
Pandas0.25来了,别错过这10大好用的新功能
呆鸟云:“7 月 18 日,Pandas 团队推出了 Pandas 0.25 版,这就相当于 Python 3.8 啦,Python 数据分析师可别错过新版的好功能哦。”安装 0.25 版:
pip install pandas,就可以了。下面和大家一起看看新版 pandas 都有哪些改变。
一、四个置顶的警告!
- 从 0.25 起,pandas 只支持 Python 3.53 及以上版本了,不再支持 Python 2.7,还在使用 Python 2 的朋友可要注意了,享受不了新功能了,不过,貌似用 Python 2 做数据分析这事儿估计已经绝迹了吧!
- 下一版 pandas 将只支持 Python 3.6 及以上版本了,这是因为 f-strings 的缘故吗?嘿嘿。

- 彻底去掉了 Panel,N 维数据结构以后要用 xarray 了。说起来惭愧,呆鸟还没用过 Panel 呢,它怎么就走了。。。。

read_pickle()与read_msgpack(),只向后兼容到 0.20.3。上一篇文章刚介绍过read_pickle(),它就也要离我们而去了吗?-_-||
看完了这四大警告,咱们再看下 0.25 带来了哪些新东西。
二、新增功能
1. Groupby 的命名聚合(Named Aggregation)
animals = pd.DataFrame({'品种': ['猫', '狗', '猫', '狗'], '身高': [9.1, 6.0, 9.5, 34.0], '体重': [7.9, 7.5, 9.9, 198.0]})
animals
命名聚合示例,居然还支持中文诶!不过,这里是为了演示清晰才写的中文变量名,平时,该用英文还是要用英文的。
animals.groupby('品种').agg(
最低=pd.NamedAgg(column='身高', aggfunc='min'),
最高=pd.NamedAgg(column='身高', aggfunc='max'),
平均体重=pd.NamedAgg(column='体重', aggfunc=np.mean),
)
这么写看起来还是有些繁琐,很不 Pythonic,好在 pandas 提供了更简单的写法,只需传递一个 Tuple 就可以了,Tuple 里的第一个元素是指定列,第二个元素是聚合函数,看看下面的代码,是不是少敲了好多下键盘:
animals.groupby('品种').agg(
最低=('身高', min),
最高=('身高', max),
平均体重=('体重', np.mean),
)
这里还可以进一步偷懒,只写Pandas 提供了一种叫min或max,连单引号都不写了。
pandas.NameAgg 的命名元组(namedtuple),但如上面的代码所示,直接使用 Tuple 也没问题。这两段代码的效果是一样的,结果都如下图所示。
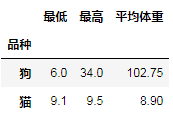
命名聚合取代了已经废弃的
dict-of-dicts 重命名方式,看了一下,之前的操作还真是挺复杂的,这里就不赘述了,有兴趣回顾的朋友,可以自己看下用 dict 重命名 groupby.agg() 输出结果(已废弃) 这部分内容。命名聚合还支持 Series 的 groupby 对象,因为 Series 无需指定列名,只要写清楚要应用的函数就可以了。
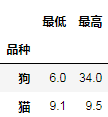
animals.groupby('品种').身高.agg(
最低=min,
最高=max,
)
更多有关命名聚合的介绍,详见官方文档 Named aggregation 。
2. Groupby 聚合支持多个 lambda 函数
agg() 函数传递多个 lambda 函数。为了减少键盘敲击量,真是无所不用其极啊!animals.groupby('品种').身高.agg([ lambda x: x.iloc[0], lambda x: x.iloc[-1]
])

animals.groupby('品种').agg([ lambda x: x.iloc[0] - x.iloc[1], lambda x: x.iloc[0] + x.iloc[1]
])

0.25 版前,这样操作会触发
SpecificationError。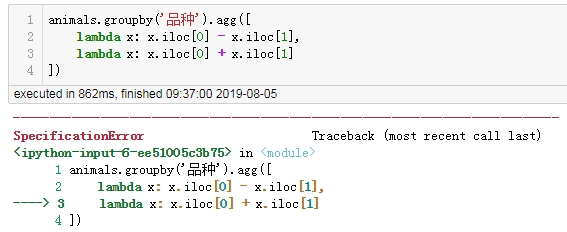
触发 SpecificationError
这个功能也有个小遗憾,多 lambda 函数的输出没有像命名聚合那样可以自定义命名,还要后面手动修改,有些不方便,不知道是我没找到,还是真没有……
3. 优化了 MultiIndex 显示输出
MultiIndex 输出的每行数据以 Tuple 显示,且垂直对齐,这样一来,MultiIndex 的结构显示的更清晰了。pd.MultiIndex.from_product([['a', 'abc'], range(500)])
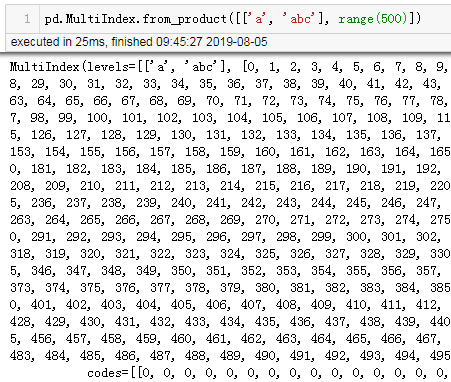
之前,是这样的
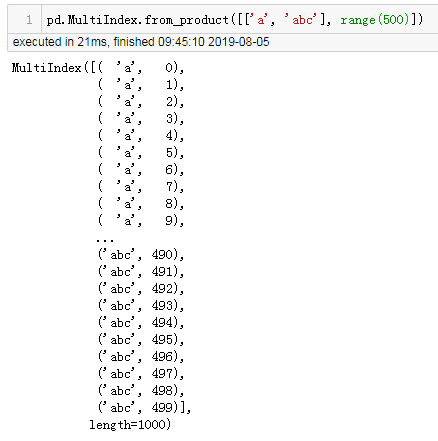
现在,是这样的
真是货比货得扔,以前没感觉,现在一比较,有没有觉得大不相同呢?
4. 精简显示 Series 与 DataFrame
display.max_rows 选项)。这种设置依然会占用大量垂直屏幕空间。因此,0.25 版引入了 display.min_rows 选项,默认只显示 10 行:- 数据量小的 Series 与 DataFrame, 显示
max_row行数据,默认为 60 行,前 30 行与后 30 行; - 数据量大的 Series 与 DataFrame,如果数据量超过
max_rows, 只显示min_rows行,默认为 10 行,即前 5 行与后 5 行。
最大与最小行数这种双重选项,允许在数据量较小时,比如数据量少于 60 行,显示全部数据,在数据量较大时,则只显示数据摘要。
要去掉
min_rows 的设置,可以把该选项设置为 None:pd.options.display.min_rows = Nonesales_date1 = pd.date_range('20190101', periods=1000, freq='D')
amount1 = np.arange(1000)
cols = ['销售金额']
sales1 = pd.DataFrame(amount1,index=sales_date1,columns=cols)
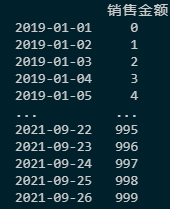
min_rows
在 VSCode 里显示正常,只显示了前 5 行与后 5 行,但貌似 Jupyter Notebook 6.0 目前貌似还不支持这个设置,还是显示前 30 行与后 30 行。图片太长,这里就不截图了。如果 Jupyter 可以的话,请告诉我。
5. json_normalize() 支持 max_level
max_level 控制参数。from pandas.io.json import json_normalize
data = [{ 'CreatedBy': {'Name': 'User001'}, 'Lookup': {'TextField': 'Some text', 'UserField': {'Id': 'ID001', 'Name': 'Name001'}}, 'Image': {'a': 'b'}
}]
0.25 以前是这样的,所有层级都读取出来了:
json_normalize(data)

0.25 以后是这样的,可以通过
max_level 参数控制读取的 JSON 数据层级:json_normalize(data, max_level=1)

6. 增加 explode() 方法,把 list “炸”成行
Series 与 DataFrame 增加了 explode() 方法,把 list 形式的值转换为单独的行。
df = pd.DataFrame([{'变量1': 'a,b,c', '变量2': 1},
{'变量1': 'd,e,f', '变量2': 2}])
df
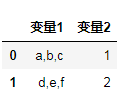
df.assign(变量1=df.变量1.str.split(',')).explode('变量1')

以后再拆分这样的数据就简单多了。具体官方文档说明详见 section on Exploding list-like column。
7. SparseDataFrame 被废弃了
SparseDataFrame(),生成稀疏矩阵,0.25 以后,这个函数被废弃了,改成 pd.DataFrame 里的 pd.SparseArray() 了,函数统一了,但是要多敲几下键盘了。0.25 以前是这样的:
pd.SparseDataFrame({"A": [0, 1]})
0.25 以后是这样的:pd.DataFrame({"A": pd.SparseArray([0, 1])})
输出的结果都是一样的: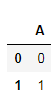
8. 对 DataFrame Groupby 后,Groupby.apply 对每组只处理一次
df = pd.DataFrame({"a": ["x", "y"], "b": [1, 2]})
dfdef func(group):
print(group.name) return group
df.groupby('a').apply(func)
有没有想到,0.25 以前输出的结果居然是这样的:
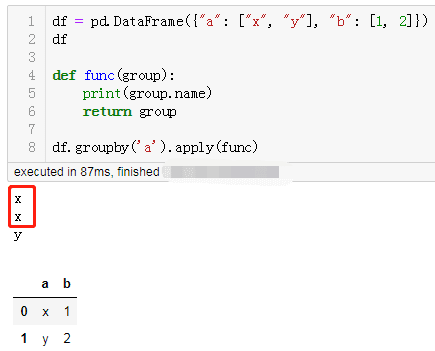
0.25以前
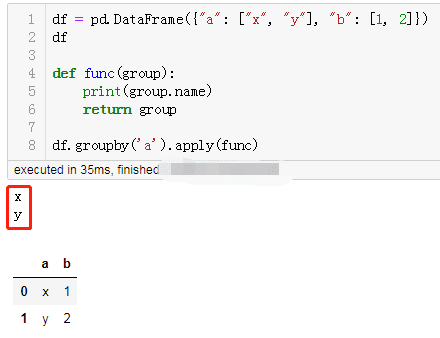
0.25以后
这样才正常嘛~~!
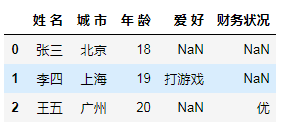
9. 用 Dict 生成的 DataFrame,终于支持列排序啦
data = [
{'姓 名': '张三', '城 市': '北京', '年 龄': 18},
{'姓 名': '李四', '城 市': '上海', '年 龄': 19, '爱 好': '打游戏'},
{'姓 名': '王五', '城 市': '广州', '年 龄': 20, '财务状况': '优'}
]
pd.DataFrame(data)
以前是乱序的,全凭 pandas 的喜好: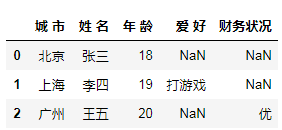
现在,我的字典终于我做主了!
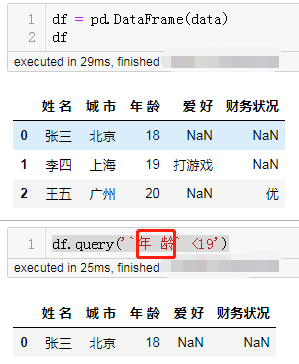
10. Query() 支持列名空格了
用上面的
data 生成一个示例 DataFrame,注意列名是有空格的。df = pd.DataFrame(data)
现在用反引号(`)括住列名,就可以直接查询了:
df.query('`年 龄` <19')
好了,本文就先介绍 pandas 0.25 的这些改变,其实,0.25 还包括了很多优化,比如,对 DataFrame GroupBy 后
ffill, bfill 方法的调整,对类别型数据的 argsort 的缺失值排序,groupby保留类别数据的数据类型等,如需了解,详见官方文档 What's new in 0.25.0。配套的 Jupyter Notebook 文件链接:https://github.com/jaystone776/pandas_answered/blob/master/10_New_Features_in_Pandas_0.25.ipynb。
点击 阅读原文,查看完整链接让我知道你“在看”

评论