key)
)
}
// 如果只有删除选项中有值
// 将操作直接交个 delete patch
if (removes.length === deletedItems && !inserts.length) {
return {
children: shuffle,
moves: null,
}
}
return {
children: shuffle,
moves: {
removes: removes,
inserts: inserts,
},
}
}
function keyIndex(children) {
const keys = {}
const free = []
const length = children.length
for (let i = 0; i < length; i++) {
const child = children[i]
if (child.key) {
keys[child.key] = i
} else {
free.push(i)
}
}
return {
keys: keys, // 子节点中所有存在的 key 对应的索引
free: free, // 子节点中不存在 key 值的索引
}
}
function remove(arr, index, key) {
arr.splice(index, 1) // 移除数组中指定元素
return {
from: index,
key: key,
}
}
这一部分比较复杂,具体可以查看 virtual-dom 的两个 pr ,这两个 pr 里面讨论了关于 diff 子节点重新排序的优化逻辑。
Rewrite reorder Rewrite reorder (part 2)
更新 DOM
在拿到了 VDOM 的 diff 结果后,需要将得到的 patches 更新到视图上。
function patch(rootNode, patches) {
if (!patches || patches.length === 0) return
// 取得对应 index 的真实 DOM
const nodes = domIndex(rootNode)
patches.forEach((patch, index) => {
patch && applyPatch(nodes[index], patch)
})
}
function domIndex(rootNode) {
const nodes = [rootNode]
const children = rootNode.childNodes
if (children.length) {
for (let child of children) {
if (child.nodeType === 1 || child.nodeType === 3) {
if (child.nodeType === 1) {
nodes.push(...domIndex(child))
} else if (child.nodeType === 3) {
nodes.push(child)
}
}
}
}
return nodes
}
遍历patches,然后得到每个真实 DOM 和其对应的 patch,然后在真实 DOM 上进行更新:
function applyPatch(node, patchList) {
for (let patch of patchList) {
patchOp(node, patch)
}
}
function patchOp(node, patch) {
const { type, vNode } = patch
const parentNode = node.parentNode
let newNode = null
switch (type) {
case PATCH.INSERT:
// 插入新节点
break
case PATCH.REMOVE:
// 删除旧新节点
break
case PATCH.REPLACE:
// 替换节点
break
case PATCH.ORDER:
// 子节点重新排序
break
case PATCH.VTEXT:
// 替换文本节点
break
case PATCH.PROPS:
// 更新节点属性
break
default:
break
}
}
这里每一步操作,不进行具体展开,感兴趣的话可以在我的 github 查看完整代码。
2️⃣ cito.js
cito 其他步骤与 virtual-dom 类似,最大的差异点就在子节点的对比上,而且 cito 移除了 patch 更新,在 diff 的过程中,直接更新真实 DOM ,这样省去了 patch 的存储,一定程度上节省了内存,后面其他的 VDOM 库基本使用这种方式。
我们再来看看 cito 在子节点的对比上,到底有何优化?
其实前面我们已经介绍过了,cito 主要变化就是引入了两端对比,将 diff 算法的速度提升了几个量级。

/**
* 子节点对比
* @param {Element} domNode 父节点的真实DOM
* @param {Array} oldChildren 旧的子节点
* @param {Array} children 新的子节点
*/
function updateChildren(domNode, oldChildren, children) {
const oldChildrenLength = oldChildren.length
const childrenLength = children.length
let oldEndIndex = oldChildrenLength - 1
let endIndex = childrenLength - 1
let oldStartIndex = 0
let startIndex = 0
let successful = true
let nextChild
// 两端对比算法
outer: while (
successful &&
oldStartIndex <= oldEndIndex &&
startIndex <= endIndex
) {
successful = false
let oldStartChild = oldChildren[oldStartIndex]
let startChild = children[startIndex]
while (oldStartChild.key === startChild.key) {
// 子节点对比
updateNode(oldStartChild, startChild, domNode)
oldStartIndex++
startIndex++
if (oldStartIndex > oldEndIndex || startIndex > endIndex) {
break outer
}
oldStartChild = oldChildren[oldStartIndex]
startChild = children[startIndex]
successful = true
}
let oldEndChild = oldChildren[oldEndIndex]
let endChild = children[endIndex]
while (oldEndChild.key === endChild.key) {
// 子节点对比
updateNode(oldEndChild, endChild, domNode)
oldEndIndex--
endIndex--
if (oldStartIndex > oldEndIndex || startIndex > endIndex) {
break outer
}
oldEndChild = oldChildren[oldEndIndex]
endChild = children[endIndex]
successful = true
}
while (oldStartChild.key === endChild.key) {
nextChild = endIndex + 1 < childrenLength ? children[endIndex + 1] : null
// 子节点对比
updateNode(oldStartChild, endChild, domNode)
// 移动子节点
moveChild(domNode, endChild, nextChild)
oldStartIndex++
endIndex--
if (oldStartIndex > oldEndIndex || startIndex > endIndex) {
break outer
}
oldStartChild = oldChildren[oldStartIndex]
endChild = children[endIndex]
successful = true
}
while (oldEndChild.key === startChild.key) {
nextChild = oldStartIndex < oldChildrenLength ? oldChildren[oldStartIndex] : null
// 子节点对比
updateNode(oldEndChild, startChild, domNode)
// 移动子节点
moveChild(domNode, startChild, nextChild)
oldEndIndex--
startIndex++
if (oldStartIndex > oldEndIndex || startIndex > endIndex) {
break outer
}
oldEndChild = oldChildren[oldEndIndex]
startChild = children[startIndex]
successful = true
}
}
}
子节点对比:
function updateNode(oldNode, node, domParent) {
if (node === oldNode) {
return
}
const tag = node.tag
if (oldNode.tag !== tag) {
// 标签不一致,创建新节点
createNode(node, domParent, oldNode, true)
} else {
const oldChildren = oldNode.children
const children = node.children
const domNode = oldNode.dom
node.dom = domNode // 真实 DOM 挂在到 虚拟 DOM 上
// 子节点对比
if (children !== oldChildren) {
updateChildren(domNode, node, oldChildren, children)
}
const oldProps = oldNode.props
const props = node.props
// 属性对比
if (props !== oldProps) {
updateAttributes(domNode, props, oldProps)
}
}
}
移动子节点:
function moveChild(domNode, child, nextChild) {
const domRefChild = nextChild && nextChild.dom
let domChild = child.dom
if (domChild !== domRefChild) {
if (domRefChild) {
domNode.insertBefore(domChild, domRefChild)
} else {
domNode.appendChild(domChild)
}
}
}
3️⃣ kivi.js
kivi 的 diff 算法在 cito 的基础上,引入了最长增长子序列,通过子序列找到最小的 DOM 操作数。
算法思想
“翻译自 kivi/lib/reconciler.ts
该算法用于找到最小的 DOM 操作数,可以分为以下几步:
1. 找到数组中首部和尾部公共的节点,并在两端移动
该方法通过比对两端的 key 值,找到旧节点(A) 和新节点(B)中索引相同的节点。
A: -> [a b c d e f g] <-
B: [a b f d c g]
这里我们可以跳过首部的 a 和 b,以及尾部的 g。
A: -> [c d e f] <-
B: [f d c]
此时,将尝试对边进行比较,如果在对边有一个 key 值相同的节点,将执行简单的移动操作,将 c 节点移动到
右边缘,将 f 节点移动到左边缘。
A: -> [d e] <-
B: [d]
现在将再次尝试查找公共的首部与尾部,发现 d 节点是相同的,我们跳过它。
A: -> [e] <-
B: [ ]
然后检查各个列表的长度是否为0,如果旧节点列表长度为0,将插入新节点列表的剩余节点,或者新节点列表长度为0,将删除所有旧节点列表中的元素。
这个简单的算法适用于大多数的实际案例,比如仅仅反转了列表。
当列表无法利用该算法找到解的时候,会使用下一个算法,例如:
A: -> [a b c d e f g] <-
B: [a c b h f e g]
边缘的 a 和 g 节点相同,跳过他们。
A: -> [b c d e f] <-
B: [c b h f e]
然后上面的算法行不通了,我们需要进入下一步。
2. 查找需要删除或者插入的节点,并且某个节点是否需要移动
我们先创建一个数组 P,长度为新子节点列表的长度,并为数组每个元素赋值 -1 ,它表示新子节点应该插入的位置。稍后,我们将把旧子节点中的节点位置分配给这个数组。
A: [b c d e f]
B: [c b h f e]
P: [. . . . .] // . == -1
然后,我们构建一个对象 I,它的键表示新子节点的 key 值,值为子节点在剩余节点数组中的位置。
A: [b c d e f]
B: [c b h f e]
P: [. . . . .] // . == -1
I: {
c: 0,
b: 1,
h: 2,
f: 3,
e: 4,
}
last = 0
我们开始遍历旧子节点列表的剩余节点,并检查是否可以在 I 对象的索引中找到具有相同 key 值的节点。如果找不到任何节点,则将它删除,否则,我们将节点在旧节点列表位置分配给数组 P。
A: [b c d e f]
^
B: [c b h f e]
P: [. 0 . . .] // . == -1
I: {
c: 0,
b: 1, <-
h: 2,
f: 3,
e: 4,
}
last = 1
当我们为数组 P 分配节点位置时,我们会保留上一个节点在新子节点列表中的位置,如果当一个节点的位置大于当前节点的位置,那么我们将 moved 变量置为 true。
A: [b c d e f]
^
B: [c b h f e]
P: [1 0 . . .] // . == -1
I: {
c: 0, <-
b: 1,
h: 2,
f: 3,
e: 4,
}
last = 1 // last > 0; moved = true
上一个节点 b位置为 “1”,当前节点 c 的位置 “0”,所以将 moved 变量置为 true。
A: [b c d e f]
^
B: [c b h f e]
P: [1 0 . . .] // . == -1
I: {
c: 0,
b: 1,
h: 2,
f: 3,
e: 4,
}
moved = true
对象 I 索引中不存在 d,则删除该节点
A: [b c d e f]
^
B: [c b h f e]
P: [1 0 . . 3] // . == -1
I: {
c: 0,
b: 1,
h: 2,
f: 3,
e: 4, <-
}
moved = true
为节点 e 分配位置。
A: [b c d e f]
^
B: [c b h f e]
P: [1 0 . 4 3] // . == -1
I: {
c: 0,
b: 1,
h: 2,
f: 3, <-
e: 4,
}
moved = true
为节点 f 分配位置。
此时,我们检查 moved 标志是否被打开,或者旧子节点列表的长度减去已删除节点的数量不等于新子节点列表的长度。如果其中任何一个条件为真,我们则进入下一步。
3. 如果 moved 为真,查找最小移动数,如果长度发送变化,则插入新节点。
如果 moved 为真,我们需要在 P 数组中找到 最长自增子序列,并移动不属于这个子序列的所有节点。
A: [b c d e f]
B: [c b h f e]
P: [1 0 . 4 3] // . == -1
LIS: [1 4]
moved = true
现在我们需要同时从尾端遍历新的子节点列表以及最长自增子序列(后面简称 LIS),并检查当前位置是否等于 LIS 的值。
A: [b c d e f]
B: [c b h f e]
^ // new_pos == 4
P: [1 0 . 4 3] // . == -1
LIS: [1 4]
^ // new_pos == 4
moved = true
节点 e 保持当前位置
A: [b c d e f]
B: [c b h f e]
^ // new_pos == 3
P: [1 0 . 4 3] // . == -1
LIS: [1 4]
^ // new_pos != 1
moved = true
移动节点 f,移动到下一个节点 e 前面它。
A: [b c d e f]
B: [c b h f e]
^ // new_pos == 2
P: [1 0 . 4 3] // . == -1
^ // old_pos == -1
LIS: [1 4]
^
moved = true
节点 h 在数组 P 中为 -1 ,则表示插入新节点 h。
A: [b c d e f]
B: [c b h f e]
^ // new_pos == 1
P: [1 0 . 4 3] // . == -1
LIS: [1 4]
^ // new_pos == 1
moved = true
节点 b 保持当前位置
A: [b c d e f]
B: [c b h f e]
^ // new_pos == 0
P: [1 0 . 4 3] // . == -1
LIS: [1 4]
^ // new_pos != undefined
moved = true
移动节点 c ,移动到下一个节点 b 前面它。
如果 moved 为 false 时,我们不需要查找LIS,我们只需遍历新子节点列表,并检查它在数组 P 中的位置,如果是 -1 ,则插入新节点。
关于 kivi
kivi 是作者对虚拟 DOM 性能提升的一些猜想,一开始它就向着性能出发,所有它在实现上代码可能并不优雅,而且它的 api 也十分不友好。而接下来的 snabbdom 就在 kivi 的基础上,大大提升了代码的可读性,很多讲述虚拟 DOM 的文章也将 snabbdom 作为案例。
另外,kivi 的作者也创建了另一个 源码以及 api 更友好的仓库:ivi,感兴趣可以了解一下。
4️⃣ snabbdom
snabbdom 的优势就是代码的可读性大大提升,并且也引入了两端对比,diff 速度也不慢。
我们可以简单看下 snabbdom 的两端对比算法的核心代码:
/**
* 子节点对比
* @param {Element} parentElm 父节点的真实DOM
* @param {Array} oldCh 旧的子节点
* @param {Array} newCh 新的子节点
*/
function updateChildren(parentElm, oldCh, newCh) {
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx
let idxInOld
let elmToMove
let before
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 跳过两端不存在的旧节点
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx]
}
// 跳过两端不存在的新节点
else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx]
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx]
}
/*
** 进行两端对比,分为四种状况:
** 1. oldStart <=> newStart
** 2. oldEnd <=> newEnd
** 3. oldStart <=> newEnd
** 4. oldEnd <=> newStart
*/
else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode)
insertBefore(parentElm, oldStartVnode.dom, oldEndVnode.dom.nextSibling)
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
// Vnode moved left
patchVnode(oldEndVnode, newStartVnode)
insertBefore(parentElm, oldEndVnode.dom, oldStartVnode.dom)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}
// 上面四种情况都不存在,通过 key 值查找对应 VDOM 进行对比
else {
// 构造旧子节点的 map 表 (key => vdom)
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
idxInOld = oldKeyToIdx[newStartVnode.key]
// 如果新的子节点在旧子节点不存在,进行插入操作
if (idxInOld === undefined) {
insertBefore(parentElm, render(newStartVnode), oldStartVnode.dom)
newStartVnode = newCh[++newStartIdx]
}
// 如果新的子节点在旧子节点存在,进行对比
else {
elmToMove = oldCh[idxInOld]
if (elmToMove.sel !== newStartVnode.sel) {
// key 值相同,但是 tag 不同,重新生成节点并替换
insertBefore(parentElm, render(newStartVnode), oldStartVnode.dom)
} else {
patchVnode(elmToMove, newStartVnode)
oldCh[idxInOld] = undefined // 该位置已经对比,进行置空
insertBefore(parentElm, elmToMove.dom, oldStartVnode.dom)
}
newStartVnode = newCh[++newStartIdx]
}
}
}
// 处理一些未处理到的节点
if (oldStartIdx <= oldEndIdx || newStartIdx <= newEndIdx) {
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].dom
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx)
} else {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
}
关于 snabbdom ,网上有太多教程来分析它的 diff 过程了,不管是虚拟 DOM 的教程,还是 Vue 的源码分析,这里就不再详细讲述了。但是可以明显的看到,snabbdom 的 diff 算法是有 cito 和 kivi 的影子在的。
总结
毋庸置疑虚拟 DOM 带给前端的意义是非凡的,虚拟 DOM 在现如今还有更多新鲜的玩法。比如 omi 将虚拟 DOM 与 Web Component 的结合,还有 Taro 和 Chameleon 带来的多端统一的能力。
另外,文中相关的代码都可以在我的 github 查看,这篇文章更多是对自己学习的一个记录,如果有什么错误的观点,欢迎进行指正。