
再见!Redis!
事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。 事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的) 事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
noeviction:返回错误当内存限制达到,并且客户端尝试执行会让更多内存被使用的命令。 allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。 volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。 allkeys-random: 回收随机的键使得新添加的数据有空间存放。 volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。 volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。 Redis使用的是非阻塞IO,IO多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。 Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。 数据结构也帮了不少忙,Redis全程使用hash结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。 Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
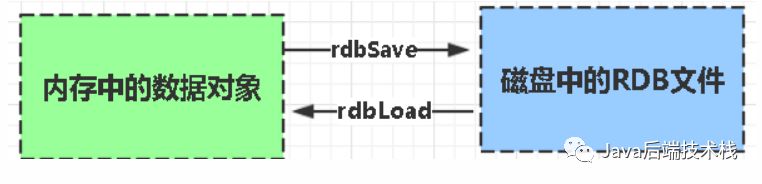
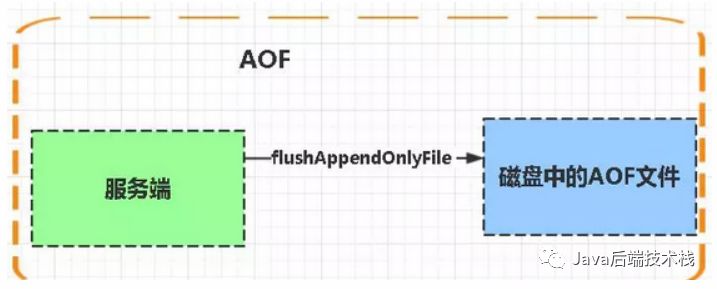
RDB(默认) AOF
评论