
关于 Android 渲染你应该了解的知识点
前言
谈到Android的UI绘制,大家可能会想到onMeasure、onLayout、onDraw三大流程。但我们的View到底是如何一步一步显示到屏幕上的?onDraw之后到View显示到屏幕上,具体又做了哪些工作?
带着这些问题,我们今天就深入学习一下Android渲染的流程吧,本文主包括以下内容:
Android渲染的整体架构是怎样的?Android渲染的生产者包括哪些?Skia与OpenGl的区别是什么?什么是硬件加速?硬件绘制与软件绘制的区别 Android渲染缓冲区是什么?什么是黄油计划?Android渲染的消费者是什么? 什么是SurfaceFlinger?
Android渲染整体架构
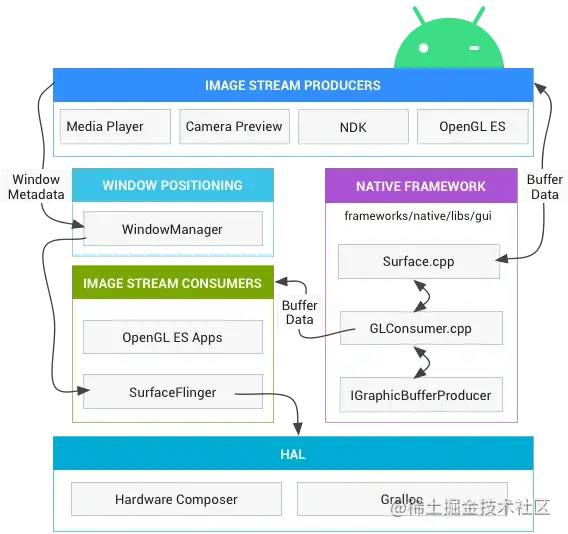
我们先来看一下Android渲染的整体架构,具体可分为以下几个部分
image stream produceers: 渲染数据的生产者,如App的draw方法会把绘制指令通过canvas传递给framework层的RenderThread线程。native Framework:RenderThread线程通过surface.dequeue得到缓冲区graphic bufer,然后在上面通过OpenGL来完成真正的渲染命令。在把缓冲区交还给BufferQueue队列中。image stream consumers:surfaceFlinger从队列中获取数据,同时和HAL完成layer的合成工作,最终交给HAL展示。HAL: 硬件抽象层。把图形数据展示到设备屏幕
可以看出,这其实是个很典型的生产者消费者模式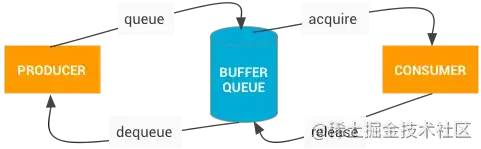
图像生产者:也就是我们的 APP,再深入点就是canvas->surface。图像消费者: SurfaceFlinger图像缓冲区: BufferQueue,一般是3缓冲区
下面我们就从生产者,消费者,缓冲区三个部分来详细了解下Android渲染的过程
图像生产者
从上面的架构图可知,图像的生产者主要有MediaPlayer,CameraPreview,NDK(Skia),OpenGl ES。
其中MediaPlayer和Camera Preview是通过直接读取图像源来生成图像数据,NDK(Skia),OpenGL ES是通过自身的绘制能力生产的图像数据
OpenGL、Vulkan、Skia的区别
OpenGL:是一种跨平台的3D图形绘制规范接口。OpenGL EL则是专门针对嵌入式设备,如手机做了优化。Skia:skia是图像渲染库,2D图形绘制自己就能完成。3D效果(依赖硬件)由OpenGL、Vulkan、Metal支持。它不仅支持2D、3D,同时支持CPU软件绘制和GPU硬件加速。Android、flutter都是使用它来完成绘制。Vulkan:Android引入了Vulkan支持。VulKan是用来替换OpenGL的。它不仅支持3D,也支持2D,同时更加轻量级
硬件加速
关于硬件加速,相信大家也经常听到,尤其是有些API不支持硬件加速,因此需要我们手动关闭,那么硬件加速到底是什么呢?
CPU 与 GPU的区别
除了屏幕,UI 渲染还要依赖另外两个核心的硬件:CPU 和 GPU。
CPU(Central Processing Unit,中央处理器),是计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元;GPU(Graphics Processin Unit,图形处理器),是一种专门用于图像运算的处理器,在计算机系统中通常被称为 "显卡"的核心部件就是GPU。
UI 组件在绘制到屏幕之前,都需要经过 Rasterization(栅格化)操作,而栅格化又是一个非常耗时的操作。
Rasterization 栅格化是绘制那些 Button、Shape、Path、String、Bitmap 等显示组件最基础的操作。栅格化将这些 UI 组件拆分到显示器的不同像素上进行显示。这是一个非常耗时的操作,GPU 的引入就是为了加快栅格化。
硬件绘制与软件绘制
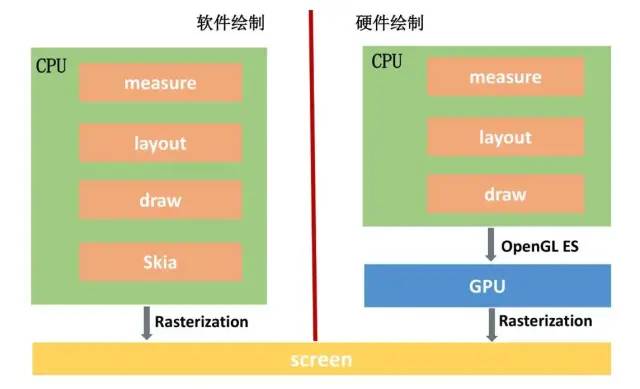
从图中可以看到,软件绘制使用 Skia库,它是一款能在低端设备,如手机呈现高质量的2D跨平台图形框架,类似Chrome、Flutter内部使用的都是Skia库。硬件绘制的思想就是通过底层软件代码,将 CPU不擅长的图形计算转换成GPU专用指令,由GPU完成绘制任务。
所以说硬件加速的本质就是使用GPU代替CPU完成Graphic Buffer绘制工作,以实现更好的性能,Android从4.0开始默认开启了硬件加速,但还有一些API不支持硬件加速,因此需要手动关闭硬件加速。
需要注意的是,软件绘制使用的Skia库,但这不代表Skia不支持硬件加速,从Android 8开始,我们可以选择使用Skia进行硬件加速,Android 9开始就默认使用Skia来进行硬件加速。Skia的硬件加速主要是通过 copybit 模块调用OpenGL或者SKia来实现。
图像缓冲区
Android中的图像生产者OpenGL,Skia,Vulkan将绘制的数据存放在图像缓冲区中,Android中的图像消费SurfaceFlinger从图像缓冲区将数据取出,进行加工及合成
那么图像缓冲区我们又需要注意哪些内容呢?
黄油计划
优化是无止境的,Google 在 2012 年的 I/O 大会上宣布了 Project Butter 黄油计划,并且在 Android 4.1 中正式开启了这个机制。
VSYNC信号
VSYNC(Vertical Synchronization)是理解 Project Butter 的核心。对于 Android 4.0,CPU 可能会因为在忙其他的事情,导致没来得及处理 UI 绘制。
为了解决这个问题,系统在收到VSync信号后,将马上开始下一帧的渲染。即一旦收到VSync通知(16ms触发一次),CPU和GPU 才立刻开始计算然后把数据写入buffer。如下图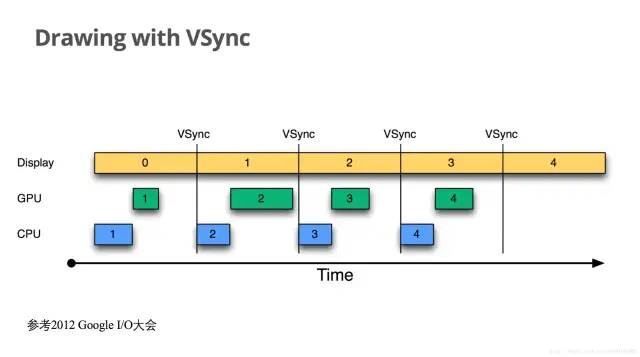
CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。
一句话总结,VSync同步使得CPU/GPU充分利用了16.6ms时间,减少jank。
三缓冲机制
在Android 4.0之前,Android采用双缓冲机制,让绘制和显示器拥有各自的buffer:GPU 始终将完成的一帧图像数据写入到 Back Buffer,而显示器使用 Frame Buffer,当屏幕刷新时,Frame Buffer 并不会发生变化,当Back buffer准备就绪后,它们才进行交换。
但是如果界面比较复杂,CPU/GPU的处理时间较长 超过了16.6ms呢,双缓冲机制会带来什么问题?如下图: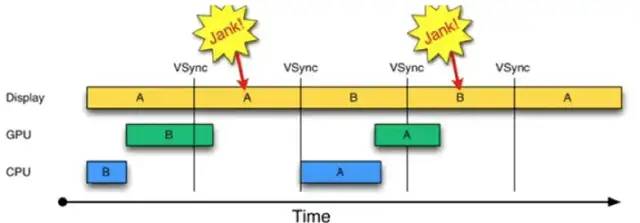
在第二个时间段内,但却因 GPU还在处理B帧,缓存没能交换,导致A帧被重复显示。而 B完成后,又因为缺乏VSync信号,它只能等待下一个signal的来临。于是在这一过程中,有一大段时间是被浪费的。当下一个 VSync出现时,CPU/GPU马上执行操作(A帧),且缓存交换,相应的显示屏对应的就是B。这时看起来就是正常的。只不过由于执行时间仍然超过16ms,导致下一次应该执行的缓冲区交换又被推迟了——如此循环反复,便出现了越来越多的“Jank”。
三缓冲就是在双缓冲机制基础上增加了一个Graphic Buffer缓冲区,这样可以最大限度的利用空闲时间,带来的坏处是多使用的一个Graphic Buffer所占用的内存。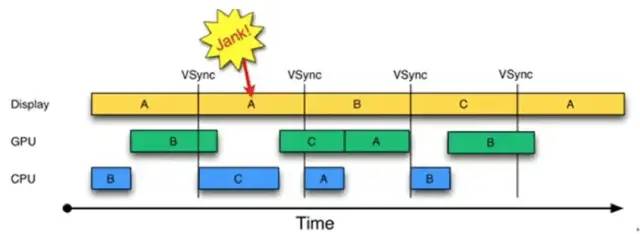
三缓冲机制有效利用了等待vysnc的时间,可以帮助我们减少了jank
RenderThread
经过 Android 4.1 的 Project Butter 黄油计划之后,Android 的渲染性能有了很大的改善。不过你有没有注意到这样一个问题,虽然利用了 GPU 的图形高性能运算,但是从计算 DisplayList,到通过 GPU 绘制到 Frame Buffer,整个计算和绘制都在 UI 主线程中完成。
UI 线程任务过于繁重。如果整个渲染过程比较耗时,可能造成无法响应用户的操作,进而出现卡顿的情况。GPU 对图形的绘制渲染能力更胜一筹,如果使用 GPU 并在不同线程绘制渲染图形,那么整个流程会更加顺畅。
正因如此,在 Android 5.0 引入两个比较大的改变。一个是引入了 RenderNode 的概念,它对 DisplayList 及一些 View 显示属性都做了进一步封装。另一个是引入了 RenderThread,所有的 GL 命令执行都放到这个线程上,渲染线程在 RenderNode 中存有渲染帧的所有信息,可以做一些属性动画,这样即便主线程有耗时操作的时候也可以保证动画流程。
图像消费者
SurfaceFlinger是Android系统中最重要的一个图像消费者,Activity绘制的界面图像,都会传递到SurfaceFlinger来,SurfaceFlinger的作用主要是接收GraphicBuffer,然后交给HWComposer或者OpenGL做合成,合成完成后,SurfaceFlinger会把最终的数据提交给FrameBuffer。
SurfaceFlinger是图像数据的消费者。在应用程序请求创建surface的时候,SurfaceFlinger会创建一个Layer。Layer是SurfaceFlinger操作合成的基本单元。所以,一个surface对应一个Layer。
当应用程序把绘制好的GraphicBuffer数据放入BufferQueue后,接下来的工作就是SurfaceFlinger来完成了。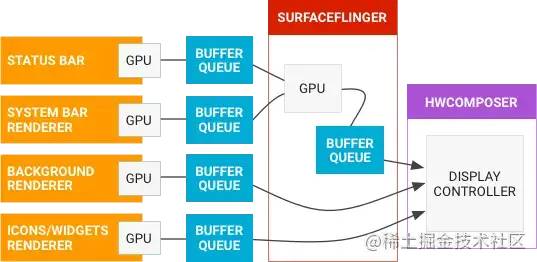
系统会有多个应用程序,一个程序有多个BufferQueue队列。SurfaceFlinger就是用来决定何时以及怎么去管理和显示这些队列的。SurfaceFlinger请求HAL硬件层,来决定这些Buffer是硬件来合成还是自己通过OpenGL来合成。
最终把合成后的buffer数据,展示在屏幕上。
总结
总得来说,Android图像渲染机制是一个生产者消费者的模型,如下图所示: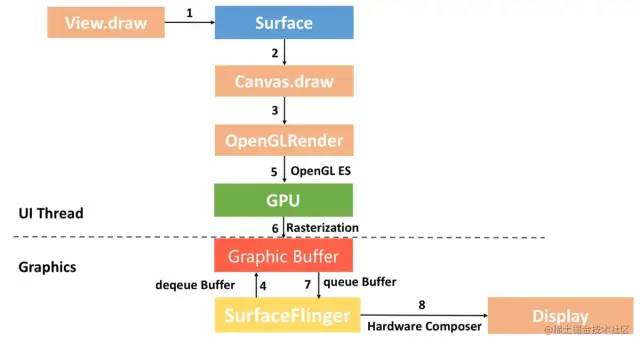
onMeasure、onLayout计算出view的大小和摆放的位置,这都是UI线程要做的事情,在draw方法中进行绘制,但此时是没有真正去绘制。而是把绘制的指令封装为displayList,进一步封装为RenderNode,在同步给RenderThread。RenderThread通过dequeue拿到graphic buffer(surfaceFlinger的缓冲区),根据绘制指令直接操作OpenGL的绘制接口,最终通过GPU设备把绘制指令渲染到了离屏缓冲区graphic buffer。完成渲染后,把缓冲区交还给 SurfaceFlinger的BufferQueue。SurfaceFlinger会通过硬件设备进行layer的合成,最终展示到屏幕。
技术问答,学习成长,欢迎加入音视频开发进阶知识星球
技术交流,欢迎加我微信:ezglumes ,拉你入技术交流群。
私信领取相关资料
推荐阅读:
觉得不错,点个在看呗~
