
分享1个爬虫小案例,还能语音播报!
三步加星标
1 预备知识
pip install requests
pip install lxml
pip install pyttsx3
import pyttsx3
word = pyttsx3.init()
word.say('你好')
# 关键一句,没有这行代码,不会播放语音
word.runAndWait()
2 详细说一说
2.1 get请求目标网址
import requests
# 向目标url地址发送请求,返回一个response对象
req = requests.get('https://www.tianqi.com/beijing/')
# .text是response对象的网页html
print(req.text)
import requests
headers = {'content-type':'application/json', 'User-Agent':'Mozilla/5.0 (Xll; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
# 向目标url地址发送请求,返回一个response对象
req = requests.get('https://www.tianqi.com/beijing/',headers=headers)
# .text是response对象的网页html
print(req.text)
2.2 lxml.etree登场
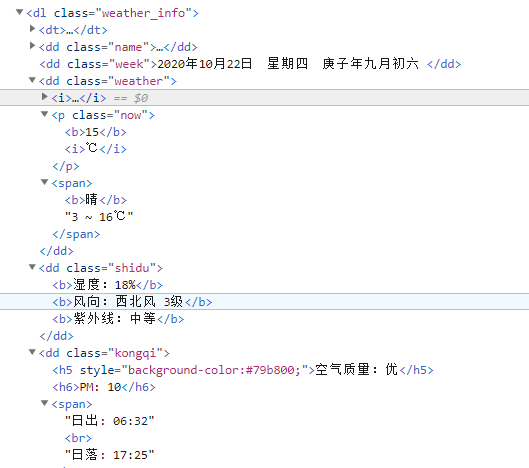
html_obj = etree.HTML(html)
html_data = html_obj.xpath("//d1[@class='weather_info']//text()")
word = "欢迎使用天气播报助手"
for data in html_data:
word += data
2.3 把结果说出来
ptt = pyttsx3.init()
ptt.say(word)
ptt.runAndWait()评论