
漫话:如何给女朋友解释什么是熔断?





在《如何给女朋友解释为什么双十一无法修改收货地址》中我们介绍过关于QPS、RT、并发用户数以及最大线程数等知识。我们知道,如果一个软件系统的并发请求数目超过了系统的最佳线程数,那么就会导致激烈的资源竞争,随着资源的匮乏甚至枯竭,整个系统也就面临着灾难。
所以,很多软件系统为了保证即使在出现并发用户数>最佳线程数时,也不至于导致整个万网站崩溃,都会采用一些技术手段来避免发生系统性灾难。这些技术中比较典型的就是限流、降级和熔断。
这次就来讲讲什么是服务熔断,以及如何在微服务架构中做服务熔断。
为什么需要熔断现在很多网站的背后都是一个庞大的《分布式》系统,多个系统之间的交互大多数都是采用《RPC》的方式,但是因为是远程调用,所以被调用者的服务的可用情况其实是不可控的。
而越是庞大的系统,上下游的调用链就会越长,而如果在一个很长的调用链中,某一个服务由于某种原因导致响应时间很长,或者完全无响应,那么就可能把整个分布式系统都拖垮。
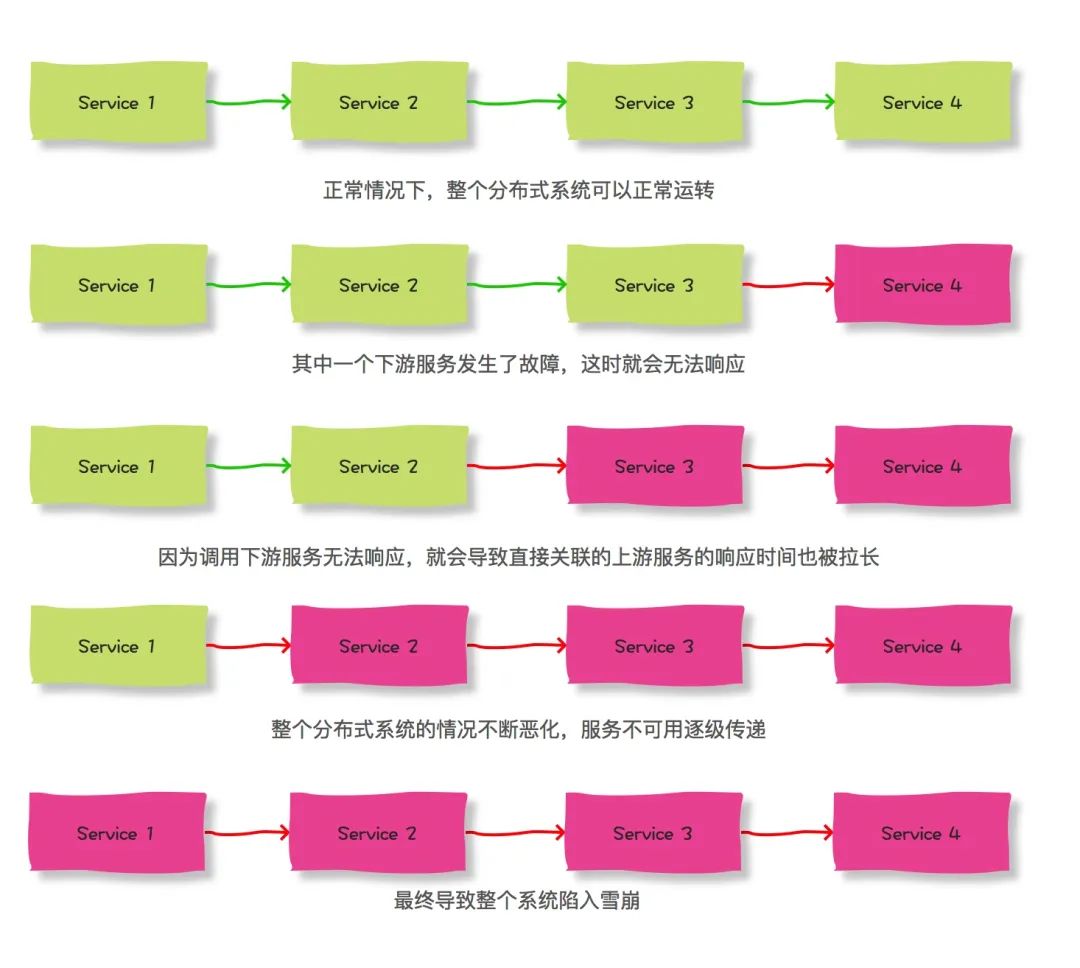
以上调用链,如果其中某一个服务由于自身原因导致响应很慢,那么就可能导致上游的服务影响也很慢,这样循环往复,就会导致整个系统全线崩溃,这就是服务雪崩。
其实,在分布式系统中,为了保证整体服务可用性和一致性,很多系统都会引入重试机制,在有些情况下,重试其实是可以解决问题的,比如网络问题等,都可以通过重试来解决。
但是,有些情况下,重试并不能解决问题,返而会加剧问题的严重性,比如下游系统因为请求量太大,导致CPU已经被打满,说着数据库连接池被占满,这时候上游系统调不通就会不断进行重试,这种重试请求,对于下游系统来说,无疑是雪上加霜,给下游系统造成二次伤害。
而分布式系统,大多数的服务雪崩也都是因为不断重试导致的,这种重试有可能是框架级别的自动重试、有可能是代码级别的重试逻辑、还有可能是用户的主动重试。
有些重试是无法避免的,而且如果因为防止雪崩,就不设计重试机制,也是一种因噎废食。






熔断器模式(Circuit Breaker Pattern),是一个现代软件开发的设计模式。用以侦测错误,并避免不断地触发相同的错误(如维护时服务不可用、暂时性的系统问题或是未知的系统错误)。
假设有个应用程序每秒会与数据库沟通数百次,此时数据库突然发生了错误,程序员并不会希望在错误时还不断地访问数据库。因此会想办法直接处理这个错误,并进入正常的结束程序。简单来说,
熔断器会侦测错误并且“预防”应用程序不断地重试调用一个近乎毫无回应的服务(除非该服务已经安全到可重试连线了)。
熔断器模式是方志微服务系统雪崩的一种重要手段。
一个比较完善的熔断器,一般包含三种状态:
关闭
熔断器在默认情况下下是呈现关闭的状态,而熔断器本身带有计数功能,每当错误发生一次,计数器也就会进行“累加”的动作,到了一定的错误发生次数断路器就会被“开启”,这个时候亦会在内部启用一个计时器,一旦时间到了就会切换成半开启的状态。
开启
在开启的状态下任何请求都会“直接”被拒绝并且抛出异常讯息。
半开启
在此状态下断路器会允许部分的请求,如果这些请求都能成功通过,那么就意味着错误已经不存在,则会被切换回关闭状态并重置计数。倘若请求中有“任一”的错误发生,则会回复到“开启”状态,并且重新计时,给予系统一段休息时间。
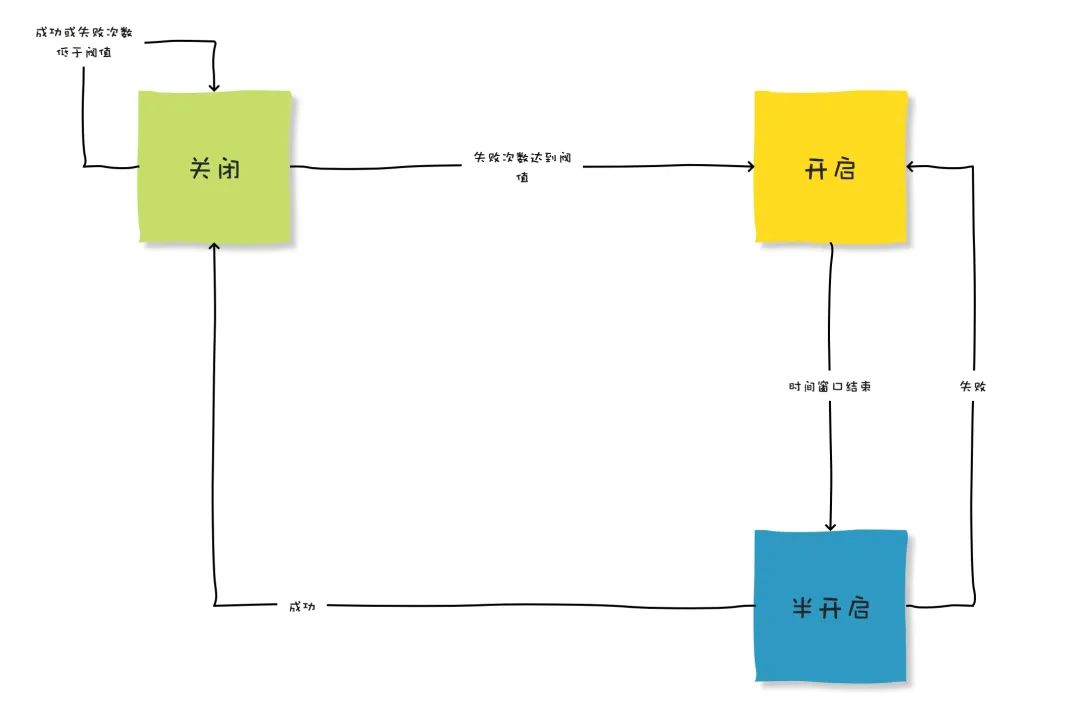
上图是熔断器的三种状态的转换情况。
如果在微服务系统的调用过程中,引入熔断器,那么整个系统将天然具备以下能力:
快速失败:当因为调用远程服务失败次数过多,熔断器开启时,上游服务对于下游服务的调用就会快速失败,这样可以避免上游服务被拖垮。
无缝恢复:因为熔断器可以定期检查下游系统是否恢复,一旦恢复就可以重新回到关闭状态,所有请求便可以正常请求到下游服务。使得系统不需要认为干预。




熔断器为了实现快速失败和无缝恢复,就需要进行服务调用次数统计、服务调用切断等操作,如果想要自己实现一个熔断器其实也是可以的。
但是,市面上有一些框架已经帮我们做了这些事情。如Hystrix和Sentinel、resilience4j等。
Hystrix
Hystrix(https://github.com/Netflix/Hystrix )是Netflix开源的一款容错系统,能帮助使用者码出具备强大的容错能力和鲁棒性的程序。提供降级,熔断等功能。
但是,在2018年底,Hystrix在其Github主页宣布,不再开放新功能,推荐开发者使用其他仍然活跃的开源项目。
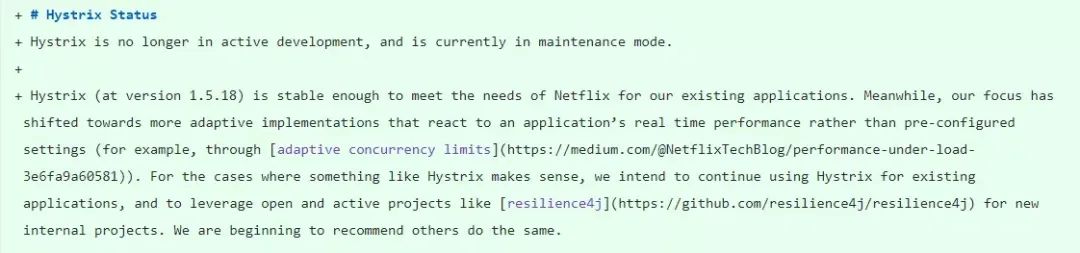
Hystrix虽然不再开发新功能 ,但对用户的影响应该不会太大,一是因为开发者可以继续使用Hystrix的最新版本1.5.18
resilience4j
Hystrix停更之后,Netflix官方推荐使用resilience4j(https://github.com/resilience4j/resilience4j ),它是一个轻量、易用、可组装的高可用框架,支持熔断、高频控制、隔离、限流、限时、重试等多种高可用机制。
与Hystrix相比,它有以下一些主要的区别:
Hystrix调用必须被封装到HystrixCommand里,而resilience4j以装饰器的方式提供对函数式接口、lambda表达式等的嵌套装饰,因此你可以用简洁的方式组合多种高可用机制
Hystrix的频次统计采用滑动窗口的方式,而resilience4j采用环状缓冲区的方式
关于熔断器在半开状态时的状态转换,Hystrix仅使用一次执行判定是否进行状态转换,而resilience4j则采用可配置的执行次数与阈值,来决定是否进行状态转换,这种方式提高了熔断机制的稳定性
关于隔离机制,Hystrix提供基于线程池和信号量的隔离,而resilience4j只提供基于信号量的隔离
Sentinel
Sentinel(https://github.com/alibaba/Sentinel )是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。
Hystrix 的关注点在于以隔离和熔断为主的容错机制,超时或被熔断的调用将会快速失败,并可以提供 fallback 机制。
而 Sentinel 的侧重点在于:
多样化的流量控制
熔断降级
系统负载保护
实时监控和控制台
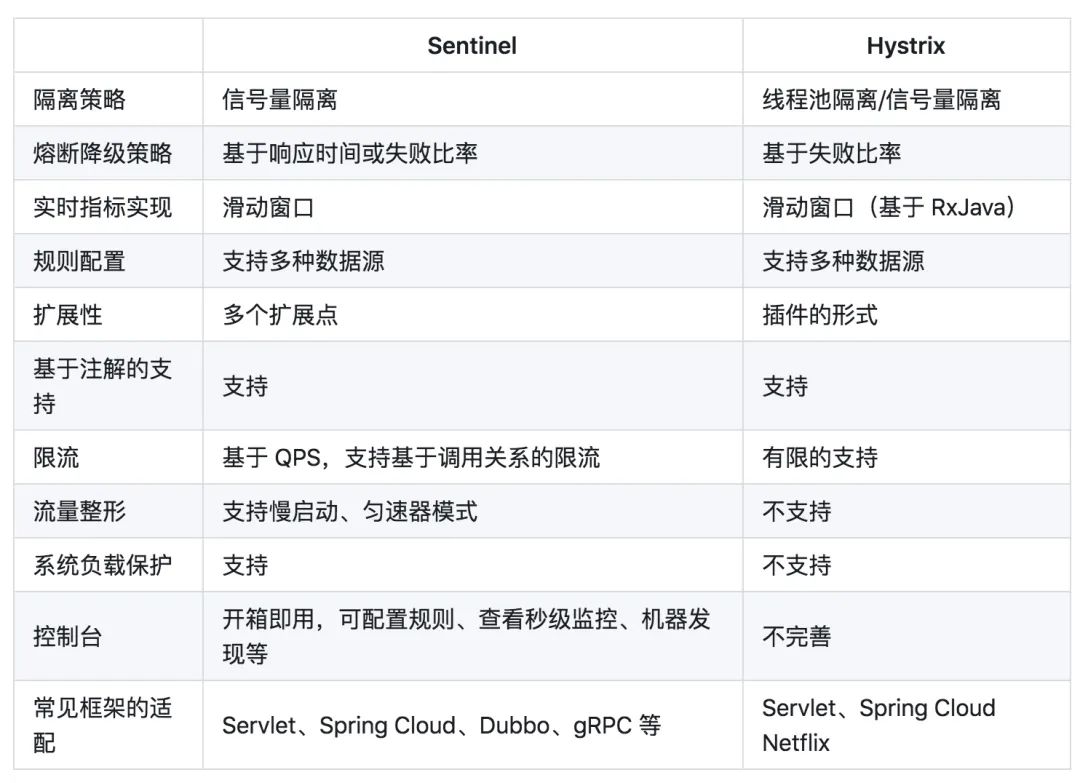
下图是Sentinel的GitHub主页中关于Sentinel和Hystrix的对比:




熔断机制:
指的是在股票市场的交易时间中,当价格波动的幅度达到某一个限定的目标(熔断点)时,对其暂停交易一段时间的机制。此机制如同保险丝在电流过大时候熔断比较相似,故而得名。
熔断机制推出的目的是为了防范系统性风险,给市场更多的冷静时间,避免恐慌情绪蔓延导致市场波动,从而防止大规模股价下跌现象的发生。然而熔断机制也因切断了资金的流通性,同样会造成市场情绪加大,并令市场风险在熔断期结束后继续扩大。
美国熔断机制:
美国指数熔断机制的基准指数为标普500,单项跌幅阈值为7%、13%、20%。当指数较前一天收盘点位下跌7%、13%时,全美证券市场交易将暂停15分钟,当指数较前一天收盘点位下跌20%时,当天交易停止。2010年美股又开始实行个股熔断机制。
熔断机制最早由美国的纽约股票交易所在1987年提出,以避免发生类似“黑色星期一”的股灾。此时的熔断机制仅针对大盘指数进行熔断。1997年10月27日,道琼斯工业指数暴跌7.18%,收于7161.15点,这是熔断机制在1988年引入之后第一次被触发。
美股第二次触发熔断机制是在美东时间2020年3月9日,受2019冠状病毒病疫情和油价崩盘影响,3月9日上午9点34分,标普500指数开盘后跌7%触发第一层熔断机制,暂停交易15分钟。3天后,3月12日,标普500指数开盘后短时间内跌幅超过7%再次触发第一层熔断机制。
中国大陆熔断机制:
中华人民共和国自2016年起开始在上海证券交易所、深圳证券交易所和中国金融期货交易所同时试行熔断机制。其熔断的基准指数是沪深300指数,设置5%、7%两档指数熔断阈值,涨跌皆熔断。
关于作者:漫话编程,是一个通过漫画+音频的形式讲解枯燥的编程知识的公众号。致力于让编程变得更有乐趣。
推荐阅读:
 喜欢我可以给我设为星标哦
喜欢我可以给我设为星标哦
好文章,我 在看
