
Redis 高负载排查记录
点击蓝字
2021
关注我们

网页监控
通过阿里的 Grafana 监控,服务器的 CPU 负载、内存、网络输入输出都挺正常的,所以肯定是 Redis 出现了问题。
我们应用使用的是单节点的 32M 16GB 的阿里云 Redis,登录网页监控看性能监控,发现 CPU 使用情况飙升到100%!!!
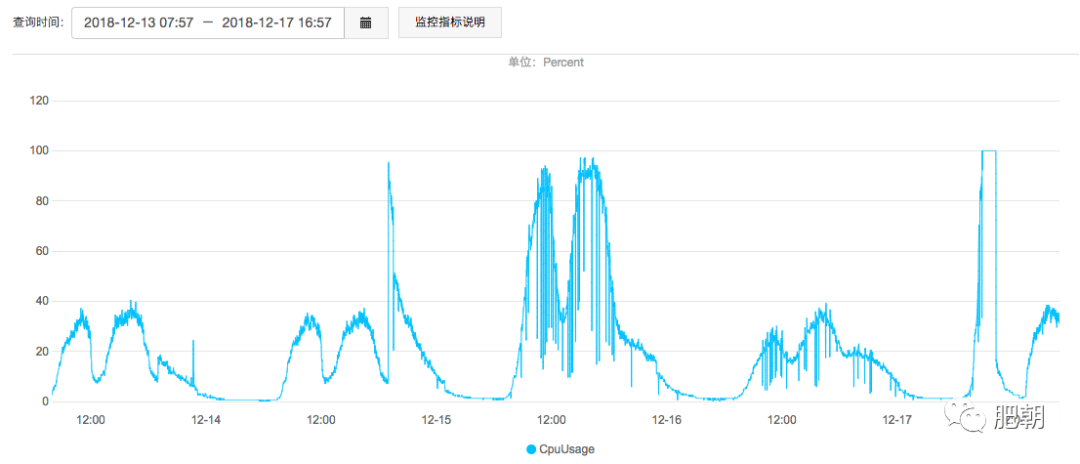
QPS 虽然从 1000 多升到 6000,但是远远低于极限值,连接数量从 0 升到 3000,也是远远低于极限值(可能用户刚上班,开始有请求,然后响应延迟,导致命令队列数量过多,打开很多连接)。
临时方案:先租用一台新的 Redis 服务器,更换应用服务器的 Redis 配置,重启应用,避免影响更多用户。
然后我们继续跟踪 Redis 的具体情况。
服务器命令监控
登录 Redis-cli,通过 info 命令查看服务器状态和命令统计,祥哥总结了两点异常点:
查询 redis 慢指令 slowlog,排行前十的指令均为keys *,并且耗时严重,在当前业务流量下执行keys* ,一定会阻塞业务,导致查询慢,cpu 高的。值得注意的是应用层面没有开放 keys * 接口,不排查有后台人为或后台程序触发该指令。
查看 redis 指令执行情况,排除 exec,flushall 等指令,业务使用指令中,耗时严重的有 setnx 有7.5千万次调用平均耗时 6s,setex 有8.4千万次调用平均耗时7.33s,del 有2.6亿次调用平均耗时69s,hmset 有1亿次调用平均耗时 64s,hmget 有6.8千万次调用平均耗时 9s,hgetall 有14亿次调用平均耗时 205s,keys 有2千万次调用平均耗时 3740s。
通常而言,这些指令耗时与 value 大小呈正比,所以可以排查这些指令相关的数据近期有没有较大增长。或者近期有没有业务改造,会频繁使用上述指令,也会造成 cpu 高。
(当时忘了截图,下图只是展示命令和参数含义)
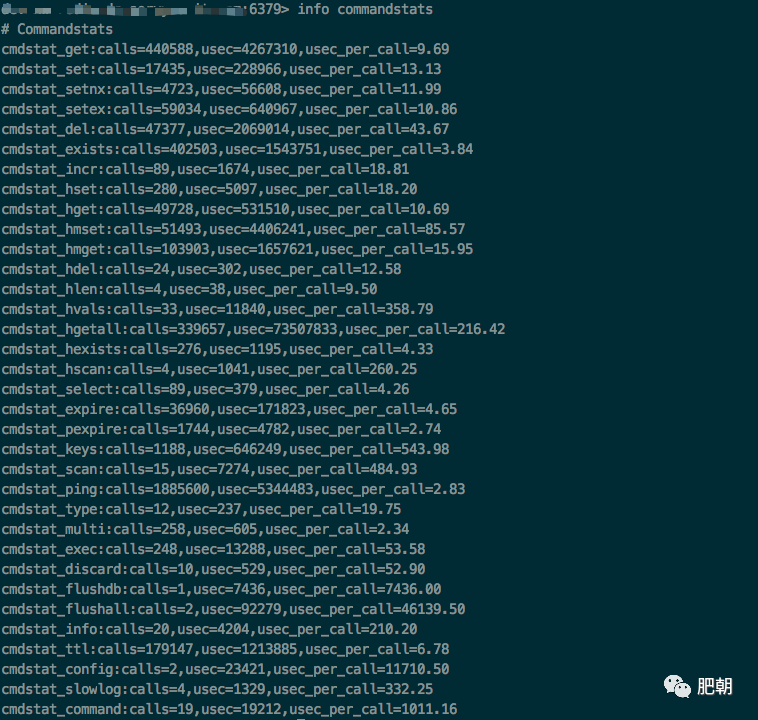
通过 info commandstats 可以查看 Redis 命令统计信息,其中命令格式是
cmdstat_XXX: calls=XXX,usec=XXX,usec_per_call=XXX
调用次数、耗费CPU时间、每个命令平均耗费CPU(单位为微秒)
通过 slowlog 命令查看慢命令(默认超过 10ms 就会被记录到日志,只会记录其命令执行的时间,不包含 IO 往返操作,也不记录单由网络延迟引起的响应慢)
(当时也忘了截图,所以就介绍一下 slowlog 怎么看)
xxxxx> slowlog get 10
3) 1) (integer) 411
2) (integer) 1545386469
3) (integer) 232663
4) 1) "keys"
2) "mecury:*"
图中各字段表示的是:
1=日志的唯一标识符 2=命令的执行时间点,以UNIX时间戳表示 3=查询命令执行时间,以微妙为单位,🌰中的是230ms 4=执行的命令,以数组的形式排列。完整的命令是 keys mucury:*
所以通过这些参数,基本可以确定,是突然有大量的keys *命令导致CPU负载升高,导致响应延迟,问题我们应用中没有开放keys *命令Σ(o゚д゚oノ)
最后将这些统计结果和慢命令发到研发群,发现是别的应用配置配成了我们的Redis,然后他们有个业务场景是爬数据,突然涌入大量的调用,不断的keys *,导致我们的Redis不堪重负,于是将配置修改正确,不再调用我们的Redis。
总结
Redis 抖动可以先看网页监控(阿里云做的真好!) 通过命令查看 Redis 指令状态和慢命令的情况 考虑优化 Redis 在代码中的使用情况 如果流量继续上升,需要考虑一下升级了=-=
来源:https://www.sevenyuan.cn
 有收获,点个在看
有收获,点个在看 