
号称下一代监控系统,来看看它有多强!
点击上方“码农突围”,马上关注
这里是码农充电第一站,回复“666”,获取一份专属大礼包 真爱,请设置“星标”或点个“在看

一、Prometheus 概述
A multi-dimensional data model, so that data can be sliced and diced at will, along dimensions like instance, service, endpoint, and method. Operational simplicity, so that you can spin up a monitoring server where and when you want, even on your local workstation, without setting up a distributed storage backend or reconfiguring the world. Scalable data collection and decentralized architecture, so that you can reliably monitor the many instances of your services, and independent teams can set up independent monitoring servers. Finally, a powerful query language that leverages the data model for meaningful alerting (including easy silencing) and graphing (for dashboards and for ad-hoc exploration).
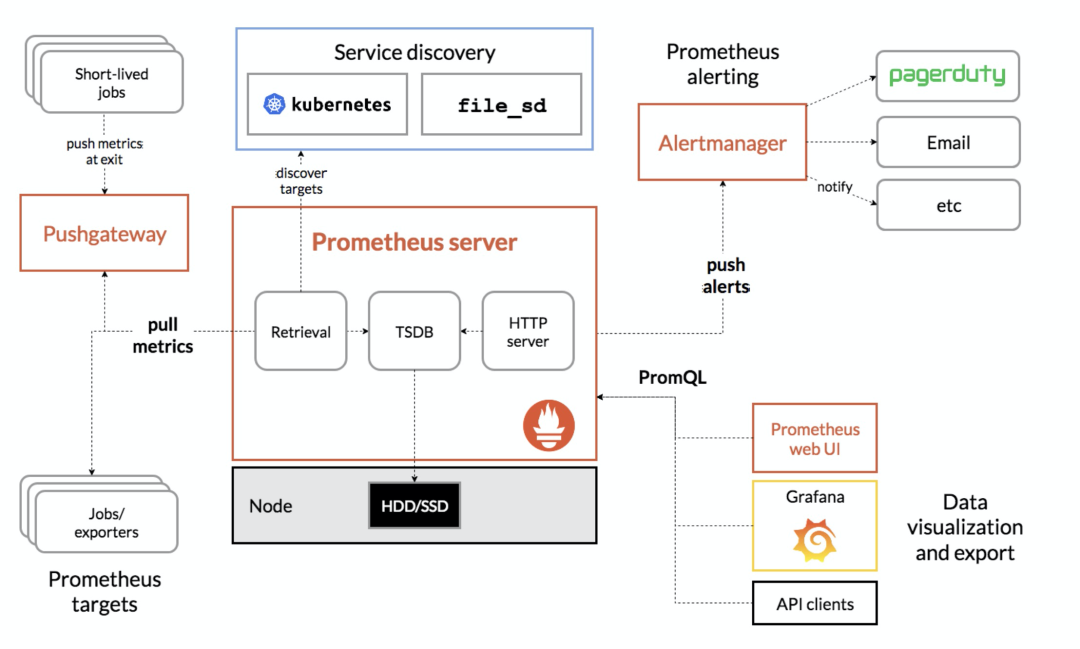
二、安装 Prometheus server
2.1 开箱即用
$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz
$ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
$ cd prometheus-2.4.3.linux-amd64
$ ./prometheus --version
prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449)
build user: root@1e42b46043e9
build date: 20181004-08:42:02
go version: go1.11.1
$ ./prometheus --config.file=prometheus.yml
2.2 使用 Docker 镜像
$ sudo docker run -d -p 9090:9090 prom/prometheus
$ sudo docker run -d -p 9090:9090 \
-v ~/docker/prometheus/:/etc/prometheus/ \
prom/prometheus
~/docker/prometheus/prometheus.yml,这样可以方便编辑和查看,通过 -v 参数将本地的配置文件挂载到 /etc/prometheus/ 位置,这是 prometheus 在容器中默认加载的配置文件位置。-v 参数的命令,然后通过 docker inspect 命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):$ sudo docker inspect 0c
[...]
"Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46",
"Created": "2018-10-15T22:27:34.56050369Z",
"Path": "/bin/prometheus",
"Args": [
"--config.file=/etc/prometheus/prometheus.yml",
"--storage.tsdb.path=/prometheus",
"--web.console.libraries=/usr/share/prometheus/console_libraries",
"--web.console.templates=/usr/share/prometheus/consoles"
],
[...]
2.3 配置 Prometheus
--config.file 来指定,配置文件格式为 YAML。我们可以打开默认的配置文件 prometheus.yml 看下里面的内容:/etc/prometheus $ cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
global 块:Prometheus 的全局配置,比如 scrape_interval表示 Prometheus 多久抓取一次数据,evaluation_interval表示多久检测一次告警规则;alerting 块:关于 Alertmanager 的配置,这个我们后面再看; rule_files 块:告警规则,这个我们后面再看; scrape_config 块:这里定义了 Prometheus 要抓取的目标,我们可以看到默认已经配置了一个名称为
prometheus的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问http://localhost:9090/metrics查看 Prometheus 暴露了哪些指标;
三、学习 PromQL
http://localhost:9090/ 即可,它默认会跳转到 Graph 页面:promhttp_metric_handler_requests_total,这个指标表示 /metrics 页面的访问次数,Prometheus 就是通过这个页面来抓取自身的监控数据的。在 Console 标签中查询结果如下:scrape_interval 参数是 15s,也就是说 Prometheus 每 15s 访问一次 /metrics 页面,所以我们过 15s 刷新下页面,可以看到指标值会自增。在 Graph 标签中可以看得更明显: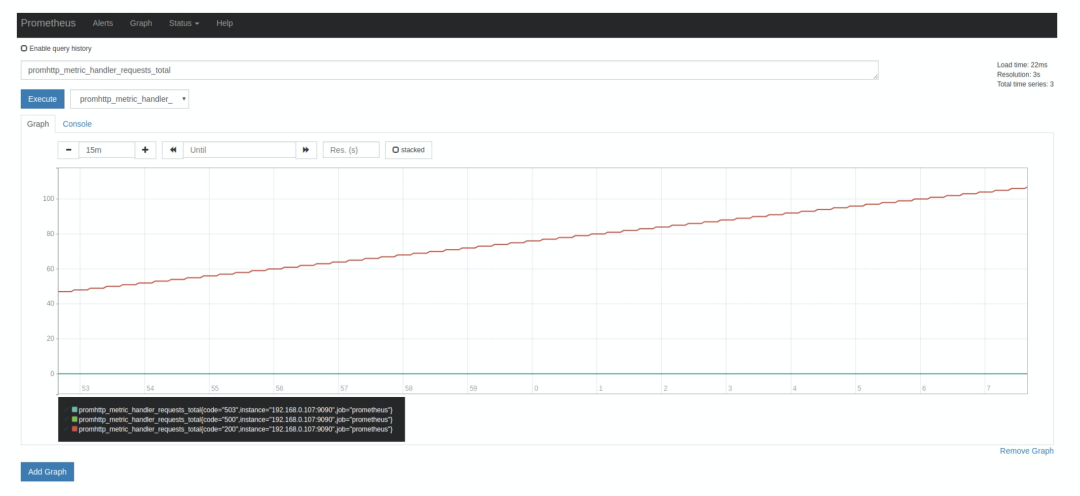
promhttp_metric_handler_requests_total{code="200",instance="192.168.0.107:9090",job="prometheus"} 106
promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。Counter Gauge Histogram Summary
3.2 PromQL 入门
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查
up
up{instance="192.168.0.107:9090",job="prometheus"} 1
up{instance="192.168.0.108:9090",job="prometheus"} 1
up{instance="192.168.0.107:9100",job="server"} 1
up{instance="192.168.0.108:9104",job="mysql"} 0
up{job="prometheus"}
= 号,还可以使用 !=、=~、!~,比如下面这样:up{job!="prometheus"}
up{job=~"server|mysql"}
up{job=~"192\.168\.0\.107.+"}
=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。http_requests_total[5m]
Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。# 计算的是每秒的平均值,适用于变化很慢的 counter
# per-second average rate of increase, for slow-moving counters
rate(http_requests_total[5m])
# 计算的是每秒瞬时增加速率,适用于变化很快的 counter
# per-second instant rate of increase, for volatile and fast-moving counters
irate(http_requests_total[5m])
count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。3.3 HTTP API
GET /api/v1/query GET /api/v1/query_range GET /api/v1/series GET /api/v1/label/ /values GET /api/v1/targets GET /api/v1/rules GET /api/v1/alerts GET /api/v1/targets/metadata GET /api/v1/alertmanagers GET /api/v1/status/config GET /api/v1/status/flags
POST /api/v1/admin/tsdb/snapshot POST /api/v1/admin/tsdb/delete_series POST /api/v1/admin/tsdb/clean_tombstones
四、安装 Grafana
$ docker run -d -p 3000:3000 grafana/grafana
http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。Name: prometheus Type: Prometheus URL: http://localhost:9090 Access: Browser
/api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。
五、使用 Exporter 收集指标
5.1 收集服务器指标
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz
$ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz
$ cd node_exporter-0.16.0.linux-amd64
$ ./node_exporter
/metrics 接口看看是否能正常获取服务器指标:$ curl http://localhost:9100/metrics
scrape_configs 中:scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.0.107:9090']
- job_name: 'server'
static_configs:
- targets: ['192.168.0.107:9100']
HUP 信号也可以让 Prometheus 重新加载配置:$ killall -HUP prometheus
node_load1 观察服务器负载:node exporter,有很多的面板模板可以直接使用,譬如:Node Exporter Server Metrics 或者 Node Exporter Full 等。我们打开 Grafana 的 Import dashboard 页面,输入面板的 URL(https://grafana.com/dashboards/405)或者 ID(405)即可。注意事项
docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter \
--path.rootfs /host
5.2 收集 MySQL 指标
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz
$ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz
$ cd mysqld_exporter-0.11.0.linux-amd64/
DATA_SOURCE_NAME,这被称为 DSN(数据源名称),它必须符合 DSN 的格式,一个典型的 DSN 格式像这样:user:password@(host:port)/。$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/'
$ ./mysqld_exporter
~/.my.cnf,或者通过 --config.my-cnf 参数指定:$ ./mysqld_exporter --config.my-cnf=".my.cnf"
$ cat .my.cnf
[client]
host=localhost
port=3306
user=root
password=123456
注意事项
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
5.3 收集 Nginx 指标
/status/format/json 接口来将 vts 的数据格式转换为 Prometheus 的格式。/status/format/prometheus,这个接口可以直接返回 Prometheus 的格式,从这点这也能看出 Prometheus 的影响力,估计 Nginx VTS exporter 很快就要退役了(TODO:待验证)。nginx_exporter 通过抓取 Nginx 自带的统计页面 /nginx_status 可以获取一些比较简单的指标(需要开启 ngx_http_stub_status_module 模块);nginx_request_exporter 通过 syslog 协议 收集并分析 Nginx 的 access log 来统计 HTTP 请求相关的一些指标;nginx-prometheus-shiny-exporter 和 nginx_request_exporter 类似,也是使用 syslog 协议来收集 access log,不过它是使用 Crystal 语言 写的。还有 vovolie/lua-nginx-prometheus 基于 Openresty、Prometheus、Consul、Grafana 实现了针对域名和 Endpoint 级别的流量统计。5.4 收集 JMX 指标
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
-javaagent 参数来加载:$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jar
config.yml 是 JMX Exporter 的配置文件,它的内容可以 参考 JMX Exporter 的配置说明 。$ curl http://localhost:9404/metrics
六、告警和通知
6.1 配置告警规则
global、alerting、rule_files、scrape_config,其中 rule_files 块就是告警规则的配置项,alerting 块用于配置 Alertmanager,这个我们下一节再看。现在,先让我们在 rule_files 块中添加一个告警规则文件:rule_files:
- "alert.rules"
alert.rules:groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
InstanceDown 和 APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。http://localhost:9090/rules 可以看到刚刚配置的规则: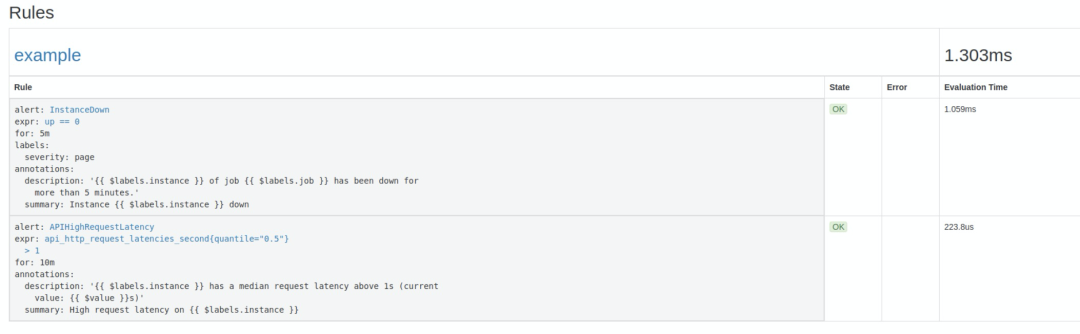
http://localhost:9090/alerts 可以看到根据配置的规则生成的告警: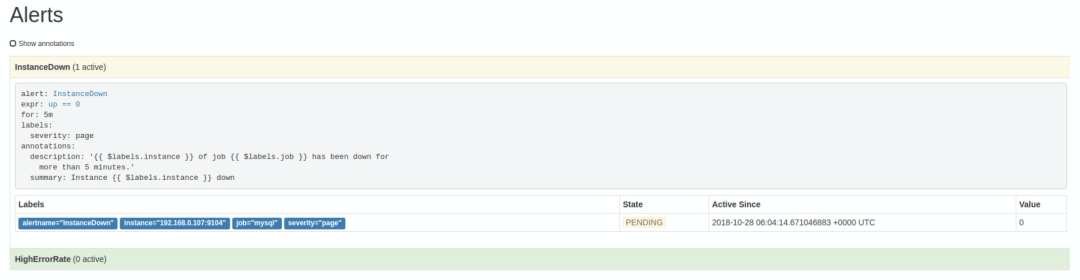
PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的 for 参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了 FIRING。6.2 使用 Alertmanager 发送告警通知
/alerts 页面可以看到所有的告警,但是还差最后一步:触发告警时自动发送通知。这是由 Alertmanager 来完成的,我们首先 下载并安装 Alertmanager,和其他 Prometheus 的组件一样,Alertmanager 也是开箱即用的:$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz
$ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz
$ cd alertmanager-0.15.2.linux-amd64
$ ./alertmanager
http://localhost:9093/ 来访问,但是现在还看不到告警,因为我们还没有把 Alertmanager 配置到 Prometheus 中,我们回到 Prometheus 的配置文件 prometheus.yml,添加下面几行:alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "192.168.0.107:9093"
http://192.168.0.107:9093。也可以使用命名行的方式指定 Alertmanager:$ ./prometheus -alertmanager.url=http://192.168.0.107:9093
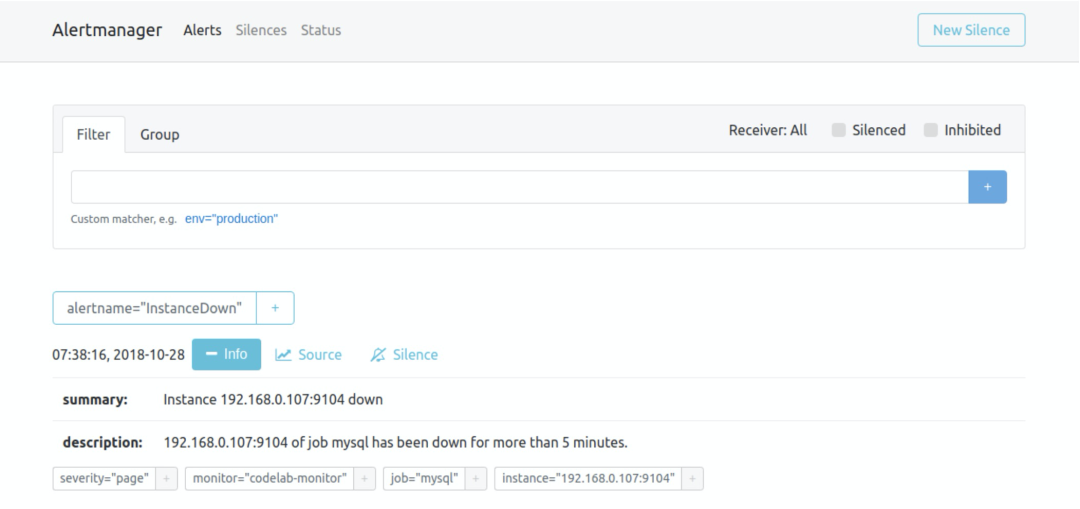
alertmanager.ym:global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
routes:
- receiver: 'database-pager'
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager'
group_by: [product, environment]
match:
team: frontend
email_config hipchat_config pagerduty_config pushover_config slack_config opsgenie_config victorops_config wechat_configs webhook_config
email_config 和 webhook_config,另外 wechat_configs 可以支持使用微信来告警,也是相当符合国情的了。七、学习更多
7.1 服务发现
7.2 告警配置管理
7.3 使用 Pushgateway
总结
附录:什么是时序数据库?
增:需要频繁的进行写操作,而且是按时间排序顺序写入 删:不需要随机删除,一般情况下会直接删除一个时间区块的所有数据 改:不需要对写入的数据进行更新 查:需要支持高并发的读操作,读操作是按时间顺序升序或降序读,数据量非常大,缓存不起作用
InfluxDB:https://influxdata.com/ Kdb+:http://kx.com/ Graphite:http://graphiteapp.org/ RRDtool:http://oss.oetiker.ch/rrdtool/ OpenTSDB:http://opentsdb.net/ Prometheus:https://prometheus.io/ Druid:http://druid.io/
参考
- END - 最近热文
• 院士拿布袋领奖归来,朋友圈刷屏了 • 32岁清华女教授获奖百万走红后回应:人生第一次因颜值受到关注 • 杭州程序员从互联网跳央企,晒一天工作和收入,网友:待一年就废 • 字节跳动P0级事故:实习生删除GB以下所有模型,差点没上头条......
评论