
分布式服务的幂等性设计,值得学习!

Java技术栈
www.javastack.cn
关注阅读更多优质文章
为什么需要保证幂等性
是否会导致最终创建了两条一样的订单? 是否会扣除两遍库存? 是否会重复扣除用户的钱?
唯一ID
就上面的幂等性下单接口来说,要做到幂等性,就需要借助一个唯一的ID来标志每次交易。唯一ID的分配可以有几种方式:
由一个统一的ID分配中心来分配。
由上游服务来生成唯一ID,但必须保证不产生冲突的ID。
采用统一的分配中心来分配唯一ID时,业务方每次调用接口都多了一次调用分配中心获取唯一ID的请求。这多了额外的开销。
获取唯一ID有一种方式,是借助mysql的自增索引,这其实也是一个ID分配中心。对服务性能有苛刻要求时,可以采用第二种方式,由主调服务本身来生成这个唯一ID。关注公众号Java技术栈可以获取MySQL系列教程。
为了保持不会产生重复的ID,可以使用一下几种ID生成方法:
UUID
UUID的全称是Universally Unique Identifier,通用唯一识别码。
具体可以看维基百科的介绍:https://en.wikipedia.org/wiki/Universally_unique_identifier
UUID是一个128bit的数字,用于标志计算机的信息,虽然UUID不能保证绝对不重复,但重复的概率小到可以被忽略。UUID的生成没有什么规律,为了保证UUID的唯一性,规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,以及从这些元素生成UUID的算法。这也就意味着:
128bit,占据了太多的内存空间
生成的ID不是人可以看懂的
无法保证ID的递增,某些场景需要按前后排序 无法满足。
这是一个在线生成UUID的网站:https://www.uuidgenerator.net/ 你可以直观感受一下UUID。
Snowflake
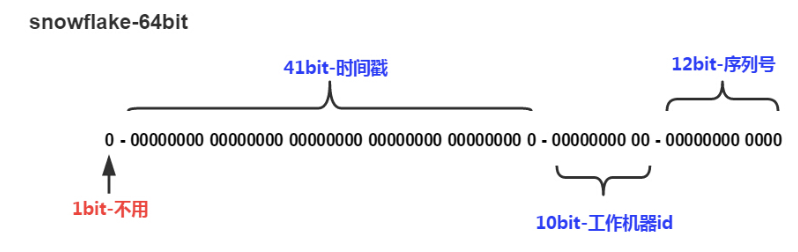
这是Twitter的一个开源项目,它是一个分布式ID的生成算法,它会产生一个long类型的唯一ID,其核心算法是:
时间部分:41bit作为毫秒数,大概可以使用69.7年
机器编号部分:10bit作为机器编号,支持1024个机器实例。
毫秒内的序列号:12bit,一毫米可以生成4096个序列号
网上有各种语言实现的Snowflake算法的实现,有兴趣的阅读一下实现代码。
实际上,redis 或是 mongoDB 的全局ID生成器的算法和Snowflake算法大同小异。这是基于redis的分布式ID生成器实现:https://github.com/hengyunabc/redis-id-generator
它的核心思想是:
使用41 bit来存放时间,精确到毫秒,可以使用41年。
使用12 bit来存放逻辑分片ID,最大分片ID是4095
使用10 bit来存放自增长ID,意味着每个节点,每毫秒最多可以生成1024个ID
共享存储
避免不必要的查询
insert into ... values ... on DUPLICATE KEY UPDATE ...作者:melonstreet
来源:https://www.cnblogs.com/QG-whz/
版权申明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。







关注Java技术栈看更多干货
