
Google三驾马车到底说了什么?
前两天跟一个架构师聊天,想跟他请教一下大佬都是怎么变得如此优秀的,结果他就给我两句话,六个字。

是的,“看论文,经常看”。
大佬果然不一般,惜字如金,学习和处理问题的方式,也和“普通码农”不太一样。比如,在面对整个异常复杂的大数据生态系统时,大家不可避免地会遇到一些问题,大部分人的解决方式很简单:去群里问问前辈有没有可靠的解决方案;或在技术社区搜索答案;很少有人会想到看论文,去挖整个系统的来龙去脉。
这也能理解,毕竟说到读论文,就是一个字,难。
一是原版论文都是英文,理解起来费劲;第二,大数据相关的学习资料良莠不齐,很难靠自己梳理出一条清晰的学习路径,去深入了解并建立大数据系统的底层知识体系。
但就开头我朋友的例子来说,想成为真正的大佬,把技术研究精深,“读论文”必不可少,也是最快的学习方式。因为最核心的东西,就在其中,一旦看懂,就可以触类旁通,从使用到开发,很多细节通过脑补就可以猜个八九不离十。
就拿过去 20 年计算机工程界,发展最迅速、产生影响最大的“大数据领域”来说。首先,大数据领域的开源框架层出不穷,一开始这些开源框架也并不完善,有这样那样的不足,所以就需要我们去研究框架的源码和它的路线图,不断地去打 patch 和做优化。而要追根溯源,还是得看启发了这些开源框架的原始论文。
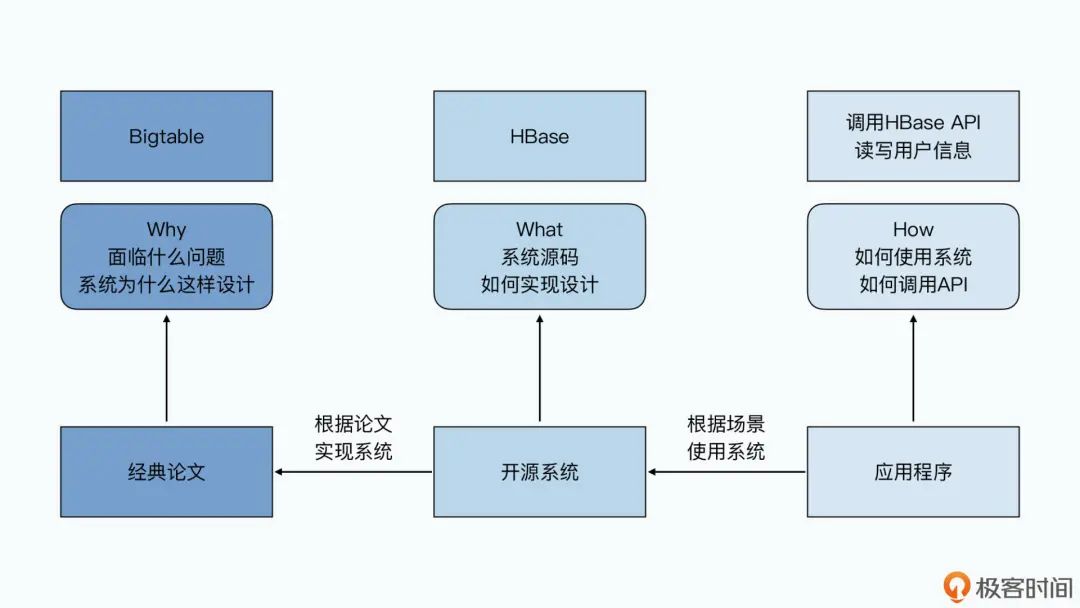
像上图所示。在大数据的世界里,会用某个开源框架,是懂了基础“招式”。看开源框架的源码,是武功“秘籍”,能让你更高效地 debug。那么,研读论文,就是真正的内功“心法”。“招式”可能每年都在更新迭代,那么心法却不仅只在今时今日有用,更能让你一辈子受益。
可能,在大部分程序员的工作中,都忙着实现业务功能。90%的工作是重复的逻辑堆砌。10%涉及到底层、架构或核心算法的东西,而实际上,正是这 10%,决定了你和顶级程序员的差距。
那么,读大数据论文有什么方法吗?
网上这类的资料并不多,很难得,最近看到一个极客时间专门做了个专栏《大数据经典论文解读》,我第一时间买来看了看。
作者是徐文浩,简单介绍下,他是 bothub.ai 创始人,一个创业的程序员,正在工业界的实战经验非常丰富。写过各种大型企业软件,从零开始搭建支撑每天百亿流量的广告算法系统,提升了十倍以上的广告收入和 ROI。
可能更出名的,是他的另一个爆款专栏《深入浅出计算机组成原理》,我 2 刷过了。只能说“太会讲了”,把底层知识讲得清晰透彻,还吸引着读者深挖下去,功力可见一斑。目前有超过 25000 人订阅,也是出于对他的认可,所以上线时,毫不犹豫就买了他的新课。
这个大数据论文课,总结来说,让你从大数据论文入手,提升问题解决能力。专栏精进了 10 余篇程序员必读的经典论文,给出一条大数据系统底层知识学习路径,还有工业级数据系统迭代方案。你不仅获得一些大数据的知识,更能从系统架构、计算机底层原理层面,获得深入而长久的成长。
我一直认为,学习是自我驱动,要学会自己“找食物”,而不是“等着喂”。现在选择就在你这了,很靠谱的老师和学习方法,推荐给你。
早鸟价+专属口令「lunwen888」
立省 ¥40,到手仅 ¥89
除了老师是工业界大牛这个点外,专栏还有其他几个比较吸引我的地方:
1、超 10 篇必读经典论文精讲
我相信大多数大数据领域的人都看过最经典的 Google 三驾马车 GFS、MapReduce 和Bigtable,这个专栏就是从这三篇经典论文开始帮你理解大数据系统面对的主要挑战,以及应对这些挑战的架构设计方法。进一步地,带你一起来看大数据系统依赖的分布式锁 Chubby、序列化和 RPC 方案 Thrift,让你能够将架构设计和计算机底层原理结合到一起,掌握好计算机科学的底层原理。
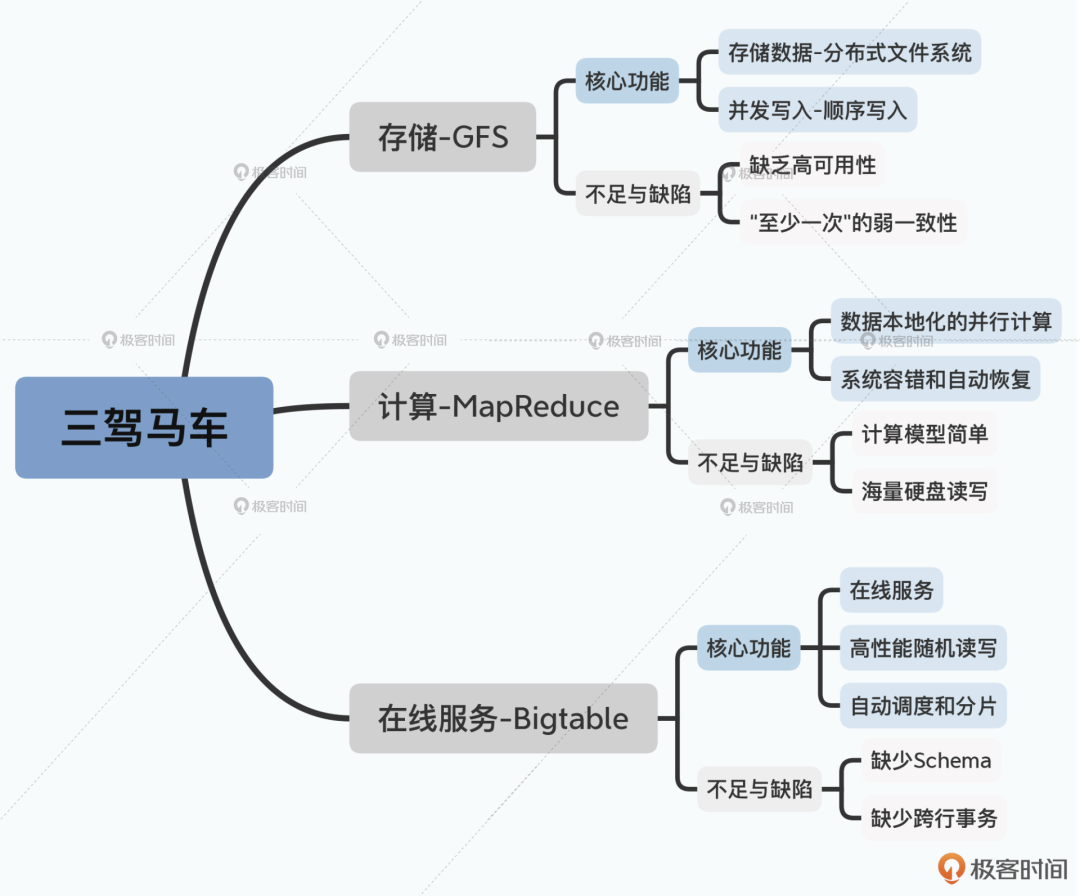
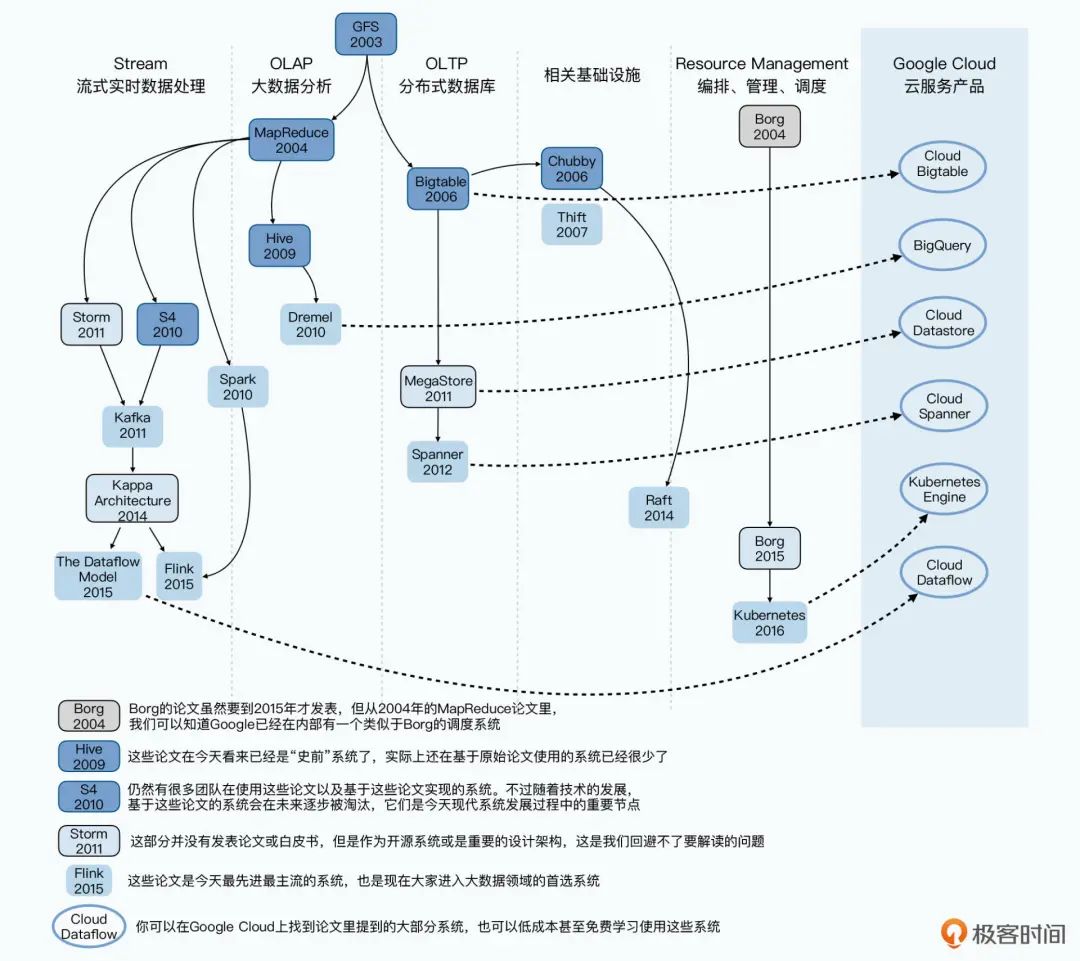
2、简化大数据论文的脉络关系
开头我就说过,我们面对的是异常复杂的大数据生态系统。而徐文浩帮大家简化过了大数据论文脉络关系,让你在对某一篇论文感到困惑的时候,可以通过脉络图翻看它前后对应的论文,找到对应问题的来龙去脉,让你大家在研读大数据论文的时候,有一个清晰的方向。
3、剖析论文核心思想
专栏一共 36 讲,手把手带你剖析论文核心思想,带大家深入体会大型系统瓶颈的完善过程,并给你真实、具体且独到的高手思路和经验观点。最终让大家能够得到的衍生性启发,举一反三的思路开拓,从而在平时工作中应用、改进和创新。
说了这么多,看看目录吧,相信它会成为一个经典专栏。

再强调一下
专栏上新优惠
早鸟 + 优惠口令「lunwen888」
立省 ¥40,到手仅 ¥89
如果你是新人,仅需 ¥59
扫码免费试读
研读论文,进行工程上的创新和突破,是每一个优秀工程师的成年礼。
点击阅读原文👇,最低 59 元拿下。