
看了我常用的数据库设计技巧,同事也开始悄悄模仿了...
前言
对于后端开发同学来说,访问数据库,是代码中必不可少的一个环节。
系统中收集到用户的核心数据,为了安全性,我们一般会存储到数据库,比如:mysql,oracle等。
后端开发的日常工作,需要不断的建库和建表,来满足业务需求。
通常情况下,建库的频率比建表要低很多,所以,我们这篇文章主要讨论建表相关的内容。
如果我们在建表的时候不注意细节,等后面系统上线之后,表的维护成本变得非常高,而且很容易踩坑。
今天就跟大家一起聊聊,数据库建表的15个小技巧,希望对你会有所帮助。

1.名字
建表的时候,给表、字段和索引起个好名字,真的太重要了。
1.1 见名知意
名字就像表、字段和索引的一张脸,可以给人留下第一印象。
好的名字,言简意赅,见名知意,让人心情愉悦,能够提高沟通和维护成本。
坏的名字,模拟两可,不知所云。而且显得杂乱无章,看得让人抓狂。
反例:
用户名称字段定义成:yong_hu_ming、用户_name、name、user_name_123456789
你看了可能会一脸懵逼,这是什么骚操作?
正例:
用户名称字段定义成:user_name
温馨提醒一下,名字也不宜过长,尽量控制在
30个字符以内。
1.2 大小写
名字尽量都用小写字母,因为从视觉上,小写字母更容易让人读懂。
反例:
字段名:PRODUCT_NAME、PRODUCT_name
全部大写,看起来有点不太直观。而一部分大写,一部分小写,让人看着更不爽。
正例:
字段名:product_name
名字还是使用全小写字母,看着更舒服。
1.3 分隔符
很多时候,名字为了让人好理解,有可能会包含多个单词。
那么,多个单词间的分隔符该用什么呢?
反例:
字段名:productname、productName、product name、product@name
单词间没有分隔,或者单词间用驼峰标识,或者单词间用空格分隔,或者单词间用@分隔,这几种方式都不太建议。
正例:
字段名:product_name
强烈建议大家在单词间用_分隔。
1.4 表名
对于表名,在言简意赅,见名知意的基础之上,建议带上业务前缀。
如果是订单相关的业务表,可以在表名前面加个前缀:order_。
例如:order_pay、order_pay_detail等。
如果是商品相关的业务表,可以在表名前面加个前缀:product_。
例如:product_spu,product_sku等。
这样做的好处是为了方便归类,把相同业务的表,可以非常快速的聚集到一起。
另外,还有有个好处是,如果哪天有非订单的业务,比如:金融业务,也需要建一个名字叫做pay的表,可以取名:finance_pay,就能非常轻松的区分。
这样就不会出现同名表的情况。
1.5 字段名称
字段名称是开发人员发挥空间最大,但也最容易发生混乱的地方。
比如有些表,使用flag表示状态,另外的表用status表示状态。
可以统一一下,使用status表示状态。
如果一个表使用了另一个表的主键,可以在另一张表的名后面,加_id或_sys_no,例如:
在product_sku表中有个字段,是product_spu表的主键,这时候可以取名:product_spu_id或product_spu_sys_no。
还有创建时间,可以统一成:create_time,修改时间统一成:update_time。
删除状态固定为:delete_status。
其实还有很多公共字段,在不同的表之间,可以使用全局统一的命名规则,定义成相同的名称,以便于大家好理解。
1.6 索引名
在数据库中,索引有很多种,包括:主键、普通索引、唯一索引、联合索引等。
每张表的主键只有一个,一般使用:id或者sys_no命名。
普通索引和联合索引,其实是一类。在建立该类索引时,可以加ix_前缀,比如:ix_product_status。
唯一索引,可以加ux_前缀,比如:ux_product_code。
2.字段类型
在设计表时,我们在选择字段类型时,可发挥空间很大。
时间格式的数据有:date、datetime和timestamp等等可以选择。
字符类型的数据有:varchar、char、text等可以选择。
数字类型的数据有:int、bigint、smallint、tinyint等可以选择。
说实话,选择很多,有时候是一件好事,也可能是一件坏事。
如何选择一个合适的字段类型,变成了我们不得不面对的问题。
如果字段类型选大了,比如:原本只有1-10之间的10个数字,结果选了bigint,它占8个字节。
其实,1-10之间的10个数字,每个数字1个字节就能保存,选择tinyint更为合适。
这样会白白浪费7个字节的空间。
如果字段类型择小了,比如:一个18位的id字段,选择了int类型,最终数据会保存失败。
所以选择一个合适的字段类型,还是非常重要的一件事情。
以下原则可以参考一下:
尽可能选择占用存储空间小的字段类型,在满足正常业务需求的情况下,从小到大,往上选。
如果字符串长度固定,或者差别不大,可以选择char类型。如果字符串长度差别较大,可以选择varchar类型。
是否字段,可以选择bit类型。
枚举字段,可以选择tinyint类型。
主键字段,可以选择bigint类型。
金额字段,可以选择decimal类型。
时间字段,可以选择timestamp或datetime类型。
3.字段长度
前面我们已经定义好了字段名称,选择了合适的字段类型,接下来,需要重点关注的是字段长度了。
比如:varchar(20),biginit(20)等。
那么问题来了,varchar代表的是字节长度,还是字符长度呢?
答:在mysql中除了varchar和char是代表字符长度之外,其余的类型都是代表字节长度。
biginit(n) 这个n表示什么意思呢?
假如我们定义的字段类型和长度是:bigint(4),bigint实际长度是8个字节。
现在有个数据a=1,a显示4个字节,所以在不满4个字节时前面填充0(前提是该字段设置了zerofill属性),比如:0001。
当满了4个字节时,比如现在数据是a=123456,它会按照实际的长度显示,比如:123456。
但需要注意的是,有些mysql客户端即使满了4个字节,也可能只显示4个字节的内容,比如会显示成:1234。
所以bigint(4),这里的4表示显示的长度为4个字节,实际长度还是占8个字节。
4.字段个数
我们在建表的时候,一定要对字段个数做一些限制。
我之前见过有人创建的表,有几十个,甚至上百个字段,表中保存的数据非常大,查询效率很低。
如果真有这种情况,可以将一张大表拆成多张小表,这几张表的主键相同。
建议每表的字段个数,不要超过20个。
5. 主键
在创建表时,一定要创建主键。
因为主键自带了主键索引,相比于其他索引,主键索引的查询效率最高,因为它不需要回表。
此外,主键还是天然的唯一索引,可以根据它来判重。
在单个数据库中,主键可以通过AUTO_INCREMENT,设置成自动增长的。
但在分布式数据库中,特别是做了分库分表的业务库中,主键最好由外部算法(比如:雪花算法)生成,它能够保证生成的id是全局唯一的。
除此之外,主键建议保存跟业务无关的值,减少业务耦合性,方便今后的扩展。
不过我也见过,有些一对一的表关系,比如:用户表和用户扩展表,在保存数据时是一对一的关系。
这样,用户扩展表的主键,可以直接保存用户表的主键。
6.存储引擎
在mysql5.1以前的版本,默认的存储引擎是myslam,而mysql5.1以后的版本,默认的存储引擎变成了innodb。
之前我们还在创建表时,还一直纠结要选哪种存储引擎?
myslam的索引和数据分开存储,而有利于查询,但它不支持事务和外键等功能。
而innodb虽说查询性能,稍微弱一点,但它支持事务和外键等,功能更强大一些。
以前的建议是:读多写少的表,用myslam存储引擎。而写多读多的表,用innodb。
但虽说mysql对innodb存储引擎性能的不断优化,现在myslam和innodb查询性能相差已经越来越小。
所以,建议我们在使用mysql8以后的版本时,直接使用默认的innodb存储引擎即可,无需额外修改存储引擎。
7. NOT NULL
在创建字段时,需要选择该字段是否允许为NULL。
我们在定义字段时,应该尽可能明确该字段NOT NULL。
为什么呢?
我们主要以innodb存储引擎为例,myslam存储引擎没啥好说的。
主要有以下原因:
在innodb中,需要额外的空间存储null值,需要占用更多的空间。
null值可能会导致索引失效。
null值只能用is null或者is not null判断,用=号判断永远返回false。
因此,建议我们在定义字段时,能定义成NOT NULL,就定义成NOT NULL。
但如果某个字段直接定义成NOT NULL,万一有些地方忘了给该字段写值,就会insert不了数据。
这也算合理的情况。
但有一种情况是,系统有新功能上线,新增了字段。上线时一般会先执行sql脚本,再部署代码。
由于老代码中,不会给新字段赋值,则insert数据时,也会报错。
由此,非常有必要给NOT NULL的字段设置默认值,特别是后面新增的字段。
例如:
alter table product_sku add column brand_id int(10) not null default 0;
8.外键
在mysql中,是存在外键的。
外键存在的主要作用是:保证数据的一致性和完整性。
例如:
create table class (
id int(10) primary key auto_increment,
cname varchar(15)
);
有个班级表class。
然后有个student表:
create table student(
id int(10) primary key auto_increment,
name varchar(15) not null,
gender varchar(10) not null,
cid int,
foreign key(cid) references class(id)
);
其中student表中的cid字段,保存的class表的id,这时通过foreign key增加了一个外键。
这时,如果你直接通过student表的id删除数据,会报异常:
a foreign key constraint fails
必须要先删除class表对于的cid那条数据,再删除student表的数据才行,这样能够保证数据的一致性和完整性。
顺便说一句:只有存储引擎是innodb时,才能使用外键。
如果只有两张表的关联还好,但如果有十几张表都建了外键关联,每删除一次主表,都需要同步删除十几张子表,很显然性能会非常差。
因此,互联网系统中,一般建议不使用外键。因为这类系统更多的是为了性能考虑,宁可牺牲一点数据一致性和完整性。
除了外键之外,存储过程和触发器也不太建议使用,他们都会影响性能。
9. 索引
在建表时,除了指定主键索引之外,还需要创建一些普通索引。
例如:
create table product_sku(
id int(10) primary key auto_increment,
spu_id int(10) not null,
brand_id int(10) not null,
name varchar(15) not null
);
在创建商品表时,使用spu_id(商品组表)和brand_id(品牌表)的id。
像这类保存其他表id的情况,可以增加普通索引:
create table product_sku (
id int(10) primary key auto_increment,
spu_id int(10) not null,
brand_id int(10) not null,
name varchar(15) not null,
KEY `ix_spu_id` (`spu_id`) USING BTREE,
KEY `ix_brand_id` (`brand_id`) USING BTREE
);
后面查表的时候,效率更高。
但索引字段也不能建的太多,可能会影响保存数据的效率,因为索引需要额外的存储空间。
建议单表的索引个数不要超过:5个。
如果在建表时,发现索引个数超过5个了,可以删除部分普通索引,改成联合索引。
顺便说一句:在创建联合索引的时候,需要使用注意最左匹配原则,不然,建的联合索引效率可能不高。
对于数据重复率非常高的字段,比如:状态,不建议单独创建普通索引。因为即使加了索引,如果mysql发现全表扫描效率更高,可能会导致索引失效。
如果你对索引失效问题比较感兴趣,可以看看我的另一篇文章《聊聊索引失效的10种场景,太坑了》,里面有非常详细的介绍。
10.时间字段
时间字段的类型,我们可以选择的范围还是比较多的,目前mysql支持:date、datetime、timestamp、varchar等。
varchar类型可能是为了跟接口保持一致,接口中的时间类型是String。
但如果哪天我们要通过时间范围查询数据,效率会非常低,因为这种情况没法走索引。
date类型主要是为了保存日期,比如:2020-08-20,不适合保存日期和时间,比如:2020-08-20 12:12:20。
而datetime和timestamp类型更适合我们保存日期和时间。
但它们有略微区别。
timestamp:用4个字节来保存数据,它的取值范围为1970-01-01 00:00:01UTC ~2038-01-19 03:14:07。此外,它还跟时区有关。
datetime:用8个字节来保存数据,它的取值范围为1000-01-01 00:00:00~9999-12-31 23:59:59。它跟时区无关。
优先推荐使用datetime类型保存日期和时间,可以保存的时间范围更大一些。
温馨提醒一下,在给时间字段设置默认值是,建议不要设置成:
0000-00-00 00:00:00,不然查询表时可能会因为转换不了,而直接报错。
11.金额字段
mysql中有多个字段可以表示浮点数:float、double、decimal等。
而float和double可能会丢失精度,因此推荐大家使用decimal类型保存金额。
一般我们是这样定义浮点数的:decimal(m,n)。
其中n是指小数的长度,而m是指整数加小数的总长度。
假如我们定义的金额类型是这样的:decimal(10,2),则表示整数长度是8位,并且保留2位小数。
12.唯一索引
唯一索引在我们实际工作中,使用频率相当高。
你可以给单个字段,加唯一索引,比如:组织机构code。
也可以给多个字段,加一个联合的唯一索引,比如:分类编号、单位、规格等。
单个的唯一索引还好,但如果是联合的唯一索引,字段值出现null时,则唯一性约束可能会失效。
关于唯一索引失效的问题,感兴趣的小伙伴可以看看我的另一篇文章《明明加了唯一索引,为什么还是产生重复数据?》。
创建唯一索引时,相关字段一定不能包含null值,否则唯一性会失效。
13.字符集
mysql中支持的字符集有很多,常用的有:latin1、utf-8、utf8mb4、GBK等。
这4种字符集情况如下:
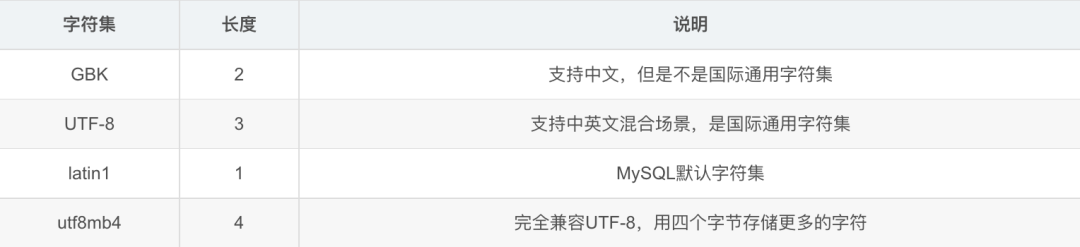
latin1容易出现乱码问题,在实际项目中使用比较少。
而GBK支持中文,但不支持国际通用字符,在实际项目中使用也不多。
从目前来看,mysql的字符集使用最多的还是:utf-8和utf8mb4。
其中utf-8占用3个字节,比utf8mb4的4个字节,占用更小的存储空间。
但utf-8有个问题:即无法存储emoji表情,因为emoji表情一般需要4个字节。
由此,使用utf-8字符集,保存emoji表情时,数据库会直接报错。
所以,建议在建表时字符集设置成:utf8mb4,会省去很多不必要的麻烦。
14. 排序规则
不知道,你关注过没,在mysql中创建表时,有个COLLATE参数可以设置。
例如:
CREATE TABLE `order` (
`id` bigint NOT NULL AUTO_INCREMENT,
`code` varchar(20) COLLATE utf8mb4_bin NOT NULL,
`name` varchar(30) COLLATE utf8mb4_bin NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `un_code` (`code`),
KEY `un_code_name` (`code`,`name`) USING BTREE,
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
它是用来设置排序规则的。
字符排序规则跟字符集有关,比如:字符集如果是utf8mb4,则字符排序规则也是以:utf8mb4_开头的,常用的有:utf8mb4_general_ci、utf8mb4_bin等。
其中utf8mb4_general_ci排序规则,对字母的大小写不敏感。说得更直白一点,就是不区分大小写。
而utf8mb4_bin排序规则,对字符大小写敏感,也就是区分大小写。
说实话,这一点还是非常重要的。
假如order表中现在有一条记录,name的值是大写的YOYO,但我们用小写的yoyo去查,例如:
select * from order where name='yoyo';
如果字符排序规则是utf8mb4_general_ci,则可以查出大写的YOYO的那条数据。
如果字符排序规则是utf8mb4_bin,则查不出来。
由此,字符排序规则一定要根据实际的业务场景选择,否则容易出现问题。
15.大字段
我们在创建表时,对一些特殊字段,要额外关注,比如:大字段,即占用较多存储空间的字段。
比如:用户的评论,这就属于一个大字段,但这个字段可长可短。
但一般会对评论的总长度做限制,比如:最多允许输入500个字符。
如果直接定义成text类型,可能会浪费存储空间,所以建议将这类字段定义成varchar类型的存储效率更高。
当然,我还见过更大的字段,即该字段直接保存合同数据。
一个合同可能会占几Mb。
在mysql中保存这种数据,从系统设计的角度来说,本身就不太合理。
像合同这种非常大的数据,可以保存到mongodb中,然后在mysql的业务表中,保存mongodb表的id。
程序汪资料链接
卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
卧槽!阿里大佬总结的《图解Java》火了,完整版PDF开放下载!
欢迎添加程序汪个人微信 itwang007 进粉丝群或围观朋友圈