
使用Mask-RCNN在实例分割应用中克服过拟合
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自AI公园
作者:Kayo Yin
编译:ronghuaiyang
只使用1349张图像训练Mask-RCNN,有代码。
代码:https://github.com/kayoyin/tiny-inst-segmentation

介绍
计算机视觉的进步带来了许多有前途的应用,如自动驾驶汽车或医疗诊断。在这些任务中,我们依靠机器的能力来识别物体。
我们经常看到的与目标识别相关的任务有4个:分类和定位、目标检测、语义分割和实例分割。
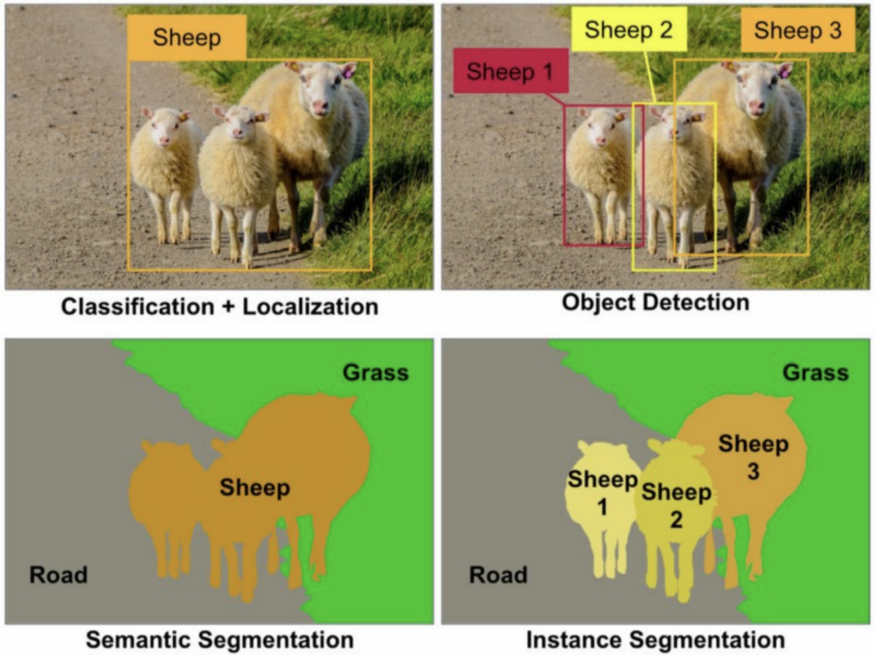
在分类和定位中,我们感兴趣的是为图像中目标的分配类标签,并在目标周围绘制一个包围框。在这个任务中,要检测的目标数量是固定的。
物体检测不同于分类和定位,因为这里我们没有预先假设图像中物体的数量。我们从一组固定的目标类别开始,我们的目标是分配类标签,并在每次这些类别中的一个目标出现在图像中时绘制边界框。
在语义分割中,我们为每个图像像素分配一个类标签:所有属于草的像素被标记为“grass”,属于羊的像素被标记为“sheep”。值得注意的是,例如,这个任务不会对两只羊产生区别。
我们的任务是实例分割,它建立在目标检测和语义分割之上。在目标检测中,我们的目标是在预定义的类别中标记和定位目标的所有实例。但是,我们没有为检测到的目标生成边界框,而是进一步识别哪些像素属于该目标,就像语义分割一样。与语义分割不同的是,实例分割为每个目标实例绘制一个单独的掩码,而语义分割将为同一类的所有实例使用相同的掩码。
在本文中,我们将在一个很小的Pascal VOC数据集上训练一个实例分割模型,其中只有1349张图像用于训练,100张图像用于测试。这里的主要挑战是在不使用外部数据的情况下防止模型过拟合。
数据处理
标注采用COCO格式,因此我们可以使用pycocotools中的函数来检索类标签和掩码。在这个数据集中,共有20个类别。

下面是一些训练图像和相关mask的可视化显示。mask的不同阴影表示同一目标类别的多个实例的不同掩码。

图像的大小和长宽比各不相同,因此在将图像输入模型之前,我们调整每个图像的尺寸500x500。当图像尺寸小于500时,我们对图像进行优化,使最大边的长度为500,并添加必要的零以获得正方形图像。

为了使模型能够很好地泛化,特别是在这样一个有限的数据集上,数据增强是克服过拟合的关键。对于每一个图像,以0.5的概率水平翻转,以0.9到1倍的尺度进行随机剪裁,以0.5的概率进行高斯模糊,标准差为随机,对比度随机调整尺度为0.75和1.5之间,亮度随机调整尺度在0.8和1.2之间,以及一系列随机仿射变换如缩放、平移、旋转,剪切。
Mask-RCNN
我们使用matterport实现的Mask-RCNN进行训练。虽然结果可能会很好看,但我们不会用MS COCO的预训练权重来展示我们如何只用1349张训练图像就能得到好的结果。
Mask-RCNN是在2017年Mask-RCNN论文中提出的,是同一作者对Faster-RCNN的扩展。Faster-RCNN被广泛应用于目标检测,模型在被检测物体周围生成包围盒。Mask-RCNN进一步生成了目标的mask 。
我将在下面简要介绍模型体系结构。
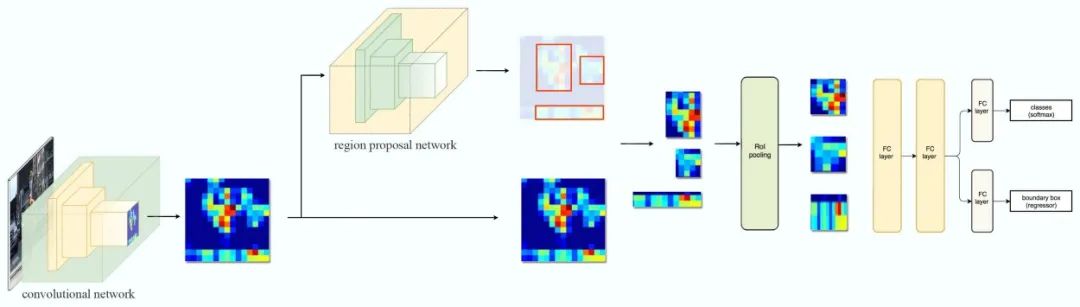
首先,我们使用一个主干模型从输入图像中提取相关的特征。在这里,我们使用ResNet101架构作为骨干。图像由张量(500,500,3)转换为特征图(32,32,2048)。
然后将之前获得的特征输入到一个区域建议网络(RPN)中。RPN扫描feature map的区域,称为anchors,并尝试确定包含目标的区域。这些anchor的尺寸和纵横比各不相同。RPN为每个anchor分配一个类别:前景(正样本anchor)或背景(负样本anchor)。中性anchor是指不影响训练的anchor。

建议层然后挑选最有可能包含目标的anchor,并优化anchor框以更接近目标。当太多anchor点重叠时,只保留前景分数最高的那个(非最大抑制)。这样,我们就得到了感兴趣的区域 (ROI)。

对于每个由ROI分类器选中的目标区域,模型生成28x28的mask。在训练过程中,将 ground truth mask缩小,用预测的mask计算损失,在推理过程中,将生成的mask放大到ROI的边界框大小。
迁移学习
特别是在数据有限的情况下,更快更好地训练模型的关键是迁移学习。Imagenet数据集是一个巨大的自然图像语料库,类似于我们的图像。因此,我们可以将Resnet101骨干模型的权值初始化为在Imagenet上预先训练的权值。这将提高我们得到的特征图的准确性,从而提高整个模型。

为了微调在Imagenet上预训练的模型,我们首先只训练model heads。然后我们在剩下的epochs中训练从ResNet level 4和以上的层。这个训练方案也有助于最小化过拟合。我们可以不去微调第一层,因为我们可以重用模型从自然图像中提取特征的权重。
结果 & 检测pipeline可视化
我们的测试集上获得的mAP为0. 53650。下面是随机选择测试图像的模型输出的一些可视化结果:

我们还可以看到算法不同步骤的输出。下面,我们有在边界框细化之前的top anchors的得分。

接下来,我们有了细化的边界框和非最大抑制后的输出。这些建议然后被输入分类网络。注意,在这里,我们有一些框框住了一些目标,比如标志,这些目标不属于我们定义的目标类别。

在建议区域上运行分类网络,得到正样本的检测,生成类概率和边界框回归。

在得到边界框并对其进行细化后,实例分割模型为每个检测到的目标生成mask。mask是soft masks(具有浮点像素值),在训练时大小为28x28。

最后,预测的mask被调整为边界框的尺寸,我们可以将它们覆盖在原始图像上以可视化最终的输出。


英文原文:https://towardsdatascience.com/overcome-overfitting-during-instance-segmentation-with-mask-rcnn-32db91f400bc

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~