
网易游戏基于 Flink 的流式 ETL 建设
业务背景
专用 ETL
EntryX 通用 ETL
调优实践
未来规划
一. 业务背景
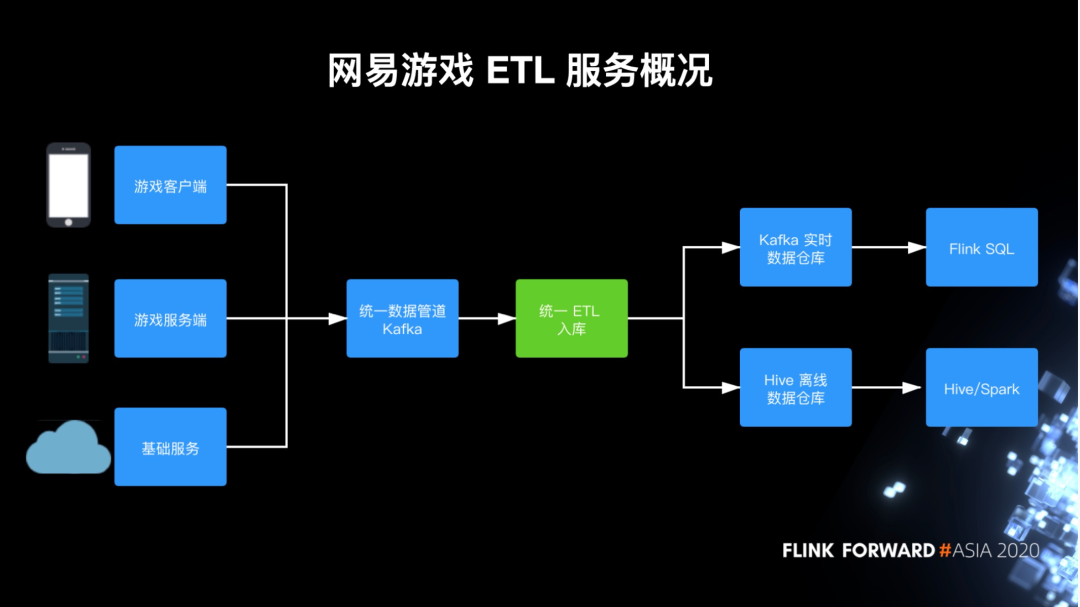
网易游戏流式 ETL 需求特点

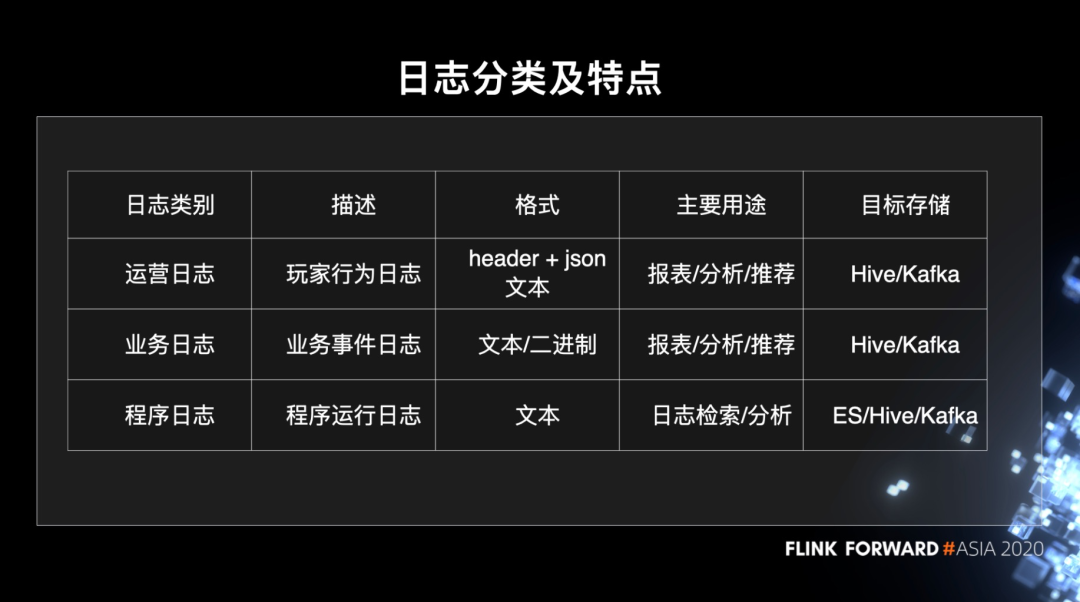
日志分类及特点
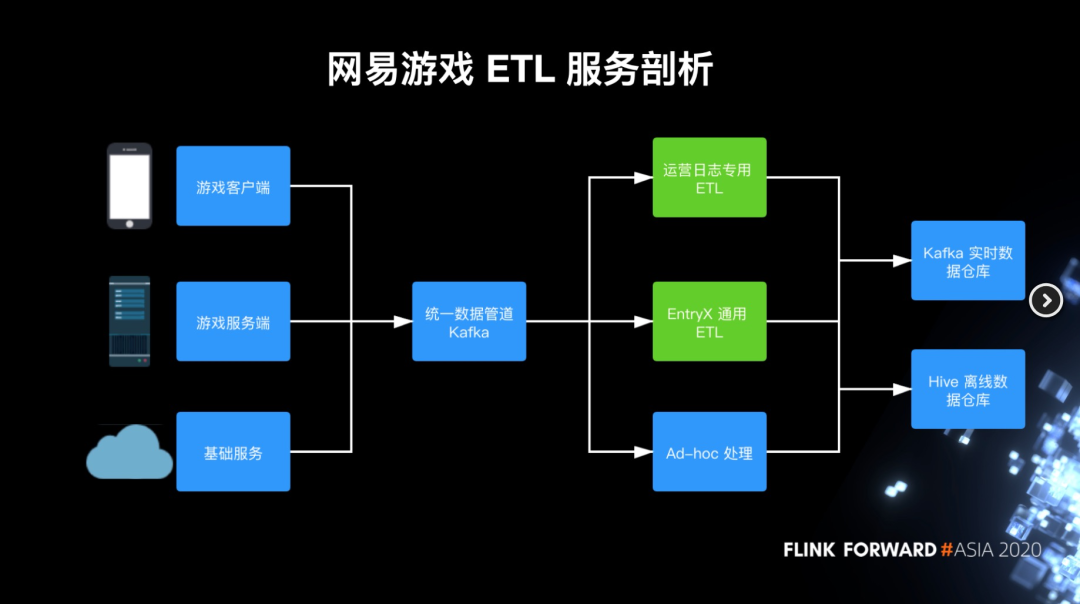
网易游戏 ETL 服务剖析
二. 运营日志专用 ETL
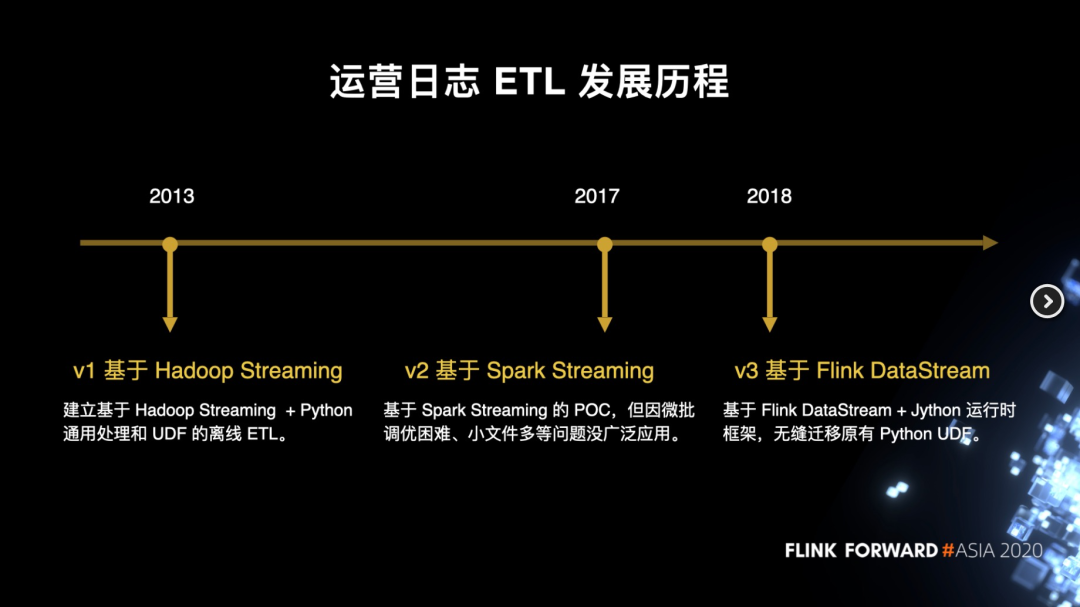
运营日志 ETL 发展历程
运营日志 ETL 架构
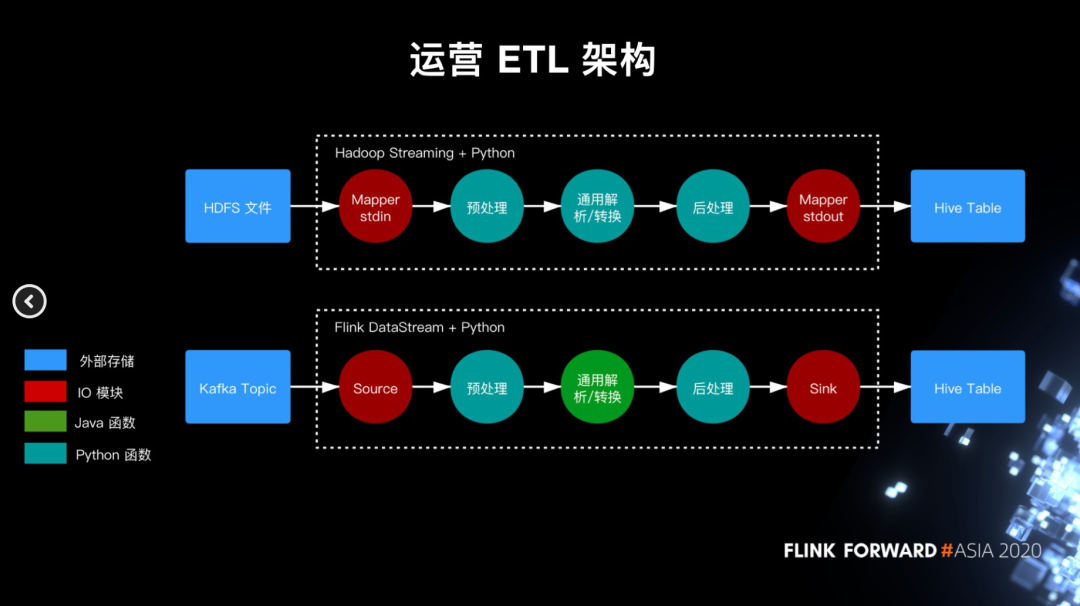
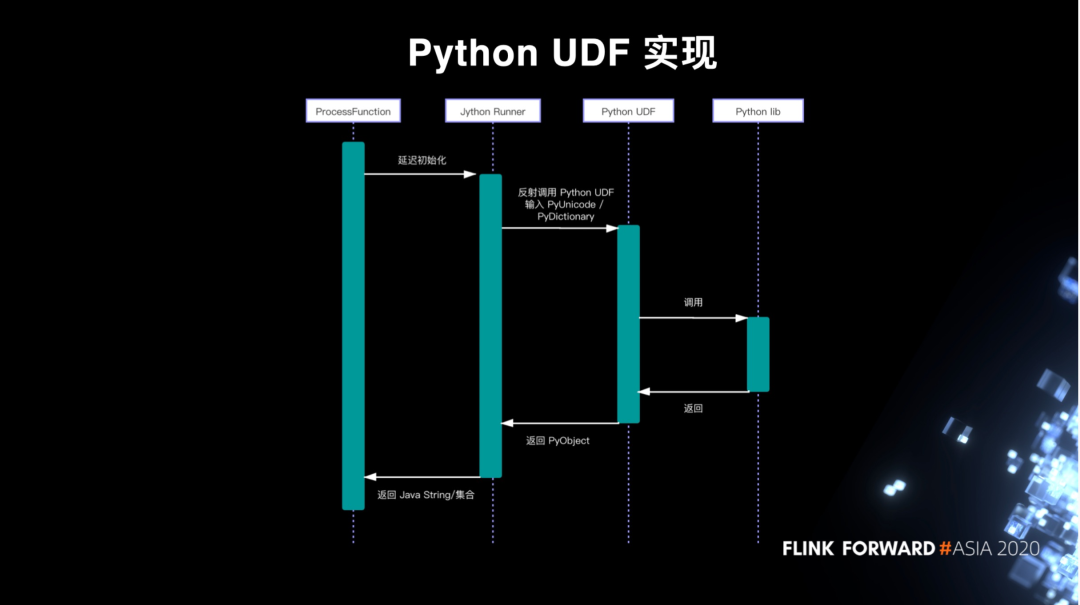
Python UDF 实现
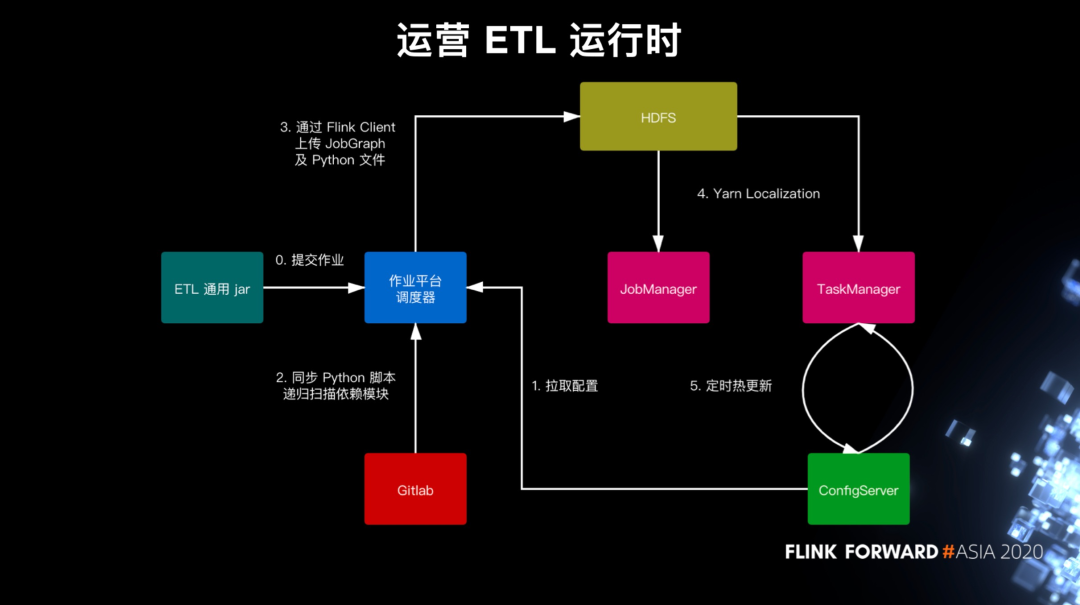
运营日志 ETL 运行时
三. EntryX 通用 ETL
EntryX 基本概念

先介绍 EntryX 的三个基本概念,Source、StreamingTable 和 Sink。用户需要分别配置这个三个模块,系统会根据这些自动生成 ETL 作业。
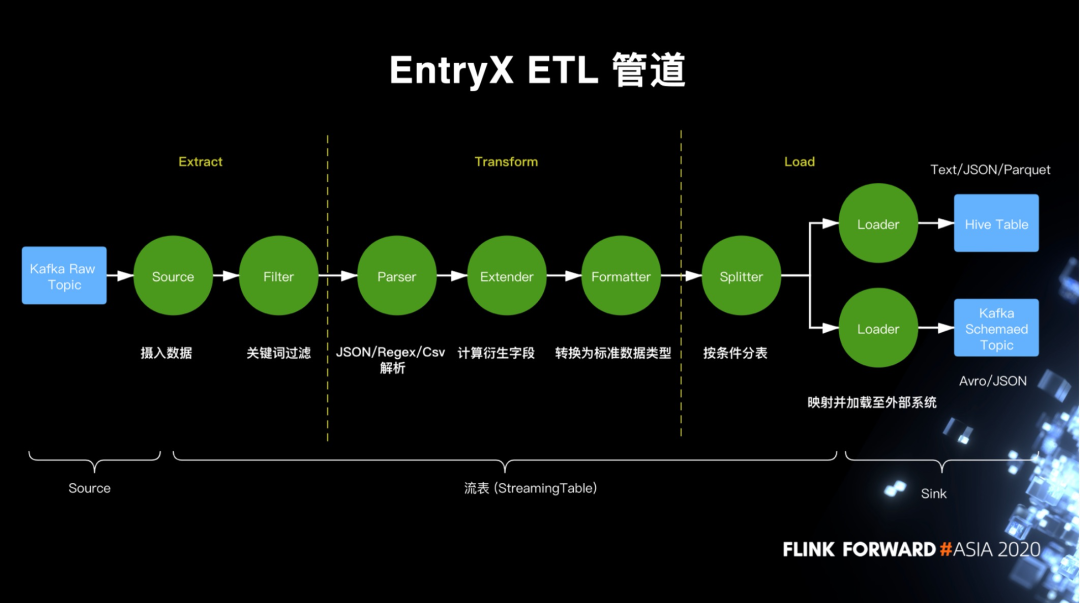
EntryX ETL 管道
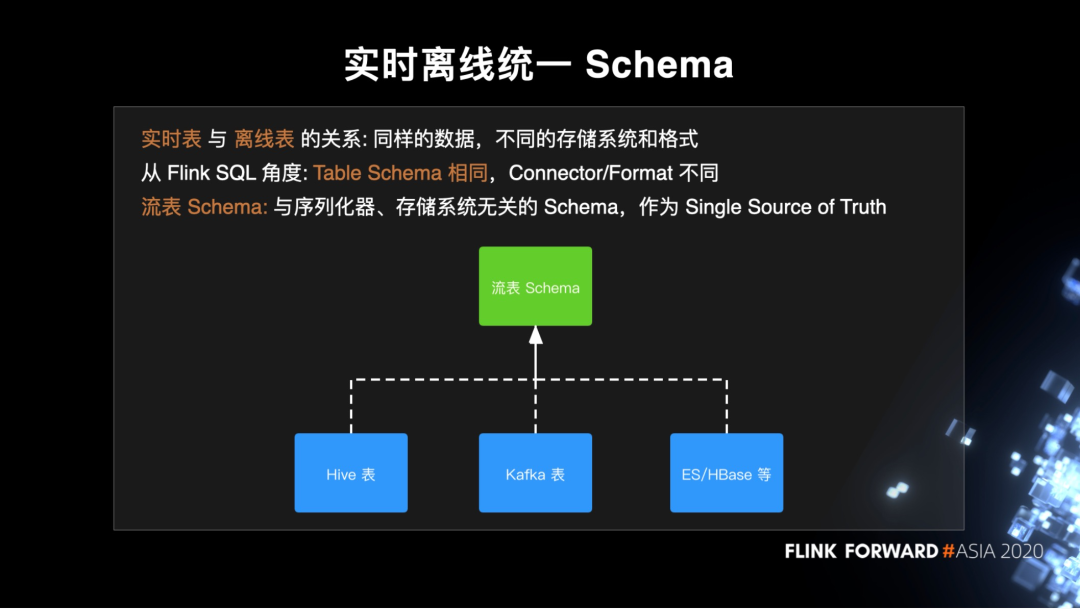
实时离线统一 Schema
实时数据仓库集成
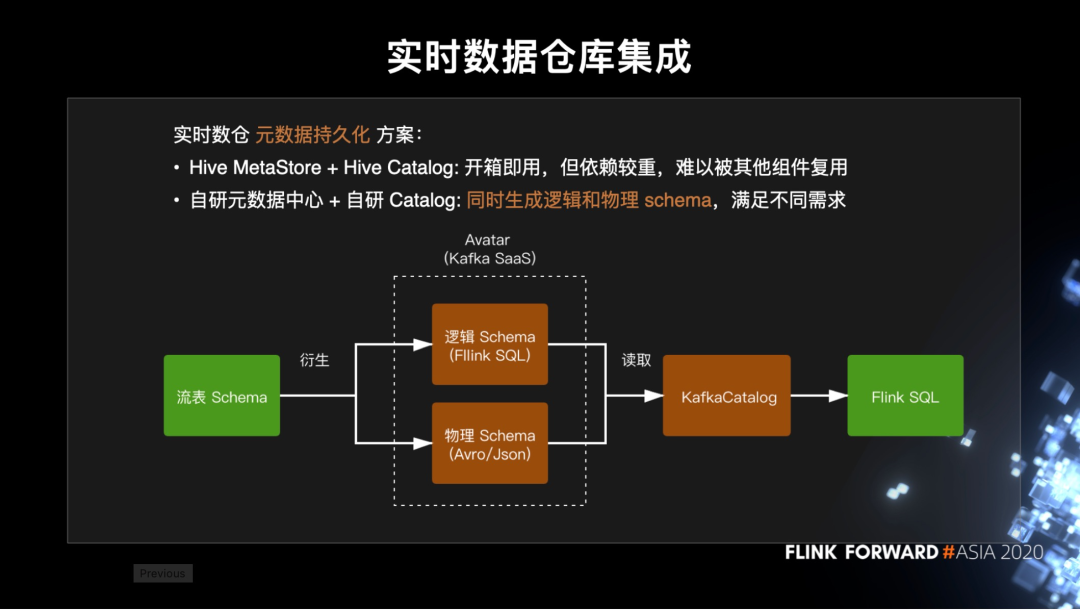
EntryX 一个重要的定位是作为实时仓库的统一入口。刚刚其实已经多次提到 Kafka 表,但还没有说实时数仓是怎么做的。实时数仓的常见问题是 Kafka 并没有原生支持 schema 元数据的持久化。目前社区的主流解决方案是基于 Hive MetaStore 来保存 Kafka 表的元数据,并复用 HiveCatalog 来直接对接到 Flink SQL。
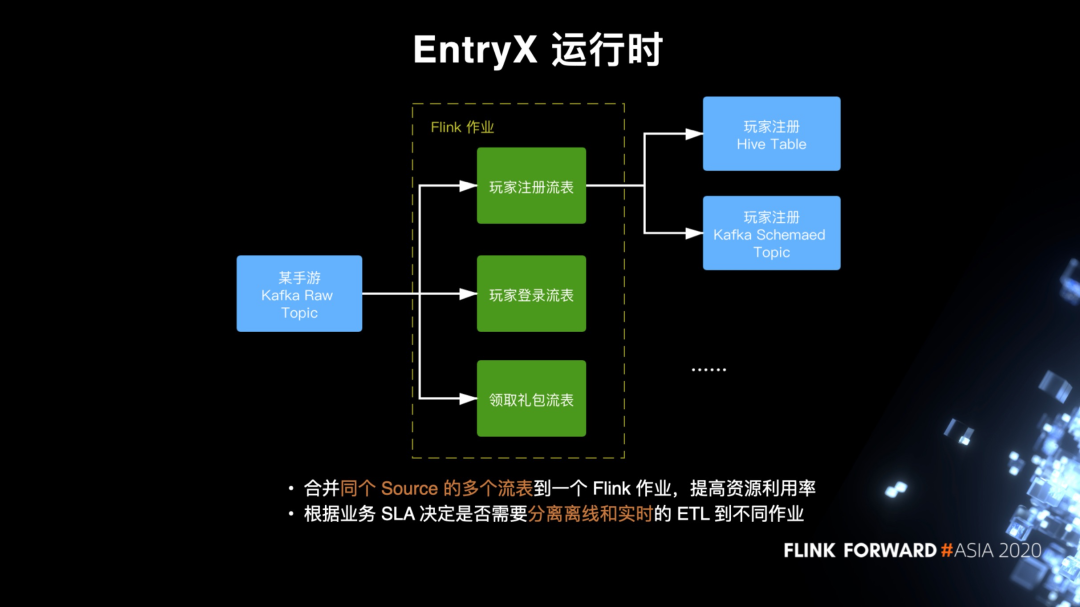
EntryX 运行时
四.调优实践
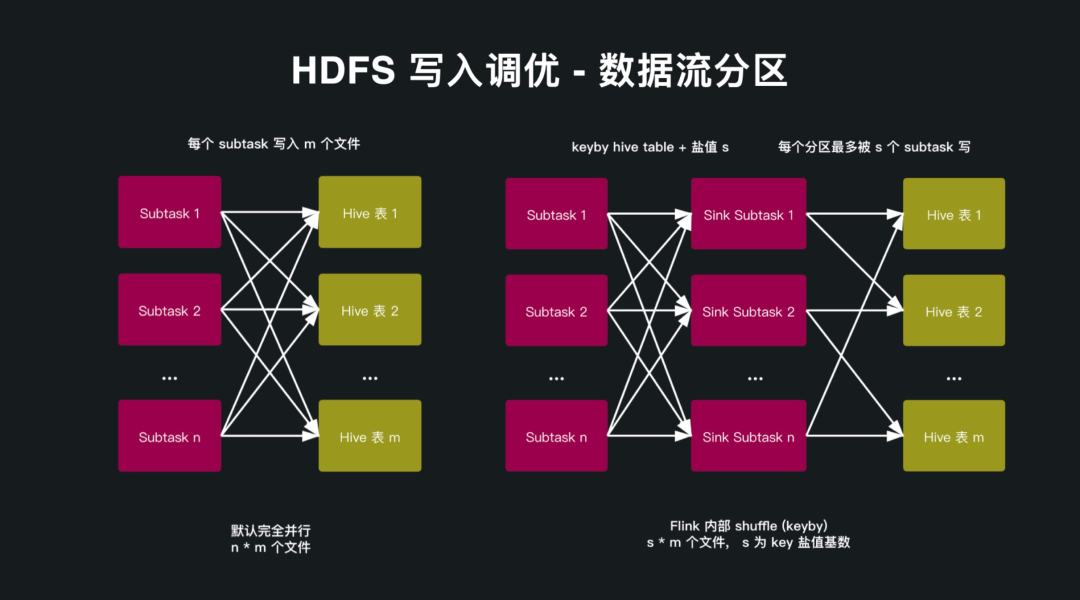
HDFS 写入调优

HDFS 写入调优 - 数据流预分区
基于 OperatorState 的 SLA 统计

第二个我想分享的是我们的 SLA 统计工具。背景是我们的用户经常会通过 Web UI 来进行调试和问题的排查,比如不同 subtask 的输入输出数目,但这些 metric 会因为作业重启或者 failover 而重置,因此我们开发了基于 OperatorState 的 SLA-Utils 工具来统计数据的输入和分类输出。这个工具设计得非常轻量级,可以很容易集成到我们自己的服务或者用户的作业里面。
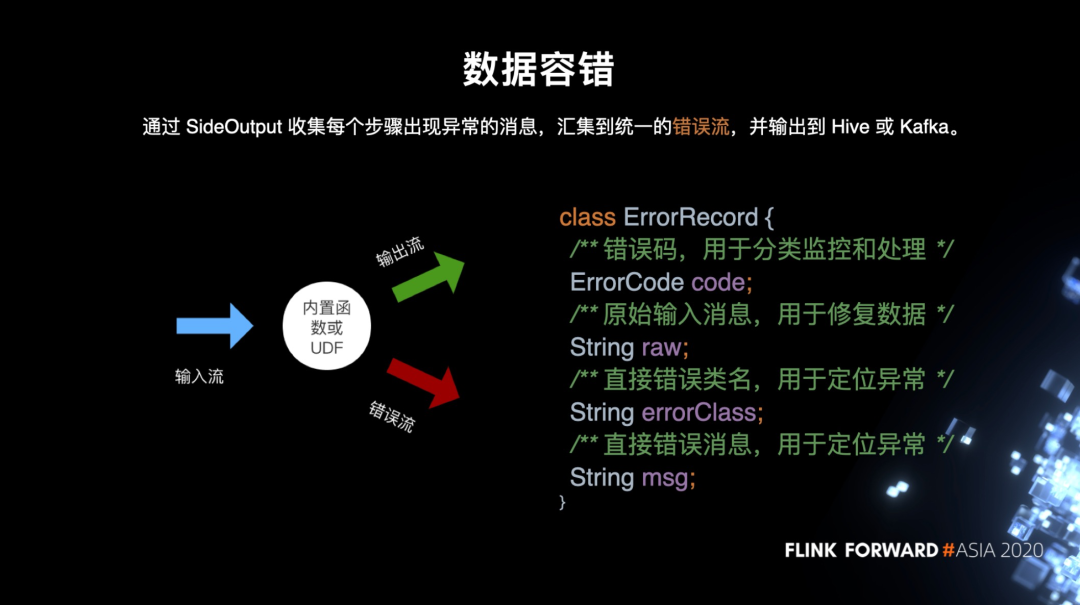
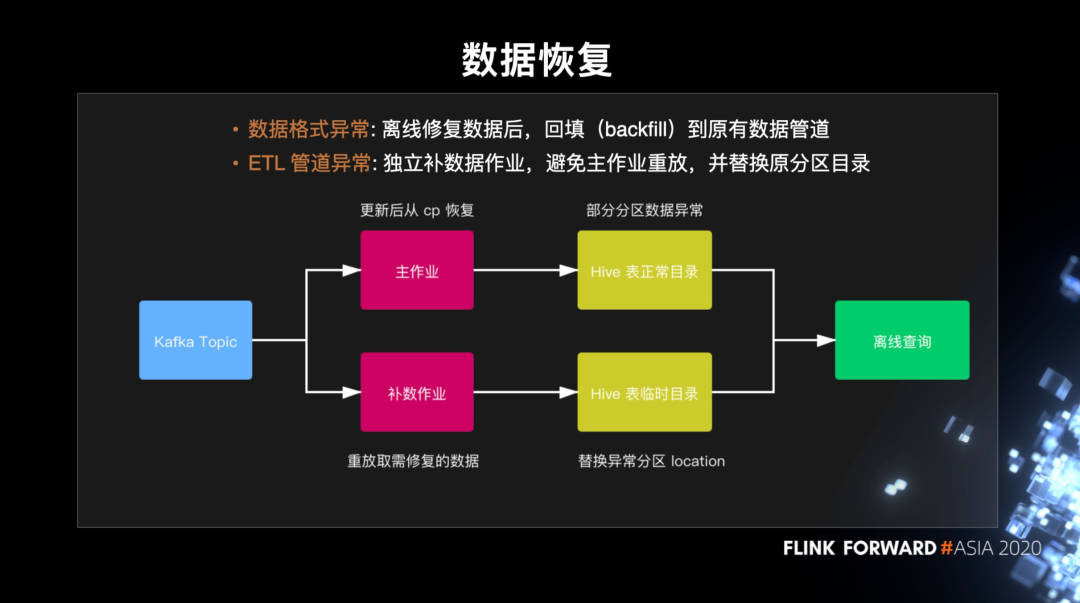
数据容错及恢复
五.未来规划

第一个是数据湖的支持。目前我们的日志绝大多数都是 append 类型,不过随着 CDC 和 Flink SQL 业务的完善,我们可能会有更多的 update、delete 的需求,因此数据湖是一个很好的选择。
第二个会提供更加丰富的附加功能,比如实时的数据去重和小文件的自动合并。这两个都是对业务方非常实用的功能。
最后是一个支持 PyFlink。目前我们的 Python 支持只覆盖到数据集成阶段,后续数据仓库的 Python 支持我们是希望通过 PyFlink 来实现。
评论