
新闻平台聚合之纽约时报爬虫发布
idea of startproject
对于 web 开发者而言,目前各大新闻门户网站,新浪新闻,百度新闻,腾讯新闻,澎湃新闻,头条新闻并没有提供稳定可用的 feed api。
对于 nlper,缺乏足够的新闻语料数据集来供训练。
对于新闻传播/社会学/心理学等从业者,缺乏获取新闻数据的简单易用途径来供分析。
如果上面三点是某见识所限,其实并不存在的话,第 4 点,则是某的私心,某以为互联网的记忆太短了,热搜一浪盖过一浪,所以试图定格互联网新闻的某些瞬间,最后会以网站的形式发布出来。
project 的 Github:https://github.com/Python3Spiders/AllNewsSpider
本篇是 新闻系列 的第四篇,以美国著名的报纸:纽约时报网站为目标站点。

这次的新闻爬虫和以往有很大不同,不再以分类形式抓取新闻,而是以关键词搜索抓取新闻,具体可以往下读。
纽约时报爬虫
该爬虫实现的主要功能罗列如下:
按自定义关键词搜索纽约时报上的新闻内容,抓取保存到本地
可以自定义抓取的起止时间
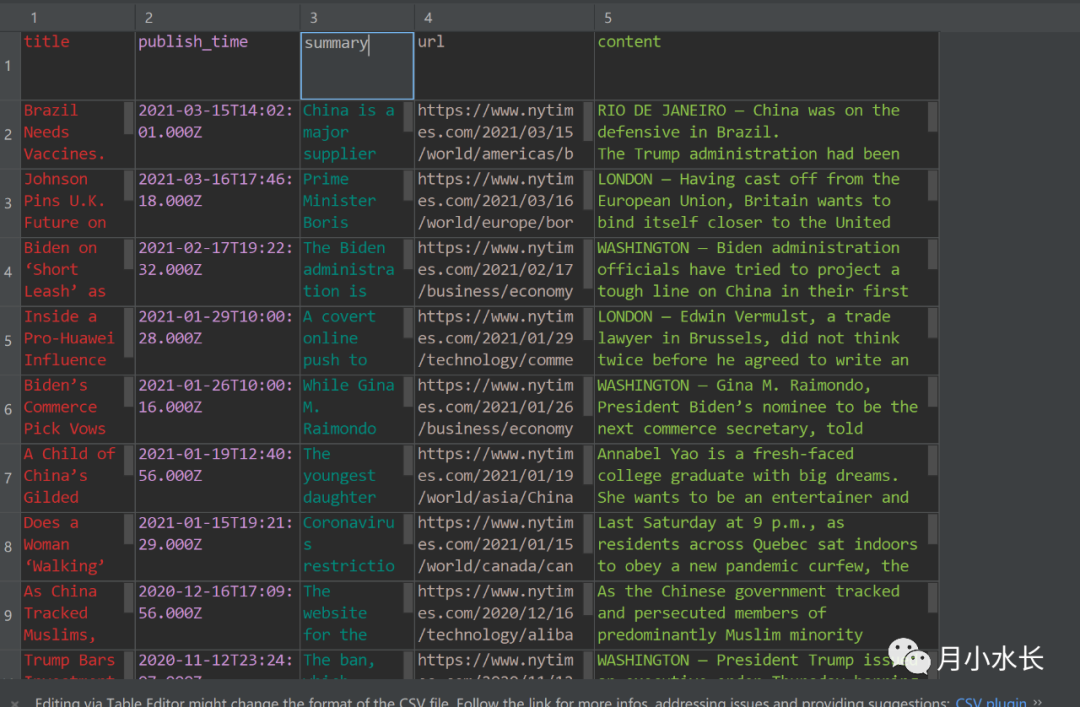
字段信息较为齐全,如下表格
| 字段名 | 字段含义 |
|---|---|
| title | 新闻标题 |
| summary | 新闻概括 |
| url | 新闻链接 |
| publish_time | 新闻发表时间 |
| content | 新闻具体内容 |
再说说如何使用(默认读者均有 python3.6+ 环境)
将仓库 nytimes 文件夹下的 nytimes_news_spider.pyd 文件下载到本地,新建项目,把 pyd 文件放进去
项目根目录下新建 runner.py,写入以下代码即可运行并抓取
from nytimes_news_spider import main
if __name__ == '__main__':
main(keyword="huawei", beginDate="20210101", endDate="20210318")
爬取结束了,会在当前目录下生成一个 {keyword}(nytimes).csv文件,如下图
阅读原文即可直达该爬虫的 Github 地址。
评论