
通过一条语句的执行,深入理解innoDB的底层架构
MySQL最常用的存储引擎是innodb,我们今天就借助一条更新语句的执行,了解下innodb具体是如何处理的,深入理解下它的架构。
假设更新语句是这样的:
update user set name ='xxx' where id = 1;这条SQL语句发送到MySQL上后,会经过SQL接口、解析器、优化器、执行器几个阶段,解析SQL、生成执行计划,再由执行器调用存储引擎执行这个执行计划。
如下图所示:
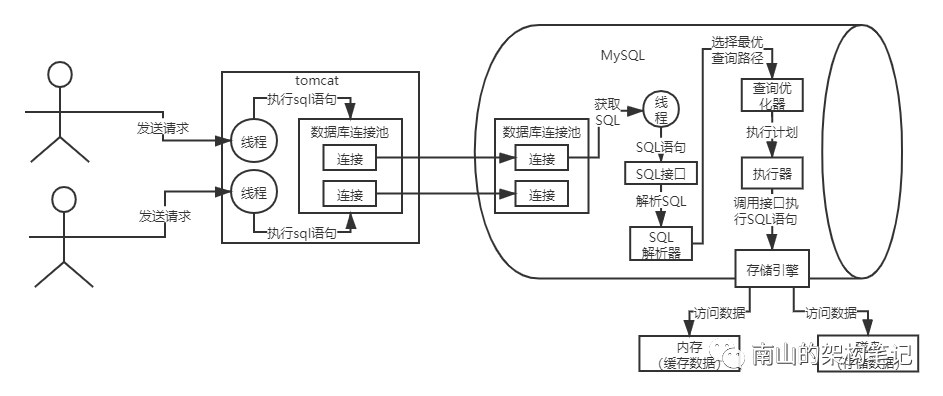
图1 MySQL底层架构
下面我们就跟随一条update语句,分析下innodb存储引擎的架构设计。
1、innodb最重要的组件:缓冲池(BufferPool)
innodb存储引擎中有一个非常重要的组件,就是缓冲池(BufferPool),这里面会缓冲很多数据,以便于以后操作数据的时候,可以直接操作内存,就不用访问磁盘了。
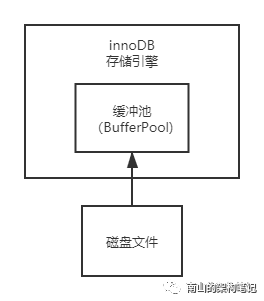
图2 innoDB重要组件缓冲池
innoDB执行上面那条更新语句的时候,会先看id = 1的这条语句是否在缓冲池中,如果不再就需要从磁盘加载到缓冲池来,而且还会对这条记录加独占锁。
锁相关的知识点,后面会有讲解,这里不是重点,就不展开了。
2、undo日志文件
接下来,准备更新id = 1的这条数据时,会先把id = 1和name原来的值写入到undo日志文件中去。
这么做的目的是什么?当然是方便回滚了。
MySQL增删改数据都是放在事务里执行的,如果事务提交失败了,就可以根据undo日志进行回滚。
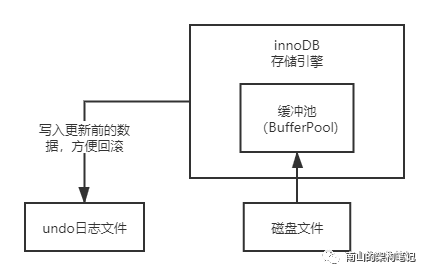
图3 undo日志文件
把id = 1的那条要更新的数据加载到缓冲池,把要更新数据的旧值写入undo日志文件后,就可以开始更新这条记录了。
更新的时候,先更新缓冲池的数据。更新完后,缓冲池里的数据就变成:name = 'xxx'了,而此时磁盘上的数据还是name='zhangsan'。此时innoDB数据状态就变成这样了:
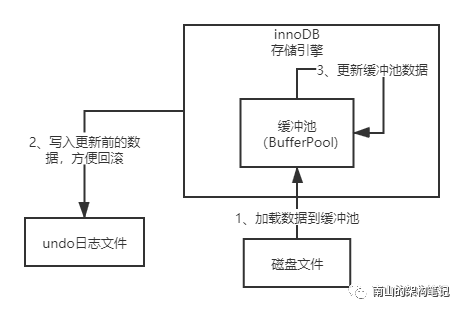
图4 更新缓冲池数据
3、redo日志文件
此时缓冲池和磁盘上的数据是不一致的,如果MySQL宕机了,怎么办?
此时MySQL宕机了,缓冲池里的数据肯定就丢失了。
这时候,就要引入一个新的组件:redo日志。
redo日志也是一个内存缓冲区,用来存放redo日志的,就是用来记录你对数据做了那些修改。
比如,id = 1这条记录,修改了name,redo日志可能就这样:id = 1, name = 'xxx'。
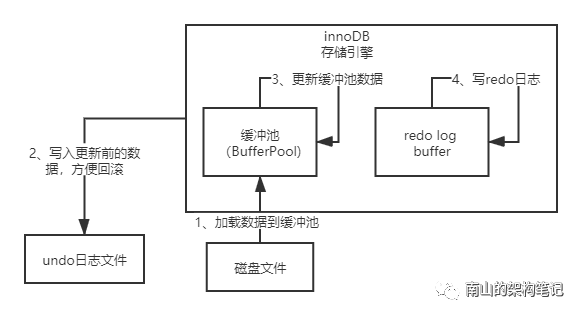
图5 redo日志
有了redo log,MySQL宕机后重启,就可以恢复更新后的数据。
但是,如果此时MySQL数据库宕机了,会怎样?
必然是缓冲池中修改过的数据,redo log buffer日志都会丢失。
但是,这也不要紧,因为你更新数据的事务没有提交,此时MySQL宕机了,事务就执行失败了,客户端会收到一个数据库异常,MySQL重启后磁盘上的数据还是原样子。
所以数据还是一致的。
另外,redo日志是innoDB特有的一个组件。
4、提交事务
上面的步骤完成之后,就要提交事务了,此时会把redo日志刷到磁盘上去。
刷盘策略可以通过innodb_flush_log_at_trx_commit来配置。
这个配置有几个选项:
0,提交事务的时候,不会把redo日志刷入磁盘;
1,默认值,提交事务的时候,会把redo刷入磁盘,只要事务提交成功,redo日志就比如进入磁盘了。
2,提交事务的时候,会把redo刷入os cache。操作系统会不定期把os cache里的数据刷到磁盘里去。
所以innodb_flush_log_at_trx_commit等于0或2的时候,redo日志都有事务提交成功,没写进磁盘的可能,缓冲池里更新后的数据也丢失了。此时MySQL重启,就无法根据redo恢复更新后的数据,就会出现数据不一致情况。
所以一般情况下,我们都会把innodb_flush_log_at_trx_commit配置为1。
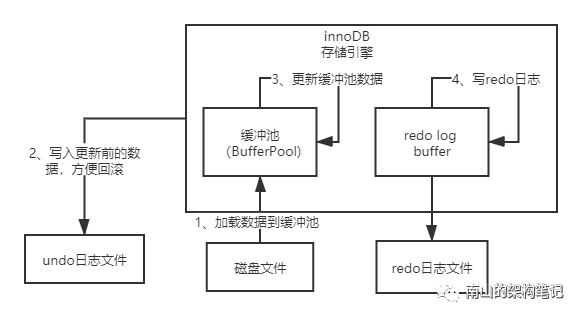
图6 redo日志
5、binlog日志
其实MySQL中提交事务的时候,还会记录binlog。binlog是MySQL server自己的日志文件。
redo日志属于一种偏向于物理性质的重做日志,它里面记录的相当于是“对某某数据页的某某记录,做了某某修改”。
binlog叫做归档日志,它里面记录的是偏向于逻辑性的日志,类似于redis的aof日志。
我们提交事物的时候,除了把redo log日志写到磁盘,还会同时把对应的binlog日志写到磁盘文件中。
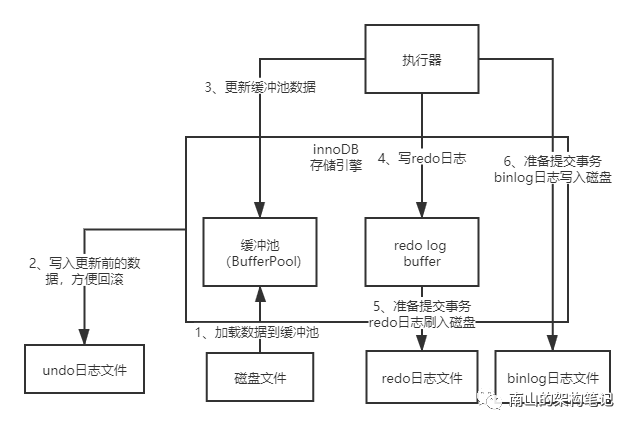
图7 binlog日志
与redo log日志一样,binlog日志有两种刷盘策略,相应的配置项为:sync_binlog。
0,默认值,提交事务的时候,会把binlog刷入os cache。
1,提交事务的时候,会把binlog写入磁盘。
所以,当sync_binlog设置为0的时候,如果机器宕机,binlog会有丢失的风险。设置为1的时候,即使机器宕机,binlog日志也不会丢失。
当我们把binlog日志写入磁盘后,接着就完成了最终的事务提交,最后会把本次更新对应的binlog日志文件名和这次更新的binlog日志在文件里的位置,都写入到redo log日志里去,同时在redo log日志文件里写入一个commit标记。
到此为止,一个事务提交才是完成了。
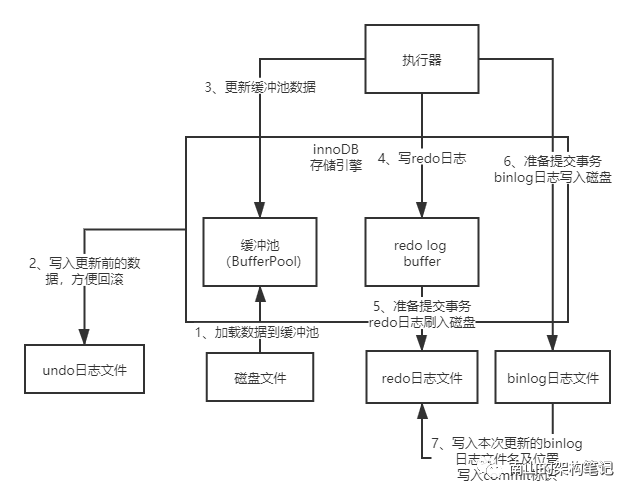
图8 binlog刷到磁盘
最后再补充一点,在redo日志中写入commit标识,其目的是保持redo log日志与binlog日志一致的。
也就是说,innoDB根据commit标识判定一个事务是否执行成功。如果在图8的5、6、7步,必须是三个步骤都执行成功了,才算提交了事务。假如执行其中某个步骤的时候,机器宕机了,会怎样?
这时候,因为redo日志里没有commit标识,所以会判定此次事务执行不成功,就不会出现数据不一致的情况。
6、后台线程把内存数据刷到磁盘
此时事务提交了,已经把缓冲池(BufferPool)中的数据更新了,磁盘里也有了redo日志和binlog日志,但这时候,磁盘上的数据还是旧的啊。
所以MySQL会有一个后台IO线程,会在某个时间,随机把缓冲池(BufferPool)中的数据刷到磁盘上去。
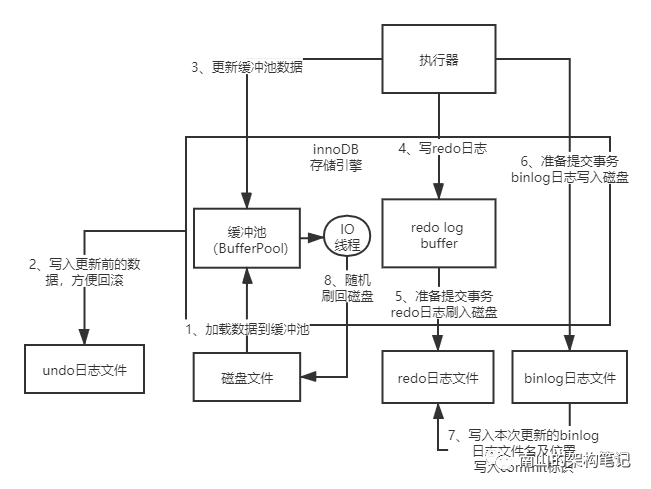
图9 innoDB执行更新语句时的完整流程
后台IO线程把缓冲池的数据刷到磁盘前,即使MySQL宕机,也没关系,因为机器重启后,会根据redo日志回复之前提交事务所作的修改。
7、总结
通过一次更新数据的流程,了解了innoDB存储引擎做了哪些工作。更新前记录undo日志,更新缓冲池(BufferPool)里的数据,记录redo log日志,binlog日志,每一步都有其专门的作用,innoDB通过这套复杂的架构设计,保证了数据更新的高性能和一致性。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️