
HDFS技术原理(下)-总结太全面了!!!

作者 | 曹世宏
接着上篇- HDFS技术原理(上)
HDFS体系结构
HDFS体系结构概述:
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中的。
HDFS命名空间管理:
HDFS的命名空间包含目录、文件和块。 在HDFS1.0体系结构中,在整个HDFS集群中只有一个命名空间,并且只有唯一一个名称节点,该节点负责对这个命名空间进行管理。 HDFS使用的是传统的分级文件体系,因此,用户可以像使用普通文件系统一样,创建、删除目录和文件,在目录间转移文件,重命名文件等。
通信协议:
HDFS是一个部署在集群上的分布式文件系统,因此,很多数据需要通过网络进行传输。 所有的HDFS通信协议都是构建在TCP/IP协议基础之上的。 客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互。 名称节点和数据节点之间则使用数据节点协议进行交互。 客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。在设计上,名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求。
客户端:
客户端是用户操作HDFS最常用的方式,HDFS在部署时都提供了客户端。 HDFS客户端是一个库,暴露了HDFS文件系统接口,这些接口隐藏了HDFS实现中的大部分复杂性。 严格来说,客户端并不算是HDFS的一部分。 客户端可以支持打开、读取、写入等常见的操作,并且提供了类似Shell的命令行方式来访问HDFS中的数据。 此外,HDFS也提供了Java API,作为应用程序访问文件系统的客户端编程接口。
HDFS体系结构的局限性:
HDFS只设置唯一一个名称节点,这样做虽然大大简化了系统设计,但也带来了一些明显的局限性,具体如下:
命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。 性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。 隔离问题:由于集群中只有一个名称节点,只有一个命名空间,因此,无法对不同应用程序进行隔离。 集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
HDFS常用参数配置
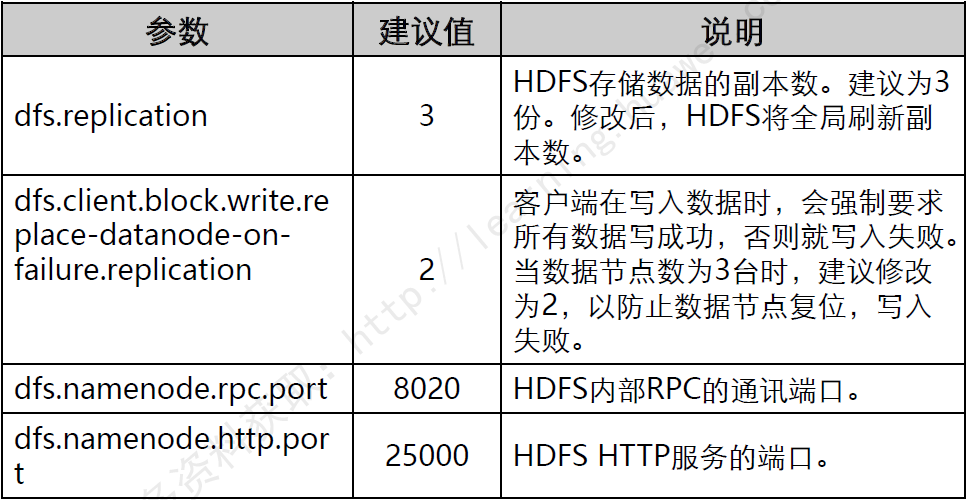
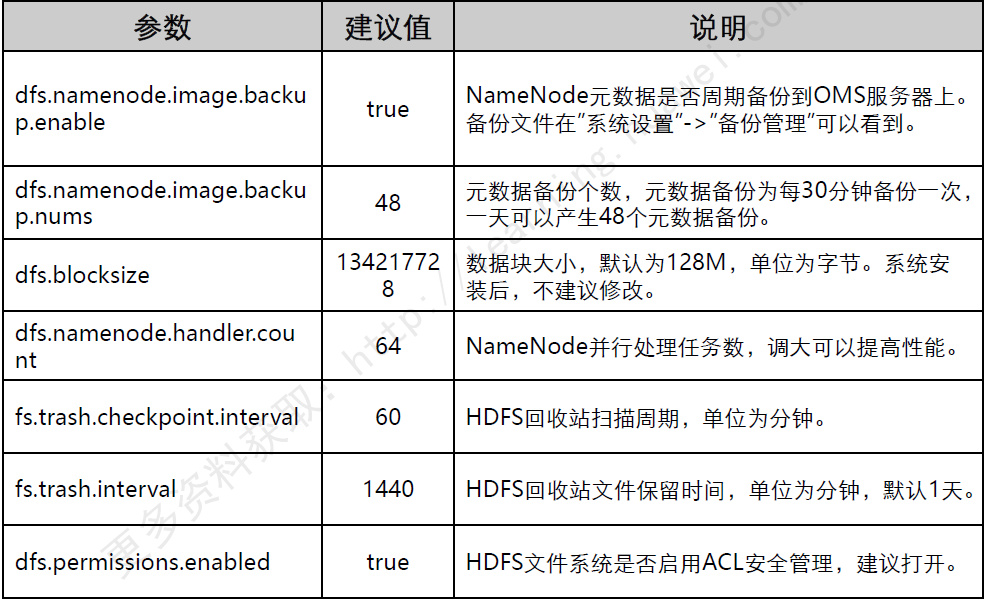
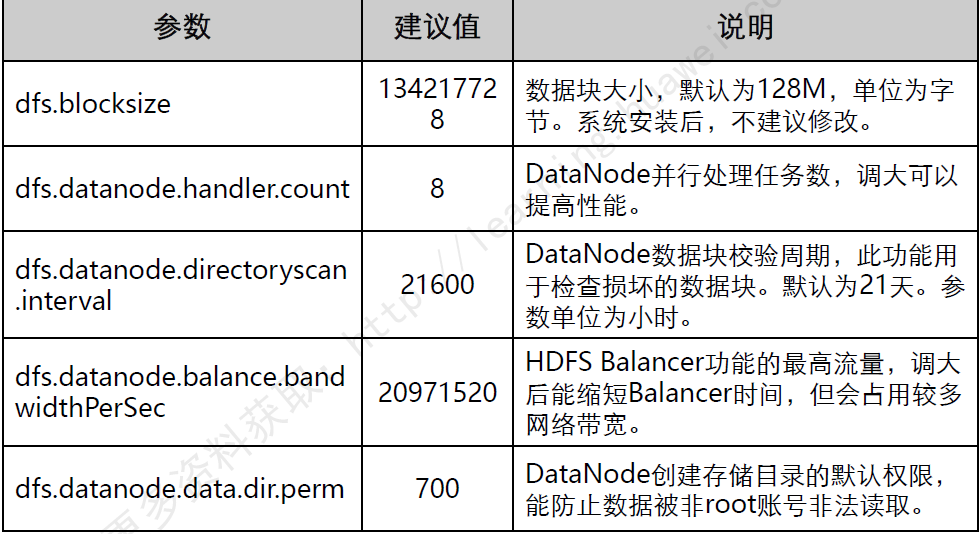
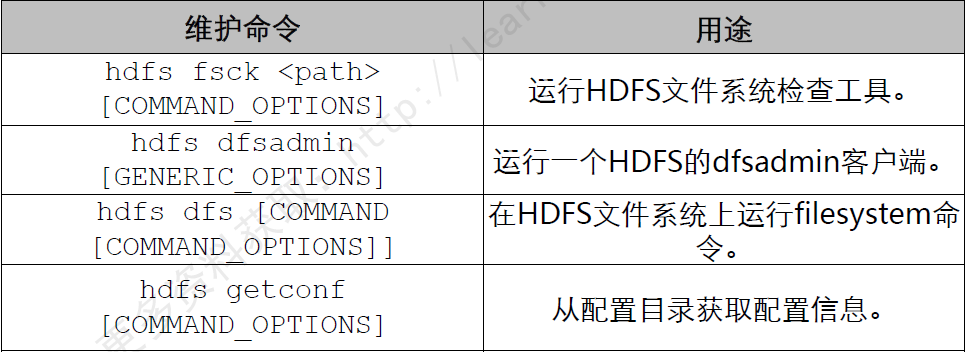
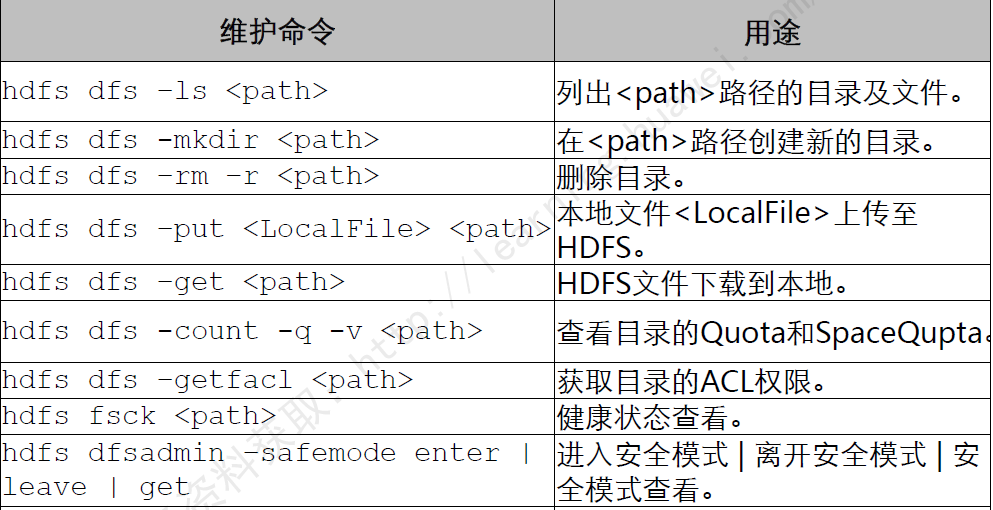
HDFS常用维护命令
往期推荐
喜欢的这里报道
↘↘↘
评论