
写 Python 脚本时,一定要加上这个
我发现有不少朋友写 Python 脚本非常随意,要么不用函数,要么函数随处定义,反正第一眼看不出要执行的第一行代码位于何处,这样的脚本可读性很差,而且容易隐藏 bug,解决这个问题很简单,当我们写 Python 脚本时,一定要加上这个:
def main():
# do something
print("do something.")
if __name__ == "__main__":
main()
你可能要反对了:我怎么爽就怎么写,凭什么听你的,多写个 if __name__...?
别急,让我说三个原因。
第一,它让 Python 文件的作用更加明确
首先需要明白 __name__ 的作用,当脚本直接被 Python 解释器执行时,其值就是 "__main__",当其被其他 Python 程序 import 的时候,其值就是对应的 Python 脚本文件名,可以在 Python 解释器验证下,假定有个 some_script.py 其内容如下:
print("some_script.py")
print(__name__)
在 Python 解释器导入一下:
❯ vim some_script.py
❯ python
Python 3.8.5 (v3.8.5:580fbb018f, Jul 20 2020, 12:11:27)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import some_script
some_script.py
some_script
>>>
可以看到,__name__ 的值就是 Python 脚本的文件名 some_script。
也就是说 if __name__ == "__main__": 后面的代码在 import 的时候是不会运行的。
明白了这一点,if __name__ == "__main__": 就可以做为区分脚本和库的一个标志,当我们看到 if __name__ == "__main__": 时,就认为这一个可以直接运行的脚本,当没有看到这行代码时,就认为这是一个库,可以被其他程序引用,Explicit is better than implicit.,不是吗?
再举个例子:
假如你写了一个不带if __name__ == "__main__": 的脚本,叫 bad_script.py,内容如下:
def useful_function(x):
return x * x
class UsefulClass:
def __init__(self, x):
self.x = x
#你自己测试了一吧,没毛病
for i in range(7):
print(useful_function(i))
别人写了个 useful.py,引用了你的 useful_function:
from bad_script import useful_function
def main():
print(f'{useful_function(3)=}')
if __name__ == '__main__':
main()
一运行,发现打印了不可预期的内容,见下图红色部分:
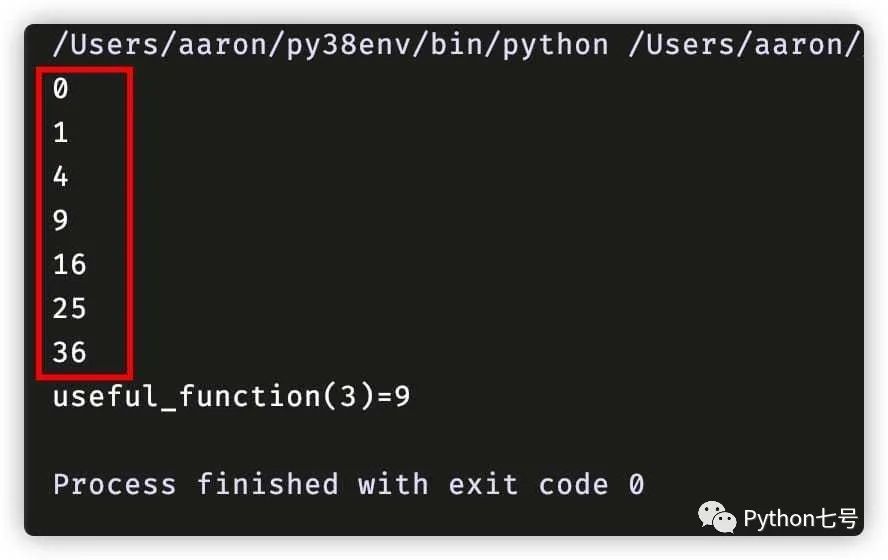
查了半天原因,发现是你的脚本输出的,你说别人会不会骂你?
假如你在自己脚本里定义了全局变量,别人如果在不合适的位置导入了 *,就会把你这个全局变量也导入,导致变量覆盖,很容易会出现 bug。
第二,它让 Python 文件更加易读,对 IDE 友好
有了 if __name__ == "__main__": 相当于 Python 程序也有了一个入口函数,所有的变量都从这里开始定义和使用,我们可以清晰的知道程序的逻辑开始于何处(当然还需要我们自觉的把程序的开始逻辑都放在这里)
其实,这也是 PyCharm 推荐的做法,当你新建一个项目的时候,它默认创建的 main.py 就是长这样的:
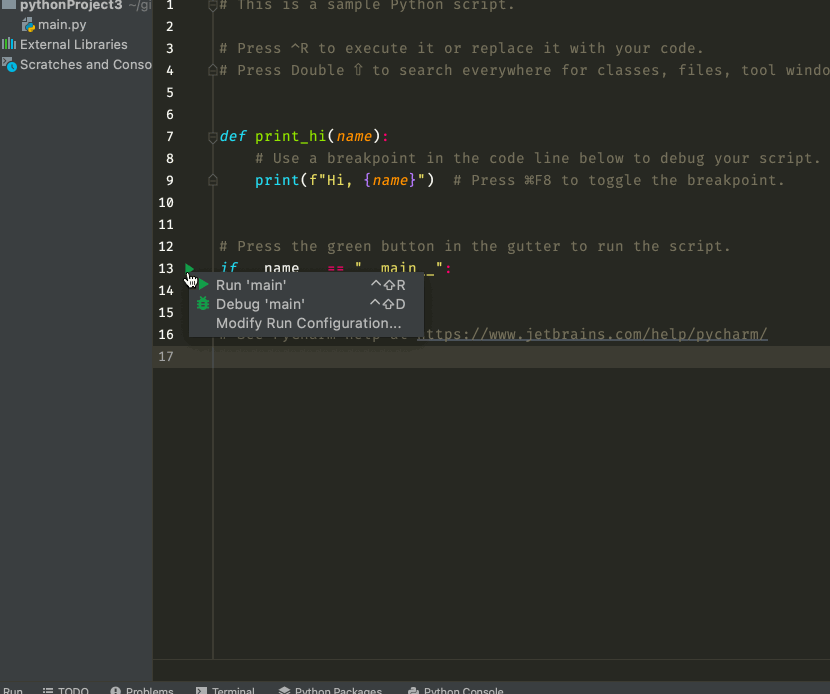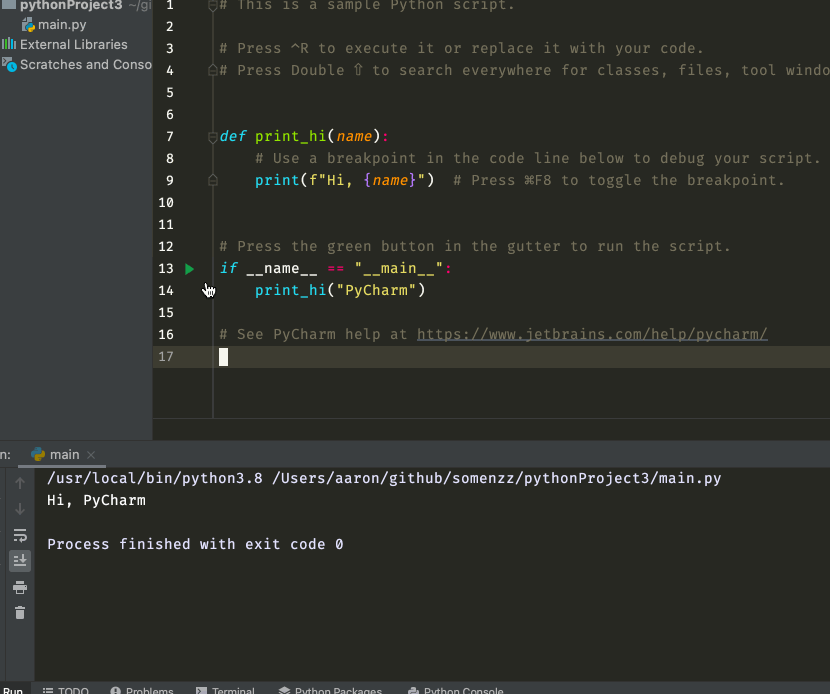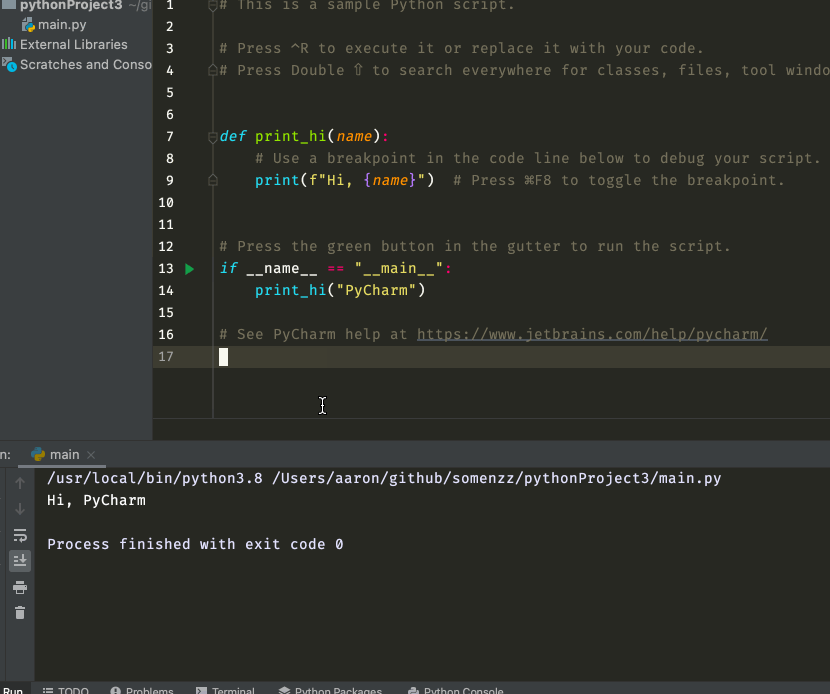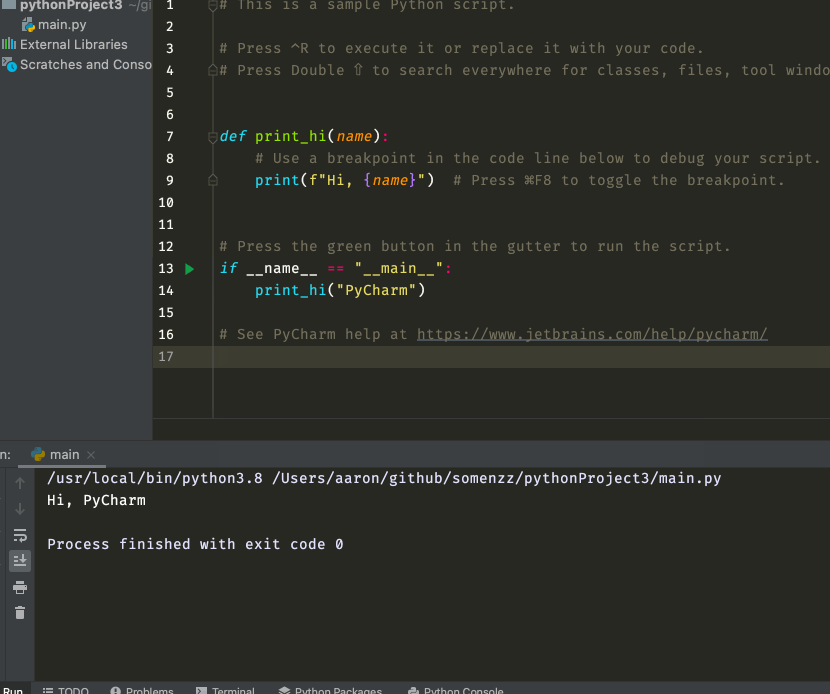
在if __name__ == "__main__": 的那一行的最左边也有一个绿色的运行按钮,点击一下,程序就从这一行开始运行了。
为什么很多优秀的编程语言,比如 C、Java、Golang、C++ 都有一个 main 入口函数呢?我想很重要的一个原因就是就是程序入口统一,容易阅读。
第三、多进程场景下,必须用 if main
比如说你用多进程搞并行计算,写了这样的代码:
import multiprocessing as mp
def useful_function(x):
return x * x
print("processing in parallel")
with mp.Pool() as p:
results = p.map(useful_function, [1, 2, 3, 4])
print(results)
当你运行的时候,会发现程序不停的在创建进程,同时也在不停的报错 RuntimeError,即使你 Ctrl C 也无法终止程序。而加上了 if __name__ == "__main__": 程序就会按照预期的进行:
import multiprocessing as mp
def useful_function(x):
return x * x
if __name__ == '__main__':
print("processing in parallel")
with mp.Pool() as p:
results = p.map(useful_function, [1, 2, 3, 4])
print(results)
这是为什么呢?
其实我是这样理解的,Python 的多程序就是启动了多个 Python 解释器,每个 Python 解释器都会导入你这个脚本,复制一份全局变量和函数给子进程用,如果有了if __name__ == "__main__":,那它后面的代码就不会被 import,也就不会被重复执行。否则,这个创建多进程的代码就会被 import,就会被执行,从而无限递归的去创建子进程,Python3 会报 RuntimeError,顺序是先创建进程,然后报错的,因此就会出现不停的创建进程,不停的报错,Ctrl C 也无法终止的现象,只能 kill 掉整个终端。这里有个官方解释[1]
最后的话
if __name__ == "__main__": 虽然不是强制的,但是基于上述三点原因,我强烈推荐你这么做,它是 Python 社区的约定,对应Python 之禅:明确优于隐晦。正如 _ 作为变量名的意思就是告诉读代码的人:这个变量不重要,后面也不会用到它。当你看到 Python 脚本有 if __name__ == "__main__": 时,就会意识到,这是一个可执行的脚本,当被其他程序导入时,这部分代码不会被执行,而多进程的程序中,这是必须的。
如果有收获的话,欢迎点赞、关注、在看,感谢阅读。
参考资料
官方解释: https://docs.python.org/zh-cn/3/library/multiprocessing.html#programming-guidelines