
简述分布式追踪和可观察性

在当前的分布式微服务架构中,一个网页中的简单请求可能在十几个不同的微服务之间跳转,因此观察或追踪数据请求在应用和网络之间的路径就显得非常有价值了。
客户端服务端示例
我们可以从一个简单客户端服务端模型的应用中来了解追踪,比如说,我们有一个简单的 Web 服务器应用程序,它在端点 /hello 处接收一个请求,然后将一个静态的字符串文本 "hello" 发送回客户端。
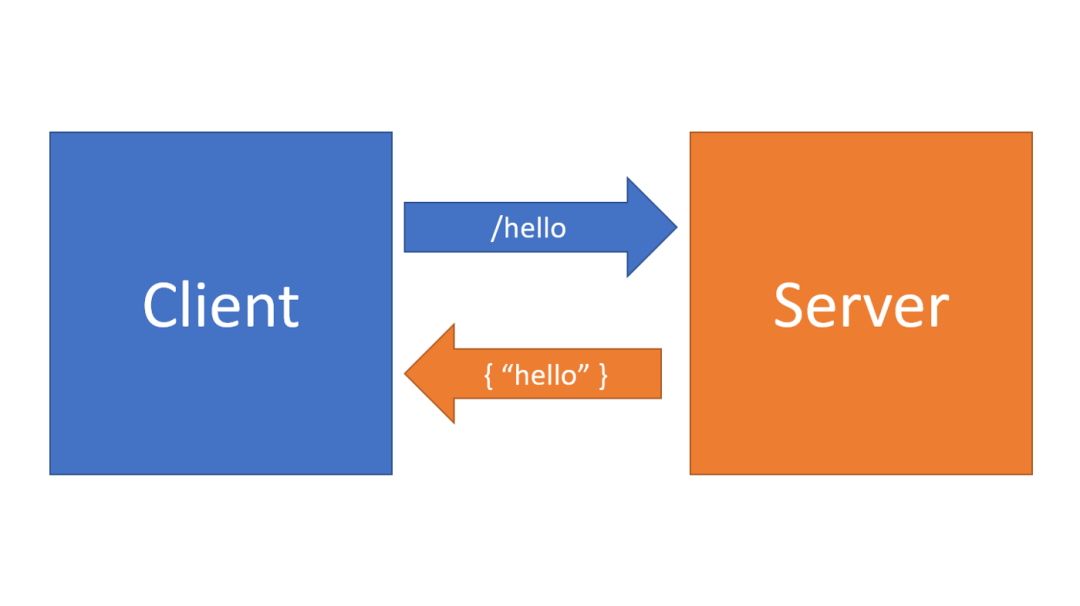
从客户端的角度来说,他们发送一个请求,等待一些时间(自己和服务器之间的网络以及服务器处理请求的时间)接收到响应。在服务器内部,只有一个返回响应数据的动作发生。在一个应用程序的上下文中,我们可以将这整个事务可视化为一个 "span",并具有一个开始和结束时间,以及有关所执行操作类型的一些详细信息或 "tag"。
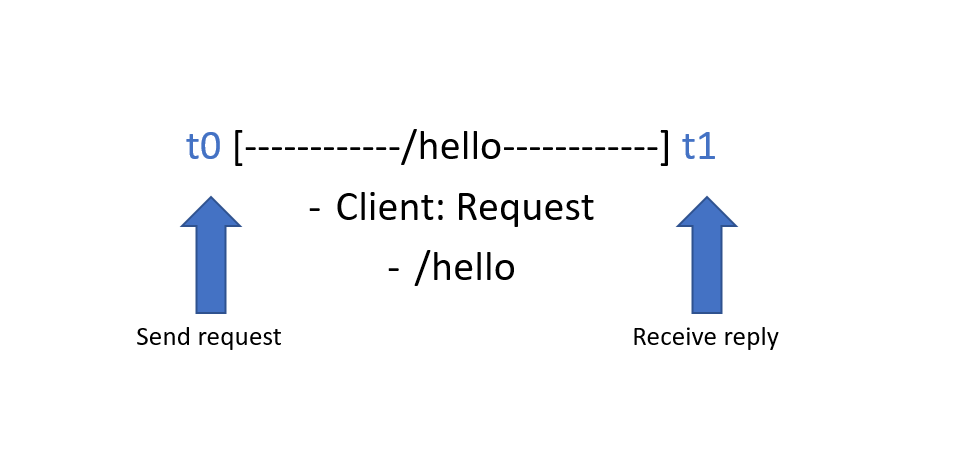
现在客户端知道了请求和响应的相关信息,包括发送了什么数据、什么时候发送的、什么时候收到的以及收到的什么数据,当然服务器也知道一些类似的信息。但是有一个问题是如果我们没有手动关联两个应用程序之间的这些事件,就没有一个简单的方法将它们链接在一起并获得有关交互的追踪信息。
追踪请求
为了创建这两个应用程序之间交互的完整场景,我们需要一个外部的"观察者"来收集有关客户端和服务器交互的信息。然后,这个观察者可以从整体上来查看应用之间的交互信息。
在这个例子中,假设客户端和服务器知道这个观察者,并且每次发送或接收数据时都会上报,他们会将交互中的每个相关事件和下面的信息告诉观察者:
它们是谁
它们在与谁交互
它们是否在发送或接收数据
它们正在发送或接收什么数据
该事件发生的时间点
这个交互过程可以用下图进行说明:
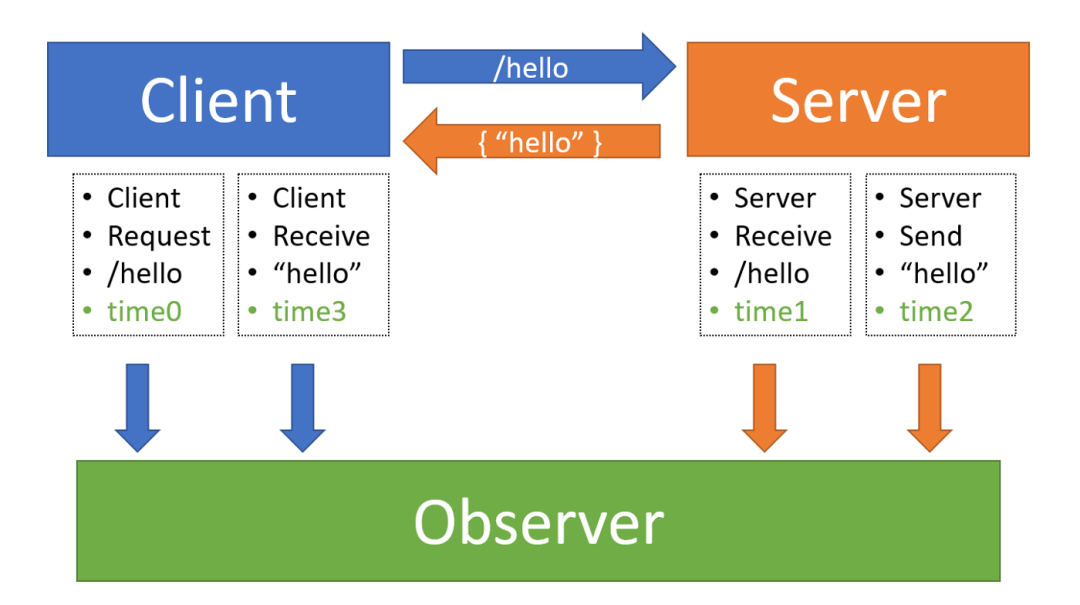
下面是这个观察者记录的相关动作:
客户端在 time0 向服务器发送一个
/hello请求
服务器在 time1 收到来自客户端的
/hello请求
服务器处理请求,并在 time2 时向客户端回复了 "hello"
客户端在 time3 接收到了服务器发来的 "hello"
观察者现在能够将这种双方交互的事件对应为一组连续的信息,我们可以从这两个系统之间的简单整合中获得一些有用信息:
什么地方发生的延迟最多?也许是在客户端和服务器之间的网络,也许是服务器的处理时间延迟最大。
如果请求失败了,它是否曾经到过服务器,或者是在它和客户端之间的链接中丢失了?
客户端在 time0 向服务器发送一个
/hello请求
服务器在 time1 收到来自客户端的
/hello请求
服务在 time1a 对来自客户端的请求进行解析
服务器运行
buildResponse()函数,在 time1b 向请求者提供相应的响应
服务器在 time2 时向客户端发出 "hello" 的响应
客户端在 time3 接收到服务器发来的 "hello"
现在我们可以更深入地了解某些进程在服务器上所花费的时间了,甚至确切地了解哪个进程在交互过程中可能已经失败了。
Spans 和 Traces
让我们以上面观察者记录的数据为例,再添加两个信息:
一个应用程序在每次报告事件时都会产生的 Span ID
一个 Trace ID,如果每个应用程序收到的数据中包含这个 ID,则会将其传递给它,如果没有,将生成一个新的 ID 并上报
如果应用程序将这些元数据附加到他们要发送给观察者的事件上,那么现在观察者记录的数据会是这样的:
客户端在 time0 向服务器发送一个
/hello请求(TraceID: hellorequest1, SpanID: 1)
服务器在 time1 接收到来自客户端的 /hello 请求(TraceID: hellorequest1, SpanID: 2)
2.1 服务器在 time1a 处解析来自客户端的请求(TraceID: hellorequest1, SpanID: 3)
2.2 服务器运行buildResponse()函数,在 time1b 向请求者提供相应的响应(TraceID: hellorequest1, SpanID: 4)
服务器在 time2 时向客户端回复 "hello"(TraceID: hellorequest1, SpanID: 5)
客户端在 time3 收到服务器发来的 "hello"(TraceID: hellorequest1, SpanID: 6)
观察者现在就可以使用 Trace ID 来将这一系列的事件归纳到一起,并使用 Span ID 将其分成独立的呃部分。
由于这样做可能会使组件的流程图变得杂乱无章,因此可以将这些信息总结为一系列时间上的 spans。注意客户端上处理响应的函数被省略了,但你可以推测出这些函数的 spans 可能是什么样的:

"hellorequest1" 这个 TraceID 涵盖了它下面所有的 spans,并将其发生的事件的追踪信息进行逻辑分组,如客户端发送请求、服务器接收请求、服务器处理后将响应发回客户端。
客户端在发起交互时,会生成一个 TraceID。然后如果存在 TraceID,交互中的每一个参与者都知道要把它传递出去,每个参与者也知道每次数据从上一个逻辑上下文或操作转移到下一个逻辑上下文或操作时,都会生成一个新的 SpanID。每个事件都会和这些 ID 一起报告给观察者,这样一来,每个完整的事务都可以在逻辑上进行分组,但一旦在观察者那里聚合起来,也可以被分解成独立的部分。
追踪多个应用
现在我们将上面的示例扩展为4个应用程序。假设交互仍然从我们的客户端开始,但这次要向服务器发送一个 /readinfo 的请求。服务器自己无法处理这个请求,所以它向另外两个应用程序各发送一个请求,我们称他们为 SecurityService 和 InfoService。当服务器收到一个 /readinfo 请求时,首先要询问 SecurityService 服务,请求者是否有正确的权限来读取这个信息,如果成功的话,它就会调用 InfoService 来读取信息,最后把信息发送给请求者。
我们把这个交互过程绘制出来,可以标注操作发生的顺序,然后我们可以推断出观察者记录的一系列事件。
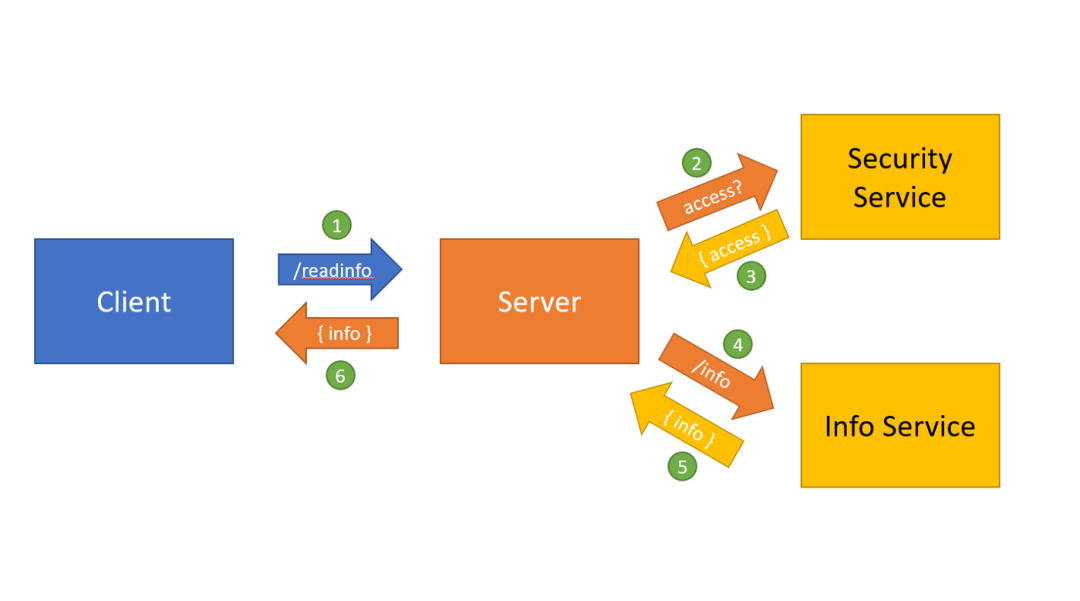
上图是观察者根据每个应用发给它的事件记录的内容,所有的事件都被列出来了,图中的数字与列表中的数字相匹配,为了节省篇幅,我省略了时间戳和 ID:
客户端向服务器发送 /readinfo 请求 - 服务器收到一个 /readinfo 请求
服务器向 SecurityService 发送一个 /access 请求 - SecurityService 收到一个 /access 请求
SecurityService 对 /access 请求做出响应 - 服务器收到来自 SecurityService 的 /access 响应
服务器向 InfoService 发送一个 /info 请求 - InfoService 收到一个 /info 请求
InfoService 响应 /info 请求 - 服务器收到来自 InfoService 的 /info 请求
服务器响应客户端的 /readinfo 请求 - 客户端收到 /readinfo 的响应
我们可以看到只是增加了两个应用,被记录的事件数量就增加了不少,我们可以将同样的事件列表可视化为 spans,以便更好地查看 /readinfo 请求的执行路径:

注意,所有的事件仍然被归纳为同一个 TraceID,但我们可以看到每个独立的服务之间传递请求的 span,并共同处理最终结果到客户端。
我们可以通过包括每个应用程序中运行的函数和子程序来进一步扩展 span 的粒度。
总结
上面的概念是微服务和分布式应用的 Opentracing 规范中的术语。有许多开源库和软件实现了 Opentracing 规范,你可以将这些直接集成到自己的应用程序中,以获得对微服务交互的强大观察。
一旦你的应用程序可以通过 Opentracing 进行通信,你仍然需要一个观察者来记录所有从应用程序发出的事件。有很多系统都能实现 Opentracing 规范,比如 Zipkin 就是这些流行的分布式追踪系统的一个,可以自行安装使用。它在我们的例子中扮演的就是观察者的角色,并从遵守 Opentracing 标准的应用程序中获取追踪数据,以提供应用程序追踪的交互式可视化。
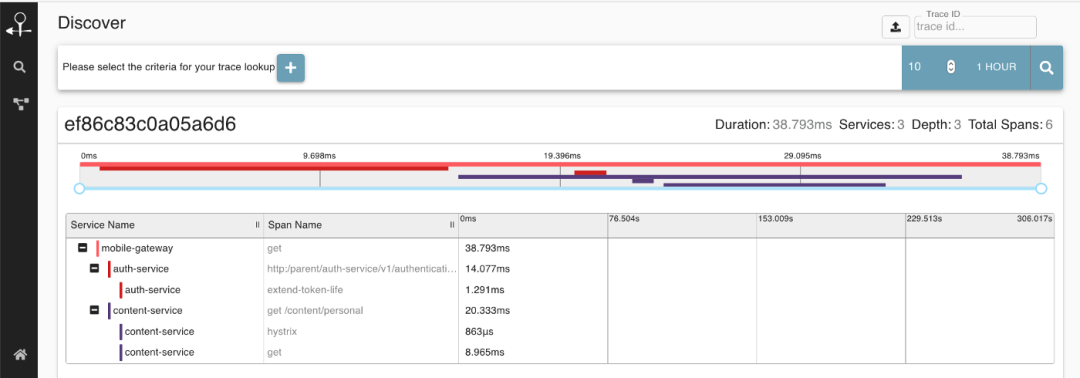
如果你想了解更多关于 Opentracing 的信息,可以查看官网,有对应的规范文档和使用指南。你也可以尝试使用 Zipkin,它的库支持几乎所有的编程语言。
原文链接
https://medium.com/swlh/tracing-and-observability-9ab98438d773
https://opentracing.io/specification/
https://zipkin.io/