
Node.js 环境性能监控探究
作者:@LucasTwilight
https://juejin.im/post/5c71324b6fb9a049d37fbb7c
业务逻辑的迁移,以及各种MV*框架的服务端渲染模型的出现,让基于Node的前端SSR策略更依赖服务器性能。首屏直出性能以及Node服务的稳定性,直接关系影响着用户体验。Node作为服务端语言,相比于Java和PHP这种老服务端语言来说,对于整体性能的调控还是不够完善。虽然有sentry这种报警平台来及时通知发生的错误,但是不能够预防错误的发生。如何防患于未然,首先需要理解Node.js性能监控的主要指标。

下面的代码均是基于Egg框架的,如果对Egg不熟悉的小伙伴可以先去浏览一下文档
指标
服务器的资源瓶颈主要有下面几个:
CPU 内存 磁盘 I/O 网络
考虑到不同的Node环境,其对于资源的需求类型也是不尽相同的。如果Node只是用于前端SSR的话,那么CPU和网络就会成为主要的性能瓶颈。
当然如果你需要使用Node来进行数据持久化相关的工作,那么I/O和磁盘也会有很高的占用率。
即使是前端发展非常超前的公司,也很少会用Node作为业务数据的支撑。充其量当做BFF层来为前端提供数据服务,并不直接接触持久化的数据。所以磁盘和I/O很难成为当下前端性能的瓶颈。
即使存在使用Node进行数据持久化平台,大多数也是实验性质的平台或者是内部平台。不直接面向业务场景。
所以,在大多数场景下,CPU、内存以及网络就可以说是Node的主要性能瓶颈。
CPU指标
CPU负载和CPU使用率
顾名思义,这两个指标都是用来评估系统当前CPU的繁忙程度的量化指标。CPU负载和CPU使用率是从两个不同的角度来量化CPU的繁忙程度的。
CPU负载:进程角度 CPU使用率:CPU时间分配
进程是资源分配的最小单位。
这句话在操作系统的教科书上或者各位的考试卷上都多多少少出现过。也就是,系统按照进程级别来进行资源的分配,一个CPU核心在一个时刻只能够为4个进程提供服务。
那么, CPU的负载也就很好理解了。在某个时间段内,占用以及等待CPU的进程总数就是CPU在这个时间段内的负载(load average),在大多数情况下,我们称这个标准为loadavg。
而CPU利用率(cpu utilization),则是量化CPU时间占用状况的,一般我们认为CPU利用率 = 1 - 空闲CPU时间(idle time) / CPU总时间。
wiki上已经解释的非常清楚了,请自备梯子(https://en.wikipedia.org/wiki/Load_(computing)#CPU_load_vs_CPU_utilization)
量化CPU指标
那么这两个指标到底哪个才最能代表的系统的实际状态呢?
滑梯:CPU
人:进程
假如有4个滑梯。每个滑梯上最多可以塞得下10个人。我们假设所有的人的大小一致。那么,可以得到如下的类比:
Loadavg = 0,表示滑梯上一个人都没有 Loadavg = 0.5, 表示平均每个滑梯上的人都占了滑梯的一半,也就是总共20个人在滑梯上,由于CPU调度策略,这些人一般会均匀分配(每个人都会挑人少的滑梯) Loadavg = 1,表示每个滑梯上都塞满人了,没有任何空闲空间 Loadavg = 2, 表示不仅仅每个滑梯上都塞满了人,还有40个人在后面等着
以上的类比都是基于瞬时的loadavg得到的。
一般对于loadavg的量化,我们都是采用3个不同的时间标准来进行的。1分钟,5分钟以及15分钟。
1分钟的指标是很难得到较为均衡的指标的。因为1分钟时间太短,可能某一秒的峰值就能够影响到1分钟时间段内的平均指标。但是,1分钟内,如果loadavg突然达到很高的值,也可能是系统崩溃的前兆,也是需要警惕的一个指标。
而5分钟和15分钟则是较为合适的评判指标。当CPU在5分钟或者15分钟内都保持高负荷运作,对于整个系统是非常危险的。遇到过堵车的人都应该知道,一旦发生了堵车,只要堵塞不及时清理,就会越堵越长。CPU也是这样,如果CPU上等待的进程阻塞的较多,那么后面进入队列的任务就更加抢占不到资源,也就会被一直阻塞了。
在MAC上可以在root权限下,使用sysctl -n vm.loadavg来获得。
// /app/lib/cpu.js
const os = require('os');
// cpu核心数
const length = os.cpus().length;
// 单核CPU的平均负载
os.loadavg().map(load => load / length);
而CPU利用率则是不太好作为直接评判标准的数值。由于进程阻塞在CPU上的原因不相同,对于CPU密集型任务来说,CPU利用率可以很好地表示当前CPU的工作情况,但是对于I/O密集型的任务来说,CPU空闲不代表CPU无事可做,可能是任务被挂起,去进行其他操作了。
但是,对于进行SSR的Node系统来说,渲染基本上可以理解为CPU密集型业务,所以这个指标在一定程度上可以体现出当前业务环境的CPU性能。
// /app/lib/cpu.js
const os = require('os');
// 获取当前的瞬时CPU时间
const instantaneousCpuTime = () => {
let idleCpu = 0;
let tickCpu = 0;
const cpus = os.cpus();
const length = cpus.length;
let i = 0;
while(i < length) {
let cpu = cpus[i];
for (let type in cpu.times) {
tickCpu += cpu.times[type];
}
idleCpu += cpu.times.idle;
i++;
}
const time = {
idle: idleCpu / cpus.length, // 单核CPU的空闲时间
tick: tickCpu / cpus.length, // 单核CPU的总时间
};
return time;
}
const cpuMetrics = () => {
const startQuantize = instantaneousCpuTime();
return new Promise((resolve, reject) => {
setTimeout(() => {
const endQuantize = instantaneousCpuTime();
const idleDifference = endQuantize.idle - startQuantize.idle;
const tickDifference = endQuantize.tick - startQuantize.tick;
resolve(1 - (idleDifference / tickDifference));
}, 1000);
});
};
cpuMetrics().then(res => {
console.log(res);
// 0.074999
});
结合上述两个指标,可以大致得到系统的运行状态,从而对于系统进行干预。比如将SSR降级为CSR。
内存指标
内存是一个非常容易量化的指标。内存占用率是评判一个系统的内存瓶颈的常见指标。对于Node来说,内部内存堆栈的使用状态也是一个可以量化的指标。
// /app/lib/memory.js
const os = require('os');
// 获取当前Node内存堆栈情况
const { rss, heapUsed, heapTotal } = process.memoryUsage();
// 获取系统空闲内存
const sysFree = os.freemem();
// 获取系统总内存
const sysTotal = os.totalmem();
module.exports = {
memory: () => {
return {
sys: 1 - sysFree / sysTotal, // 系统内存占用率
heap: heapUsed / headTotal, // Node堆内存占用率
node: rss / sysTotal, // Node占用系统内存的比例
}
}
}
对于process.memoryUsage()拿到的值有一些需要关注的地方:
我的Node启蒙书《深入浅出Node.js》这本书,虽然版本已经落后了现在的Node.js很多release了,但是其中讲到的关于V8引擎的GC机制的内容,仍然非常受用,推荐大家买正版支持一下朴灵老师。
rss:表示node进程占用的内存总量。 heapTotal:表示堆内存的总量。 heapUsed:实际堆内存的使用量。 external:外部程序的内存使用量,包含Node核心的C++程序的内存使用量。
首先需要关注的是内存堆栈,也就是堆内存的占用。在Node的单线程模式下,C++程序(V8引擎)会为Node申请一定的内存,来作为Node线程的内存资源heapTotal。而在我们Node的使用过程中,声明的新的变量都会使用这些内存来进行存储heapUsed。
Node的分代式GC算法会在一定程度上浪费部分内存资源,所以当heapUsed达到heapTotal一半的时候,就可以强制触发GC操作了global.gc()。gc操作相关可以看下这篇文章。对于系统内存的监控处理,不能够仅仅像Node内存级别一样,进行GC操作就可以,而同样需要进行渲染降级。70% ~ 80%的内存占用就是非常危险的情况了。具体的数值需要根据环境所在的宿主机来确定。
具体和Node内存GC策略以及分配规则相关的,可以看StrongLoop - Node.js Performance Tip of the Week: Managing Garbage Collection。
QPS
严格意义上来说,QPS不能够作为web监控的直接标准。但是当服务器在高负载的情况下,不能够得到和压测情况下接近的QPS的时候,就需要考虑是某些其他原因导致了服务器的性能瓶颈。一般在进行Node环境下的SSR的时候,假设Node-Cluster最大线程数为10,那么可以并行进行10个页面的渲染,当然这也取决于宿主CPU的核心数。
在将Node作为SSR的宿主环境的情况下,可以很容易地记录到当前机器在一段时间内响应的请求数。之前在做毕业论文的时候,有尝试过对于web站点进行压力测试的几种方式。
ApacheBench
http_load
Seige
这三个web压测工具大同小异,都能够进行并发请求测试,对于web站点进行多用户的并发访问,并且记录到所有请求过程的响应时间,并且重复进行请求,可以很好地模拟Node环境在压力下的表现。
根据性能压测的结果,以及对于需求的流量峰值的评估,可以大致计算出需要多少台机器才能够保证web服务的稳定性,保证大多数用户能够在可接受的时间内得到响应。
测试
根据上述三个指标,对于本地启动的环境进行压测。
本地启动的Node环境是基于Egg框架扩展的React SSR环境,实际线上环境由于很多静态资源(包括javascript脚本、css、图片等)都被推到了CDN上,所以这些资源不会直接对环境产生压力,而且生产环境和开发环境也存在很多流程上的区别,所以实际性能要比本地启动的好很多。这里为了测试方便,所以直接在本地启动了Egg工程。
测试环境本地可以使用PM2启动Node工程,或者直接通过Node命令启动,在本地测试环境尽量不要使用webpack-dev-server这样的开发环境启动,这样可能会导致Node的Cluster模式不能够很好地运行,监控线程阻塞掉页面渲染的线程。基于Egg的环境可以使用schedule定时任务来定时打印环境监控日志。具体使用可以看Egg的文档,里面会写的比较详细。然后自定义一个日志类型,将监控日志独立于应用日志存储起来,便于分析和可视化。
// /app/schedule/monitor.js
const memory = require('../lib/memory');
const cpu = require('../lib/cpu');
module.exports = app => {
return {
schedule: {
interval: 10000,
type: 'worker',
},
async task(ctx) {
ctx.app.getLogger('monitorLogger').info('你想打印的日志结果')
}
}
}
// /config/config.prod.js
const path = require('path');
// 自定义日志,将日志文件自定义到一个单独的监控日志文件中
module.exports = appInfo => {
return {
customLogger: {
monitorLogger: { file: path.resolve(__dirname, '../logs/monitor.log') }
}
}
}
然后准备siege进行压测:Mac上安装siege
或者在MAC上可以更简单地使用brew来直接安装siege。推荐使用这种方法,因为直接下载源码包编译的话,可能会发生libssl库链接不上的问题,导致不能够进行https请求。
测试和监控结果
在无请求访问情况下:

siege
配置siege的请求URL列表:我们可以将想要siege请求的URL放在文件里面,通过siege命令进行读取(这里需要注意,siege只能够访问http站点,如果站点强制https的话可能需要考虑其他方法)。
urls文件
urls执行:siege -c 10 -r 5 -f urls -i -b
-c:模拟有n个用户同时访问
-r:重复测试n次
-f:指定测试URL的获取文件
-I:指定随机访问URL获取文件中的URL
-b:请求无需等待
上面的siege命令就表示,每次并发10个,分别请求urls文件中的随机一个站点,然后这样的并发一共执行5次,并且无需等待直接访问。
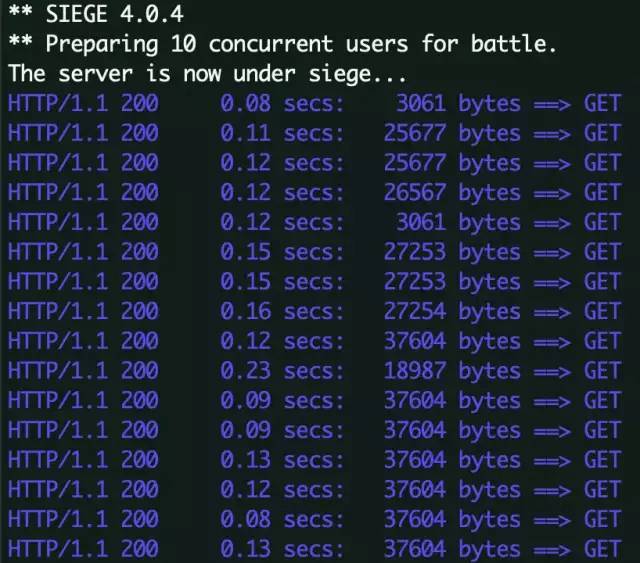
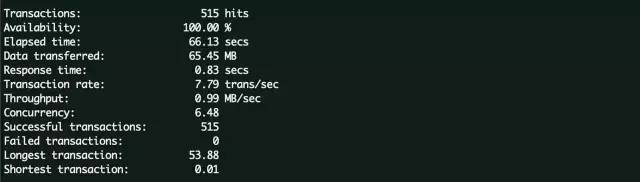

可以看到,siege对于服务端进行了515次命中,因为服务端除了主页面还有一些静态资源需要请求,这些命中包含页面,javascript脚本,图片以及css等,平均每个资源的响应时间为0.83秒
请求结束时间为20:29:37,可以看到这个时间之后,cpu的各项指标都开始下降,而内存没有非常明显的变化。
再进行一次压力较大的测试:
执行:siege -c 100 -r 5 -f urls -i -b,将并发数增加到10倍也就是100并发。
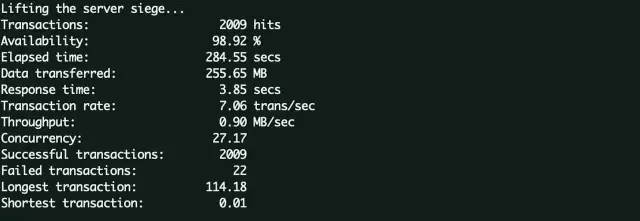

可以看到平均响应时间下降到了3.85秒,非常明显。而且loadavg相比第一次压测的时候,有着非常明显的上升。内存使用的变化不大,
因为测试环境的机器是虚拟机,不会独占物理机的所有资源,但是获取的CPU数却是物理机的CPU数。由于之前我们对于每种参数都计算了单核的情况,所以这里和CPU相关的结果需要和物理机核心数以及虚拟机占用的核心数相关。
有兴趣的小伙伴可以尝试一下机器的极限ORZ。或者在物理机上尝试一下压测。我没有敢这么伤害我的小兄弟。

Conclusion
现在很多业务开始往前端进行迁移,BFF(backends for frontends)的概念有很多团队已经开始逐渐尝试去做了。让后端专注于提供统一的数据模型,然后将业务逻辑迁移到基于Node.js的BFF层中,让前端给自己提供api接口,这样就剩下了很多前后端联调的成本,让后端提供的RPC或者HTTP接口更加通用,更少地修改后端工程,加快开发的效率。
但是这样就非常依赖Node端的稳定性,在BFF架构中,一旦Node端发生错误导致阻塞,则所有前端页面都会丢失服务,造成很严重的后果,所以Node端的监控越来越有意义。结合一些传统平台比如sentry或者zabbix可以帮助构建一个稳定的前端部署环境。
❤️爱心三连击
1.看到这里了就点个在看支持下吧,你的「在看」是我创作的动力。
2.关注公众号
程序员成长指北,回复「1」加入Node进阶交流群!「在这里有好多 Node 开发者,会讨论 Node 知识,互相学习」!3.也可添加微信【ikoala520】,一起成长。
“在看转发”是最大的支持