
来自 BAT 资深网络专家的计网总结
TCP/IP
给我一个名字
就像婴儿呱呱落地,需要父母取一个名字。主机加入一个新的局域网后也是同样的道理:需要路由器分配一个IP作为名字。
这个分配是通过DHCP(Dynamic Host Configuration Protocol)协议完成的。这个协议的交互可以分为4步。
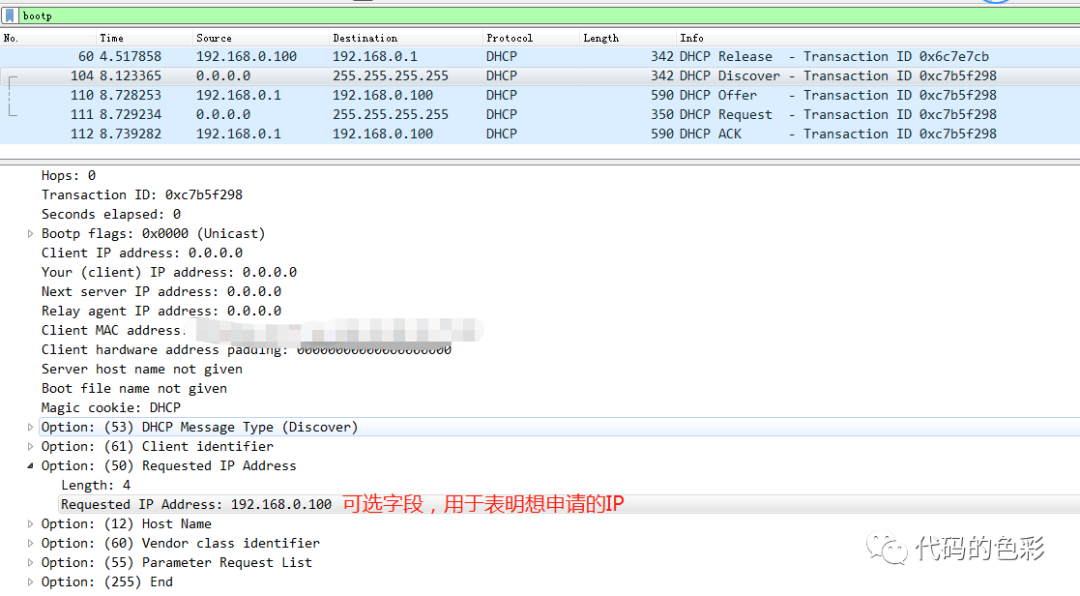
DHCP发现。新加入的主机在局域网发一个广播包,询问谁可以给我分配一个IP DHCP提供。有IP分配权限的机器(一般是路由器)会热情地分配IP并且回复分配的IP、子网掩码和租期以及自身的IP地址。 DHCP请求。由于可能出现多个DHCP服务器,因此主机需要通知所有的DHCP服务器,他选了哪个IP和DHCP服务器。此时那些没有被选中的DHCP服务器就可以回收刚才分配出去的IP。 DHCP确认。被选中的DHCP服务器向主机确认主机的请求。
用神器WireShark观察可以这个过程。首先在Windows的终端输入命令ipconfig /release断开网络连接,接着输入ipconfig /renew即可观察到下面的抓包了。记得用bootp过滤,而不是DHCP。
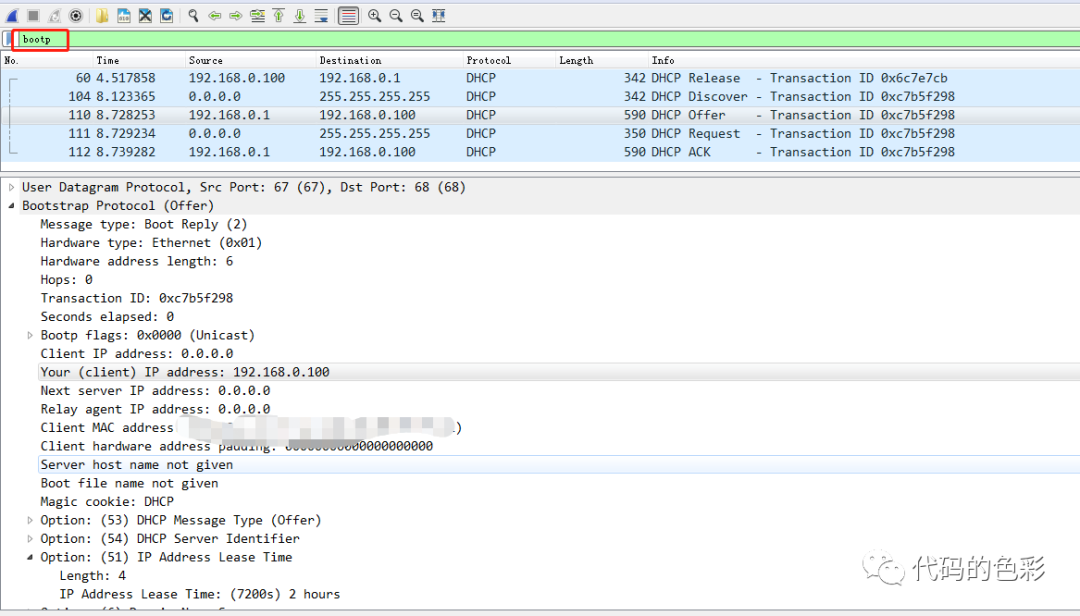
可以观察到在DHCP Offer包中,路由器192.168.0.1给主机分配了IP地址192.168.0.100,租期为2个小时。
如果经常搞局域网的读者会发现自己的同一个局域网的IP基本上都是一样的。这个好像和动态分配IP地址有点矛盾。嗯,主要是客户端提出续约之前的IP。当主机之前的租期过半的时候就会向原来的DHCP发送一个续期请求,DHCP服务器再次确认即可继续使用之前的IP。这个续约请求也是刚才的DHCP Discover包。如下图:
与局域网内的小伙伴玩耍
我们一般直接用IP地址跟局域网的其他主机交互,比如ping某个ip,telnet某个ip。但内网主机间通信是基于mac地址通过数据链路层传输数据的。换言之,将数据发过去不能依靠对方的IP地址,而是得依靠MAC地址。但我们日常哪里有用过MAC地址,我们也记不住长长的MAC地址。此时,ARP协议登场了。它能够通过IP地址找到对应的MAC地址。
ARP协议是一个比较简单的协议。交互过程就是一问一答。先是询问方广播:
询问方:你有xxxx这个IP,告诉我(把自己的IP和MAC地址附上) 目标方:xxxx这个IP的MAC地址是yyyy。
如下图:
PS: ARP查询结果是会缓存在本地的,所以会出现第一次ping 局域网机器会有ARP查询报文。第二次ping就看不到这个ARP查询报文了。
外面的世界那么大, 我想出去看看
当然我们不会满足于只在内网玩。外面的世界那么大,我确实想出去看看。怎么办?这里假定我们是通过最常用的tcp协议出去的。假设我们在昨晚梦中得到外面世界某个景点的ip地址。
要出去第一步是需要知道自己家附近有哪些车可以去到目的地。因此第一步就是查一下车次信息。在哪里查?在路由表中查。Windows: route print , Linux: netstat -nr
不不不,第一步不是去搭车啊。因为可能那个IP就是你邻居的IP啊,邻居的话,直接走路过去即可(前面的内网通信)。因为可能是你睡着的时候邻居在你身边不断重复说某个IP,你醒后对这个IP有印象。那怎么知道这个IP是不是你邻居的IP?找村长(路由器)查吗?村长才不管你昨晚做了什么梦。那只能靠自己了。
怎么才知道是不是自己的邻居?当然要自问一下,怎么的IP才能称为自己的邻居。嗯,这个嘛,同一个子网嘛。是的!所以只需用自己的子网掩码跟自己的IP异一下,再用自己的子网掩码跟目标IP异一下,对比两个结果。如果一致,那么就是邻居了。如果不同,那么就不是邻居了。
假定梦中的IP不是邻居,那么我们只能搭车去了。回到车站,查一下车次信息。在Windows中用命令route print,在Linux中用命令netstat -nr可以查询到路由表(也就是车次表)。下表是例子。
| Destination | Gateway | Flags | Refecnt | Use | Interface |
|---|---|---|---|---|---|
| 140.252.13.65 | 140.252.13.35 | UGH | 0 | 0 | emd0 |
| 127.0.0.1 | 127.0.0.1 | UH | 1 | 0 | lo0 |
| default | 140.252.13.33 | UG | 0 | 0 | emd0 |
| 140.252.13.32 | 140.252.13.34 | U | 4 | 25043 | emd0 |
关注上表中的第一列和第二列,第一列表示目的地,第二列表示去这个目的地要从这个网关出发。default就是说如果目的地不在其他路由记录中找到的话,就走这条路由。路由表的记录是可以手动添加的。添加的时候千万不加错了,不然可能会使得某些目的地走错了网关,永远到不了目的地。
去一个遥远的地方可能需要换好几次车才能到达目的地,本地的路由表只是第一趟车的车次信息。如果想查后面搭的每一趟车,在Windows用命令tracert host,Linux用命令traceroute host。一个查询结果如下图:
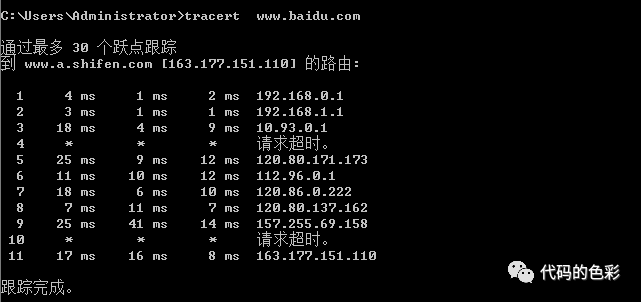
这个查询的原理是利用IP报文可以设置最大跳数(到达一个路由器就是一跳),只需从1开始依次增大跳数,就能知道每一步能达到的路由。
经过前面的折腾终于找到了一条通往终点的乘车路线。由于采用了实名制乘车,作为只有内网IP的你(也就是没有实名制),是没有办法乘车的。怎么样才能实名制得到公网IP?找村长(路由器)分配?可惜,大部分情况下路由器也有一个公网IP,无法给你一个人使用。这个问题是通过NAT协议解决的。
内网主机对外提出访问时,会在本机发起一个tcp请求,tcp首部会随机使用本地的一个端口号。当经过路由器时,路由器会修改TCP首部里面的端口号,以及IP包首部的源IP。端口会被修改成路由器指定的一个端口,源IP则被修改为路由的公网IP, 这样就有了身份证。路由器还需要记录新的端口和源端口的映射关系,当路由器收到外面世界的回包时,根据回包的目的端口号找到原始的端口号,修改回包的目的IP和端口号。在内网主机看来,端口号和IP地址都对得上,是属于自己的包,接收!
TCP与Socket编程
TCP有三次握手和四次挥手,其状态转移图如下。
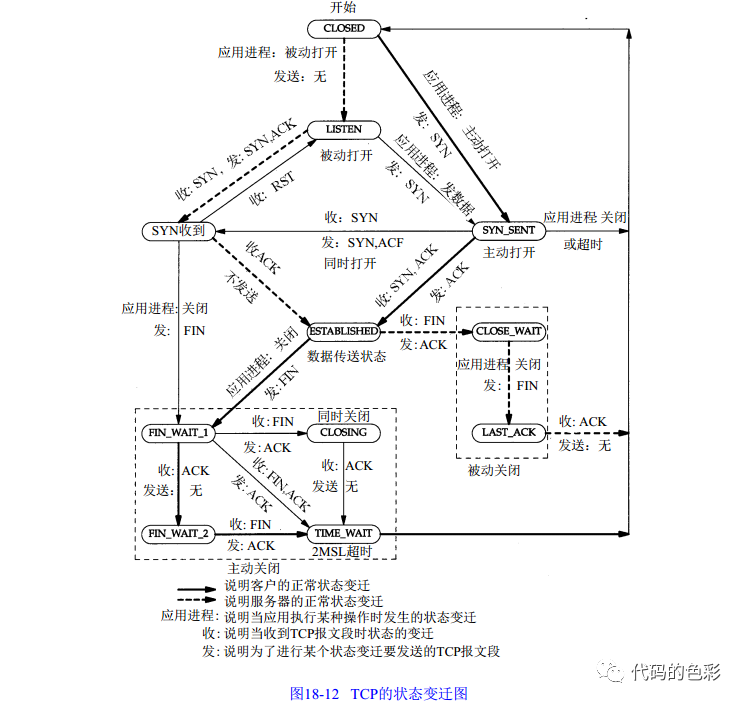
接下来通过socket编程介绍tcp的三次握手和四次挥手。
socket编程中,客户端的connect、服务器端的accept和tcp的三次握手是怎样的对应关系?对于阻塞型的connect来说,当connect和accept返回时就说明已经完成了三次握手(当然也可能失败)。
那能不能观察到中间状态,或者有相关参数可以影响三次握手?是可以的。对于客户端,需要将套接字设置成非阻塞的;对于服务器端listen函数的第二个参数是int backlog,其含义是两个队列长度之和:1. 未完成连接队列;2. 已完成连接队列。此时,三次握手的过程如下:


第一次握手:客户端调用connect会马上返回,而不会等三次握手完成才返回。此时,客户端的套接字进入到SYN_SENT状态,等候后面的两次握手。
第二次握手:当接收到客户端一个SYN握手请求时,会返回一个SYN和ACK给客户端,并且将这个待完成三次握手的套接字放到这个未完成队列,并且将套接字的状态设置成SYN_RCVD。
第三次握手:客户端收到服务器的握手ACK后,会向服务器端再发送一个ACK,此时客户端套接字进入到ESTABLISHED状态。服务器端收到客户的ACK后,会将对应的套接字从未完成连接队列挪到已完成连接队列,并且将该套接字也设置成ESTABLISHED状态。
PS:对于设置为非阻塞的客户端套接字,调用完connect后,一般是通过监听该套接字可写情况感知三次握手是否完成。
对于四次挥手,先看几道经典的面试题:
某GM的经典题库题目:read返回0表示什么? 为什么服务器端要设置SO_REUSEADDR? 客户端和服务器端,一般是谁进入到TIME_WAIT状态?其作用是什么?2MSL超时又是什么?
一般来说,先断开连接的一方会最终进入到TIME_WAIT状态。此时如果socket上已经没有数据了,另外一方再去read就会返回0。所以当read返回0说明对方关闭了socket。
TIME_WAIT状态要停留2MSL超时的原因有两个:
留意状态图中的FIN_WAIT2到TIME_WAIT状态的动作。主动关闭的一方收到对端的FIN后要回复一个ACK。但这个ACK可能会在半路丢失。对端在一定时间内没有收到该ACK,又会重发一个FIN。如果还停留在TIME_WAIT状态的话,那么在收到FIN后会继续发送ACK 。如果不处于TIME_WAIT状态,就会直接响应一个RST。收到RST的一端会觉得关闭socket失败。为了避免这个,需要停留2MSL的超时。 假设TIME_WAIT的停留时间为0。考虑下面情况:关闭后,两端又马上建立另外一个具有相同目标和源端口号都和之前一致的新连接,并且之前四次挥手的时候有一个FIN包迷路了。在建立连接之后,那个迷路的FIN终于达到了目的地。此时,会被这个FIN将会被认为是新连接的断开挥手。
对于服务器来说,如果由于出现了bug导致进程退出。由于服务器的主动退出的,所以会进入TIME_WAIT状态,需要等待2MSL。但进程应该被马上拉起并对外提供服务,不能耽误一刻。因此需要设置参数SO_REUSEADDR。
HTTP
DNS
前面提及,到外面玩耍需要公网IP,但我们日常极少使用IP。主要是IP地址是一个无意义难于记忆的一串文本。为了方便人们记住上网用的地址,发明了域名。但底层终究还是得用IP地址。为此,需要一个协议将域名转换成IP。这个协议就是DNS(Domain Name System)。这个服务一般是宽带供应商提供,当然也可以自行指定一个DNS服务器地址。下图是一个查询结果:
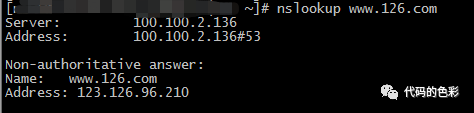
这个DNS查询是浏览器自动进行的,并且会有缓存。DNS的查询原理和过程过于无聊,这里就不展开了,有兴趣的可以参考https://blog.csdn.net/luotuo44/article/details/45545059
经典问题:为什么域名根服务器只有13个?简单来说,就是DNS查询默认是UDP协议的,而不被分片的UDP报文长度是512字节的,这个长度只能放下13个IP地址。具体的计算可以参考https://www.zhihu.com/question/22587247/answer/1021961852
前面的查询本质上是向DNS服务器查询某个域名的A记录。但除了A记录还有AAAA记录(IPv6)、MX记录(邮箱)和CNAME记录。CNAME记录主要是用于CDN的,也就是网络加速,你刷快手、知乎都是需要CDN加速的,不然慢得一逼。CNAME过于人(ren)工(rou)智(pei)能(zhi)就不展开讲了。
报文
http协议报文是一个纯文本的协议,一行一行的。
请求信息由请求行、请求头、空行和其他消息体组成。如下图。

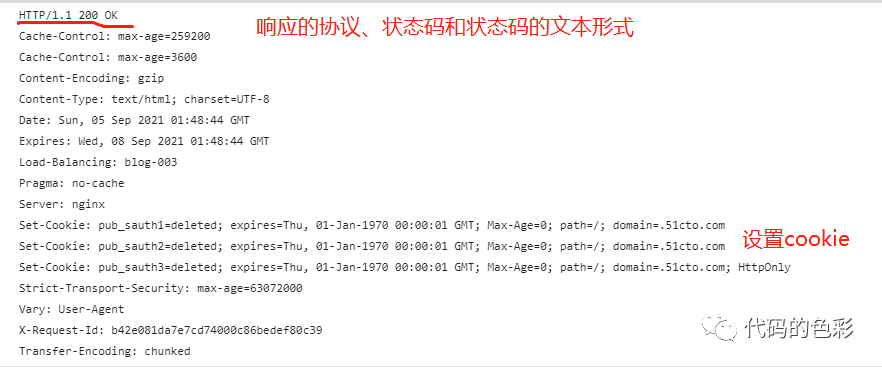
响应信息也是有响应行、响应头和其他消息组成。如下图。
http问题与解决
性能问题
HTTP经历了0.9、1.0、1.1和2.0几个版本,性能是其中一条发展主线。如何才能做到请求文件性能最好?最好当然是不请求,这样就不会有耗时。当然这不现实,退而求其次就是尽量减少交互,减少RTT。
对于1.0版本,默认是一次请求就新建一个TCP连接,用完就关闭这个连接。在1.1版本时,改进了这点。默认会重复使用之前的连接,也就是持久连接。传完一个文件后,继续用同一个tcp连接传输下一个文件。这样就减少了tcp三次握手的时间。此外,考虑到tcp的慢启动以及http文本本身是小文件,复用连接会使得后面的的传输速度更快。
为什么不将所有文件都打包成一个?确实是可以这样做,并且像Vue这样的框架确实会将多个js文件打包成一个。但这终究不应该将js、css、html和png文件打包成一个。
那为什么要串行请求文件,而不是并发多个tcp连接同时请求文件?很可惜并发数是有限制的。浏览器对于同一个域名最多只允许同时存在6条连接。当然这个限制也有一些办法突破,比如说我多搞几个域名,将js、css和png这些静态文件放到一个固定的域名,其他域名直接引用即可。像Vue这类工具在打包的时候就可以选定哪些文件不打包进去,此时可以将这些js、css和png文件放到CDN上,提高访问速度。
http 1.1还有一个慢的原因:队首阻塞。假设客户端在同一个连接先发送了一个js资源的请求,再发送了一个css资源的请求。而服务器这边先将css文件准备就绪,但服务器还是先等js资源发送给客户端之后才能传输css资源。也就是后面的资源得先等前面传输完毕才能传输,这也是称为队首阻塞的原因。
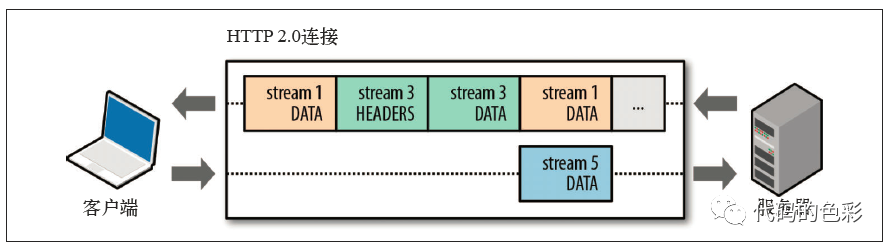
http2.0给的解决方案是使用数据帧。如下图,对于每个请求都加入帧标识,服务器在响应的时候也携带这个帧标识,这样即使乱序返回给客户端,客户端也能正确识别。
安全性问题
跨域、https、无状态
无状态
http协议是一个无状态的协议。也就是说在协议层面,即使是同一个客户端和服务器端,前后两个http请求都是独立无关的。但现实世界里,又要求做到前后相关。比如我前脚将商品加入了购物车,我后面查看的购物车详情的时候要能看到购物车的内容。
为了实现有状态,就需要认证客户端。知道这次的请求是谁在操作。

session
最常见的解决方案是服务器session了。服务器为该客户生成一个session并保存到服务器内存中,然后生成一个能找到该session的ID,并将这个ID作为cookie写入到客户端中。当客户端再次请求时会自动写到cookie。服务器再根据cookie里面的ID找到session,这样就知道这个客户是谁,他之前的数据是什么。
session方案也是有一些问题。当服务扛不住需要水平扩展时,怎么跨机器共享session?共享sessin的原因是,这个客户前后两次的请求到的服务器不是同一台机器。解决办法可以将session统一写到另外一个地方,比如redis集群。也可以根据用户ID,将同一个客户路由到同一台服务器,这样就没有共享的问题了。
此外,保存在浏览器的cookie有被盗取的风险,参考后面的跨域。
jwt
前面session的方案是将用户信息存储在服务器上,而jwt则将信息存储在客户端。服务器负责生成JWT,传给客户端。客户端每次请求都带上这个JWT。服务器校验JWT是否合法,并且从JWT的内容读取该用户是谁。
JWT是由三部分组成,分别是头部、负荷和签证。并且用.号分隔,也就是header.payload.signature。
头部由令牌类型(即JWT)和所使用的签名算法组成,如下
{
"type": "JWT",
"alg": "HS256"
}
这个json会用base64编码作为header。
负荷则是存放一些有效信息的地方。比如用户的ID,过期时间等。其也是一个JSON。常见的字段如下:
iss:JWT签发者
sub:JWT面向的用户
aud:接收JWT的一方
exp:JWT的过期时间
iat:JWT的签发时间
除了常见的字段,也可以添加自己所需的字段。这json最终通过base64编码作为payload。
签证就是用头部申明的加密方法对header.paylod字符串进行加密,得到signature。注意密钥只保存在服务器上。
显然,payload部分可以填写用户的相关信息,比如用户名用户ID等信息。而signature部分则保证payload部分的内容不能被篡改。由于payload部分是明文传输的,所以JWT的应用场景最好是https。
跨域
跨域是浏览器本身禁止了一些行为。比如在A网站的页面禁止向B网站发起一个获取非js、css、png资源的HTTP请求。这主要是出于安全考虑。因为浏览器访问B网站会将B网站存储在浏览器的cookie也带上。有了cookie,那么A网站就可以伪造成用户向B网站发起请求。比如A网站的开发人员打听到B网站的一个支付URL是https://B.com/payTo/user?userId=xxxx, A网站返回的内容有一个按钮,当用户点击这个按钮时发起的请求就是刚才那个URL,那相当于在用户不知情的情况下进行了支付操作,因为在B网站看来携带的cookie是该用户的。
注意:js、css、png/jpg这些静态文件并不会出现跨域问题。
浏览器禁止了这种行为,但在前后端分离的开发模式下,前后端提供服务的域名往往是不同的。这导致前端的请求无法请求后台的数据。这就是跨域问题的由来。跨域问题既可以在服务器端解决,也可以在客户端解决。
服务器端方法
前面介绍跨域由来的原因可知,其影响的是B网站数据安全。所以,假设B网站本身就允许从A网站发出请求,那么浏览器也没有理由禁止这种行为。一般来说,浏览器碰到跨域时都会先向B网站发起一个OPTIONS方法的请求,向B网站申请跨域,B网站响应允许跨域。如下图:
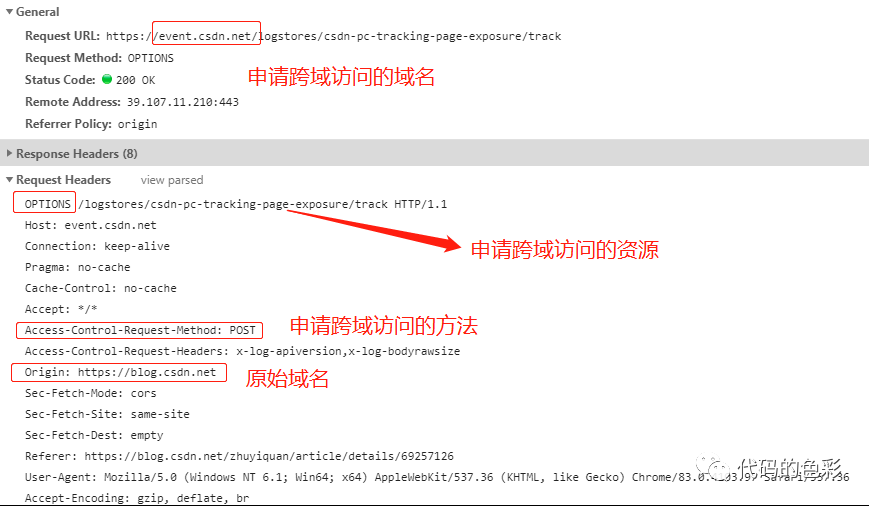
响应如下:
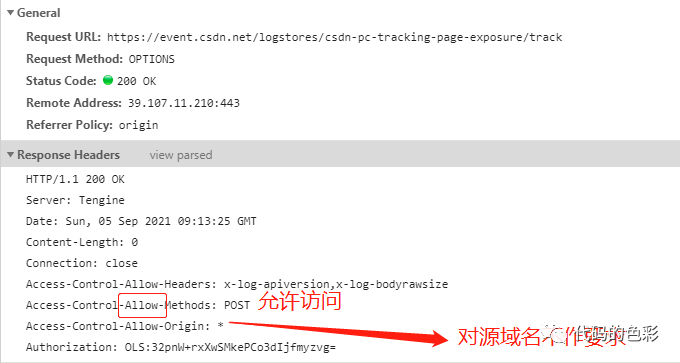
具体要怎么设置呢?
假如源域名为localhost:9528, 跨域的域名为127.0.0.1:8000,其中8000所在的nginx要配置如下:
Access-Control-Allow-Credentials: true
Access-Control-Allow-Headers: Origin,Content-Length,Content-Type,X-Token
Access-Control-Allow-Methods: GET,PUT,POST,PATCH,DELETE,HEAD
Access-Control-Allow-Origin: http://localhost:9528
Access-Control-Max-Age: 43200
如果127.0.0.1:8000没有涉及到cookie,那么也可以不设置Access-Control-Allow-Credentials以及将Access-Control-Allow-Origin也可以设置为*,表示源域名可以是任意的。
如果访问127.0.0.1:8000要用到cookie,那么就必须将Access-Control-Allow-Credentials设置为true,并且Access-Control-Allow-Origin设置成具体的源域名,表示本站可以被哪些域名所跨。
如果不想在nginx里面设置,那么对于gin,设置代码如下:
func settingCors(r *gin.Engine){
r.Use(cors.New(cors.Config{
AllowOrigins: []string{"http://localhost:9528"},
AllowMethods: []string{"GET", "PUT", "POST", "PATCH", "DELETE", "HEAD"},
AllowHeaders: []string{"Origin", "Content-Length", "Content-Type", "x-token"},
AllowCredentials: true,
MaxAge: 43200 * time.Second,
}))
}
上面代码可以发现,Access-Control-Allow-Origin是可以写多个的域名的。
对于spring boot,设置代码如下:
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("http://localhost:9528")
.allowCredentials(true)
.allowedMethods("GET", "POST", "DELETE", "PUT","PATCH")
.allowedHeaders("Origin", "Content-Length", "Content-Type", "x-token")
.maxAge(3600);
}
}
客户端方法
客户端解决跨域的方法就是不跨域,就是不要跟浏览器硬刚。
比如对于所有需要跨域访问的资源,都在其URI前面加一个特定的前缀(如api),然后设置代理捕抓这个前缀,并且更改其访问的Host,从而绕过浏览器的跨域限制。
对于Vue,具体代码如下:
//main.js文件
import axios from 'axios'
Vue.prototype.$axios = axios;
if(process.env.NODE_ENV === "development") {
axios.defaults.baseURL = "/api"; //加入前缀
}
//vue.config.js
devServer: {
host: "localhost",
port: 8081, // 端口号
https: false, // https:{type:Boolean}
open: true, //配置自动启动浏览器
proxy: {
"/api": {
target: "http://127.0.0.1/v1",// 待跨域的后端域名和前缀
//ws: true,// 是否启用websockets
changeOrigin: true, //开启代理:在本地会创建一个虚拟服务端,然后发送请求的数据,并同时接收请求的数据,这样服务端和服务端进行数据的交互就不会有跨域问题
pathRewrite: {
'^/api': '' //去掉前缀/api
}
}
}
}
参考
https://zh.wikipedia.org/wiki/%E5%8A%A8%E6%80%81%E4%B8%BB%E6%9C%BA%E8%AE%BE%E7%BD%AE%E5%8D%8F%E8%AE%AE https://blog.csdn.net/zqixiao_09/article/details/77131239 https://blog.51cto.com/yupeizhi/1413886 《TCP/IP详解 卷1:协议》 《Web性能权威指南》 https://www.jianshu.com/p/576dbf44b2ae

声明
本公众号部分分享的资料来自网络收集和整理,所有文字和图片版权归属于原作者所有,且仅代表作者个人观点,与本公众号无关。文章仅供读者学习交流使用,并请自行核实相关内容。如文章内容涉及侵权,请联系后台管理员删除。
「校招季节,给大家送上BAT的内推福利」
腾讯:https://join.qq.com/judgetalent.html?rec_key=1Hw3F6hAZNfQtgpR5MwRwOJ5V4uEeu0PKvjK-y0hROY
字节:https://jobs.toutiao.com/s/d6STPBd
阿里:
不要问我为什么B是字节,阿里的内推不是链接。
更多干货请点击关注
▼