
从 0 到 1 带你搭建 Java 并发爬虫框架(全文)
温馨提示:有效阅读本文大概需要15min
文章目录
前言
爬虫的原理与流程
爬虫框架搭建
一、新建 Spring Boot 项目
二、免费代理服务
三、HTTP 请求封装
四、业务爬取逻辑
五、云数据库
六、任务调度
前言
“数据是新一轮技术革命最重要的生产资料”,在互联网行业可以近似的说拥有了数据就拥有了市场。爬虫在互联网上无处不在,国内外的各大搜索引擎都是基于爬虫抓取信息后检索的,所以说 “互联网上 50% 的流量都是爬虫创造的” 这一点都不为过。近 2 年爬虫技术跟随着大数据的火热逐渐从台后走到台前,被越来越多的人所熟知,也被应用的越来越广泛,小到个人利用爬虫抓取数据分析建模,大到利用爬虫构建公司的内容和数据生态圈。所以爬虫已经成为一门 “平民化” 的技术,大家在工作和学习中都有用得着的地方。
爬虫的原理与流程
本场 Chat 重点是要讲述如何构建爬虫框架,但考虑到大家的对爬虫的了解程度不同,所以还是稍微带一下爬虫的原理和流程。
爬虫的原理其实很简单,其实跟在浏览器中输入一串 URL 地址并按下回车键后发生的事情是一样的(对于这个问题的理解有兴趣的童鞋可以参看:在浏览器中输入 URL 地址并回车后都发生了什么?),只不过爬虫的这些操作是用代码来实现的。
爬虫的主要目的就是爬取目标数据,但是为了达到这个目的,还需要很多辅助工作要做,比如前期的目标 URL 提取或页面分析,绕过登录限制,以及爬虫身份的隐藏、爬虫的调度和容错处理等,还有最后的数据清洗和入库。一个完整的爬虫程序应该是包含分析、爬取到入库等一系列流程的,为了直观我就画一个图来表示:
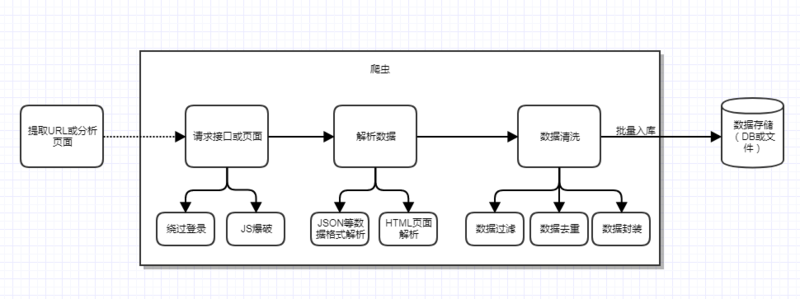
当然上面只是一个单线的爬虫流程,如果考虑到分布式和并发功能等,还需要继续加上任务调度功能。比如前期已经解析出了 URL,并发现了 URL 的数据分页关系,假定用 pageNumber 来表示分页 index,那么完全可以一次并发 10 个线程去跑 10 个任务,每个任务就是爬取指定 URL 的的数据,这样就可以大大提高爬取效率。
此外,前面还提到过容错处理,这里也说明一下,爬虫在爬取过程中有时可能会遇到突发异常,比如目标服务器异常、网络异常、对方实施了反扒策略等,这种情况我们也需要分别考虑到,通常需要加入重试机制,你可以自己定义什么类型的异常需要加入重试,比如请求失败,这可能被对方屏蔽了,也可能网络出现了震荡。所以这时候重试 2 次看看,如果重试还是失败,那么就可以放弃这次爬取任务了,你可以将失败的任务记录下来,后面等空闲或等实现失败任务定时调度功能,等待下一次的再次调度;并设置一个最大的调度失败次数(比如 3),超过这个次数,移除这个任务,以后都不用考虑了。
另外对于页面数据解析,要分 2 种情况,提取的种子 URL 请求后返回的是 JSON 或 XML 格式的,直接用 FastJson 来解析 JSON 即可,可是通常没有这么方便,很多时候需要我们去解析页面的 HTML 文档,这时候就需要用到 jsoup 来解析页面,从而拿到我们需要的数据。这些流程中具体的功能和问题都会在后面的框架搭建时体现。
爬虫框架搭建
主体框架采用现在比较火热的微服务框架 Spring Boot,HTTP 请求部分基于 HttpClient 封装,页面解析部分使用 FastJson + jsoup,数据储存采用 Bmob 后端云数据库。项目的整体架构如下图:
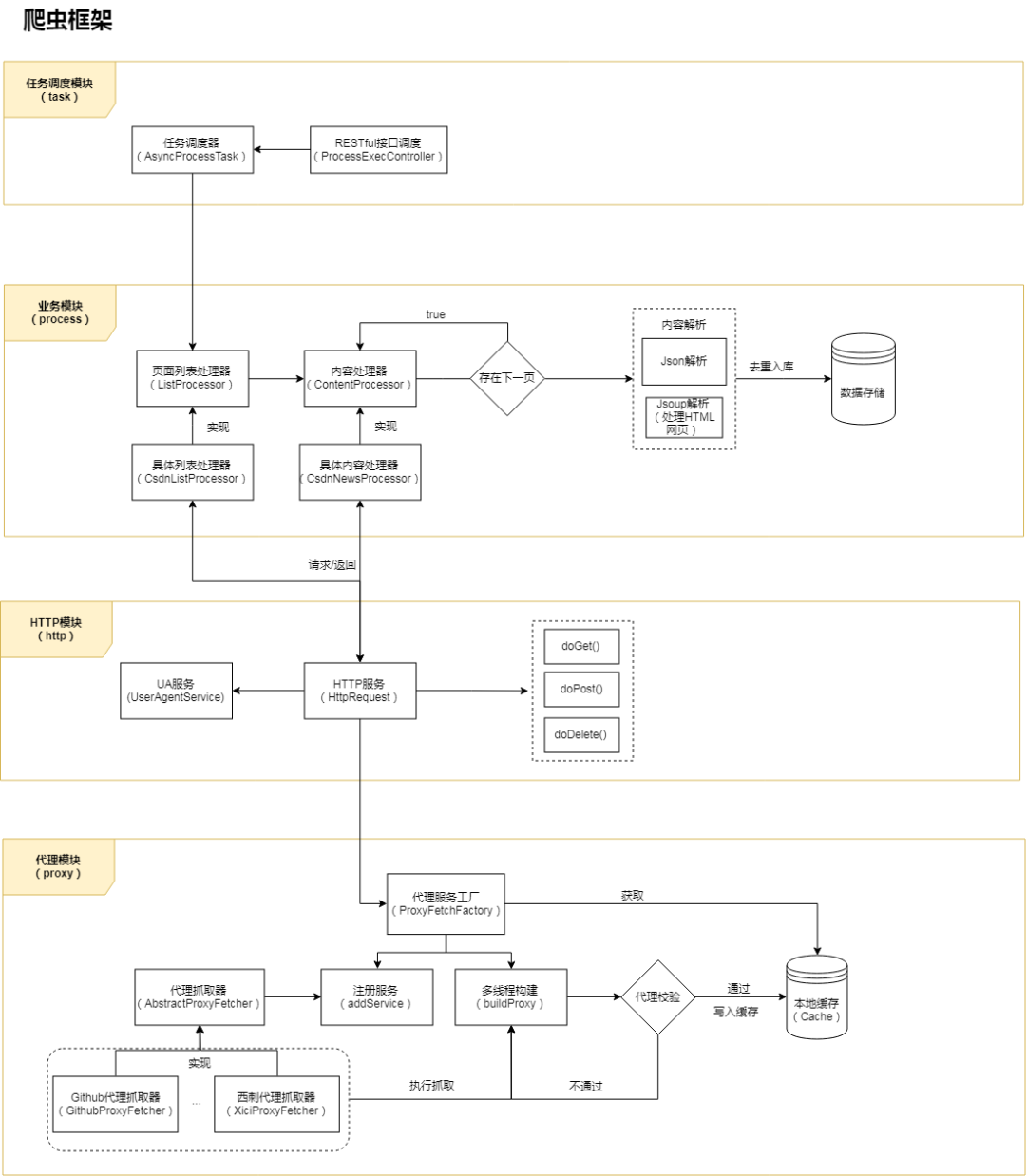
整个框架根据功能或业务分为 4 层 / 模块:代理层、HTTP 请求层、业务层、调度层。后面会依次介绍每一层的实现逻辑,首先我们从创建项目开始。
注:在学习和实践爬虫框架搭建时,建议将源码项目也在编辑器中打开,参考着源码看文章效果更好,因为文中不可能把所有代码都贴出来,未贴出的部分可以在源码中了解,这样更方便理解框架。
框架源码地址:
https://github.com/AlanYangs/spiders/tree/master/spider-framework
一、新建 Spring Boot 项目
本项目采用宇宙最强的 IDEA 开发工具,新建 Spring Boot 项目,JDK 建议选择 1.8(熟悉的同学可以跳过本小节):
下一步,输入项目的 group 和 artifact:
下一步,选择依赖,这里暂时就选择 Web:
下一步,输入 module 名称,项目创建完成。
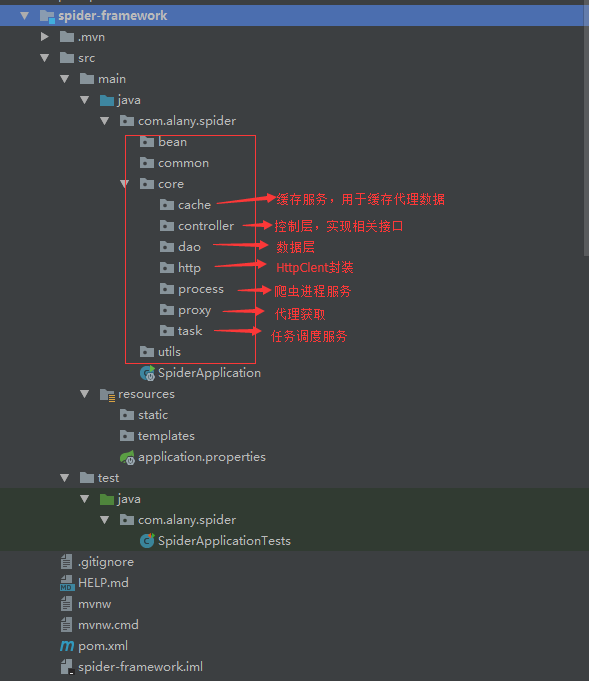
接着再新建一些后面需要用的包,整体的项目结构及核心包名的说明如下图所示:
再贴一下项目中所需要用到的依赖,这里就直接给出对应的 pom:
org.springframework.boot
spring-boot-starter-web
org.apache.httpcomponents
httpclient
4.5.5
com.google.guava
guava
18.0
org.jsoup
jsoup
1.11.2
com.alibaba
fastjson
1.2.51
commons-io
commons-io
2.6
org.springframework.boot
spring-boot-starter-test
test
下面按架构图中分层的功能和模块来逐步实现对应的功能和服务。
二、免费代理服务
要想爬虫健壮长久,肯定不能直接暴露本机 IP 去跑,这时候就需要用到代理池,每次请求都从带上代理去请求,从而隐藏爬虫的身份。市面上有不少专门做代理的公司,都是要收费的,价格还不便宜,每天 1000 个 IP 使用上限,按稳定时长区分,来感受一下包月的价格吧:
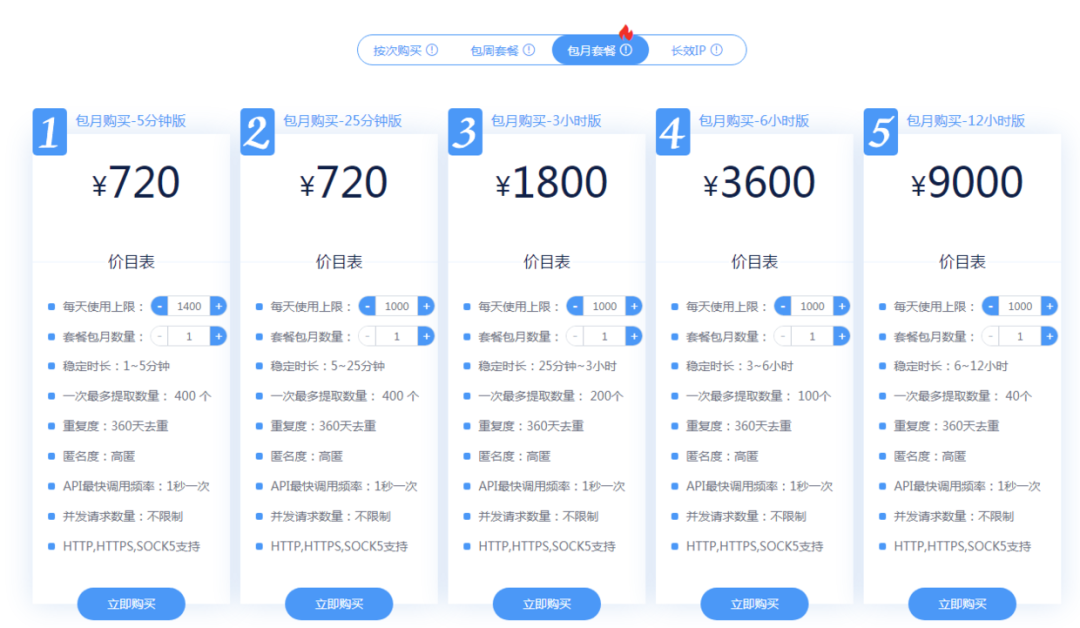
这价格一点都不美丽,所以我才想通过获取免费 IP 代理的方式来自己构建一个代理池。构建的思路就是参看各大代理网站上面都有提供一些免费的 IP 列表(举例:快代理),我们可以抓取一些下来然后校验一下它的可用性,加入到自己的代理池中。考虑到在代码实现中,IP 的抓取和校验都需要一定的时间,所以需要有一个缓存机制来存储,可以用 Redis 等,但考虑部署的问题,这里就用 Google 的 Guava Cache 来作为本地缓存存储代理 IP。
我们来封装一个 CacheService 服务,方便使用,代码如下:
@Service
public class CacheService {
private static final Logger LOGGER = LoggerFactory.getLogger(CacheService.class);
private int cacheMaxSize = 3000;
public void setCacheMaxSize(int cacheMaxSize) {
this.cacheMaxSize = cacheMaxSize;
}
// 缓存
private Cache cache = CacheBuilder.newBuilder()
.maximumSize(cacheMaxSize)
.removalListener(new RemovalListener() { //移出缓存时执行的操作
@Override
public void onRemoval(RemovalNotification notification) {
if (notification.wasEvicted()) {
LOGGER.debug("key[" + notification.getKey() + "] was removed with expired.");
} else {
LOGGER.debug("key[" + notification.getKey() + "] was updated with put operation.");
}
}
})
.build();
public boolean containsKey(K key) {
try {
return cache.getIfPresent(key) != null;
} catch (Exception e) {
return false;
}
}
public long size() {
return cache.size();
}
public V get(K key) {
return cache.getIfPresent(key);
}
public ConcurrentMap getAll() {
return cache.asMap();
}
public List getValues(){
return new ArrayList(getAll().values());
}
public void put(K key, V value) {
cache.put(key, value);
LOGGER.debug(String.format("put key %s with value %s to cache...", key, JSON.toJSONString(value)));
}
public void remove(K key) {
if (containsKey(key)) {
cache.invalidate(key);
}
}
}
由于需要从多个免费代理网站上获取代理,所以这里采用 Factory 工厂模式,类之间的继承关系如下图:
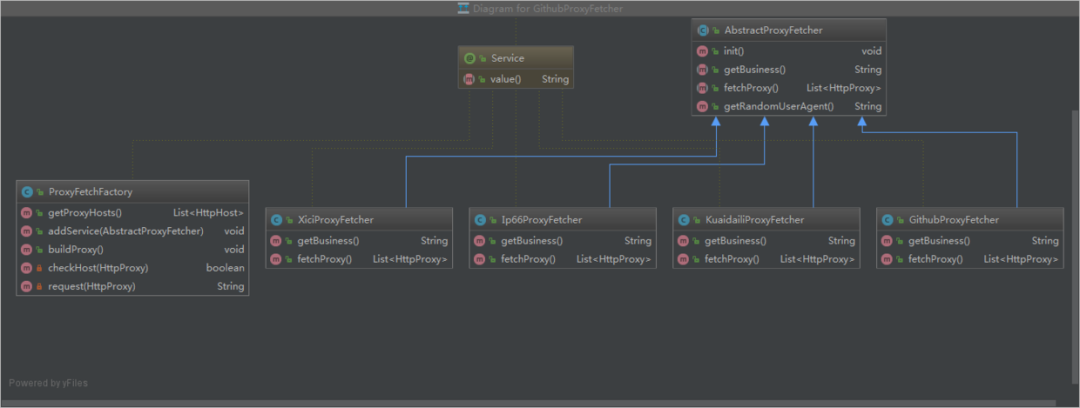
各具体的代理抓取实现类会实现各自的爬取方法,并会在初始化时自动注册到工厂类 ProxyFetchFactory 中,然后在工厂类中统一构建和多线程执行。下面看一下工厂类 ProxyFetchFactory 的实现代码:
@Service
public class ProxyFetchFactory {
private static final Logger LOGGER = LoggerFactory.getLogger(ProxyFetchFactory.class);
private static final int MAX_TIMEOUT_MS = 2000;//ms
private List proxyServices = new ArrayList<>();
private CacheService cacheService = SpringContext.getBean(CacheService.class);
public List getProxyHosts() {
return cacheService.getValues();
}
public void addService(AbstractProxyFetcher proxyService) {
proxyServices.add(proxyService);
}
public void buildProxy() {
List proxies = null;
List> futures = new ArrayList<>();
for (AbstractProxyFetcher proxyService : proxyServices) {
if (!proxyService.getBusiness().equals("github")){
continue;
}
try {
proxies = proxyService.fetchProxy();
} catch (Exception e) {
LOGGER.error("fetch " + proxyService.getBusiness() + " proxy meet error", e);
continue;
}
if (proxies != null && !proxies.isEmpty()) {
ExecutorService es = Executors.newFixedThreadPool(10);
for (final HttpProxy proxy : proxies) {
futures.add((Future) es.submit(new Runnable() {
@Override
public void run() {
proxy.setValid(checkHost(proxy));
}
}));
}
es.shutdown();
for (Future future : futures) {
try {
future.get();
} catch (Exception e) {
}
}
}
}
LOGGER.info("valid host total size: " + getProxyHosts().size());
}
private boolean checkHost(final HttpProxy httpProxy) {
boolean isValid = false;
ExecutorService executor = Executors.newSingleThreadExecutor();
FutureTask future = new FutureTask(new Callable() {//使用Callable接口作为构造参数
public String call() {
//搜索任务异步处理
return request(httpProxy);
}
});
executor.execute(future);
String content = null;
try {
content = future.get(MAX_TIMEOUT_MS, TimeUnit.MILLISECONDS); //在执行超时时间内获取结果
} catch (Exception e) {
future.cancel(true);
} finally {
executor.shutdown();
}
isValid = StringUtils.isNotBlank(content) && content.indexOf("百度") > 0;
LOGGER.info(httpProxy.getProvider() + " - " + httpProxy.getAddress() + " : " + isValid);
if (isValid) {
cacheService.put(httpProxy.getAddress() + ":" + httpProxy.getPort(), httpProxy.toHost());
LOGGER.info("cache size:" + cacheService.size());
}
return isValid;
}
private String request(HttpProxy httpProxy) {
String content = null;
InetSocketAddress addr = null;
URLConnection conn = null;
InputStream in = null;
try {
//Proxy类代理方法
URL url = new URL("http://www.baidu.com");
// 创建代理服务器
addr = new InetSocketAddress(httpProxy.getAddress(), httpProxy.getPort());
Proxy proxy = new Proxy(Proxy.Type.HTTP, addr); // http 代理
conn = url.openConnection(proxy);
in = conn.getInputStream();
content = IOUtils.toString(in);
} catch (Exception e) {
return null;
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return content;
}
}
代理的构建和多线程爬取是在 buildProxy() 方法中实现的,对于抓取下来的免费代理,我们还需要验证一下可用性,有些代理已经失效或本身就不可用,这种我们需要排除掉,通过 checkHost() 来验证,验证逻辑其实就是用抓取的代理加到 HTTP 请求,看能不能跑通,超时或不通则可以判定该代理无效。
具体实现类的抓取逻辑其实就是一个简单的爬虫逻辑,根据种子 URL 作为入口,抓取页面所需的内容,这里举例快代理的页面解析逻辑(KuaidailiProxyFetcher 类),代码如下:
@Service("kuaidailiNewProxyService")
public class KuaidailiProxyFetcher extends AbstractProxyFetcher {
private static final Logger LOGGER = LoggerFactory.getLogger(KuaidailiProxyFetcher.class);
private static final String KUAIDAILI_FREE_PROXY_URL = "https://www.kuaidaili.com/proxylist/%d";
@Override
public String getBusiness() {
return "kuaidaili";
}
@Override
public List fetchProxy() {
Document doc = null;
List list = new ArrayList<>();
Random random = new Random();
for (int i = 1; i < 10; i++) {
String url = String.format(KUAIDAILI_FREE_PROXY_URL, i);
String refererUrl = i > 1 ? String.format(KUAIDAILI_FREE_PROXY_URL, i-1) : "";
try {
doc = jsoup.connect(url)
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3")
.header("Accept-Encoding", "gzip, deflate, br")
.header("Accept-Language", "zh-CN,zh;q=0.9")
.header("User-Agent", getRandomUserAgent())
.header("Host", "www.kuaidaili.com")
.header("Referer", refererUrl)
.timeout(30 * 1000)
.get();
Elements ipElms = doc.select("td[data-title=\"IP\"]");
Elements portElms = doc.select("td[data-title=\"PORT\"]");
Elements typeElms = doc.select("td[data-title=\"类型\"]");
if (ipElms != null) {
for (int j = 0, length = ipElms.size(); j < length; j++) {
String ip = ipElms.get(j).text();
String port = portElms.get(j).text();
if (StringUtil.isBlank(ip) || StringUtil.isBlank(port)) {
continue;
}
HttpProxy httpProxy = new HttpProxy(ip, Integer.parseInt(port));
String type = typeElms.get(j).text();
if (StringUtils.isNotBlank(type) && !type.contains(",")) {
httpProxy.setType(type.toLowerCase());
}
httpProxy.setProvider(getBusiness());
list.add(httpProxy);
}
}
Thread.sleep(random.nextInt(5) * 1000);
} catch (Exception e) {
LOGGER.error("fetch proxy meet error with url["+ url +"]: ", e);
}
}
LOGGER.info("fetch [" + getBusiness() + "] proxy list size=" + list.size());
return list;
}
}
代码主要在 fetchProxy() 方法,拿到返回结果后使用的是 jsoup 来解析,鉴于篇幅关系,关于 jsoup 的使用我就详细介绍了,不熟悉的同学请参看 jsoup 中文文档,关键就在于查找 DOM 文档的元素,然后拿到对应的值。
这一部分搭建完以后,我们起一个 Test 来测试一下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpiderApplicationTests {
@Autowired
private ProxyFetchFactory proxyFetchFactory;
@Test
public void testProxyFetch() {
proxyFetchFactory.buildProxy();
}
}
下面贴一下结果,总共跑了 12 分钟,抓取到了 346 个有用的代理 IP,耗时 12 分钟主要是检验代理有效性上面的耗时较多,所以才需要用缓存或者队列来存储代理数据从而避免后续任务的阻塞,不然后面的业务爬取就要阻塞等待,等代理抓取完了才能跑。

三、HTTP 请求封装
爬虫就是基于网络请求的业务,那么当然需要进行大量 HTTP 请求,为了方便使用,这里需要对 HttpClient 做一下封装。按照链式调用的方式封装参数和方法,下面给出 HTTP 请求的 HttpRequest 类代码参考:
@Service("httpRequest")
public class HttpRequest {
private static Logger logger = LoggerFactory.getLogger(HttpRequest.class);
private boolean useProxy = true; //默认请求时使用代理
private String url;
private Map headers;
private Map params;
private String content;
private ContentType contentType;
private ProxyFetchFactory proxyFetchFactory = SpringContext.getBean(ProxyFetchFactory.class);
public HttpRequest() {
}
public HttpRequest(String url) {
this.url = url;
}
public HttpRequest setUrl(String url) {
this.url = url;
return this;
}
public HttpRequest setHeaders(Map headers) {
this.headers = headers;
return this;
}
public HttpRequest setParams(Map params) {
this.params = params;
return this;
}
public HttpRequest setContent(String content, ContentType contentType) {
this.content = content;
this.contentType = contentType;
return this;
}
public HttpRequest setUseProxy(boolean useProxy) {
this.useProxy = useProxy;
return this;
}
public CloseableHttpClient getSSLHttpClient() throws Exception {
//设置代理IP、端口、协议
RequestConfig config = null;
if (useProxy && proxyFetchFactory != null){
List proxyHosts = proxyFetchFactory.getProxyHosts();
if (proxyHosts != null && !proxyHosts.isEmpty()) {
int index = new Random().nextInt(proxyHosts.size());
HttpHost host = proxyHosts.get(index);
logger.info("url: " + url + ", proxy: " + host.toHostString());
//请求配置,设置链接超时和读取超时
config = RequestConfig.custom().setProxy(host).setConnectTimeout(30000).setSocketTimeout(30000).build();
}
}
if (config == null) {
config = RequestConfig.custom().setConnectTimeout(30000).setSocketTimeout(30000).build();
}
try {
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() {
public boolean isTrusted(X509Certificate[] paramArrayOfX509Certificate, String paramString) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext, SSLConnectionSocketFactory.ALLOW_ALL_HOSTNAME_VERIFIER);
return HttpClients.custom().setSSLSocketFactory(sslsf).setDefaultRequestConfig(config).build();
} catch (Exception e) {
throw e;
}
}
public HttpResult doGet() {
try {
//HttpClient client = HttpClients.createDefault();
HttpClient client = getSSLHttpClient();
//发送get请求
HttpGet request = new HttpGet(url);
if (headers != null && headers.size() > 0) {
for (Map.Entry header : headers.entrySet()) {
request.setHeader(header.getKey(), String.valueOf(header.getValue()));
}
}
if (params != null && params.size() > 0) {
StringBuilder sb = new StringBuilder();
if (!url.contains("?")) {
sb.append("?");
}
for (Map.Entry param : params.entrySet()) {
sb.append(param.getKey() + "=" + param.getValue() + "&");
}
sb.deleteCharAt(sb.lastIndexOf("&"));
url = url + sb.toString();
}
HttpResponse response = client.execute(request, new BasicHttpContext());
return new HttpResult(response.getStatusLine().getStatusCode(), EntityUtils.toString(response.getEntity()));
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public HttpResult doPost() {
try {
//HttpClient client = HttpClients.createDefault();
HttpClient client = getSSLHttpClient();
//发送get请求
HttpPost request = new HttpPost(url);
//设置url
request.setURI(new URI(url));
setParams(request);
HttpResponse response = client.execute(request);
return new HttpResult(response.getStatusLine().getStatusCode(), EntityUtils.toString(response.getEntity()));
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public HttpResult doPut(){
//参看项目源码
}
public HttpResult doDelete() {
//参看项目源码
}
private void setParams(HttpEntityEnclosingRequestBase request) throws UnsupportedEncodingException {
if (headers != null && headers.size() > 0) {
for (Map.Entry header : headers.entrySet()) {
request.setHeader(header.getKey(), String.valueOf(header.getValue()));
}
}
List nvps = new ArrayList();
//设置参数
if (params != null && params.size() > 0) {
for (Iterator iter = params.keySet().iterator(); iter.hasNext(); ) {
String name = (String) iter.next();
String value = String.valueOf(params.get(name));
nvps.add(new BasicNameValuePair(name, value));
}
request.setEntity(new UrlEncodedFormEntity(nvps, HTTP.UTF_8));
}
//设置内容
if (content != null) {
contentType = contentType == null ? ContentType.APPLICATION_JSON : contentType;
request.setEntity(new StringEntity(content, contentType));
}
}
}
定义了各种参数的 setter 方法,调用的时候就非常简单了,按照链式调用即可:
httpRequest.setUrl(url).setHeaders(headers).doGet();
另外,有一点需要注意,请求的时候 header 需要带上 UserAgent 信息,这是一个最简单的爬虫伪装,不加直接就被判定为爬虫或机器人了,这里采用简单的一点的做法,搜集一些已知的 UA 信息写到一个 TXT 文件中,然后初始化的时候将 UA 信息加载到 List 中,后面在请求的时候随机遍历 List 的值即可。代码就不贴了,可以参看源码的 UserAgentService 类。
四、业务爬取逻辑
这一部分是爬虫的业务部分,也就是说跟你爬取的数据对象有关系,有时候我们需要爬取网页的全部内容,比如资讯类的文章信息;而有时候我们需要爬取网页里面的特定内容,比如京东淘宝的商品价格信息,这时候就需要对页面内容进行定位和过滤。文中我们就以爬取 CSDN 的热门文章来举例。首先,我们还是来看一下各类之间的关系,如下图:
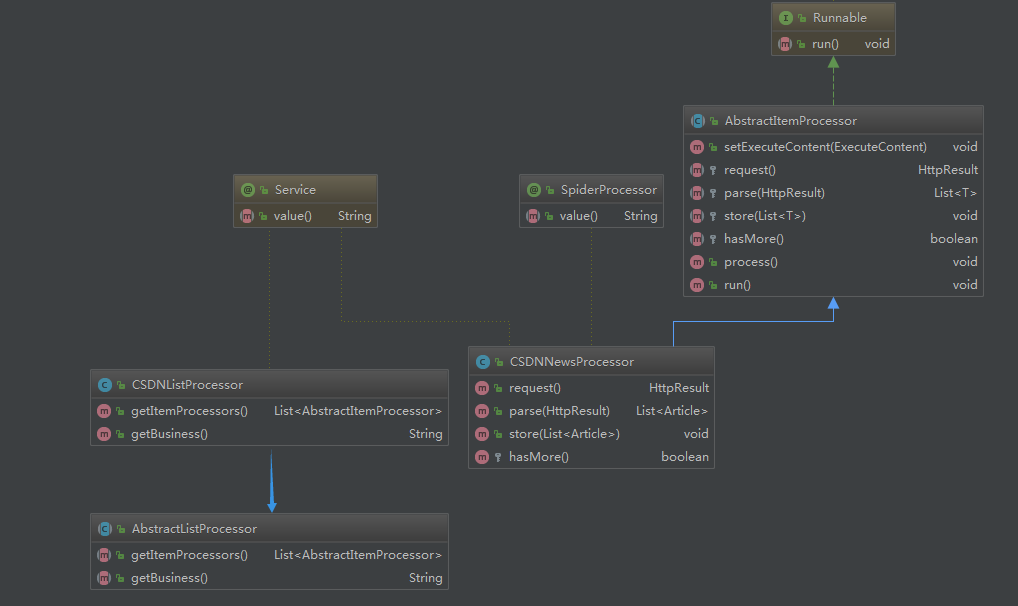
从上面类图中可以看到有 2 个抽象类,这是便于业务扩展用的,后面如果还需写其他页面的爬虫,比如需要爬取知乎热榜的文章,直接套着当前框架就能写,加 2 个对应的实现类,实现知乎热榜具体的页面解析即可。下面具体解释一下这 2 个类的用法。
1. AbstractListProcessor 类
抽象页面列表处理器,目的就是构建多个页面内容处理器,通常是按分页来构建。
public abstract class AbstractListProcessor {
/**
* 内容处理器列表
* @return
*/
public abstract List getItemProcessors();
/**
* 业务名称
* @return
*/
public abstract String getBusiness();
}
定义了 2 个抽象方法,需要子类去实现,下面我们看一下它的实现类:
@Service
public class CSDNListProcessor extends AbstractListProcessor {
private static final String API_NEWS_URL = "https://www.csdn.net/api/articles?type=more&category=news&shown_offset=%s";
private long offset = System.currentTimeMillis() * 1000; //初始offset值,16位
private int maxPageNumber = 10; //最大的分页数
@Override
public List getItemProcessors() {
List list = new ArrayList<>();
for (int i = 0; i < maxPageNumber; i++) {
ExecuteContent executeContent = new ExecuteContent();
long currOffset = offset + i * 10; //由于接口每次返回10条记录,所以offset按10递增
executeContent.setUrl(String.format(API_NEWS_URL, ""));//多次调试发现这种方式可以不传offset,接口每次会自动更新
executeContent.setBusiness(getBusiness());
Map params = new HashMap();
params.put("offset", currOffset);
executeContent.setParams(JSON.toJSONString(params));
CSDNNewsProcessor csdnNewsProcessor = new CSDNNewsProcessor();
csdnNewsProcessor.setExecuteContent(executeContent);
list.add(csdnNewsProcessor);
}
return list;
}
@Override
public String getBusiness() {
return "CSDN";
}
}
代码说明:
在实现类中就比较清晰的能看出来,在 getItemProcessors() 方法中是需要构建一个后面页面内容处理器所需要的一些参数,包括入口 URL、业务名称、一些后面需要用到的参数等,然后通过 ExecuteContent 对象进行传递;
这里的循环逻辑,也可以在具体内容处理器的 hasMore() 方法中实现,后面对应内容时会提到;
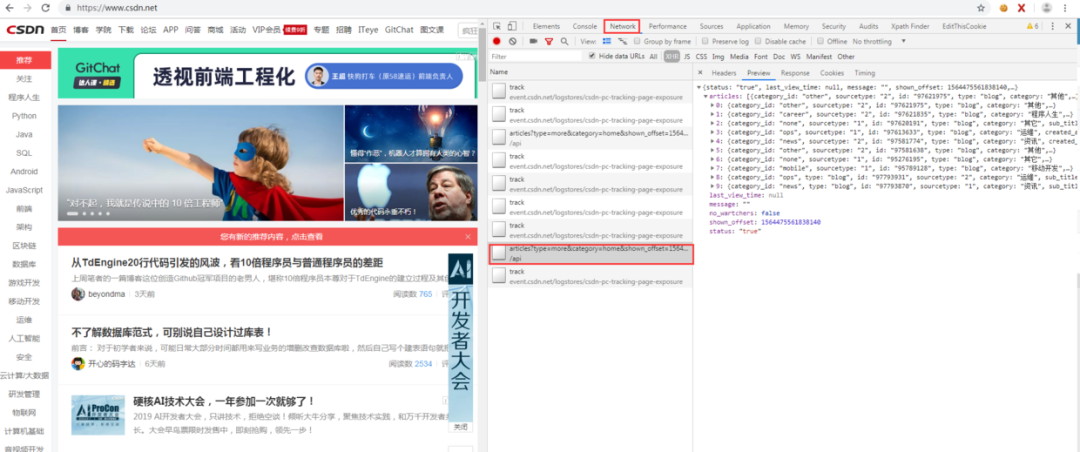
照顾一下基础较差的同学,怕有些同学不知道这个入口 URL 是怎么来的,其实就是爬虫流程中的前期阶段需要做的工作,对页面进行分析提取出入口 URL,如下图,在分析 CSDN 首页时 F12 打开 Chrome 浏览器的调试器,在网络那个 tab 可以看到页面的请求信息,可以看到这个 URL 就是后台的获取文章信息的接口:
2. AbstractItemProcessor 类
抽象页面内容处理器,这里面定义了爬取页面所需要的一系列操作,包括请求、解析、入库等,此外它还是一个线程类,用于在任务调度时多线程并发执行。
public abstract class AbstractItemProcessor implements Runnable{
private static final Logger LOGGER = LoggerFactory.getLogger(AbstractItemProcessor.class);
public List userAgentList = new ArrayList<>();
public SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public ExecuteContent executeContent;
public void setExecuteContent(ExecuteContent executeContent) {
this.executeContent = executeContent;
}
/**
* 请求
*
* @return
*/
protected abstract HttpResult request();
/**
* 解析
*/
protected abstract List parse(HttpResult result);
/**
* 入库
*/
protected abstract void store(List list);
/**
* 是否有下一页
*/
protected abstract boolean hasMore();
/**
* 入口:整合流程
*/
public void process() throws InterruptedException {
UserAgentService userAgentService = SpringContext.getBean(UserAgentService.class);
userAgentList = userAgentService.getUserAgentList();
HttpResult result = null;
List list = null;
int retryTimes = 0;
do {
while (result == null && retryTimes < 3) { //请求失败重试3次
result = request();
retryTimes ++;
Thread.sleep(5000);
}
list = parse(result);
store(list);
} while (hasMore());
}
@Override
public void run() {
LOGGER.info("executing processor: " + executeContent.toString());
try {
process();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
将请求、解析、入库和分页判断,这些按业务可能有差异的过程抽象出来,让业务实现类自己去实现,其中请求的过程加了失败重试(默认 3 次)机制,此外该类实现了 Runnable 接口,也就是说它及其子类都是一个线程类,用于后续任务的多线程执行。下面看一个业务实现类 CSDNNewsProcessor:
@SpiderProcessor
@Service("csdnNewsProcessor")
public class CSDNNewsProcessor extends AbstractItemProcessor {
private static Logger logger = LoggerFactory.getLogger(CSDNNewsProcessor.class);
private ArticleCouldDBService articleCouldDBService = SpringContext.getBean(ArticleCouldDBService.class);
private HttpRequest httpRequest = SpringContext.getBean(HttpRequest.class);
@Override
public HttpResult request() {
Map headers = new HashMap<>();
if (userAgentList != null && !userAgentList.isEmpty()) {
int index = new Random().nextInt(userAgentList.size());
headers.put("User-Agent", userAgentList.get(index));
}
HttpResult result = httpRequest.setUrl(executeContent.getUrl()).setHeaders(headers).doGet();
return result;
}
@Override
public List parse(HttpResult result) {
List list = new ArrayList<>();
if (result != null && StringUtils.isNotEmpty(result.getContent())) {
try {
JSONObject root = JSON.parseObject(result.getContent());
JSONArray articles = root.getJSONArray("articles");
if (articles != null && !articles.isEmpty()) {
for (int i = 0, length = articles.size(); i < length; i++) {
JSONObject item = articles.getJSONObject(i);
Article article = new Article();
article.setSourceName(executeContent.getBusiness());
article.setTitle(item.getString("title"));
article.setArticleId(item.getString("id"));
article.setAuthor(item.getString("nickname"));
article.setUrl(item.getString("url"));
String category = item.getString("category");
if (StringUtils.isEmpty(category)) {
category = item.getString("tag");
}
article.setCategory(category);
article.setDescription(item.getString("desc"));
article.setImgUrl(item.getString("avatar"));
Date now = new Date();
article.setPublishTime(sdf.format(now));
if (StringUtils.isNotBlank(article.getTitle()) && StringUtils.isNotBlank(article.getUrl())) {
list.add(article);
}
}
}
} catch (Exception e) {
logger.error("parse json to bean meet error:", e);
}
}
return list;
}
@Override
public void store(List list) {
if (list != null && !list.isEmpty()) {
for (Article article : list) {
articleCouldDBService.insert(article);
}
}
}
@Override
protected boolean hasMore() {
// long currMs = System.currentTimeMillis();
// Map paramsMap = (Map) JSON.parse(executeContent.getParams());
// long offset = Long.parseLong(String.valueOf(paramsMap.get("offset")).substring(0,Long.toString(currMs).length()));//就取毫秒级别的时间戳作为比较
// return offset < currMs;
return false;
}
}
代码说明:
上面内容处理器的类名前面加了一个自定义的注解 @SpiderProcessor ,也是为了后面任务调度的需要;
request() 方法对应的是请求过程,唯一需要注意的就是 header 中需要加入随机的 UserAagent;
parse() 方法对应的是页面数据解析过程,解析的是请求返回的结果,刚好上面的 CSDN 中的例子返回的是 JSON 数据,所以我们直接用 FastJson 来解析就 ok 了(如果返回的是 HTML 文本数据,就用 jsoup 来处理,可以参考之前的代理模块),就是简单的 JSON 解析过程,就不多说了;
store() 方法对应的是数据存储过程,这里应用的是云数据库存储,后面一节会具体介绍;
hasMore() 方法是判断当前爬虫是否结束?类似于是否存在分页,由于前面列表处理器中已经加入了 offset 自增,所以这里直接返回 false 即可,如果列表处理器没有处理自增逻辑,那么可以按照 hasMore() 方法代码注释部分来实现循环爬取。
五、云数据库
数据入库,你当然可以入库到本地的 MySQL 数据库,甚至写入到文件中,可是这里我想介绍一下云数据库,顾名思义,就是数据存储在第三方云服务器上,对于个人开发者自己因为兴趣或学习去开发 App 或小程序应用,最烦恼的就是后端,自己去写一个后端服务成本太高,服务器成本和运维成本都得不偿失,所以这时候就想到了云数据库,这里推荐 Bmob(官网地址)的云数据库,我从 17 年开始使用的,App 和小程序的后台数据都存在 Bmob 的云数据库上,暂时还有免费版,下面简要说一下 Bmob 云数据库的使用步骤:
1. 去 Bmob 官网申请账号。
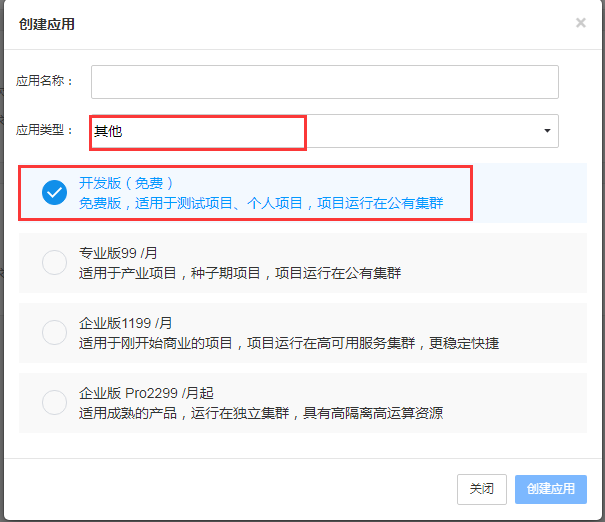
2. 创建应用,选择开发版,应用类型选其他:
3. 进入应用设置的应用秘钥页面,可以看到有 AppId 和几个 key,后面代码时需要用到:
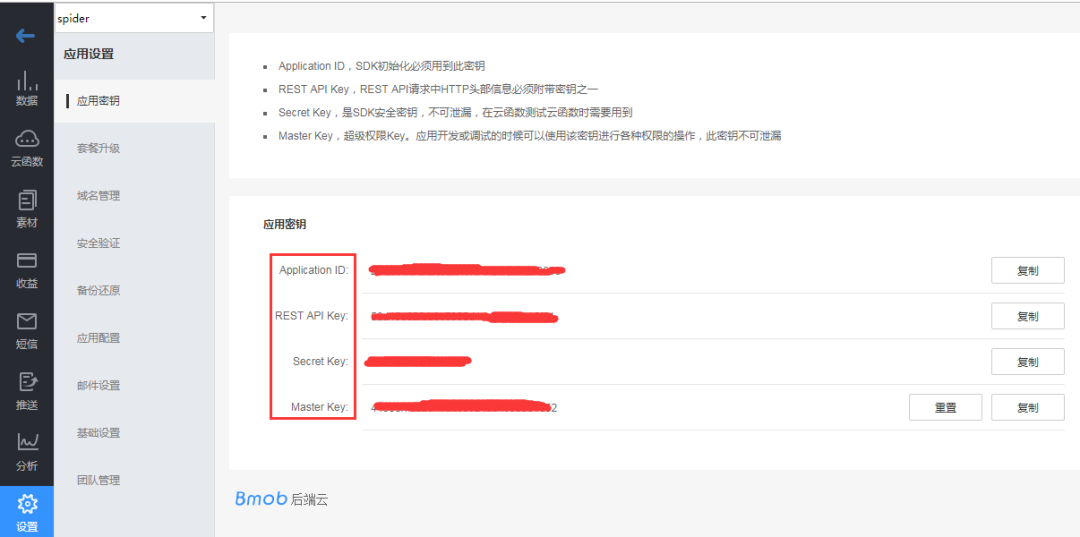
4. 创建表结构,需要注意下在 Bmob 后台创建表结构时字段要和代码中的表 bean 对象的属性要一致;
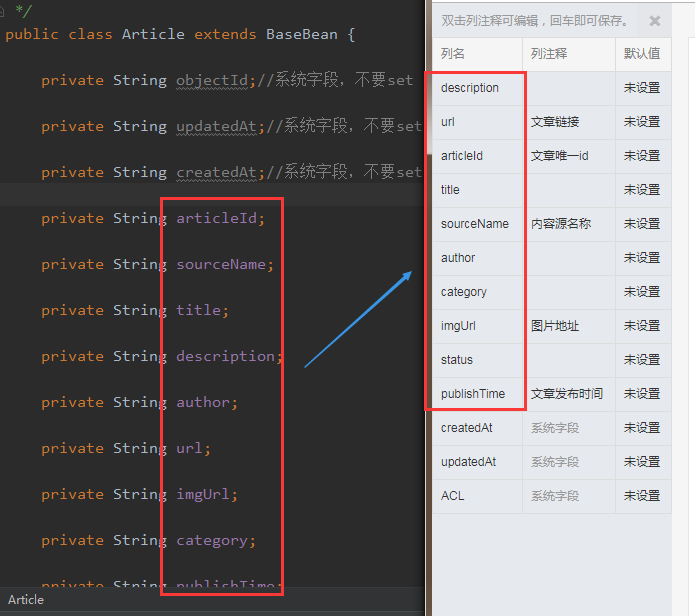
5. 前面准备工作做好后,就可以开始编码了,下面就参考 API 文档(文档地址),来封装代码,类关系图如下:
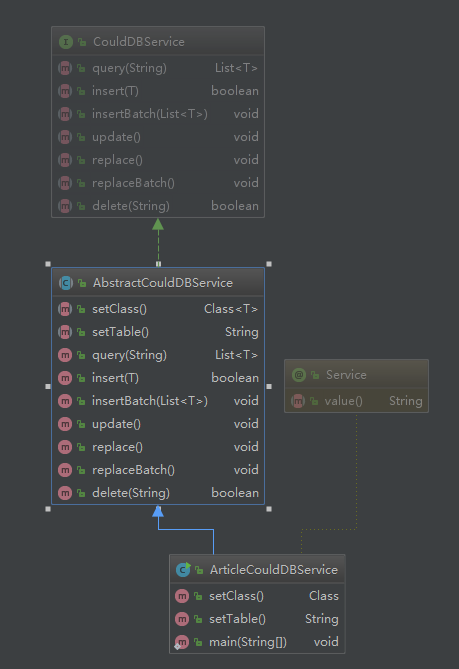
CouldDBService 是一个接口,定义了需要实现的方法
AbstractCouldDBService 是一个实现了通用方法的业务抽象类
ArticleCouldDBService 是一个具体的表实现类,主要功能在 AbstractCouldDBService 类中:
public abstract class AbstractCouldDBService implements CouldDBService {
private static Logger logger = LoggerFactory.getLogger(AbstractCouldDBService.class);
private static final String APP_ID = "68ab2056a549e0f640dfc1e801bf6915"; //对应应用秘钥的Application ID
private static final String API_KEY = "f8eee065e9e011ecd7e98e4256373629"; //对应应用秘钥的REST API Key
private static final String API_HOST_BASE = "https://api2.bmob.cn/1/";
private static final String API_TABLE_URL = API_HOST_BASE + "classes/%s";
private HttpRequest httpRequest = SpringContext.getBean(HttpRequest.class);
private static Map headers;
static {
headers = new HashMap<>();
headers.put("X-Bmob-Application-Id", APP_ID);
headers.put("X-Bmob-REST-API-Key", API_KEY);
headers.put("Content-Type", "application/json");
}
public abstract Class setClass();
public abstract String setTable();
@Override
public List query(String whereAs) {
String url = String.format(API_TABLE_URL, setTable());
if (whereAs != null && !whereAs.isEmpty()) {
try {
whereAs = URLEncoder.encode(whereAs, "utf-8");
} catch (UnsupportedEncodingException e) {
logger.error("encode params["+ whereAs +"] meet error: ", e);
}
url += "?where=" + whereAs;
}
logger.info("query url: " + url);
HttpResult response = httpRequest.setUrl(url).setHeaders(headers).setUseProxy(false).doGet();
if (response == null) {
throw new RuntimeException("request error: response is null");
}
if (200 == response.getCode()) {
try {
String res = response.getContent();
JSONArray dataArray = JSON.parseObject(res).getJSONArray("results");
if (dataArray != null && !dataArray.isEmpty()) {
List list = new ArrayList();
for (int i = 0, length = dataArray.size(); i < length; i++) {
JSONObject data = dataArray.getJSONObject(i);
list.add(data.toJavaObject(setClass()));
}
logger.info("query success and result size=" + list.size());
return list;
}
} catch (Exception e) {
logger.error("parse response meet error: ", e);
}
} else {
logger.error("request error: response=" + response.toString());
}
return null;
}
@Override
public boolean insert(T bean) {
String url = String.format(API_TABLE_URL, setTable());
if (bean == null) {
logger.error("insert failed: bean is null");
return false;
}
Map beanMap = bean.toMap();
HttpResult response = httpRequest.setUrl(url).setUseProxy(false).setHeaders(headers)
.setContent(JSON.toJSONString(beanMap), ContentType.APPLICATION_JSON).doPost();
if (response == null) {
throw new RuntimeException("request error: response is null");
}
if (201 == response.getCode()) {
logger.info("success to insert bean ["+ JSON.toJSONString(beanMap) +"]");
return true;
} else {
logger.error("failed to insert bean ["+ JSON.toJSONString(beanMap) +"], msg:" + response.getContent());
return false;
}
}
@Override
public void insertBatch(List list) {
String url = API_HOST_BASE + "batch";
if (list == null || list.isEmpty()) {
return;
}
JSONArray reqArray = new JSONArray();
for (T t : list) {
JSONObject item = new JSONObject();
item.put("method", "POST");
item.put("path", "1/classes/" + setTable());
item.put("body", JSON.toJSONString(t.toMap()));
reqArray.add(item);
}
JSONObject contentJson = new JSONObject();
contentJson.put("requests", reqArray);
HttpResult response = httpRequest.setUrl(url).setUseProxy(false).setHeaders(headers)
.setContent(contentJson.toJSONString(), ContentType.APPLICATION_JSON).doPost();
if (response == null) {
throw new RuntimeException("request error: response is null");
}
System.out.println(response.toString());
}
@Override
public void update() {
}
@Override
public void replace() {
}
@Override
public void replaceBatch() {
}
@Override
public boolean delete(String objectId) {
if (objectId == null || "".equals(objectId)) {
return false;
}
String url = String.format(API_TABLE_URL, setTable()) + "/" + objectId;
HttpResult response = httpRequest.setUrl(url).setUseProxy(false).setHeaders(headers).doDelete();
if (response == null) {
throw new RuntimeException("request error: response is null");
}
JSONObject retJson = JSON.parseObject(response.getContent());
boolean isSuccess = "ok".equalsIgnoreCase(retJson.getString("msg"));
if (isSuccess) {
logger.info("success to delete row [objectId="+ objectId +"]");
} else {
logger.error("failed to delete row [objectId="+ objectId +"], msg:" + response.getContent());
}
return isSuccess;
}
}
代码说明:
记得将上面的 APPID 和 key 换成自己在 Bmob 上面创建的
这里封装了一个支持泛型的抽象云数据服务类,这样设计的好处就是可以支持多个表
原 API 文档中只提供了 RESTful 接口供调用,这里通过 HTTP 请求封装了增删查方法
下面再看一个具体表的实现类:
@Service("articleCouldDBService")
public class ArticleCouldDBService extends AbstractCouldDBService {
@Override
public Class setClass() {
return Article.class;
}
@Override
public String setTable() {
return "t_articles";
}
}
表的实现类非常简单,只需要指定表名和对象类型,这样设计的好处,在有多个表的时候就体现出来了,无需额外修改代码,只需要增加表的实现类即可。
下面写一个测试方法来测试一下 ArticleCouldDBService 类:
@Test
public void testArticleCouldDBSeervice(){
List articles = new ArrayList<>();
Article article = new Article();
article.setArticleId("test12345678");
article.setTitle("insert test");
article.setSourceName("测试数据");
articles.add(article);
articleCouldDBService.insert(article);
articles.clear();
articles = articleCouldDBService.query("{\"articleId\":\"test12345678\"}");
System.out.println(articles);
}
从打印的 log 中可以看到插入和查询都正常,再去 Bmob 的后台表中可以看到记录成功插入。
六、任务调度
一个多层的爬虫任务架构应该至少是下图这样的(有兴趣的同学,可以按此架构去试着搭一个 task 模块或者微服务,那样架构更加完整和清晰),但是考虑到实施的复杂程度,所以本 Chat 就不对任务做分层和分库处理了,处理简单一点,就按照之前上面的项目整体架构图来实施,把任务调度简单化。
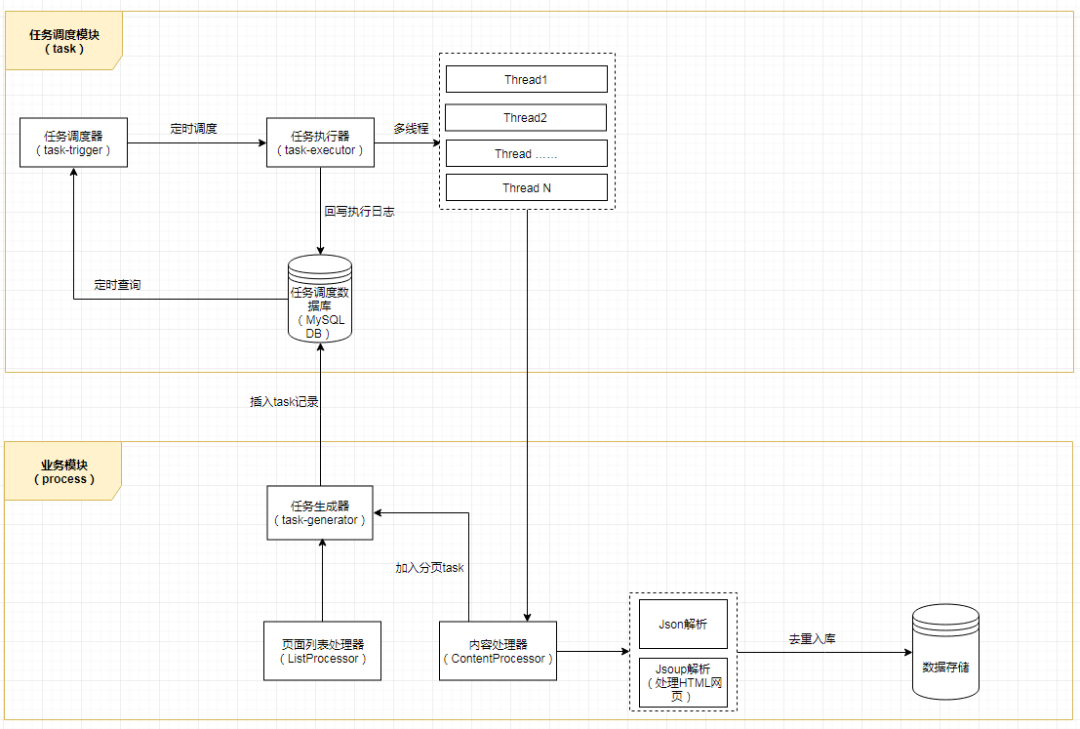
先忘掉上面的任务架构,我们还是按照最开始前面说的架构图(不记得了?翻回去再加深一下记忆),我们需要实现一个任务调度器,可以按业务调起任务,可以定时调度任务,这里需要用到 Spring 相关知识,先看代码:
@Service("asyncProcessTask")
public class AsyncProcessTask {
private static final Logger LOGGER = LoggerFactory.getLogger(AsyncProcessTask.class);
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
private ApplicationContext context = SpringContext.getApplicationContext();
/**
* 初始化代理爬取,触发代理爬取
*/
public void initProxy() {
Map serviceBeanMap = context.getBeansOfType(ProxyFetchFactory.class);
if (serviceBeanMap != null && !serviceBeanMap.isEmpty()) {
for (Object serviceBean : serviceBeanMap.values()) {
ProxyFetchFactory service = (ProxyFetchFactory) serviceBean;
service.buildProxy();
}
}
}
/**
* 按定时调度触发所有业务爬取任务
*/
@Scheduled(cron = "0 0 0 1 * ?") //每天凌晨0点执行一次
public void scheduleAllProcessors() {
LOGGER.info("schedule task start with " + sdf.format(new Date()));
startAllProcessors();
LOGGER.info("schedule task end with " + sdf.format(new Date()));
}
/**
* 触发所有业务爬取任务
*/
public void startAllProcessors() {
ExecutorService es = Executors.newFixedThreadPool(10);
List processors = getAllListProcessors();
if (processors == null || processors.isEmpty()) {
return;
}
for (AbstractListProcessor listProcessor : processors) {
for (AbstractItemProcessor itemProcessor : listProcessor.getItemProcessors()) {
es.execute(itemProcessor);
}
}
try {
es.awaitTermination(60, TimeUnit.SECONDS);//最大等待60s
} catch (InterruptedException e) {
} finally {
es.shutdown();
}
}
/**
* 按业务名称触发爬取任务
*
* @param business
*/
public void startProcessorsByBusiness(String business) {
List processors = getAllListProcessors();
if (processors == null || processors.isEmpty()) {
return;
}
ExecutorService es = Executors.newFixedThreadPool(10);
for (AbstractListProcessor listProcessor : processors) {
if (business.equalsIgnoreCase(listProcessor.getBusiness())) {
for (AbstractItemProcessor itemProcessor : listProcessor.getItemProcessors()) {
es.execute(itemProcessor);
}
break;
}
}
try {
es.awaitTermination(60, TimeUnit.SECONDS);//最大等待60s
} catch (InterruptedException e) {
} finally {
es.shutdown();
}
}
private List getAllListProcessors() {
List processors = new ArrayList<>();
Map serviceBeanMap = context.getBeansOfType(AbstractListProcessor.class);
if (serviceBeanMap != null && !serviceBeanMap.isEmpty()) {
for (Object serviceBean : serviceBeanMap.values()) {
AbstractListProcessor processor = (AbstractListProcessor) serviceBean;
processors.add(processor);
}
}
LOGGER.info("fetch list processor size=" + processors.size());
return processors;
}
private List getAllItemProcessors() {
List processors = new ArrayList<>();
Map serviceBeanMap = context.getBeansWithAnnotation(SpiderProcessor.class);
if (serviceBeanMap != null && !serviceBeanMap.isEmpty()) {
for (Object serviceBean : serviceBeanMap.values()) {
AbstractItemProcessor processor = (AbstractItemProcessor) serviceBean;
processors.add(processor);
}
}
LOGGER.info("fetch processor size=" + processors.size());
return processors;
}
}
主要方法的说明已经在代码中注释,定义了代理爬取任务和业务爬取任务等方法,还记得前面有提到过业务的内容处理器是一个线程类,所以在上面调度时,就是直接在线程池中加入了对应的内容处理器,从而实现并发爬取。
具体的项目全过程调用我准备放在 Spring Boot 的 Application 类中来实现,不过原则上,代理的爬取任务是要先于业务爬取任务的,不然业务爬取时没有足够的代理使用。下面我们来实现 Spring Boot 的 Application 类的内容:
@ComponentScan(basePackages = {"com.alany.spider"}) //扫描该包路径下的所有Spring组件
@SpringBootApplication
public class SpiderApplication {
public static void main(String[] args) throws InterruptedException {
SpringApplication.run(SpiderApplication.class, args);
AsyncProcessTask asyncProcessTask = SpringContext.getBean(AsyncProcessTask.class);
asyncProcessTask.initProxy();
Thread.sleep(1000 * 60); //等60s
asyncProcessTask.startAllProcessors();
}
}
代码说明:
由于 Spring Boot 运行时当前上下文 Context 是在 Tomcat 的 Web 容器中,所以这里需要再实现一个 Spring 的上下文 ApplicationContext 工具类来获取 Spring 容器中的组件,代码如下:
@Component
public class SpringContext implements ApplicationContextAware {
private static ApplicationContext context;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
if (context == null) {
context = applicationContext;
}
//startAllItemProcessors();
}
//获取applicationContext
public static ApplicationContext getApplicationContext() {
return context;
}
//通过name获取 Bean.
public static Object getBean(String name){
return getApplicationContext().getBean(name);
}
//通过class获取Bean.
public static T getBean(Class clazz){
return getApplicationContext().getBean(clazz);
}
//通过name,以及Clazz返回指定的Bean
public static T getBean(String name,Class clazz){
return getApplicationContext().getBean(name, clazz);
}
}
运行 SpiderApplication 的 main 方法可以看到爬虫欢快的跑起来了,并且成功入库云数据库。贴一小段爬取成功的 log 来证明框架是真的可以跑起来的 :
2019-08-01 16:56:32.786 INFO 9020 --- [pool-1-thread-3] c.a.spider.core.proxy.ProxyFetchFactory : github - 185.6.138.28 : false
2019-08-01 16:56:32.925 INFO 9020 --- [pool-1-thread-8] c.a.spider.core.proxy.ProxyFetchFactory : github - 78.186.237.112 : false
2019-08-01 16:56:32.944 INFO 9020 --- [pool-1-thread-2] c.a.spider.core.proxy.ProxyFetchFactory : github - 78.186.237.112 : false
2019-08-01 16:56:32.947 INFO 9020 --- [ main] c.a.spider.core.proxy.ProxyFetchFactory : valid host total size: 299
2019-08-01 16:57:02.951 INFO 9020 --- [ main] c.a.spider.core.task.AsyncProcessTask : fetch list processor size=1
2019-08-01 16:57:02.960 INFO 9020 --- [l-3809-thread-2] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524010}', httpResult=null}
2019-08-01 16:57:02.960 INFO 9020 --- [l-3809-thread-3] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524020}', httpResult=null}
2019-08-01 16:57:02.961 INFO 9020 --- [l-3809-thread-4] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524030}', httpResult=null}
2019-08-01 16:57:02.962 INFO 9020 --- [l-3809-thread-5] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524040}', httpResult=null}
2019-08-01 16:57:02.962 INFO 9020 --- [l-3809-thread-6] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524050}', httpResult=null}
2019-08-01 16:57:02.960 INFO 9020 --- [l-3809-thread-1] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524000}', httpResult=null}
2019-08-01 16:57:02.964 INFO 9020 --- [l-3809-thread-9] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524080}', httpResult=null}
2019-08-01 16:57:02.964 INFO 9020 --- [l-3809-thread-7] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524060}', httpResult=null}
2019-08-01 16:57:02.965 INFO 9020 --- [-3809-thread-10] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524090}', httpResult=null}
2019-08-01 16:57:02.966 INFO 9020 --- [l-3809-thread-3] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 51.158.99.51:8811
2019-08-01 16:57:02.966 INFO 9020 --- [l-3809-thread-5] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 39.137.107.98:8080
2019-08-01 16:57:02.966 INFO 9020 --- [l-3809-thread-9] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 49.48.144.160:8080
2019-08-01 16:57:02.966 INFO 9020 --- [l-3809-thread-8] c.a.s.c.process.AbstractItemProcessor : executing processor: ExecuteContent{start=0, end=0, business='CSDN', url='https://www.csdn.net/api/articles?type=more&category=news&shown_offset=', params='{"offset":1564649090524070}', httpResult=null}
2019-08-01 16:57:02.967 INFO 9020 --- [l-3809-thread-8] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 178.128.229.122:8080
2019-08-01 16:57:02.968 INFO 9020 --- [l-3809-thread-7] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 92.49.188.250:8080
2019-08-01 16:57:02.969 INFO 9020 --- [-3809-thread-10] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 36.90.158.178:8080
2019-08-01 16:57:02.970 INFO 9020 --- [l-3809-thread-2] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 159.138.22.112:80
2019-08-01 16:57:02.972 INFO 9020 --- [l-3809-thread-6] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 110.74.199.125:35604
2019-08-01 16:57:02.972 INFO 9020 --- [l-3809-thread-1] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 13.115.109.245:8080
2019-08-01 16:57:02.973 INFO 9020 --- [l-3809-thread-4] com.alany.spider.core.http.HttpRequest : url: https://www.csdn.net/api/articles?type=more&category=news&shown_offset=, proxy: 185.80.130.17:80
2019-08-01 16:57:10.161 INFO 9020 --- [l-3809-thread-1] c.a.s.c.dao.impl.AbstractCouldDBService : success to insert bean [{"imgUrl":"https://profile.csdnimg.cn/B/0/7/1_l659292998","publishTime":"2019-08-01 16:57:09","author":"恒指交易指导","articleId":"95589302","description":"恒指7.12号开盘前瞻:美股再创新高,恒指能否踏上新台阶。\n美国减息预期持续升温,推动道指和标普500再创新高。周四(7月11日)美国三大股指涨跌不一,道指收报27088点,升227点或0.85%,历史首次突破27000点大关,创收市新高;标指收报2999点,升6点或0.23%,同创收市新高;以科技股为主的纳指微跌6点或0.08%,收报8196点。\n近日,美联储主席鲍威尔一展“鸽”喉,7月降息之门...","sourceName":"CSDN","title":"进退博弈:恒指7.12号早盘资讯及交易计划","category":"恒指,恒指早盘,进退博弈","url":"https://blog.csdn.net/L659292998/article/details/95589302","status":0}]
2019-08-01 16:57:10.381 INFO 9020 --- [l-3809-thread-1] c.a.s.c.dao.impl.AbstractCouldDBService : success to insert bean [{"imgUrl":"https://profile.csdnimg.cn/F/1/1/1_win_le","publishTime":"2019-08-01 16:57:09","author":"吾昂王","articleId":"94658782","description":"linux目录结构:\n类似倒挂的树. \n/ : 根目录,所有数据都在此目录下(Windows中,通常说文件夹,文件. LINUX中通常为 目录 和 文件 )\nlinux中 一切 皆文件!!!!\n例 : /dev : 存放系统设备相关的数据\n\nlinux磁盘表示:\nhd,表示IDE设备\nsd:表示SCSI设备\n\n命令行提示符:\n[当前用户名@当前主机名 当前所在位置] # $ (#为此用户为超级...","sourceName":"CSDN","title":"Linux基础中的基础 一","url":"https://blog.csdn.net/Win_Le/article/details/94658782","status":0}]
2019-08-01 16:57:10.590 INFO 9020 --- [l-3809-thread-1] c.a.s.c.dao.impl.AbstractCouldDBService : success to insert bean [{"imgUrl":"https://profile.csdnimg.cn/0/E/1/1_qq_42391904","publishTime":"2019-08-01 16:57:09","author":"Maker星蔚","articleId":"95529565","description":"Android四大组件分别为:1.活动Activity,2.服务Service,3.广播Broadcast Receiver,4.内容提供器Content Provider\n1.Service概念与要点\n1.定义:服务(Service)是Android中使程序在后台运行的方法。\n(1) 服务适合去执行不需要用户交互却要长期执行的任务,例如一个音乐app可在当程序在后台时仍然播放音乐,用户使用其他程...","sourceName":"CSDN","title":"Android基础-四大组件之Service(基础)","category":"安卓开发,Android四大组件,Android入门","url":"https://blog.csdn.net/qq_42391904/article/details/95529565","status":0}]
此外,之前在架构图中还提到过一种通过 RESTful 接口的方式触发任务,那么把对应的控制器也实现下,代码如下:
@RestController
@RequestMapping("/exec")
public class ProcessExecController {
private AsyncProcessTask asyncProcessTask = SpringContext.getBean(AsyncProcessTask.class);
@RequestMapping(value = "/all")
public void execAll(){
asyncProcessTask.startAllProcessors();
}
@RequestMapping(value = "/biz")
public void execByBiz(String business){
asyncProcessTask.startProcessorsByBusiness(business);
}
}
代码非常简单,就是对 AsyncProcessTask 类的简单调用,项目启动后在浏览器中输入 URL——http://localhost:8080/exec/all,也可以触发所有业务的爬取任务。
至此,整个爬虫项目的框架就搭建完毕,内容和代码较多,涉及到 Spring、SpringBoot、Java 并发编程、HTTP、JSON 解析、jsoup 页面解析、设计模式等多方面的知识,所以存在不熟悉的知识点需要额外补一下短板哈,此外在阅读文章的同时边上机实践效果会更好,最后祝愿大家都能有所收获。