
这几点鲜有人知的爬虫技巧,让你爽歪歪!
今天小帅b想跟分享几个
关于爬虫可以用到的技巧
用好让你爽到飞起

一、换个角度,解锁新姿势
我知道
你在爬取某些 web 网站的时候
被各种反爬弄得哭天喊地
什么几把 css 字体加密
什么几把 js 的 MD5 等
各种乱七八糟的加密
什么几把各种飞的验证码

这时候
就别太执着于 web PC 端嘛
咱们去看看人家的移动端
看看人家的 H5
在爬取前可以问问对方:
“在吗?看看 H5”

可能你会在移动端发现惊喜
数据都是一样的数据
冤冤相报何时了
二、夜太美,爬虫就没那么危险
在爬取的时候
不要猛攻嘛~
人家受不了啊
你要学会停顿
克制一点
该 sleep 就 sleep

要趁人家睡觉的时候
限制防范程度低的时候
能晚点就晚点再去爬
没看过凌晨四点的洛杉矶
但是你可以看到凌晨四点的爬虫啊
这样你买的 IP 才不会频繁被封
三、善用他人的 UA
如果你去看别人网站的 robots.txt
你就会看到别人的声明
声明什么东西是可以爬取
什么东西是不允许被爬的
但你常常忽略了一个东西
人家声明了希望给什么搜索引擎爬
比如这个
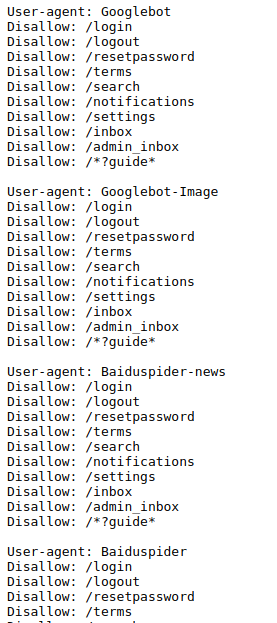
看到没
这是别人定义的 robots
值得注意的是
尚亮亮的 User-agent
那么当你在 Python 构造 Header 的时候
User-agent 就直接指定他们 robots 定义的就好了啊
比如 百度的UA,google的UA,360的UA
你再去爬取看看
那是一个友好啊

四、插件让你节省时间
有时候我们要拿一些关键的数据
往往会用到 xpath、css selctor 之类的
自己一个一个去比对获取
那就太麻烦了啊
还记得之前说得这个吗?
记得用起来呀
五、那 Header 快速生成吧
每一次你在复制 request header 的时候
是不是有一大串有的没的
又不得不复制过来
在你的 Python 中使用

可是
格式又不对
每次操作很麻烦是不?
那你可以自己写一个方法
参数就是你复制的 header 字符串
然后生成 header 的字典格式
不就完事了
六、爬取整站其实是这样的
有时候你想爬取整个网站的url
怎么办呢?
不是去首页一个一个抓
你应该找到对方的 sitemap.xml
因为网站一般希望 Google 或者百度快点收录他们的网站
所以他们会把自己的网站的 url 生成 sitemap 提交
这个时候 sitemap 就包含了这个网站所有可爬取的 url
sitemap一般在网站的根目录下
可以在他们的 robots.txt 看看他们指定的位置
比如猫眼电影的sitemap:
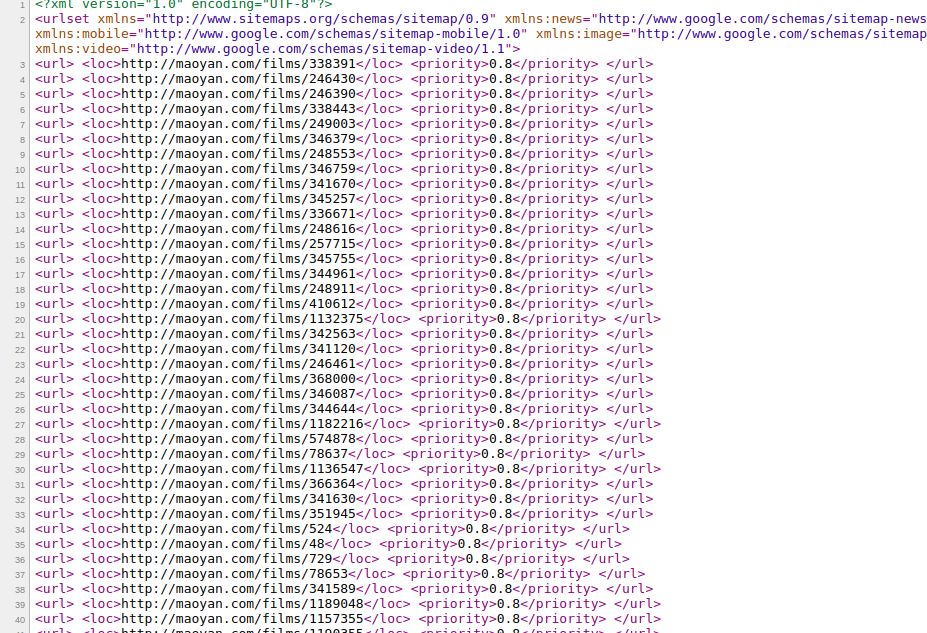
从而获取 sitemap 再去请求里面的 url 即可!
ojbk
以上就是小帅b
给你分享的爬虫技巧
希望对你有帮助
那么我们下回见
回复关键词「简明python」,立即获取入门必备书籍《简明python教程》电子版
回复关键词「爬虫」,立即获取爬虫学习资料
推荐阅读