
pwru: 一款基于 eBPF 的细粒度网络数据包排查工具

pwru 是 Cilium 推出的基于 eBPF 开发的网络数据包排查工具,它提供了更细粒度的网络数据包排查方案。本文将介绍 pwru 的使用方法和经典场景,并介绍其实现原理。
安装部署
部署要求
pwru 要求内核代码在 5.5 版本之上,--output-skb 要求内核版本在 5.9 之上,并且要求内核开启以下配置:
| Option | Note |
|---|---|
| CONFIG_DEBUG_INFO_BTF=y | Available since >= 5.3 |
| CONFIG_KPROBES=y | |
| CONFIG_PERF_EVENTS=y | |
| CONFIG_BPF=y | |
| CONFIG_BPF_SYSCALL=y |
使用方法
Usage of ./pwru:
--filter-dst-ip string filter destination IP addr
--filter-dst-port uint16 filter destination port
--filter-func string filter kernel functions to be probed by name (exact match, supports RE2 regular expression)
--filter-mark uint32 filter skb mark
--filter-netns uint32 filter netns inode
--filter-proto string filter L4 protocol (tcp, udp, icmp)
--filter-src-ip string filter source IP addr
--filter-src-port uint16 filter source port
--output-limit-lines uint exit the program after the number of events has been received/printed
--output-meta print skb metadata
--output-relative-timestamp print relative timestamp per skb
--output-skb print skb
--output-stack print stack
--output-tuple print L4 tuple
案例演示
下图案例演示了 pwru 展现出快速定位出数据包被 iptables 规则 drop 掉的原因:

在不设置 iptables 规则之前:
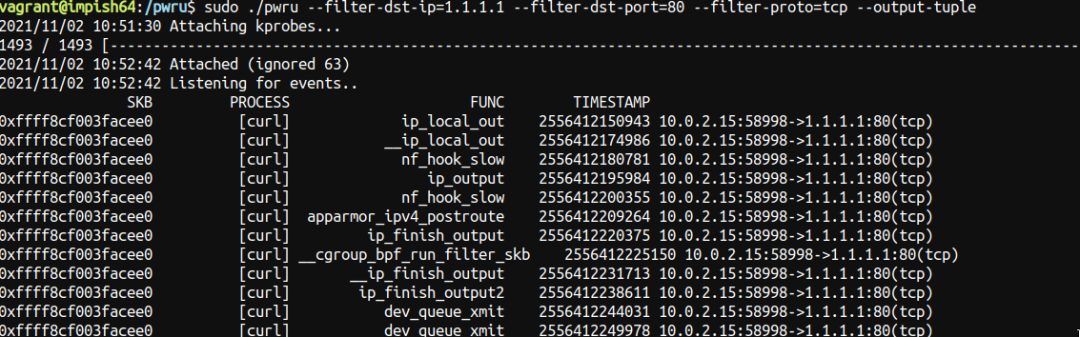
添加了 iptables 规则之后
iptables -t filter -I OUTPUT 1 -m tcp --proto tcp --dst 1.1.1.1/32 -j DROP
可以看到在 nf_hook_slow 函数后发生了变化:
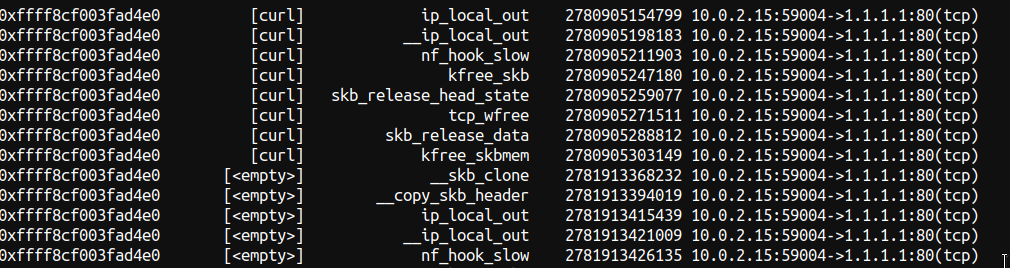
我们可以看到数据包在 nf_hook_slow 判决为 NF_DROP,调用了 kfree_skb
int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state,
const struct nf_hook_entries *e, unsigned int s)
{
unsigned int verdict;
int ret;
for (; s < e->num_hook_entries; s++) {
verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state);
switch (verdict & NF_VERDICT_MASK) {
case NF_ACCEPT:
break;
case NF_DROP:
kfree_skb(skb);
ret = NF_DROP_GETERR(verdict);
if (ret == 0)
ret = -EPERM;
return ret;
case NF_QUEUE:
ret = nf_queue(skb, state, s, verdict);
if (ret == 1)
continue;
return ret;
default:
/* Implicit handling for NF_STOLEN, as well as any other
* non conventional verdicts.
*/
return 0;
}
}
return 1;
}
原理实现
pwru 本质上是向 kprobe 注册了一些 eBPF code,根据 pwru 传入的参数可以更新 eBPF Map,改变限制条件,从而更新输出。
比如在 FilterCfg 里面制定了过滤的 IP 地址和协议等条件
type FilterCfg struct {
FilterMark uint32
//Filter l3
FilterIPv6 uint8
FilterSrcIP [16]byte
FilterDstIP [16]byte
//Filter l4
FilterProto uint8
FilterSrcPort uint16
FilterDstPort uint16
//TODO: if there are more options later, then you can consider using a bit map
OutputRelativeTS uint8
OutputMeta uint8
OutputTuple uint8
OutputSkb uint8
OutputStack uint8
Pad byte
}
会根据 pwru 传入的参数更新这个 eBPF Map
func ConfigBPFMap(flags *Flags, cfgMap *ebpf.Map) {
cfg := FilterCfg{
FilterMark: flags.FilterMark,
}
if flags.FilterSrcPort > 0 {
cfg.FilterSrcPort = byteorder.HostToNetwork16(flags.FilterSrcPort)
}
if flags.FilterDstPort > 0 {
cfg.FilterDstPort = byteorder.HostToNetwork16(flags.FilterDstPort)
}
switch strings.ToLower(flags.FilterProto) {
case "tcp":
cfg.FilterProto = syscall.IPPROTO_TCP
case "udp":
cfg.FilterProto = syscall.IPPROTO_UDP
case "icmp":
cfg.FilterProto = syscall.IPPROTO_ICMP
case "icmp6":
cfg.FilterProto = syscall.IPPROTO_ICMPV6
}
// ...
if err := cfgMap.Update(uint32(0), cfg, 0); err != nil {
log.Fatalf("Failed to set filter map: %v", err)
}
}
在 eBPF code 中,可以看到会读取配置 bpf_map_lookup_elem,然后进而执行真正的 filter:
struct config {
u32 mark;
u8 ipv6;
union addr saddr;
union addr daddr;
u8 l4_proto;
u16 sport;
u16 dport;
u8 output_timestamp;
u8 output_meta;
u8 output_tuple;
u8 output_skb;
u8 output_stack;
u8 pad;
} __attribute__((packed));
static __always_inline int
handle_everything(struct sk_buff *skb, struct pt_regs *ctx) {
struct event_t event = {};
u32 index = 0;
struct config *cfg = bpf_map_lookup_elem(&cfg_map, &index);
if (cfg) {
if (!filter(skb, cfg))
return 0;
set_output(ctx, skb, &event, cfg);
}
event.pid = bpf_get_current_pid_tgid();
event.addr = PT_REGS_IP(ctx);
event.skb_addr = (u64) skb;
event.ts = bpf_ktime_get_ns();
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &event, sizeof(event));
return 0;
}
可以看到,这里通过 bpf_perf_event_output 将过滤结果以 Perf event 传递上来。
rd, err := perf.NewReader(events, os.Getpagesize())
if err != nil {
log.Fatalf("Creating perf event reader: %s", err)
}
defer rd.Close()
// ...
var event pwru.Event
for {
record, err := rd.Read()
if err != nil {
if perf.IsClosed(err) {
return
}
log.Printf("Reading from perf event reader: %s", err)
}
if record.LostSamples != 0 {
log.Printf("Perf event ring buffer full, dropped %d samples", record.LostSamples)
continue
}
if err := binary.Read(bytes.NewBuffer(record.RawSample), binary.LittleEndian, &event); err != nil {
log.Printf("Parsing perf event: %s", err)
continue
}
output.Print(&event)
select {
case <-ctx.Done():
break
default:
continue
}
}
本文转载自:「 Houmin 的博客 」,原文:https://url.hi-linux.com/et8wH ,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。
链接:https://houmin.cc/posts/6a8748a1/
(版权归原作者所有,侵删)
评论