
GitHub Star 20000+,程序员圈里都炸锅了!
OCR方向的工程师,之前一定听说过PaddleOCR这个项目,
累计Star数量已超过20000+,
频频登上GitHub Trending和Paperswithcode 日榜月榜第一,
在Medium与Papers with Code 联合评选的《Top Trending Libraries of 2021》,从百万量级项目中脱颖而出,荣登Top10!
在《2021中国开源年度报告》中被评为活跃度Top5!
称它为 OCR方向目前最火的repo绝对不为过。

PaddleOCR影响力

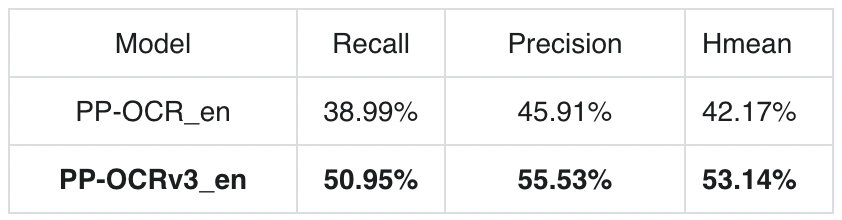
PP-OCRv3效果
下面我们就对上述升级依次进行说明:


具体的优化策略包括:



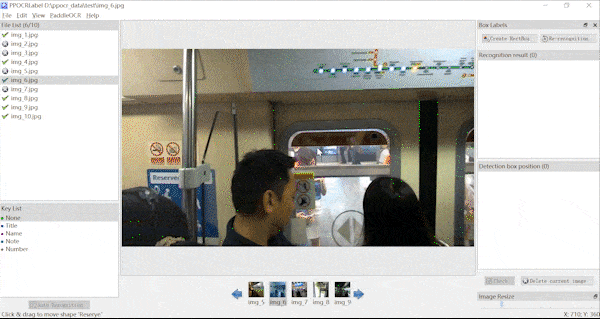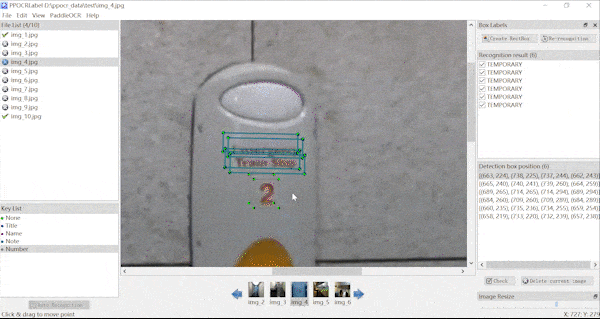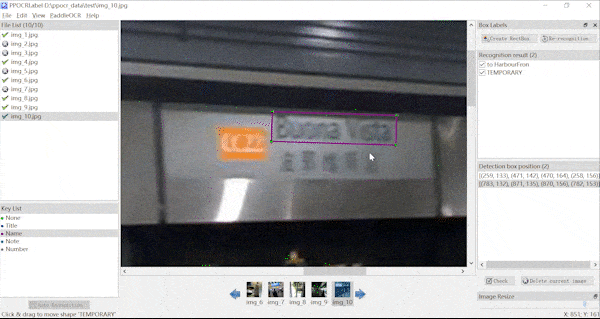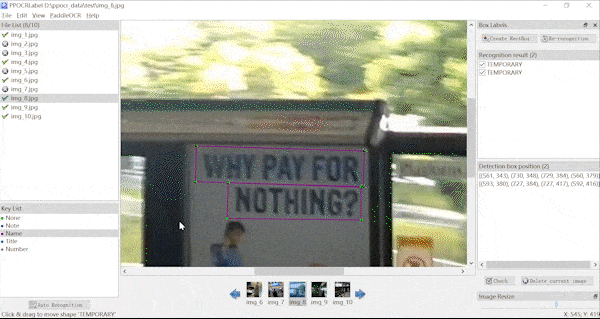
表格标注动图、KIE标注动图(横向拉动)



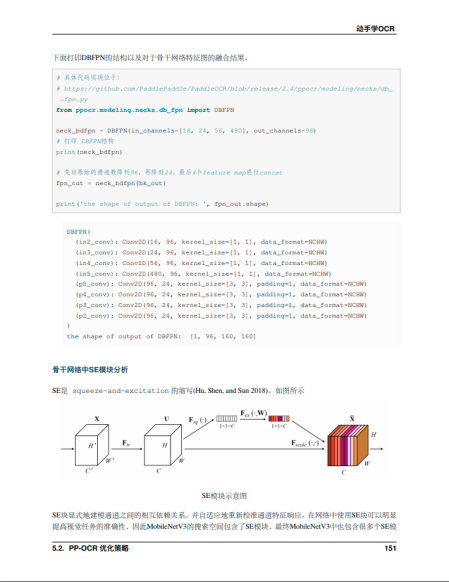

(可竖向拉动多图)
加入PaddleOCR技术交流群
获取精品直播课/学习大礼包等福利!



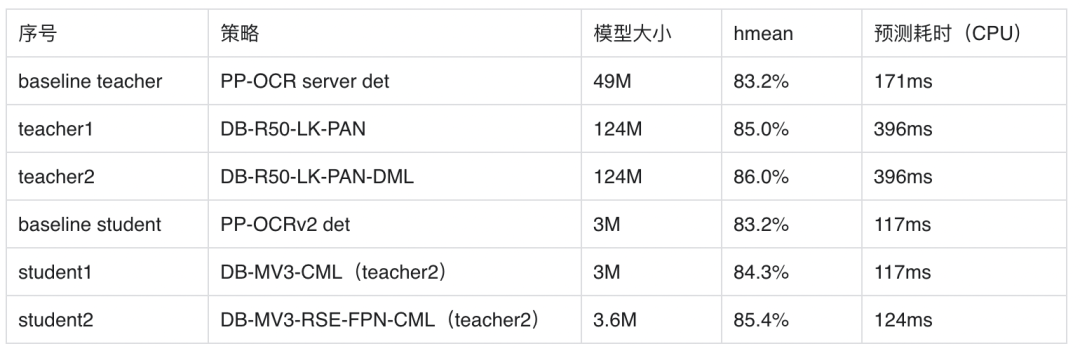
测试环境:Intel Gold 6148 CPU,预测时开启MKLDNN加速。
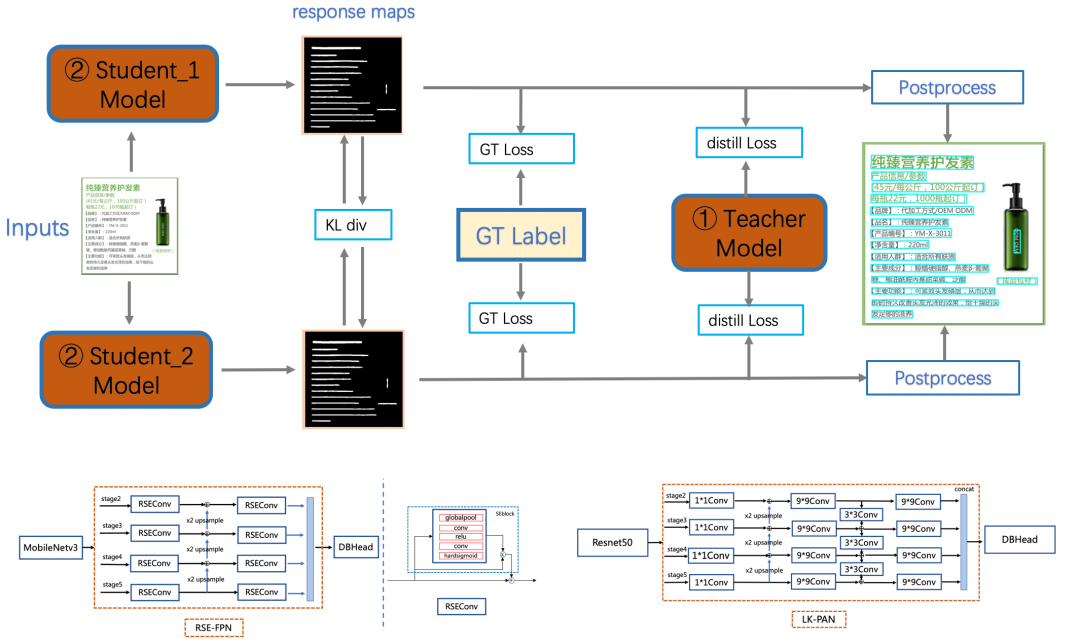
LK-PAN:大感受野的PAN结构
DML:教师模型互学习策略
RSE-FPN:残差注意力机制的FPN结构
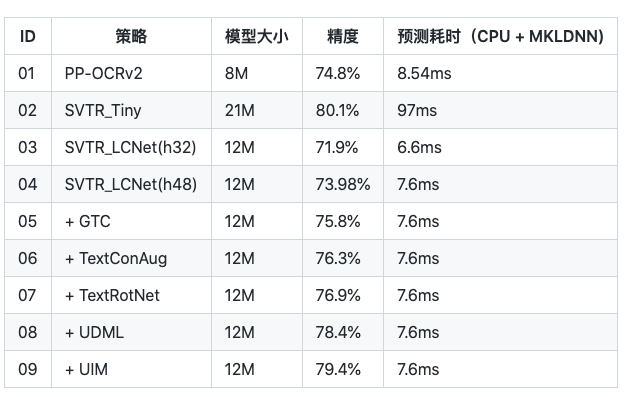

SVTR_LCNet:轻量级文本识别网络
GTC:Attention指导CTC训练策略
TextConAug:挖掘文字上下文信息的数据增广策略
TextRotNet:自监督的预训练模型
联合互学习策略
无标注数据挖掘方案


想了解更多技术详细解读,欢迎扫码加入技术交流群。
大家如果觉得不错,建议访问GitHub点个star关注收藏哈。
https://github.com/PaddlePaddle/PaddleOCR
评论