
该死,我又心动了,这都能行
大家好,我是假期努力肝文的 Jack。
多模态是近几年的热点,文本到图像的合成算法,更是卷上了天。
谷歌的 Imagen 超越 OpenAI 的 DALL・E 2,成为了新的 SOTA。
Imagen 文本到图像的生成可谓是天马行空,能够生成各种有趣的图片。
比如给 Imagen 算法输入:
一张背着旅行包的柴犬户外骑行照,它戴着墨镜,头顶沙滩帽。

泰迪熊的 400 米蝶泳首秀。

愤怒的小鸟。

Imagen 算法原理如下:
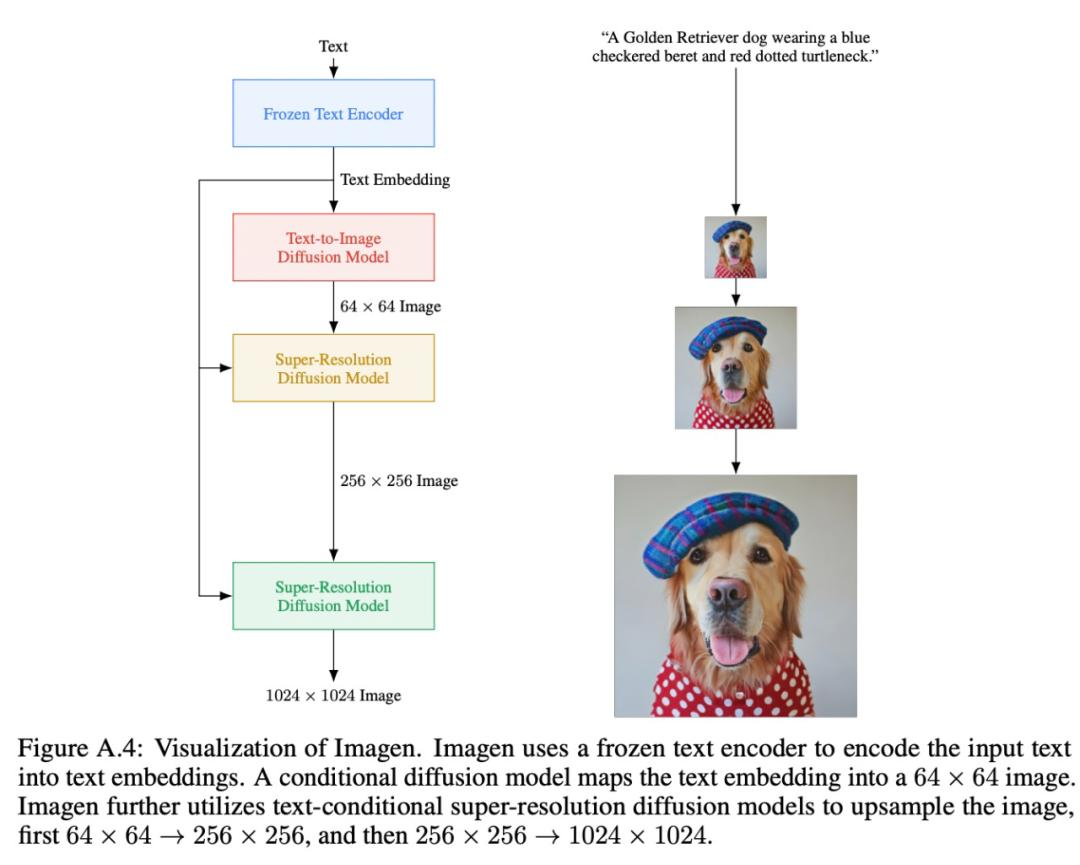
首先,算法会采用 frozen T5-XXL 编码器对接收到的文本进行编码。
输出送给文本转图像的扩散模型,并输入给两个超分辨率扩散模型。
文本转图像的扩散模型输出的图像分辨率是 64 * 64的,然后再经过两次超分,得到最终 1024 * 1024 的图像。
项目仓库 3 月份就建好了,不过直到 6 月,也就是这两天,才正式开源。
项目地址:
https://github.com/lucidrains/imagen-pytorch
对这类算法感兴趣的小伙伴,一定要去试试,效果提升很不错~
在我之前介绍 DALL・E 2 的就有小伙伴脑洞大开留言道:
既然能用文本生成图片,那是不是也能用文本生成视频?
CogVideo 它来了!
咱们先看下 CogVideo 的文本生成视频的效果。
一个视频都是根据一段文本描述生成的。
比如输入文本:
一个男人在海里奔跑。

CogVideo 算法会生成一系列的图片,最终生成视频。
CogVideo 算法的流程如下:
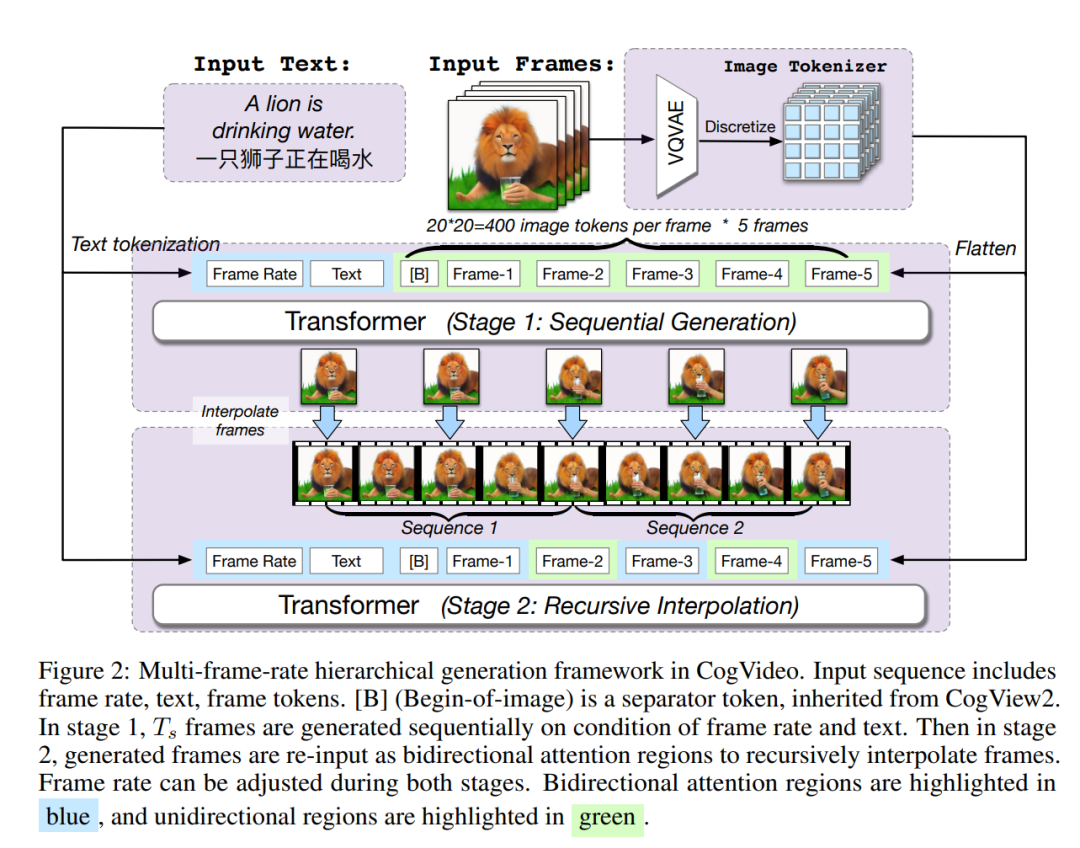
第一部分先基于CogView2,通过文本生成几帧图像,这时候合成视频的帧率还很低;
这个算法是文本生成图片的,大家可以在这里体验第一版的 CogView 效果:
https://wudao.aminer.cn/CogView/index.html
我试了一下,齐刘海的狮子,它可能理解不了,哈哈。
第二部分则会基于双向注意力模型对生成的几帧图像进行插帧,来生成帧率更高的完整视频。
给大家放几组效果,感受一下。

不过这个代码还没有开源,只是建了仓库,可以先 star 标记一下。
https://github.com/thudm/cogvideo
今天主要是介绍这类算法的进展,没教大家怎么部署环境,感兴趣的小伙伴,可以先自己根据 readme 进行配置。
行了,今天就聊这么多吧,我是 Jack,我们下期见!
