
Java协程实践指南(一)

一. 协程产生的背景
说起协程,大多数人的第一印象可能就是GoLang,这也是Go语言非常吸引人的地方之一,它内建的并发支持。Go语言并发体系的理论是C.A.R Hoare在1978年提出的CSP(Communicating Sequential Process,通讯顺序进程)。CSP有着精确的数学模型,并实际应用在了Hoare参与设计的T9000通用计算机上。从NewSqueak、Alef、Limbo到现在的Go语言,对于对CSP有着20多年实战经验的Rob Pike来说,他更关注的是将CSP应用在通用编程语言上产生的潜力。作为Go并发编程核心的CSP理论的核心概念只有一个:同步通信。
首先要明确一个概念:并发不是并行。并发更关注的是程序的设计层面,并发的程序完全是可以顺序执行的,只有在真正的多核CPU上才可能真正地同时运行。并行更关注的是程序的运行层面,并行一般是简单的大量重复,例如GPU中对图像处理都会有大量的并行运算。为更好的编写并发程序,从设计之初Go语言就注重如何在编程语言层级上设计一个简洁安全高效的抽象模型,让程序员专注于分解问题和组合方案,而且不用被线程管理和信号互斥这些繁琐的操作分散精力。
在并发编程中,对共享资源的正确访问需要精确的控制,在目前的绝大多数语言中,都是通过加锁等线程同步方案来解决这一困难问题,而Go语言却另辟蹊径,它将共享的值通过Channel传递(实际上多个独立执行的线程很少主动共享资源)。在任意给定的时刻,最好只有一个Goroutine能够拥有该资源。数据竞争从设计层面上就被杜绝了。为了提倡这种思考方式,Go语言将其并发编程哲学化为一句口号:

Do not communicate by sharing memory; instead, share memory by communicating.
不要通过共享内存来通信,而应通过通信来共享内存。
这是更高层次的并发编程哲学(通过管道来传值是Go语言推荐的做法)。虽然像引用计数这类简单的并发问题通过原子操作或互斥锁就能很好地实现,但是通过Channel来控制访问能够让你写出更简洁正确的程序。
在《七周七并发模型》中描述的七种并发编程模型。
参考: https://www.cnblogs.com/barrywxx/p/10406978.html
线程与锁:线程与锁模型有很多众所周知的不足,但仍是其他模型的技术基础,也是很多并发软件开发的首选。
函数式编程:函数式编程日渐重要的原因之一,是其对并发编程和并行编程提供了良好的支持。函数式编程消除了可变状态,所以从根本上是线程安全的,而且易于并行执行。
Clojure之道——分离标识与状态:编程语言Clojure是一种指令式编程和函数式编程的混搭方案,在两种编程方式上取得了微妙的平衡来发挥两者的优势。
actor:actor模型是一种适用性很广的并发编程模型,适用于共享内存模型和分布式内存模型,也适合解决地理分布型问题,能提供强大的容错性。
通信顺序进程(Communicating Sequential Processes,CSP):表面上看,CSP模型与actor模型很相似,两者都基于消息传递。不过CSP模型侧重于传递信息的通道,而actor模型侧重于通道两端的实体,使用CSP模型的代码会带有明显不同的风格。
数据级并行:每个笔记本电脑里都藏着一台超级计算机——GPU。GPU利用了数据级并行,不仅可以快速进行图像处理,也可以用于更广阔的领域。如果要进行有限元分析、流体力学计算或其他的大量数字计算,GPU的性能将是不二选择。
Lambda架构:大数据时代的到来离不开并行——现在我们只需要增加计算资源,就能具有处理TB级数据的能力。Lambda架构综合了MapReduce和流式处理的特点,是一种可以处理多种大数据问题的架构。
通常语言的并发模型有以下几种。
线程模型
操作系统抽象,开发效率高,IO密集、高并发下切换开销大。
异步模型
编程框架抽象,执行效率高,破坏结构化编程,开发门槛高。
协程模型
语言运行时抽象,轻量级线程,兼顾开发效率和执行效率。
二. Java协程发展历程
Java本身有着丰富的异步编程框架,比如说CompletableFuture,在一定程度上缓解了Java使用协程的紧迫性。
在2010年,JKU大学发表了一篇论文《高效的协程》,向OpenJdk社区提了一个协程框架的Patch,在2013年Quasar和Coroutine,这两种协程框架不需要修改Runtime,在协程切换时本来是要保存调用栈的,但是它们不保存这个调用栈,而是在切换时回溯调用链,生成一个状态机,将状态机保存起来。

Quasar和Coroutine并不是OpenJdk社区原生的协程解决方案,直到2018年1月,官方提出了Project Loom,到了2019年,Loom的首个EA版本问世,此时Java的协程类叫做Fiber,但社区觉得这引入了一个新的概念,于是在2019年10月将Fiber重新实现为了Thread的子类VirtualThread,兼容Thread的所有操作。
这时Project Loom的基本雏形已经完成了,在它的概念中,协程就是一个特殊的线程,是线程的一个子类,从Project Loom已经可以看到Open Jdk社区未来协程发展的方向, 但Loom还有很多的工作需要完成,并没有完全开发完。
三. Project Loom的目标与挑战
目标
易于理解的Java协程系统解决方案,协程即线程。
Virtual threads are just threads that are scheduled by the Java virtual machine rather than the operating system.
挑战
兼容庞大而复杂的标准类库、JVM特性,同时支持协程和线程。
四. Loom实现架构
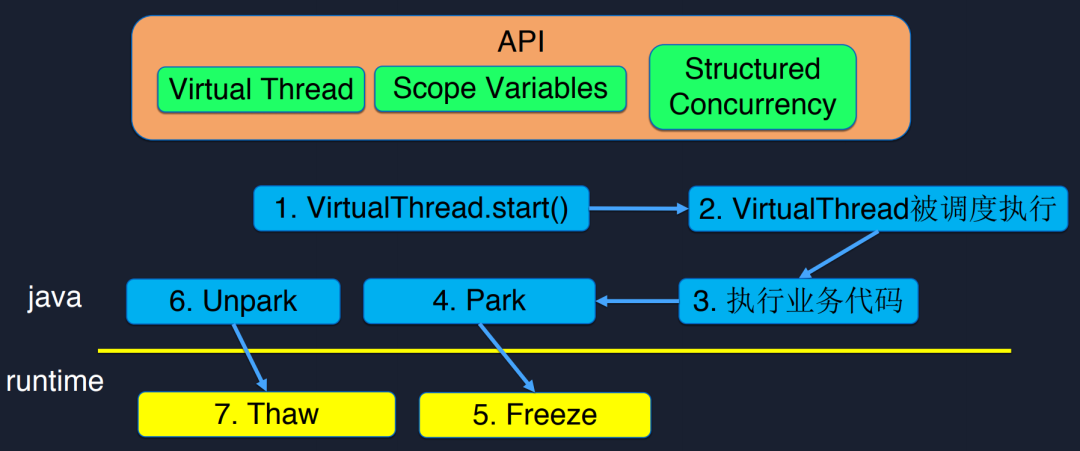
在API层面Loom引入最重要的概念就是Virtual Thread,对于使用者来说可以当做Thread来理解。
下面是协程生命周期的描述,与线程相同需要一个start函数开始执行,接下来VirtualThread就会被调度执行,与线程不同的是,协程的上层需要一个调度器来调度它,而不是被操作系统直接调度,被调度执行后就是执行业务代码,此时我们业务代码可能会遇到一个数据库访问或者IO操作,这时当前协程就会被Park起来,与线程相同,此时我们的协程需要在切换前保存上下文,这步操作是由Runtime的Freeze来执行,等到IO操作完成,协程被唤醒继续执行,这时就要恢复上下文,这一步叫做Thaw。
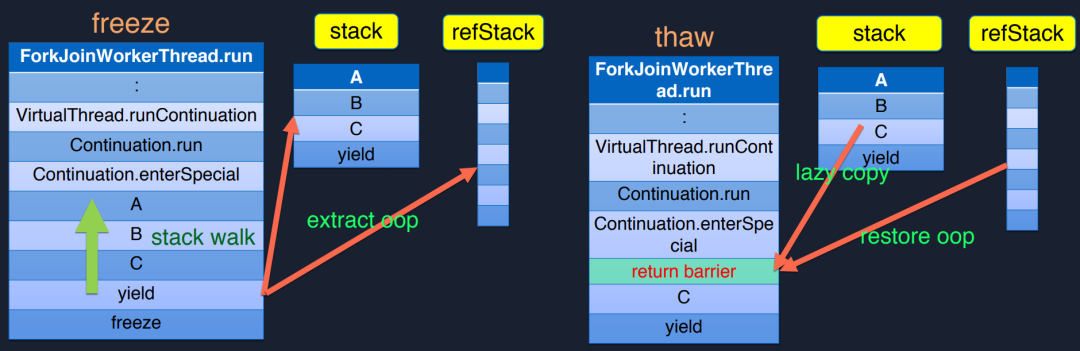
1. Freeze操作
上图左侧是对Freeze的介绍,首先一个协程要被执行需要一个调度器,在Java生态本身就有一个非常不错的调度器ForkJoinPool,Loom也默认使用ForkJoinPool来作为调度器。
图中ForkJoinWorkerThread调用栈前半部分直到enterSpecial都是类库的调用栈,用户不需要考虑,A可以理解为用户自己的实现,从函数A调用到函数B,函数B调用函数C,函数C此时有一个数据访问,就会将当前协程挂起,yield操作会去保存当前协程的执行上下文,调用freeze,freeze会做一个stack walk,从当前调用栈的最后一层(yield)回溯到用户调用(函数A),将这些内容拷贝到一个stack。这也是协程栈大小不固定的原因,我们可以动态扩缩协程需要的空间,而线程栈大小默认1M,不管用没用到。而协程按需使用的特点,可以创建的数量非常多。extract_pop是Loom非常好的一个优化,它将ABC调用栈中的Java对象单独拷贝到一个refStack,在GC root时,如果把协程栈也当做root,几百万个协程会导致扫描停顿很久,Loom将所有对象都提到一个refStack里面,只需要处理这个stack即可,避免过多的协程栈增加GC时间。
2. Thaw操作
Thaw用于恢复执行,如果将stack里面ABC、yield全部拷贝回执行栈里面可能是很耗时的,因为执行栈可能非常深了,Loom社区成员在调研后发现,函数C可能不止一个数据访问操作,在恢复执行栈之后,可能因为C的IO操作又会再次切换上下文,所以Loom用了一种lazy copy的方式,每次只拷贝一部分,执行完成之后遇到return barrier则继续去stack中拷贝。这样除了第一次切换开销比较大,其他所有的切换开销都会很小。
另一方面refStack里面保存的OOP要restore回来,因为很多的GC可能在执行时将OOP地址改了,如果不restore之后访问可能会出现问题。
五. Loom使用
Virtual Thread创建
通过Thread.builder创建VirtualThread
通过Thread.builder创建VirtualThread工厂
默认ForkJoinPool调度器(负载均衡、自动扩展),支持定制调度器
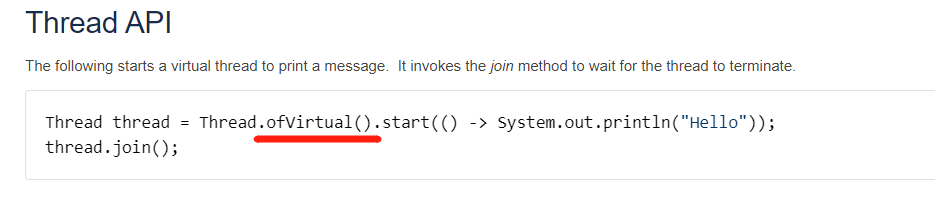
定制调度器
static ExecutorService SCHEDULER_1 = Executors.newFixedThreadPool(1);Thread thread = Thread.ofVirtual().scheduler(SCHEDULER_1).start(() -> System.out.println("Hello"));thread.join();
创建协程池
ThreadFactory factory;if (usrFiber == false) {factory = Thread.builder().factory();else {factory = Thread.builder().ofVirtual().factory();}ExecutorService e = Executors.newFixThreadPool(threadCount, factory);for (int i=0; i < requestCount; i++) {e.execute(r);}