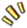6 种事件驱动的架构模式
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
在过去一年里,我一直是数据流团队的一员,负责Wix事件驱动的消息传递基础设施(基于 Kafka)。有超过 1400 个微服务使用这个基础设施。在此期间,我实现或目睹了事件驱动消息传递设计的几个关键模式,这些模式有助于创建一个健壮的分布式系统,该系统可以轻松地处理不断增长的流量和存储需求。
1.消费与投影
针对那些使用非常广泛、已经成为瓶颈的服务
当有遗留服务存储着大型域对象的数据,这些数据使用又非常广泛,使得该遗留服务成为瓶颈时,此模式可以提供帮助。
在 Wix,我们的 MetaSite 服务就面临着这样的情况,它为 Wix 用户创建的每个站点保存了大量的元数据,比如站点版本、站点所有者以及站点上安装了哪些应用程序——已安装应用上下文(The Installed Apps Context.)。
这些信息对于 Wix 的许多其他微服务(团队)很有价值,比如 Wix Stores、Wix booking、Wix Restaurants 等等。这个服务被超过 100 万 RPM 的请求轰炸,它们需要获取站点元数据的不同部分。
从服务的各种 API 可以明显看出,它处理了客户端服务的太多不同的关注点。
MetaSite 服务处理大约 1M RPM 的各类请求
我们想要回答的问题是,如何以最终一致的方式将读请求从该服务转移出来?
使用 Kafka 创建“物化视图”
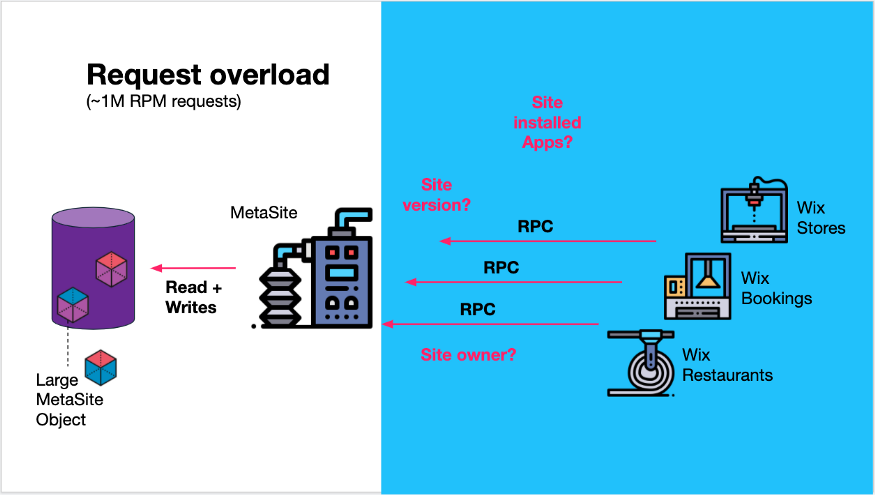
负责这项服务的团队决定另外创建一个服务,只处理 MetaSite 的一个关注点——来自客户端服务的“已安装应用上下文”请求。
首先,他们将所有数据库的站点元数据对象以流的方式传输到 Kafka 主题中,包括新站点创建和站点更新。一致性可以通过在 Kafka Consumer 中进行 DB 插入来实现,或者通过使用CDC产品(如Debezium)来实现。
其次,他们创建了一个有自己数据库的“只写”服务(反向查找写入器),该服务使用站点元数据对象,但只获取已安装应用上下文并写入数据库。即将站点元数据的某个“视图”(已安装的应用程序)投影到数据库中。
已安装应用上下文消费与投影
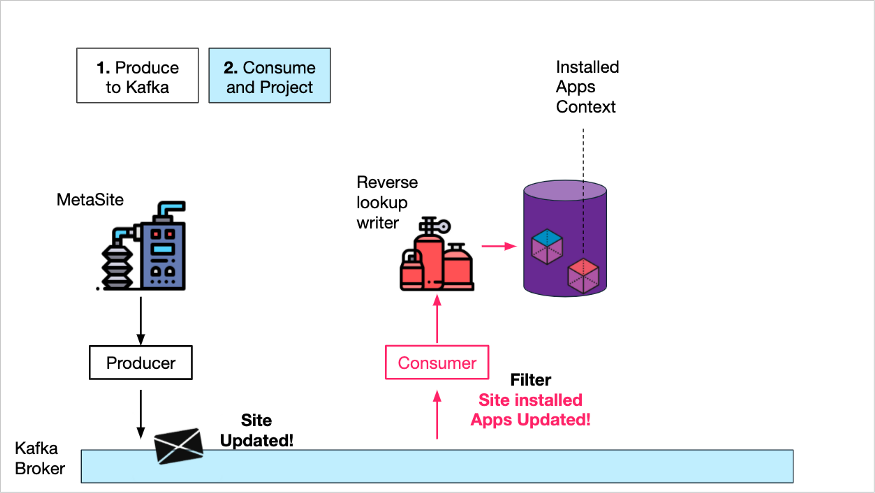
第三,他们创建了一个“只读”服务,只接受与已安装应用上下文相关的请求,通过查询存储着“已安装应用程序”视图的数据库来满足请求。
读写分离
效果
通过将数据以流的方式传输到 Kafka,MetaSite 服务完全同数据消费者解耦,这大大降低了服务和 DB 的负载。
通过消费来自 Kafka 的数据,并为特定的上下文创建一个“物化视图”,反向查找写入器服务能够创建一个最终一致的数据投影,大幅优化了客户端服务的查询需求。
将读服务与写服务分开,可以方便地扩展只读 DB 副本和服务实例的数量,这些实例可以处理来自全球多个数据中心的不断增长的查询负载。
2.端到端事件驱动
针对简单业务流程的状态更新
请求-应答模型在浏览器-服务器交互中特别常见。借助 Kafka 和WebSocket,我们就有了一个完整的事件流驱动,包括浏览器-服务器交互。
这使得交互过程容错性更好,因为消息在 Kafka 中被持久化,并且可以在服务重启时重新处理。该架构还具有更高的可伸缩性和解耦性,因为状态管理完全从服务中移除,并且不需要对查询进行数据聚合和维护。
考虑一下这种情况,将所有 Wix 用户的联系方式导入 Wix 平台。
这个过程涉及到两个服务:Contacts Jobs 服务处理导入请求并创建导入批处理作业,Contacts Importer 执行实际的格式化并存储联系人(有时借助第三方服务)。
传统的请求-应答方法需要浏览器不断轮询导入状态,前端服务需要将状态更新情况保存到数据库表中,并轮询下游服务以获得状态更新。
而使用 Kafka 和 WebSocket 管理者服务,我们可以实现一个完全分布式的事件驱动过程,其中每个服务都是完全独立工作的。
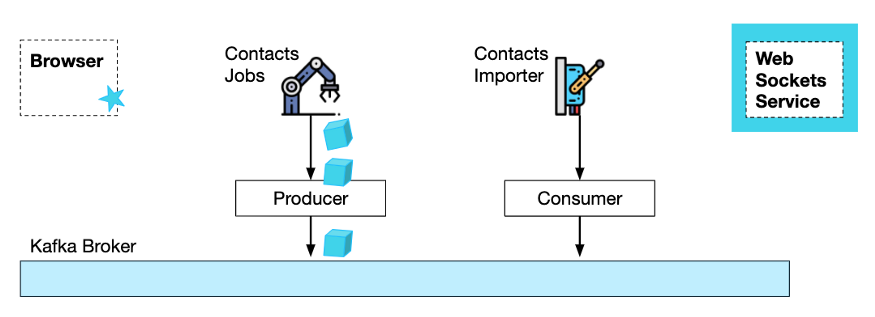
使用 Kafka 和 WebSocket 的 E2E 事件驱动
首先,浏览器会根据开始导入请求订阅 WebSocket 服务。
它需要提供一个 channel-Id,以便 WebSocket 服务能够将通知路由回正确的浏览器:
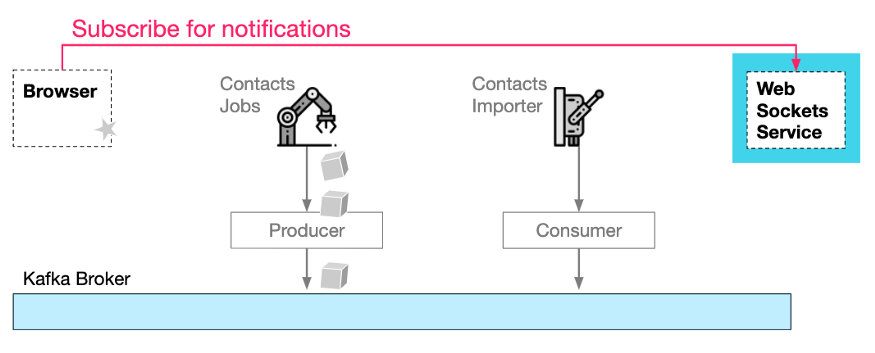
打开 WebSocket 通知“通道”
第二,浏览器需要向 Jobs 服务发送一个 HTTP 请求,联系人信息使用 CSV 格式,并附加 channel-Id,这样 Jobs 服务(和下游服务)就能够向 WebSocket 服务发送通知。注意,HTTP 响应将立即返回,没有任何内容。
第三,Jobs 服务在处理完请求后,会生成并向 Kafka 主题发送作业请求。
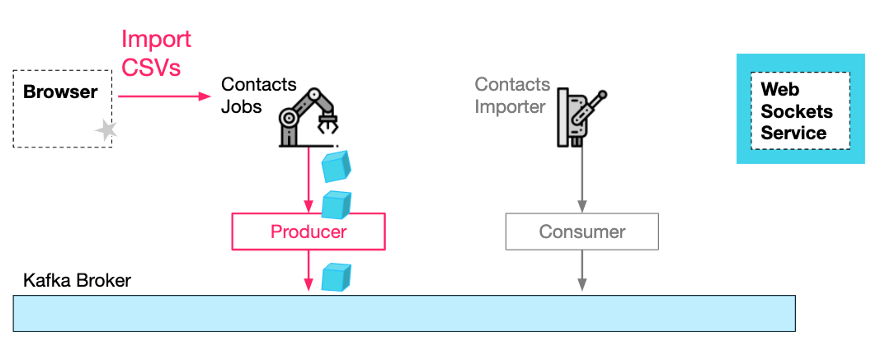
HTTP Import 请求和生成的 Import Job 消息
第四,Contacts Importer**服务消费来自 Kafka 的作业请求,并执行实际的导入任务。当它完成时,它可以通知 WebSocket 服务作业已经完成,而 WebSocket 服务又通知浏览器。
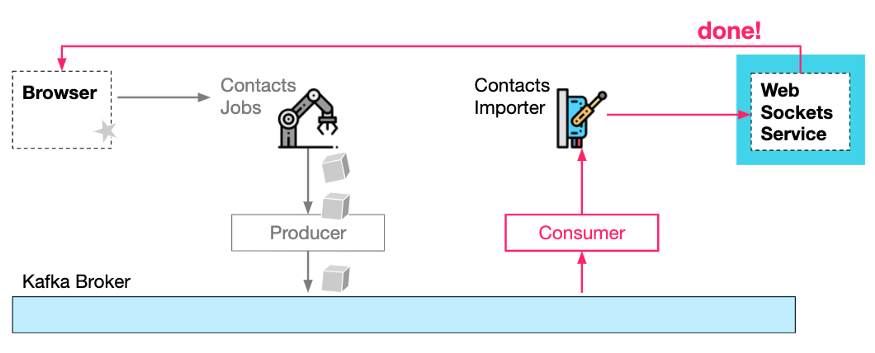
工作已消费、已处理和已完成状态通知
效果
使用这种设计,在导入过程的各个阶段通知浏览器变得很简单,而且不需要保持任何状态,也不需要任何轮询。
Kafka 的使用使得导入过程更具弹性和可扩展性,因为多个服务可以处理来自同一个原始导入 http 请求的作业。
使用 Kafka 复制,很容易将每个阶段放在最合适的数据中心和地理位置。也许导入器服务需要在谷歌 DC 上,以便可以更快地导入谷歌联系人。
WebSocket 服务的传入通知请求也可以生成到 Kafka,然后复制到 WebSocket 服务所在的数据中心。
3.内存 KV 存储
针对 0 延迟数据访问
有时,我们需要动态对应用程序进行持久化配置,但我们不想为它创建一个全面的关系数据库表。
一个选择是用HBase/Cassandra/DynamoDB为所有应用创建一个大的宽列存储表,其主键包含标识应用域的前缀(例如“store_taxes_”)。
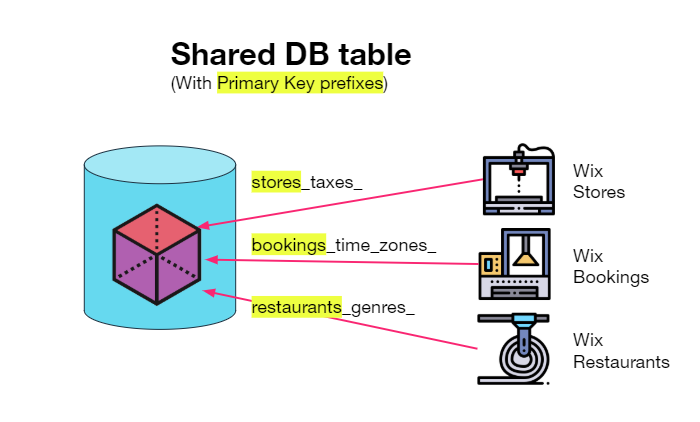
这个解决方案效果很好,但是通过网络取值存在无法避免的延迟。它更适合于更大的数据集,而不仅仅是配置数据。
另一种方法是有一个位于内存但同样具有持久性的键/值缓存——Redis AOF提供了这种能力。
Kafka 以压缩主题的形式为键/值存储提供了类似的解决方案(保留模型确保键的最新值不会被删除)。
在 Wix,我们将这些压缩主题用作内存中的 kv-store,我们在应用程序启动时加载(消费)来自主题的数据。这有一个 Redis 没有提供的好处,这个主题还可以被其他想要获得更新的用户使用。
订阅和查询
考虑以下用例——两个微服务使用压缩主题来做数据维护:Wix Business Manager(帮助 Wix 网站所有者管理他们的业务)使用一个压缩主题存放支持的国家列表,Wix Bookings(允许安排预约和课程)维护了一个“(Time Zones)”压缩主题。从这些内存 KV 存储中检索值的延迟为 0。
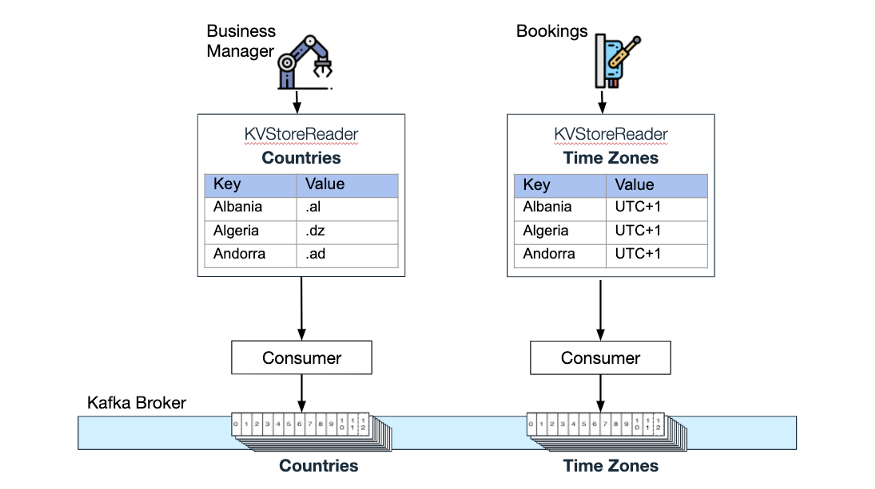
各内存 KV 存储以及相应的 Kafka 压缩主题
Wix Bookings 监听“国家(Countries)”主题的更新:
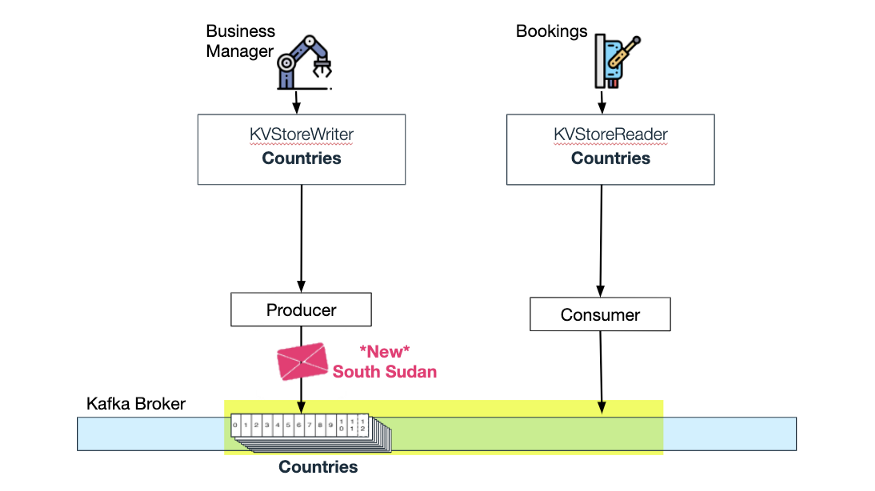
Bookings 消费来自压缩主题 Countries 的更新
当 Wix Business Manager 将另一个国家添加到“国家”主题时,Wix Bookings 会消费此更新,并自动为“时区”主题添加一个新的时区。现在,内存 KV 存储中的“时区”也通过更新增加了新的时区:
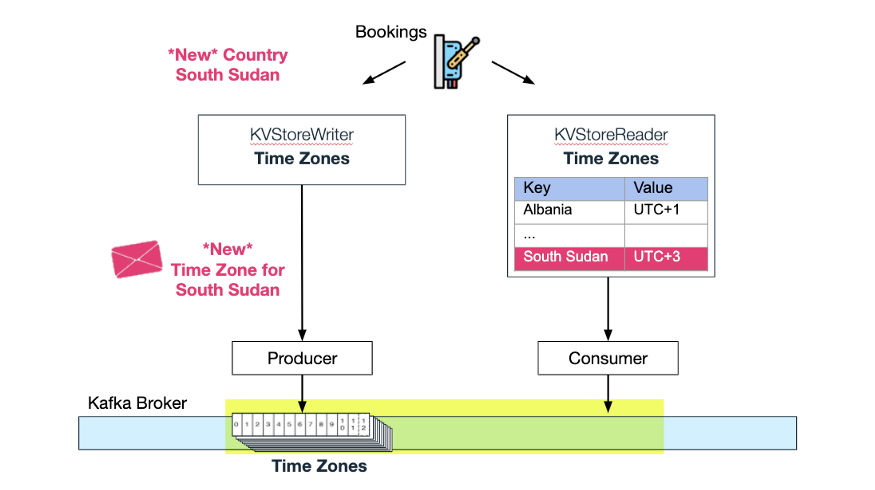
South Sudan 的时区被加入压缩主题
我们没有在这里停下来。Wix Events(供 Wix Users 管理事件传票和 RSVP)也可以使用 Bookings 的时区主题,并在一个国家因为夏令时更改时区时自动更新其内存 kv-store。
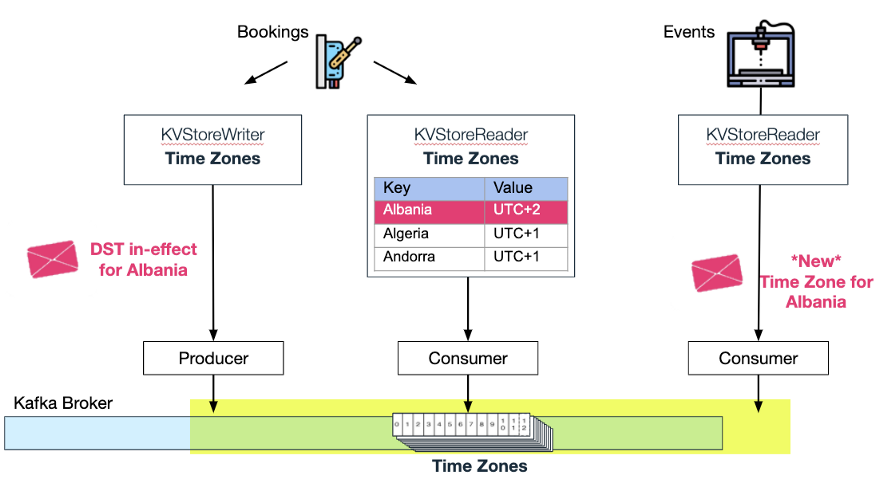
两个内存 KV 存储消费同一个压缩主题
4.调度并遗忘
当存在需要确保计划事件最终被处理的需求时
在许多情况下,需要 Wix 微服务根据某个计划执行作业。
Wix Payments Subscriptions 服务就是一个例子,它管理基于订阅的支付(例如瑜伽课程的订阅)。
对于每个月度或年度订阅用户,必须通过支付提供程序完成续订过程。
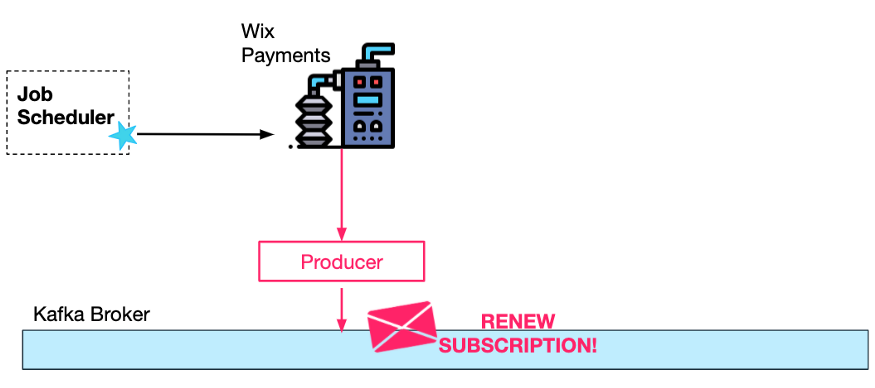
为此,Wix 自定义的 Job Scheduler 服务调用由 Payments Subscription 服务预先配置好的 REST 端点。
订阅续期过程在后台进行,不需要(人类)用户参与。这就是为什么最终可以成功续订很重要,即使临时有错误——例如第三支付提供程序不可用。
要确保这一过程是完全弹性的,一种方法是由作业调度器重复请求 Payment Subscriptions 服务(续订的当前状态保存在数据库中),对每个到期但尚未续期的订阅进行轮询。这将需要数据库上的悲观/乐观锁定,因为同一用户同一时间可能有多个订阅续期请求(来自两个单独的正在进行的请求)。
更好的方法是首先生成 Kafka 请求。为什么?因为请求的处理将由 Kafka 的消费者顺序完成(对于每个特定的用户),所以不需要并行工作的同步机制。
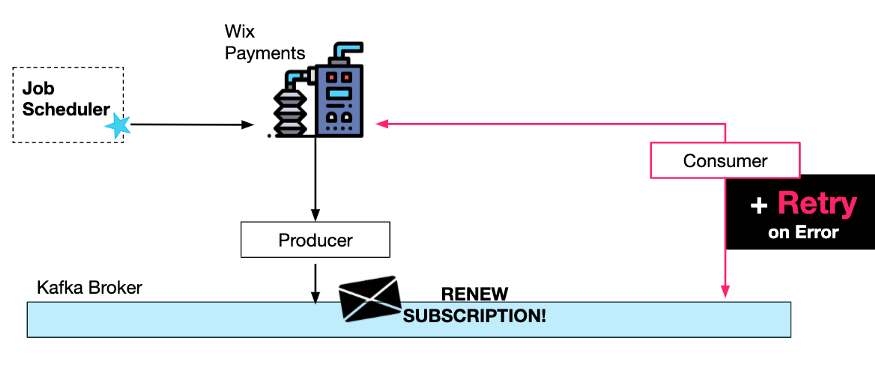
此外,一旦消息生成并发送到 Kafka,我们就可以通过引入消费者重试来确保它最终会被成功处理。由于有这些重试,请求调度的频率可能就会低很多。
在这种情况下,我们希望可以保持处理顺序,这样重试逻辑可以在两次尝试之间(以“指数退避”间隔进行)简单地休眠。
Wix 开发人员使用我们自定义的Greyhound消费者,因此,他们只需指定一个 BlockingPolicy,并根据需要指定适当的重试间隔。
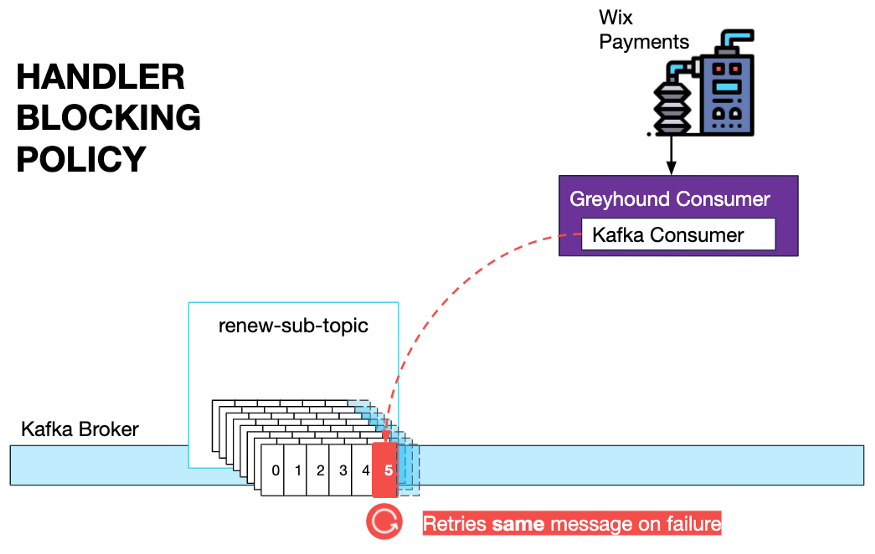
在某些情况下,消费者和生产者之间可能会产生延迟,如长时间持续出错。在这些情况下,有一个特殊的仪表板用于解除阻塞,并跳过开发人员可以使用的消息。
如果消息处理顺序不是强制性的,那么 Greyhound 中还有一个使用“重试主题”的非阻塞重试策略。
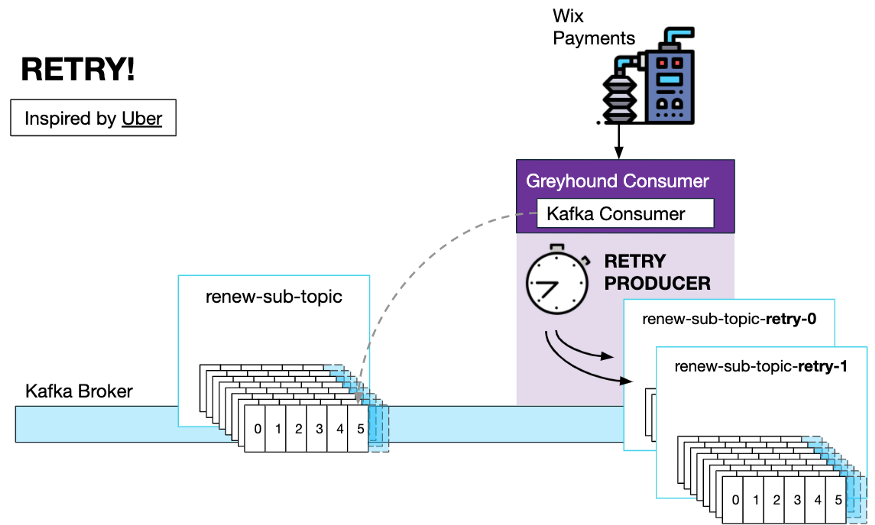
当配置重试策略时,Greyhound 消费者将创建与用户定义的重试间隔一样多的重试主题。内置的重试生成器将在出错时生成一条下一个重试主题的消息,该消息带有一个自定义头,指定在下一次调用处理程序代码之前应该延迟多少时间。
还有一个死信队列,用于重试次数耗尽的情况。在这种情况下,消息被放在死信队列中,由开发人员手动审查。
这种重试机制是受 Uber这篇文章的启发。
Wix 最近开放了 Greyhound 的源代码,不久将提供给测试用户。要了解更多信息,可以阅读 GitHub 上的自述文件。
总结:
Kafka 允许按顺序处理每个键的请求(例如使用 userId 进行续订),简化工作进程逻辑;
由于 Kafka 重试策略的实现大大提高了容错能力,续期请求的作业调度频率大大降低。
5.事务中的事件
当幂等性很难实现时
考虑下面这个典型的电子商务流程。
Payments 服务生成一个 Order Purchase Completed 事件到 Kafka。现在,Checkout 服务将消费此消息,并生成自己的 Order Checkout Completed 消息,其中包含购物车中的所有商品。
然后,所有下游服务(Delivery、Inventory 和 Invoices)将消费该消息并继续处理(分别准备发货、更新库存和创建发票)。
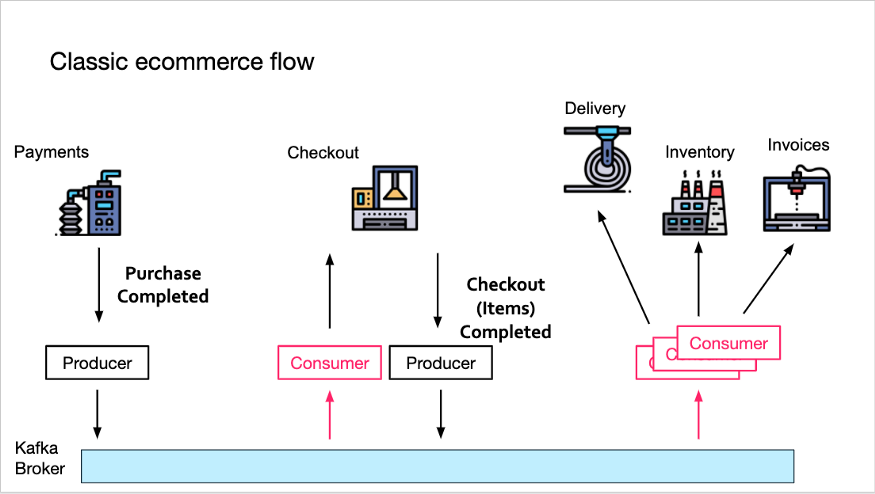
如果下游服务可以假设 Order Checkout Completed 事件只由 Checkout 服务生成一次,则此事件驱动流的实现会简单很多。
为什么?因为多次处理相同的 Checkout Completed 事件可能导致多次发货或库存错误。为了防止下游服务出现这种情况,它们将需要存储去重后的状态,例如,轮询一些存储以确保它们以前没有处理过这个 Order Id。
通常,这是通过常见的数据库一致性策略实现的,如悲观锁定和乐观锁定。
幸运的是,Kafka 为这种流水线事件流提供了一个解决方案,每个事件只处理一次,即使当一个服务有一个消费者-生产者对(例如 Checkout),它消费一条消息,并产生一条新消息。
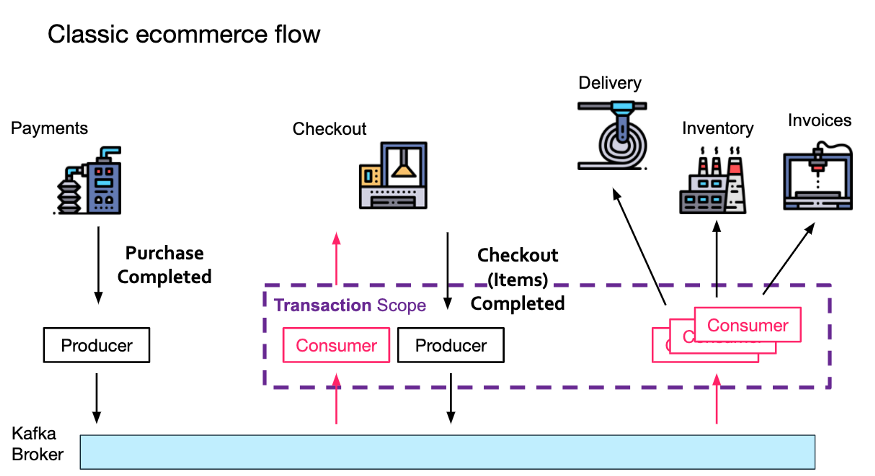
简而言之,当 Checkout 服务处理传入的 Payment Completed 事件时,它需要将 Checkout Completed 事件的发送过程封装在一个生产者事务中,它还需要发送消息偏移量(使 Kafka 代理能够跟踪重复的消息)。
事务期间生成的任何消息将仅在事务完成后才对下游消费者(Inventory Service)可见。
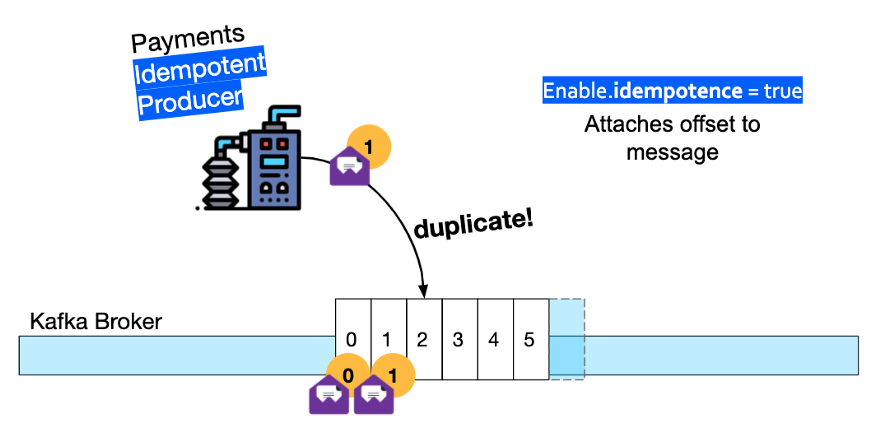
此外,位于 Kafka 流开始位置的 Payment Service Producer 必须转变为幂等(Idempotent)生产者——这意味着代理将丢弃它生成的任何重复消息。
要了解更多信息,请观看我的视频“Kafka中的恰好一次语义”。
6.事件聚合
当你想知道整个批次的事件已经被消费时
在上半部分,我描述了在 Wix 将联系人导入到 Wix CRM 平台的业务流程。后端包括两个服务。一个是作业服务,我们提供一个 CSV 文件,它会生成作业事件到 Kafka。还有一个联系人导入服务,它会消费并执行导入作业。
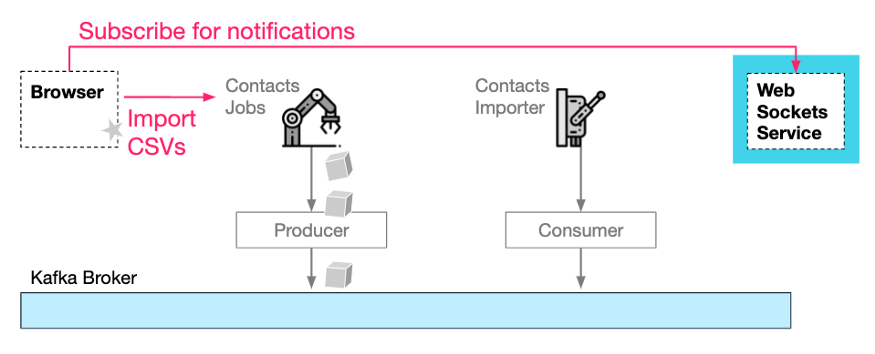
假设 CSV 文件有时非常大,将工作负载分割成更小的作业,每个作业中需要导入的联系人就会更少,这个过程就会更高效。通过这种方式,这项工作可以在 Contacts Importer 服务的多个实例中并行。但是,当导入工作被拆分为许多较小的作业时,该如何知道何时通知最终用户所有的联系人都已导入?
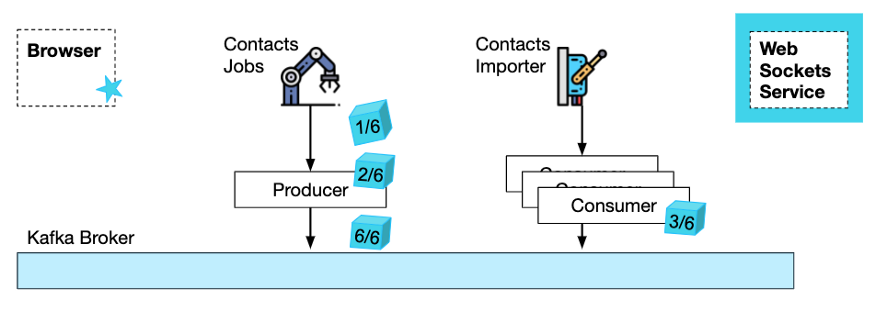
显然,已完成作业的当前状态需要持久化,否则,内存中哪些作业已完成的记录可能会因为随机的 Kubernetes pod 重启而丢失。
一种在 Kafka 中进行持久化的方法是使用 Kafka 压缩主题。这类主题可以看成是一种流式 KV 存储。
在我们的示例中,Contacts Importer 服务(在多个实例中)通过索引消费作业。每当它处理完一些作业,就需要用一个 Job Completed 事件更新 KV 存储。这些更新可以同时发生,因此,可能会出现竞态条件并导致作业完成计数器失效。
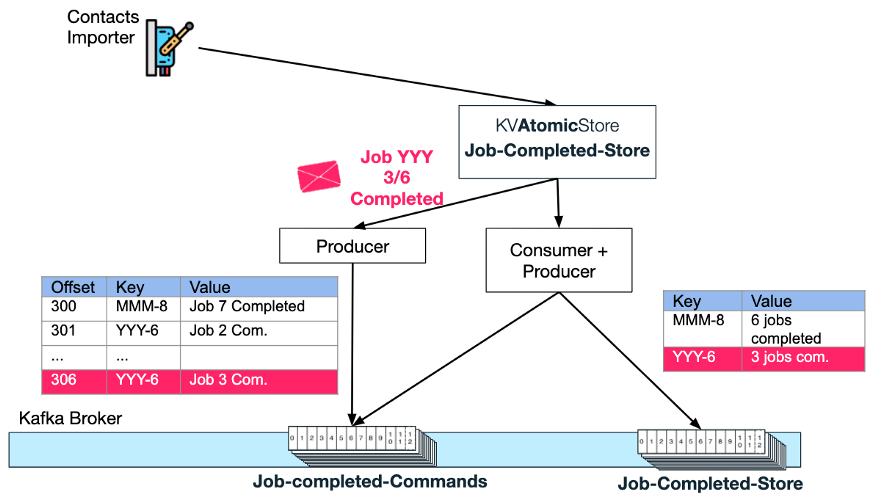
原子 KV 存储
为了避免竞态条件,Contacts Importer 服务将完成事件写到原子 KV 存储类型的 Jobs-Completed-Store 中。
原子存储确保所有作业完成事件将按顺序处理。它通过创建一个“Commands”主题和一个“Store”压缩主题来实现。
顺序处理
从下图可以看出,原子存储如何生成每一条新的 Import-job-completed“更新”消息,并以[Import Request Id]+[total job count]作为键。借助键,我们就可以总是依赖 Kafka 将特定 requestId 的“更新”放在特定的分区中。
接下来,作为原子存储的一部分,消费者-生产者对将首先侦听每个新的更新,然后执行 atomicStore 用户请求的“命令”——在本例中,将已完成作业数量的值加 1。
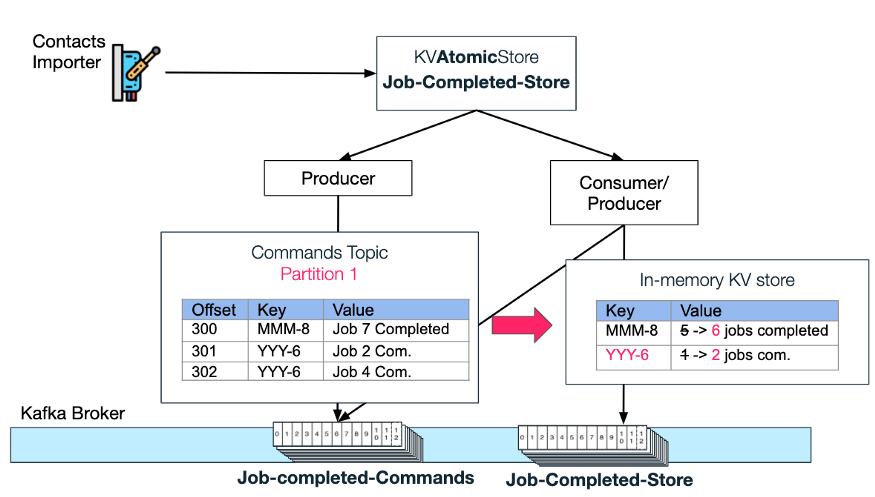
端到端更新流示例
让我们回到 Contacts Importer 服务流。一旦这个服务实例完成了某些作业的处理,它将更新 Job-Completed KVAtomicStore(例如,请求 Id 为 YYY 的导入作业 3 已经完成):
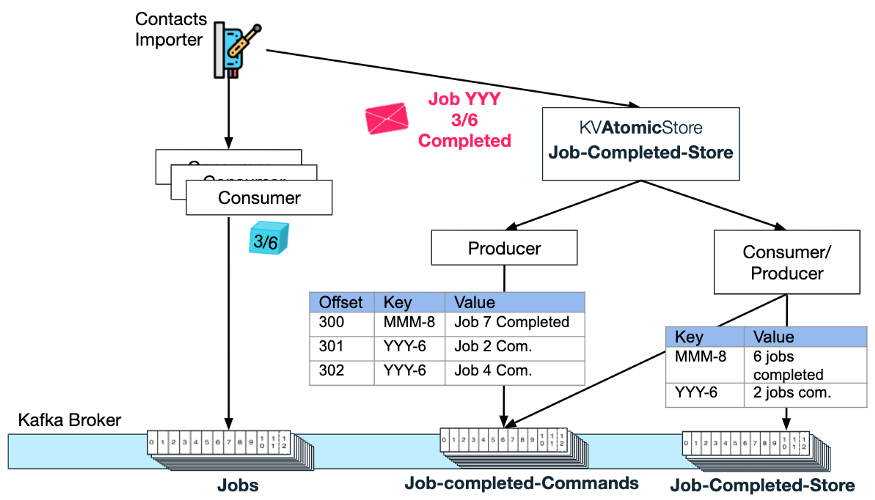
Atomic Store 将生成一条新消息到 job-completed-commands 主题,键为 YYY-6,值为 Job 3 Completed。
接下来,Atomic Store 的消费者-生产者对将消费此消息,并增加 KV Store 主题中键 YYY-6 的已完成作业计数。
恰好一次处理
注意,“命令”请求处理必须只发生一次,否则完成计数器可能不正确(错误增量)。为消费者-生产者对创建一个 Kafka 事务(如上文的模式 4 所述)对于确保统计准确至关重要。
AtomicKVStore 值更新回调
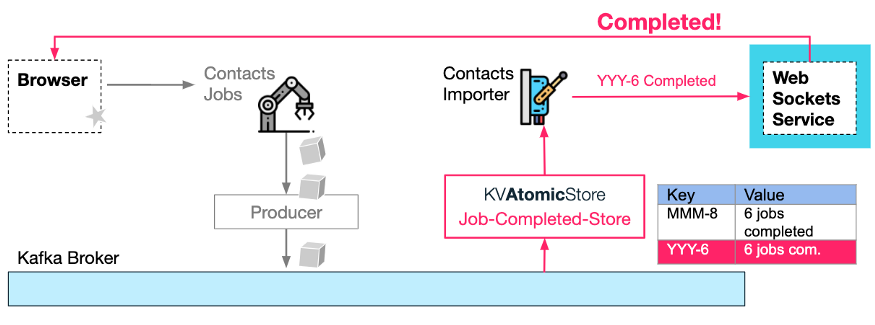
最后,一旦 KV 最新生成的已完成作业计数的值与总数匹配(例如 YYY 导入请求有 6 个已完成作业),就可以通知用户(通过 WebSocket,参见本系列文章第一部分的模式 3)导入完成。通知可以作为 KV-store 主题生成动作的副作用,即调用用户提供给 KV 原子存储的回调。
注意事项:
完成通知逻辑不一定要在 Contacts Importer 服务中,它可以在任何微服务中,因为这个逻辑完全独立于这个过程的其他部分,只依赖于 Kafka 主题。
不需要进行定期轮询。整个过程都是事件驱动的,即以管道方式处理事件。
通过使用基于键的排序和恰好一次的 Kafka 事务,避免作业完成通知或重复更新之间的竞态条件。
Kafka Streams API 非常适合这样的聚合需求,其特性包括 groupBy(按 Import Request Id 分组), reduce 或 count(已完成作业计数)和 filter (count 等于总作业数),然后是副作用 Webhook 通知。对于 Wix 来说,使用现有的生产者/消费者基础设施更有意义,这对我们的微服务拓扑影响更小。
总结
这里的一些模式比其他的模式更为常见,但它们都有相同的原则。通过使用事件驱动的模式,可以减少样板代码(以及轮询和锁定原语),增加弹性(减少级联失败,处理更多的错误和边缘情况)。此外,微服务之间的耦合要小得多(生产者不需要知道谁消费了它的数据),扩展也更容易,向主题添加更多分区(和更多服务实例)即可。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈