
问题排查利器:Linux 原生跟踪工具 Ftrace 必知必会
TLDR:建议收藏,需要时查阅。
如果你只是需要快速使用工具来进行问题排查,包括但不限于函数调用栈跟踪、函数调用子函数流程、函数返回结果,那么推荐你直接使用 BCC trace[1] 或 Brendan Gregg[2] 封装的 perf-tools[3] 工具即可,本文尝试从手工操作 Ftrace 跟踪工具的方式展示在底层是如何通过 tracefs 实现这些能力的。如果你对某个跟踪主题感兴趣,建议直接跳转到相关的主题查看。
快速说明:
kprobe 为内核中提供的动态跟踪机制, /proc/kallsym中的函数几乎都可以用于跟踪,但是内核函数可能随着版本演进而发生变化,为非稳定的跟踪机制,数量比较多。uprobe 为用户空间提供的动态机制; tracepoint 是内核提供的静态跟踪点,为稳定的跟踪点,需要研发人员代码编写,数量有限; usdt 为用户空间提供的静态跟踪点 【本次暂不涉及】
Ftrace 是 Linux 官方提供的跟踪工具,在 Linux 2.6.27 版本中引入。Ftrace 可在不引入任何前端工具的情况下使用,让其可以适合在任何系统环境中使用。
Ftrace 可用来快速排查以下相关问题:
特定内核函数调用的频次 (function) 内核函数在被调用的过程中流程(调用栈) (function + stack) 内核函数调用的子函数流程(子调用栈)(function graph) 由于抢占导致的高延时路径等
Ftrace 跟踪工具由性能分析器(profiler)和跟踪器(tracer)两部分组成:
性能分析器,用来提供统计和直方图数据(需要 CONFIG_ FUNCTION_PROFILER=y) 函数性能分析 直方图 跟踪器,提供跟踪事件的详情: 函数跟踪(function) 跟踪点(tracepoint) kprobe uprobe 函数调用关系(function_graph) hwlat 等
除了操作原始的文件接口外,也有一些基于 Ftrace 的前端工具,比如 perf-tools 和 trace-cmd (界面 KernelShark)等。整体跟踪及前端工具架构图如下:
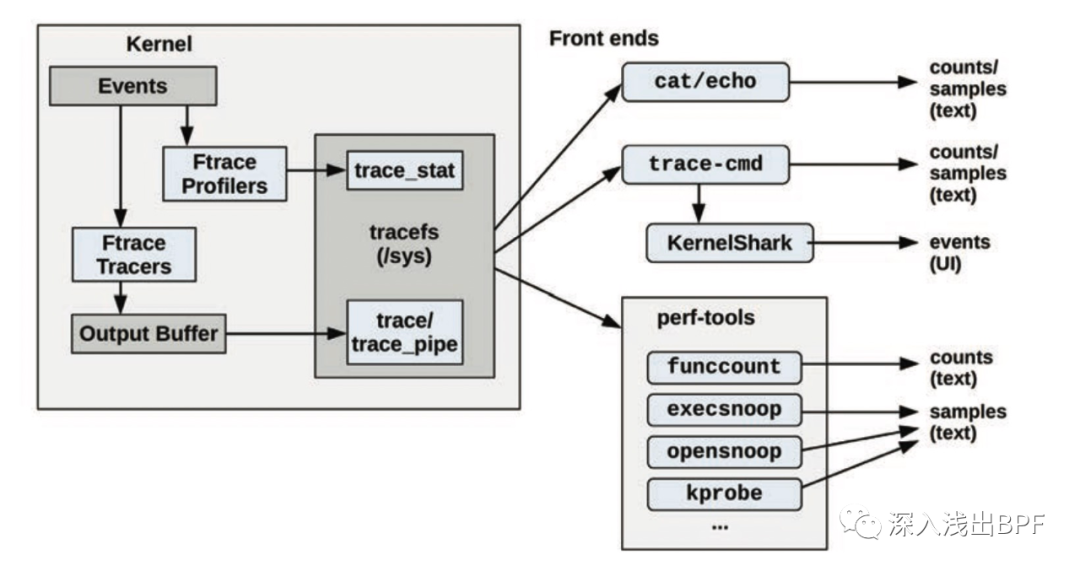
图片来自于 《Systems Performance Enterprise and the Cloud 2nd Edition》 14.1 P706
Ftrace 的使用的接口为 tracefs 文件系统,需要保证该文件系统进行加载:
$ sysctl -q kernel.ftrace_enabled=1
$ mount -t tracefs tracefs /sys/kernel/tracing
$ mount -t debugfs,tracefs
tracefs on /sys/kernel/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
debugfs on /sys/kernel/debug type debugfs (rw,nosuid,nodev,noexec,relatime)
tracefs on /sys/kernel/debug/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
$ ls -F /sys/kernel/debug/tracing # 完整目录如下图
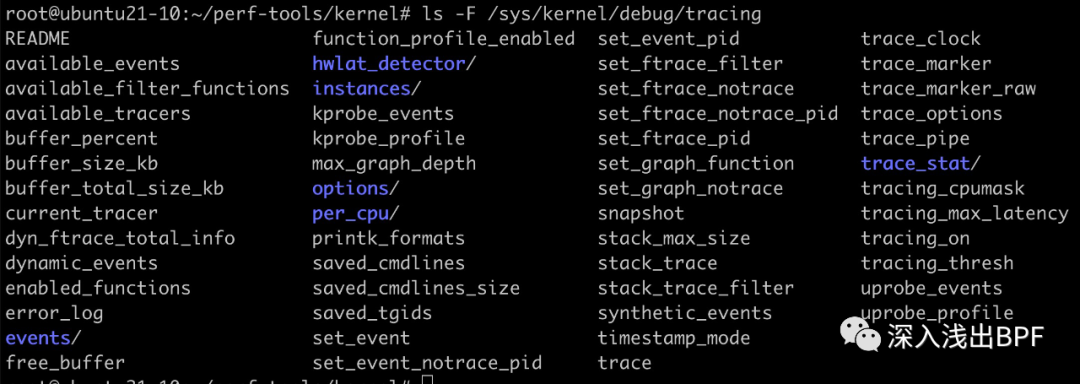
tracing 目录下核心文件介绍如下表格,当前可仅关注黑体加粗的项,其他项可在需要的时候再进行回顾:
| 文件 | 描述 |
|---|---|
| available_tracers | 可用跟踪器,hwlat blk function_graph wakeup_dl wakeup_rt wakeup function nop,nop 表示不使用跟踪器 |
| current_tracer | 当前使用的跟踪器 |
| function_profile_enabled | 启用函数性能分析器 |
| available_filter_functions | 可跟踪的完整函数列表 |
| set_ftrace_filter | 选择跟踪函数的列表,支持批量设置,例如 *tcp、tcp* 和 *tcp* 等 |
| set_ftrace_notrace | 设置不跟踪的函数列表 |
| set_event_pid | 设置跟踪的 PID,表示仅跟踪 PID 程序的函数或者其他跟踪 |
| tracing_on | 是否启用跟踪,1 启用跟踪 0 关闭跟踪 |
| trace_options | 设置跟踪的选项 |
| trace_stat(目录) | 函数性能分析的输出目录 |
| kprobe_events | 启用 kprobe 的配置 |
| uprobe_events | 启用 uprobe 的配置 |
| events ( 目录 ) | 事件(Event)跟踪器的控制文件:tracepoint、kprobe、uprobe |
| trace | 跟踪的输出 (Ring Buffer) |
| trace_pipe | 跟踪的输出;提供持续不断的数据流,适用于程序进行读取 |
perf_tools 包含了一个复位所有 ftrace 选型的工具脚本,在跟踪不符合预期的情况下,建议先使用 reset-ftrace[4] 进行复位,然后再进行测试。
1. 内核函数调用跟踪
基于 Ftrace 的内核函数调用跟踪整体架构如下所示:
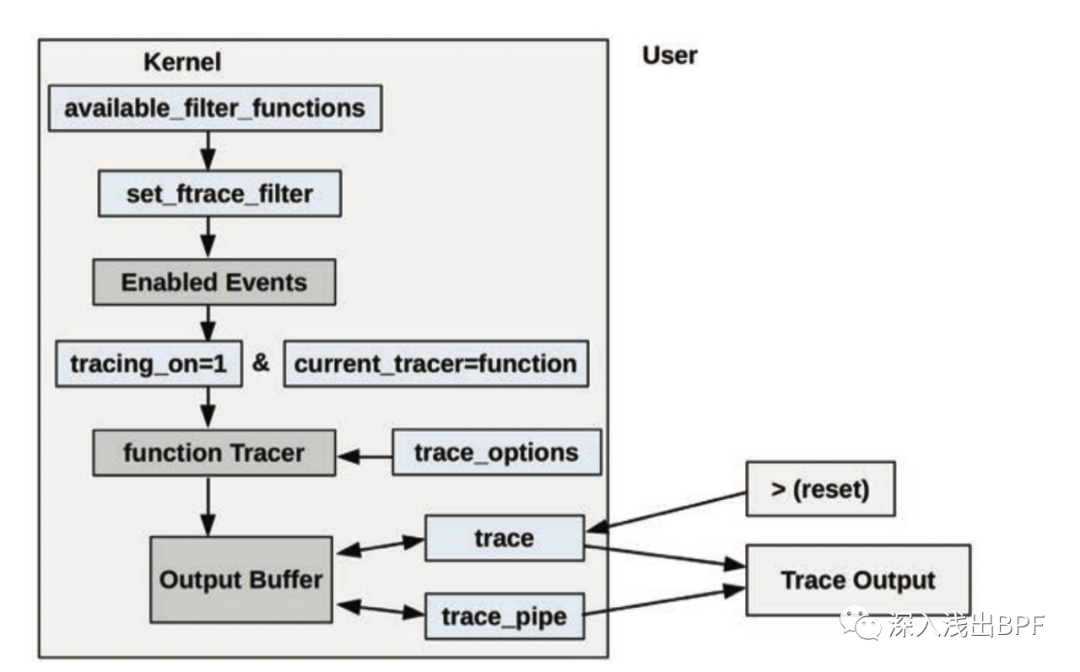
图片来自于 《Systems Performance Enterprise and the Cloud 2nd Edition》 14.4 P713
这里我们尝试对于内核中的系统调用函数 __arm64_sys_openat 进行跟踪(前面两个下划线),需要注意的是 __arm64_sys_openat 是在 arm64 结构体系下 sys_openat 系统调用的包装,如果在 x86_64 架构下则为 __x64_sys_openat() ,由于我们本地的电脑是 M1 芯片,所以演示的样例以 arm64 为主。
在不同的体系结构下,可以在 /proc/kallsym 文件中搜索确认。
后续的目录,如无特殊说明,都默认位于
/sys/kernel/debug/tracing/根目录。
# 使用 function 跟踪器,并将其设置到 current_tracer
$ sudo echo function > current_tracer
# 将跟踪函数 __arm64_sys_openat 设置到 set_ftrace_filter 文件中
$ sudo echo __arm64_sys_openat > set_ftrace_filter
# 开启全局的跟踪使能
$ sudo echo 1 > tracing_on
# 运行 ls 命令触发 sys_openat 系统调用,新的内核版本中直接调用 sys_openat
$ ls -hl
# 关闭
$ sudo echo 0 > tracing_on
$ sudo echo nop > current_tracer
# 需要主要这里的 echo 后面有一个空格,即 “echo+ 空格>"
$ sudo echo > set_ftrace_filter
# 通过 cat trace 文件进行查看
$ sudo cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 224/224 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
sudo-15099 [002] .... 29469.444400: __arm64_sys_openat <-invoke_syscall
sudo-15099 [002] .... 29469.444594: __arm64_sys_openat <-invoke_syscall
我们可以看到上述的结果表明了函数调用的任务名称、PID、CPU、标记位、时间戳及函数名字。
在 perf_tools[5] 工具集中的前端封装工具为 functrace[6] ,需要注意的是该工具默认不会设置 tracing_on 为 1, 需要在启动前进行设置,即 ”echo 1 > tracing_on“。
perf_tools[7] 工具集中 kprobe[8] 也可以实现类似的效果,底层基于 kprobe 机制实现,ftrace 机制中的 kprobe 在后续章节会详细介绍。
2. 函数被调用流程(栈)
在第 1 部分我们获得了内核函数的调用,但是有些场景我们更可能希望获取调用该内核函数的流程(即该函数是在何处被调用),这需要通过设置 options/func_stack_trace 选项实现。
$ sudo echo function > current_tracer
$ sudo echo __arm64_sys_openat > set_ftrace_filter
$ sudo echo 1 > options/func_stack_trace # 设置调用栈选项
$ sudo echo 1 > tracing_on
$ ls -hl
$ sudo echo 0 > tracing_on
$ sudo cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 292/448 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
sudo-15134 [000] .... 29626.670430: __arm64_sys_openat <-invoke_syscall
sudo-15134 [000] .... 29626.670431:
=> __arm64_sys_openat
=> invoke_syscall
=> el0_svc_common.constprop.0
=> do_el0_svc
=> el0_svc
=> el0_sync_handler
=> el0_sync
# 关闭
$ sudo echo nop > current_tracer
$ sudo echo > set_ftrace_filter
$ sudo echo 0 > options/func_stack_trace
通过上述跟踪记录,我们可以发现记录同时展示了函数调用的记录和被调用的函数流程,__arm64_sys_openat 的被调用栈如下:
=> __arm64_sys_openat
=> invoke_syscall
=> el0_svc_common.constprop.0
=> do_el0_svc
=> el0_svc
=> el0_sync_handler
=> el0_sync
perf_tools[9] 工具集中 kprobe[10] 通过添加 ”-s“ 参数实现同样的功能,运行的命令如下:
$ ./kprobe -s 'p:__arm64_sys_openat'
3. 函数调用子流程跟踪(栈)
如果想要分析内核函数调用的子流程(即本函数调用了哪些子函数,处理的流程如何),这时需要用到 function_graph 跟踪器,从字面意思就可看出这是函数调用关系跟踪。
基于 __arm64_sys_openat 子流程调用关系的跟踪的完整设置过程如下:
# 将当前 current_tracer 设置为 function_graph
$ sudo echo function_graph > current_tracer
$ sudo echo __arm64_sys_openat > set_graph_function
# 设置跟踪子函数的最大层级数
$ sudo echo 3 > max_graph_depth # 设置最大层级
$ sudo echo 1 > tracing_on
$ ls -hl
$ sudo echo 0 > tracing_on
#$ echo nop > set_graph_function
$ sudo cat trace
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
1) | __arm64_sys_openat() {
1) | do_sys_openat2() {
1) 0.875 us | getname();
1) 0.125 us | get_unused_fd_flags();
1) 2.375 us | do_filp_open();
1) 0.084 us | put_unused_fd();
1) 0.125 us | putname();
1) 4.083 us | }
1) 4.250 us | }
在本样例中 __arm64_sys_openat 函数的调用子流程仅包括 do_sys_openat2() 子函数,而 do_sys_openat2() 函数又调用了 getname()/get_unused_fd_flags() 等子函数。
这种完整的子函数调用关系,对于我们学习内核源码和分析线上的问题都提供了便利,排查问题时则可以顺藤摸瓜逐步缩小需要分析的范围。
在 perf_tools[11] 工具集的前端工具为 funcgraph[12] ,使用 funcgraph 启动命令如下所示:
$./funcgraph -m 3 __arm64_sys_openat
如果函数调用栈比较多,直接查看跟踪记录则非常不方便,基于此社区补丁 [PATCH] ftrace: Add vim script to enable folding for function_graph traces[13] 提供了一个基于 vim 的配置,可通过树状关系来折叠和展开函数调用的最终记录,vim 设置完整如下:
" Enable folding for ftrace function_graph traces.
"
" To use, :source this file while viewing a function_graph trace, or use vim's
" -S option to load from the command-line together with a trace. You can then
" use the usual vim fold commands, such as "za", to open and close nested
" functions. While closed, a fold will show the total time taken for a call,
" as would normally appear on the line with the closing brace. Folded
" functions will not include finish_task_switch(), so folding should remain
" relatively sane even through a context switch.
"
" Note that this will almost certainly only work well with a
" single-CPU trace (e.g. trace-cmd report --cpu 1).
function! FunctionGraphFoldExpr(lnum)
let line = getline(a:lnum)
if line[-1:] == '{'
if line =~ 'finish_task_switch() {$'
return '>1'
endif
return 'a1'
elseif line[-1:] == '}'
return 's1'
else
return '='
endif
endfunction
function! FunctionGraphFoldText()
let s = split(getline(v:foldstart), '|', 1)
if getline(v:foldend+1) =~ 'finish_task_switch() {$'
let s[2] = ' task switch '
else
let e = split(getline(v:foldend), '|', 1)
let s[2] = e[2]
endif
return join(s, '|')
endfunction
setlocal foldexpr=FunctionGraphFoldExpr(v:lnum)
setlocal foldtext=FunctionGraphFoldText()
setlocal foldcolumn=12
setlocal foldmethod=expr
将上述指令保存为 function-graph-fold.vim 文件,在 vim 使用时通过 -S 参数指定上述配置,就可实现按照层级展示跟踪记录。在 vim 中,可通过 za 展开,zc 折叠跟踪记录。(通过文件分析,我们需要在 cat trace 文件时候重定向到文件)。
$ vim -S function-graph-fold.vim trace.log
4. 内核跟踪点(tracepoint)跟踪
可基于 ftrace 跟踪内核静态跟踪点,可跟踪的完整列表可通过 available_events 查看。events 目录下查看到各分类的子目录,详见下图:
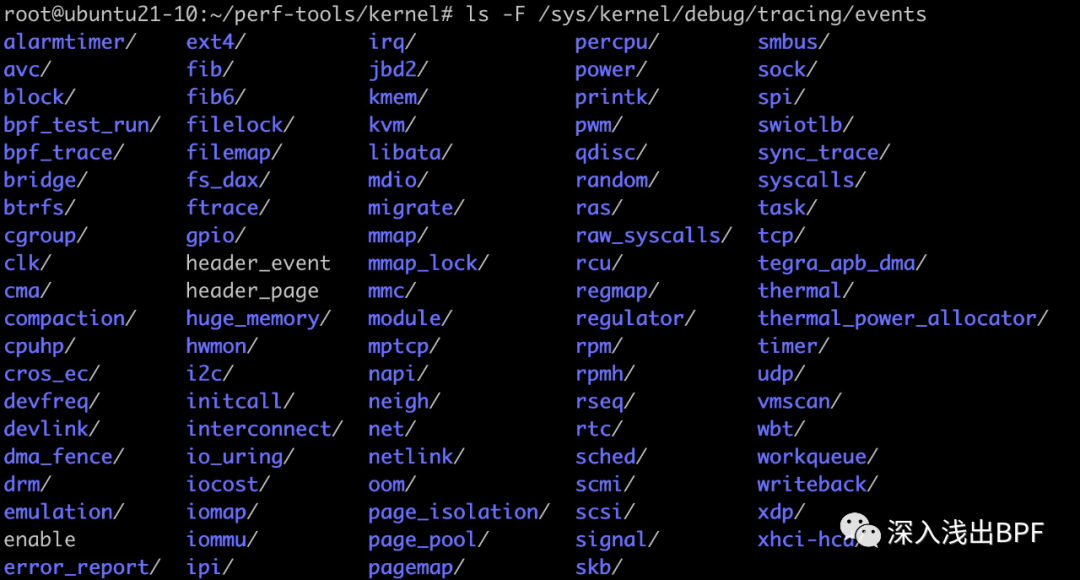
# available_events 文件中包括全部可用于跟踪的静态跟踪点
$ sudo grep openat available_events
syscalls:sys_exit_openat2
syscalls:sys_enter_openat2
syscalls:sys_exit_openat
syscalls:sys_enter_openat
# 我们可以在 events/syscalls/sys_enter_openat 中查看该跟踪点相关的选项
$ sudo ls -hl events/syscalls/sys_enter_openat
total 0
-rw-r----- 1 root root 0 Jan 1 1970 enable # 是否启用跟踪 1 启用
-rw-r----- 1 root root 0 Jan 1 1970 filter # 跟踪过滤
-r--r----- 1 root root 0 Jan 1 1970 format # 跟踪点格式
-r--r----- 1 root root 0 Jan 1 1970 hist
-r--r----- 1 root root 0 Jan 1 1970 id
--w------- 1 root root 0 Jan 1 1970 inject
-rw-r----- 1 root root 0 Jan 1 1970 trigger
$ sudo cat events/syscalls/sys_enter_openat/format
name: sys_enter_openat
ID: 555
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:int dfd; offset:16; size:8; signed:0;
field:const char * filename; offset:24; size:8; signed:0;
field:int flags; offset:32; size:8; signed:0;
field:umode_t mode; offset:40; size:8; signed:0;
print fmt: "dfd: 0x%08lx, filename: 0x%08lx, flags: 0x%08lx, mode: 0x%08lx", ((unsigned long)(REC->dfd)), ((unsigned long)(REC->filename)), ((unsigned long)(REC->flags)), ((unsigned long)(REC->mode))
这里直接使用 tracepoint 跟踪 sys_openat 系统调用,设置如下:
$ sudo echo 1 > events/syscalls/sys_enter_openat/enable
$ sudo echo 1 > tracing_on
$ sudo cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 19/19 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
cat-16961 [003] .... 47683.934082: sys_openat(dfd: ffffffffffffff9c, filename: ffff9abf20f0, flags: 80000, mode: 0)
cat-16961 [003] .... 47683.934326: sys_openat(dfd: ffffffffffffff9c, filename: ffff9ac09f20, flags: 80000, mode: 0)
cat-16961 [003] .... 47683.935468: sys_openat(dfd: ffffffffffffff9c, filename: ffff9ab75150, flags: 80000, mode: 0)
# 关闭
$ sudo echo 0 > events/syscalls/sys_enter_openat/enable
我们通过设置 sys_enter_openat/enable 开启对于 sys_enter_openat 的跟踪,trace 文件中的跟踪记录格式与 sys_enter_openat/format 中的 print 章节的格式一致。
print fmt: "dfd: 0x%08lx, filename: 0x%08lx, flags: 0x%08lx, mode: 0x%08lx" ...
Filter 跟踪记录条件过滤
关于 sys_enter_openat/filter 文件为跟踪记录的过滤条件设置,格式如下:
field operator value
其中:
field 为 sys_enter_openat/format中的字段。operator 为比较符 整数支持:==,!=,= 和 & , 字符串支持 ==,!=,~ 等,其中 ~ 支持 shell 脚本中通配符 *,?,[] 等操作。 不同的条件也支持 && 和 || 进行组合。
如需要通过 format 格式中的 mode 字段过滤:
field:umode_t mode; offset:40; size:8; signed:0;
只需要将进行如下设置即可:
$ sudo echo 'mode != 0' > events/syscalls/sys_enter_openat/filter
如果需要清除 filter,直接设置为 0 即可:
$ sudo echo 0 > events/syscalls/sys_enter_openat/filter
5. kprobe 跟踪
kprobe 为内核提供的动态跟踪机制。与第 1 节介绍的函数跟踪类似,但是 kprobe 机制允许我们跟踪函数任意位置,还可用于获取函数参数与结果返回值。使用 kprobe 机制跟踪函数须是 available_filter_functions 列表中的子集。
kprobe 设置文件和相关文件如下所示,其中部分文件为设置 kprobe 跟踪函数后,Ftrace 自动创建:
kprobe_events设置 kprobe 跟踪的事件属性;
完整的设置格式如下,其中 GRP 用户可以直接定义,如果不设定默认为
kprobes:p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS] # 设置 probe 探测点
r[:[GRP/]EVENT] [MOD:]SYM[+0] [FETCHARGS] # 函数地址的返回跟踪
-:[GRP/]EVENT # 删除跟踪kprobes// /enabled 设置后动态生成,用于控制是否启用该内核函数的跟踪;
kprobes// /filter 设置后动态生成,kprobe 函数跟踪过滤器,与上述的跟踪点 fliter 类似;
kprobes// /format 设置后动态生成,kprobe 事件显示格式;
kprobe_profilekprobe 事件统计性能数据;
Kprobe 跟踪过程可以指定函数参数的显示格式,这里我们先给出 sys_openat 函数原型:
SYSCALL_DEFINE4(openat, int, dfd, const char __user *, filename, int, flags,
umode_t, mode);
跟踪函数入口参数
这里仍然以 __arm64_sys_openat 函数为例,演示使用 kpboe 机制进行跟踪:
# p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS]
# GRP=my_grp EVENT=arm64_sys_openat
# SYM=__arm64_sys_openat
# FETCHARGS = dfd=$arg1 flags=$arg3 mode=$arg4
$ sudo echo 'p:my_grp/arm64_sys_openat __arm64_sys_openat dfd=$arg1 flags=$arg3 mode=$arg4' >> kprobe_events
$ sudo cat events/my_grp/arm64_sys_openat/format
name: __arm64_sys_openat
ID: 1475
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:unsigned long __probe_ip; offset:8; size:8; signed:0;
print fmt: "(%lx)", REC->__probe_ip
events/my_grp/arm64_sys_openat/format
$ sudo echo 1 > events/my_grp/arm64_sys_openat/enable
# $ sudo echo 1 > options/stacktrace # 启用栈
$ cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 38/38 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
cat-17025 [002] d... 52539.651096: arm64_sys_openat: (__arm64_sys_openat+0x0/0xb4) dfd=0xffff8000141cbeb0 flags=0x1bf mode=0xffff800011141778
# 关闭,注意需要先 echo 0 > enable 停止跟踪
# 然后再使用 "-:my_grp/arm64_sys_openat" 停止,否则会正在使用或者忙的错误
$ sudo echo 0 > events/my_grp/arm64_sys_openat/enable
$ sudo echo '-:my_grp/arm64_sys_openat' >> kprobe_events
跟踪函数返回值
kprobe 可用于跟踪函数返回值,格式如下:
r[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS]
例如:
$ sudo echo 'r:my_grp/arm64_sys_openat __arm64_sys_openat ret=$retval' >> kprobe_events
变量 $retval 参数表示函数返回值,其他的使用格式与 kprobe 类似。
6. uprobe 跟踪
uprobe 为用户空间的动态跟踪机制,格式和使用方式与 kprobe 的方式类似,但是由于是用户态程序跟踪需要指定跟踪的二进制文件和偏移量。
p[:[GRP/]EVENT]] PATH:OFFSET [FETCHARGS] # 跟踪函数入口
r[:[GRP/]EVENT]] PATH:OFFSET [FETCHARGS] # 跟踪函数返回值
-:[GRP/]EVENT] # 删除跟踪点
这里以跟踪 /bin/bash 二进制文件中的 readline() 函数为例:
$ readelf -s /bin/bash | grep -w readline
920: 00000000000d6070 208 FUNC GLOBAL DEFAULT 13 readline
$ echo 'p:my_grp/readline /bin/bash:0xd6070' >> uprobe_events
$ echo 1 > events/my_grp/readline/enable
$ cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 1/1 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
bash-14951 [003] .... 54570.055093: readline: (0xaaaab3ce6070)
$ echo 0 > events/my_grp/readline/enable
$ echo '-:my_grp/readline' >> uprobe_events
uprobe 跟踪是跟踪用户态的函数,因此需要指定二进制文件+符号偏移量才能进行跟踪。不同系统中的二进制版本或者编译方式不同,会导致函数符号表的位置不同,因此需要跟踪前进行确认。
7. 总结
至此,我们完整介绍 Ftrace 的整体应用场景,也通过具体的设置,学习了使用的完整流程。
实际问题排查中,考虑到效率和易用性,推荐大家这样选择:
如果排查问题机器上支持 eBPF 技术,首选 BCC trace[14] 及相关工具; 否则推荐使用 perf-tools[15] ; 最后的招数就是使用本文 Ftrace 的完整流程了。
但目前基于 eBPF 的工具还未支持
function_graph跟踪器,特定场景下还需要 ftrace 的function_graph跟踪器的配合。
Ftrace 与 eBPF 并非是相互替代,而是相互补充协同关系,在后续的问题排查案例中我们将看到这一点。
参考
高效分析 Linux 内核源码 [16], 相关代码参见这里 [17]。 Linux kprobe 调试技术使用 [18] ftrace 在实际问题中的应用 [19] 《Systems Performance Enterprise and the Cloud 2nd Edition》
参考资料
BCC trace: https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
[2]Brendan Gregg: https://github.com/brendangregg
[3]perf-tools: https://github.com/brendangregg/perf-tools
[4]reset-ftrace: https://github.com/brendangregg/perf-tools/blob/master/tools/reset-ftrace
[5]perf_tools: https://github.com/brendangregg/perf-tools
[6]functrace: https://github.com/brendangregg/perf-tools/blob/master/kernel/functrace
[7]perf_tools: https://github.com/brendangregg/perf-tools
[8]kprobe: https://github.com/brendangregg/perf-tools/blob/master/kernel/kprobe
[9]perf_tools: https://github.com/brendangregg/perf-tools
[10]kprobe: https://github.com/brendangregg/perf-tools/blob/master/kernel/kprobe
[11]perf_tools: https://github.com/brendangregg/perf-tools
[12]funcgraph: https://github.com/brendangregg/perf-tools/blob/master/kernel/funcgraph
[13][PATCH] ftrace: Add vim script to enable folding for function_graph traces: https://lore.kernel.org/lkml/20090806145701.GB7661@feather/
[14]BCC trace: https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
[15]perf-tools: https://github.com/brendangregg/perf-tools
[16]高效分析 Linux 内核源码 : https://blog.51cto.com/u_15069487/2612548
[17]这里 : https://github.com/x-lugoo/Anytime-Note/tree/master/trace
[18]Linux kprobe 调试技术使用 : https://www.cnblogs.com/arnoldlu/p/9752061.html
[19]ftrace 在实际问题中的应用 : https://blog.csdn.net/rikeyone/article/details/95081117