
Python私活案例,办公自动化处理水质数据
前言:
今天接到一个私活,是要求通过python实现办公自动化的,我一看表格有点多,瞬间感觉到头大。当我静下心来看的时候,发现做这些表格用到的知识在蚂蚁老师的课上都有讲过,于是果断搞起。
任务说明:
表1和表2是每个月更新的数据,要求按照表3模板的格式,将表3红色方框中的数据进行更新,并且水质类别表的标题也进行更新。实现全部自动化。
表1:
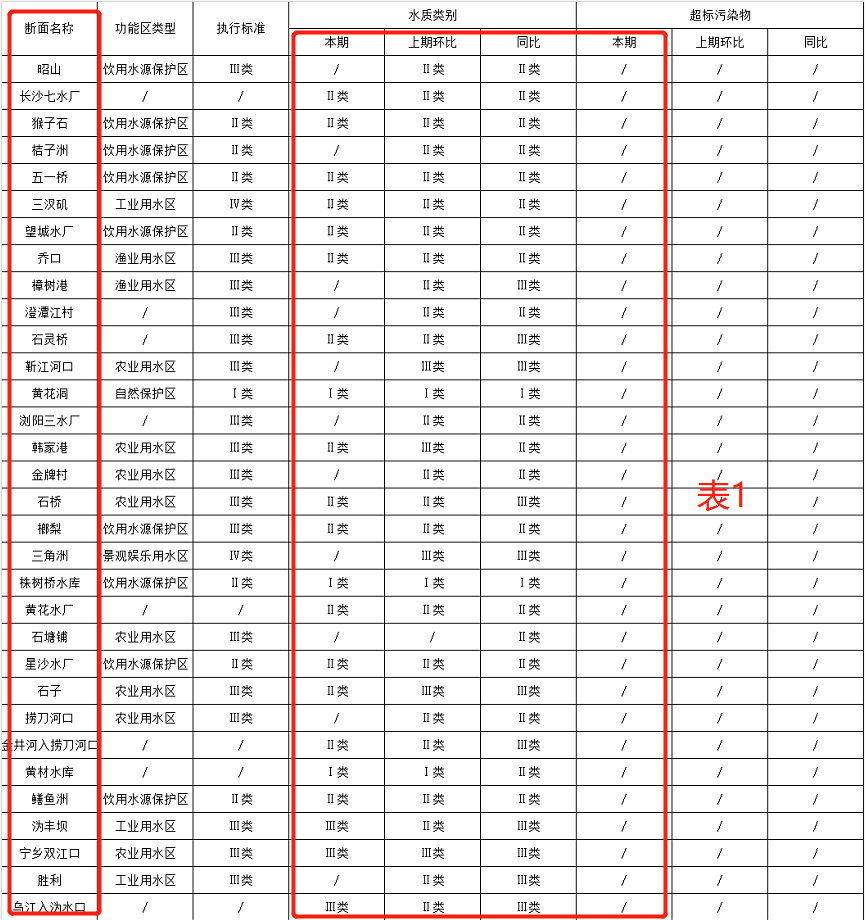
表2:

表3:
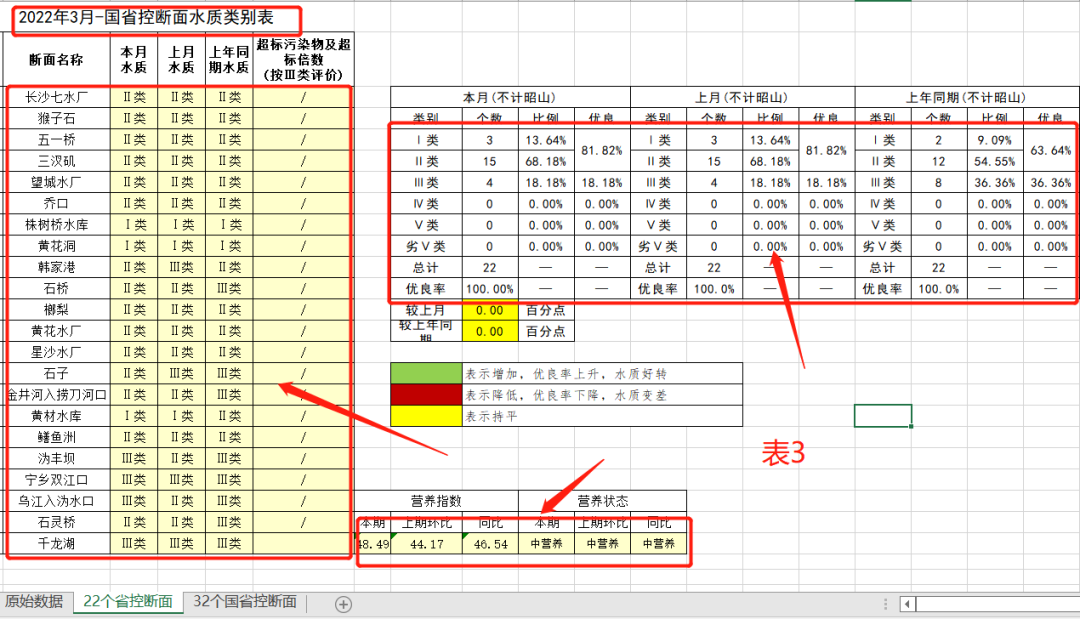
一,读取表格数据
经过对表3的分析,首先我们要读取表1,表2中红色方框的数据,以及表三中断面名称。要实现一键自动化,那就将三个目标文件放在一个文件夹里,然后根据名称进行判断。
import pandas as pd
import xlwings as xw
import os,re
file_list = os.listdir('./')
file1=''
file2 = ''
file3 = ''
for file in file_list:
if file.endswith('xlsx'):
if '-断面水质类别表' in file:
file1 = file
elif '年报' in file:
file2 = file
elif '国省控断面水质类别表' in file:
file3 = file
print('断面水质类别文件1:',file1)
print('湖库水质文件2:',file2)
print('国省控断面文件3:',file3)
得到对应文件结果:
断面水质类别文件1:2022年3月-断面水质类别表.xlsx
湖库水质文件2:2022年3月-湖库水质月_季_年报 .xlsx
国省控断面文件3:2022年2月-(定)国省控断面水质类别表.xlsx
读取表1数据:
df1 = pd.read_excel(file1,header=1)
df1 = df1.iloc[1:,[3,6,7,8,9]]
df1.columns = ['断面名称','本月','上月','上年同期','超标污染物']
df1
读取表2数据:
df2 = pd.read_excel(file2,header=1)
df2_1 = df2.iloc[1:,[4,7,8,9,10]]
df2_1.columns = ['断面名称', '本月', '上月', '上年同期', '超标污染物']
df2_2 = df2.iloc[1:,13:19]
df2_1

读取表3中断面名称:
app = xw.App(visible=False, add_book=False)
workbook = app.books.open(file3)
data1 = workbook.sheets['22个省控断面'].range('C3:C24').options(index=False).value
df3_1 = pd.Series(data1,name='断面名称')
然后将表1表2数据进行拼接,然后与表3的断面名称进行合并:
df1 = pd.concat([df1,df2_1],axis=0)
df_province = pd.merge(df3_1,df1,on='断面名称',how='left')
df_province
部分结果如下: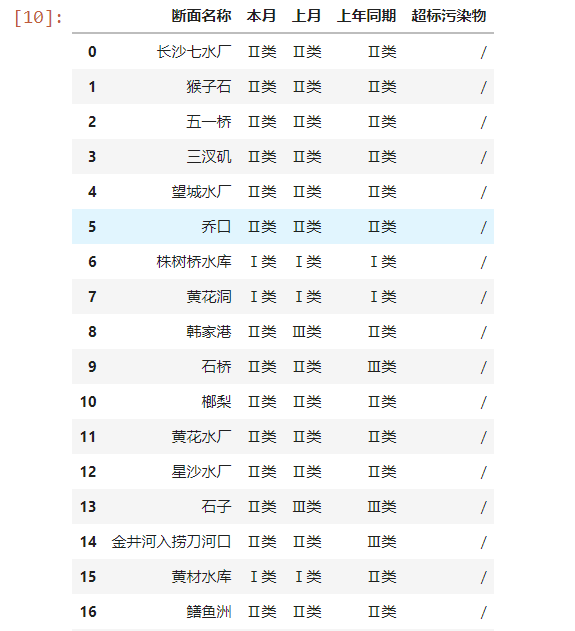
二,数据分析
下面就是要根据导出来的表对本月,上月,上年同期的类别进行数据分析了
df_province_data = df_province.loc[:,['本月','上月','上年同期']]
def get_tpye_data(df):
# 获取单月df类别个数比例
new_df = pd.DataFrame()
ser = pd.Series(['Ⅰ类','Ⅱ类','Ⅲ类','Ⅳ类','Ⅴ类','劣Ⅴ类'],name='类别')
# new_df['个数'] = df_province["本月"].value_counts()
new_df['个数'] = df
new_df = pd.merge(ser,new_df,how='left',left_on='类别',right_on=new_df.index,sort=True)
new_df.set_index('类别',inplace=True)
new_df.fillna(0, inplace=True)
new_df.loc['总计'] = new_df.sum()
new_df['比例'] = new_df.apply(lambda x: new_df['个数']/new_df.loc['总计','个数'])
new_df['优良'] = new_df['比例']
new_df.loc[['Ⅰ类','Ⅱ类'],'优良'] = new_df.loc['Ⅰ类','比例'] + new_df.loc['Ⅱ类','比例']
new_df.loc['优良率'] = new_df.loc[['Ⅰ类','Ⅱ类','Ⅲ类'],'比例'].sum()
new_df.loc[['总计','优良率'],['比例','优良']] = '—'
new_df['个数'] = new_df['个数'].astype('int')
new_df['类别'] = new_df.index
new_df = new_df.reindex(columns=['类别','个数','比例','优良'])
return new_df
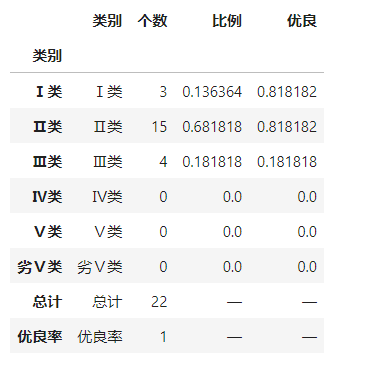
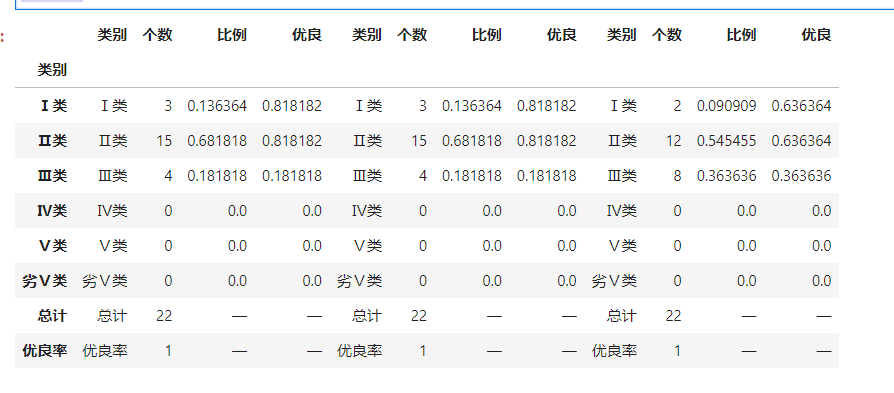
benyue_df = get_tpye_data(df_province["本月"].value_counts())
benyue_df
得到单月的类别数据情况,结果如下:
通过调用函数分别的到不同月份的数据,并进行合并:
shangyue_df = get_tpye_data(df_province["上月"].value_counts())
qunian_df = get_tpye_data(df_province["上年同期"].value_counts())
df_all = pd.concat([benyue_df,shangyue_df,qunian_df],axis=1,join='outer',ignore_index=False)
df_all
三,按照表格位置写入数据
最后就是数据写入文件了,由于表3中文件都是设置好的格式,比例导入后直接转成百分比;
写入表格标题:
month = file1.split('-')[0]
title_provice = workbook.sheets['22个省控断面'].range('A1').value # 获得表格标题
workbook.sheets['22个省控断面'].range('A1').value = month + '-' + title_provice.split('-')[-1] # 写入标题
写入水质类别表及营养指数:
workbook.sheets['22个省控断面'].range('C3:G24').value = df_province.values
workbook.sheets['22个省控断面'].range('H24:M24').value = df2_2.values
写入类别数据:
workbook.sheets['22个省控断面'].range('I5:T12').value = df_province_data.values
更新当前数据月份文件名,并关闭表格:
f = re.sub('\w+月',month,file3)
workbook.save(f)
print(f,'文件保存完成')
workbook.close()
app.quit()
任务完成!只要好好听蚂蚁老师的课,这些python实现办公自动化的案例你也能搞定~
蚂蚁老师的全栈套餐,在抖音扫码购买;有答疑服务、副业介绍等福利

评论