
5分钟完全掌握正则表达式

前言
如果说什么是我学习编程来最好用,最常用的知识点,那应该就是正则表达式了。严谨的说,正则表达式并不是一门编程语言,也不是为了一种编程语言而服务的知识。但他确实足够好用,应用也足够广泛。
例如可以在文本中提取规则的电话号码,电子邮箱。在office中的通配符也是正则表达式哦,这样在office中做规则的搜索和替换,也是能极高的提升工作效率。
正则表达式在爬虫中也经常使用到,例如只需要简单的几行代码,就可以获取h1标签下的所有内容。
import re
html = '''
test1
test2
test3
'''
content = re.findall('(.*?)
', html)
print(content)
#result [' test1 ', ' test2 ', ' test3 ']
那正则表达式到底是什么,又该如何使用,为什么我们爬虫中老是使用(.*?),它到底起到了什么作用,这篇文章就详细告诉你。
什么是正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),听起来确实不是很好理解。
我们从这个定义中抽出三个关键词:
字符串:这个定义了使用的对象,也就是文本。 匹配:定义了用途,用于查找定位。 模式:模式其实就是规则,这就是正则表达式的核心,这里的规则是人为定义好的,可以是字符,数字和字母。
所以用大白话来说,正则表达式就是一些人为定义的规则,进行组合,使其具有快速匹配字符串的功能。
元字符
前面说到正则表达式就是一些定义好的规则的组合,这个规则背后就是元字符。
元字符有很多,我们按用途将他们分为5类,便于理解和使用。
集合:[ ] 次数:表示次数:* + ? {} 并列:| 提取:() 特定意义符号:. ^ $ \b\B
本篇文章的实例都在该网站上在线验证:https://regex101.com/ (1)集合([ ]) [ ]表示匹配所包含的任意一个字符,例如[Pp]ython,就能匹配Python和python。
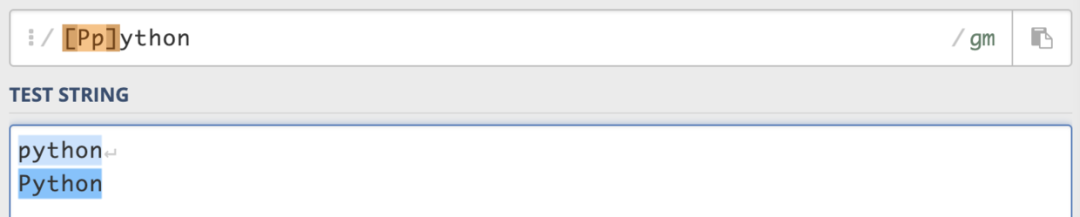
在集合中使用-,可以匹配一个范围内的字符,例如[a-z]可以匹配a到z任意一个字符。
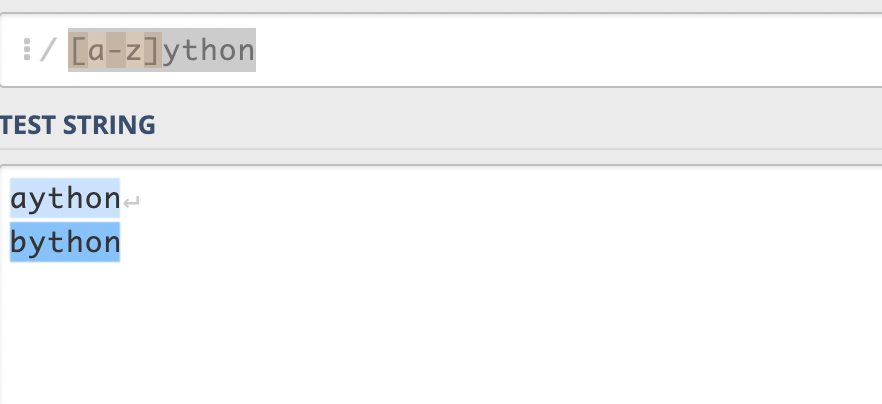
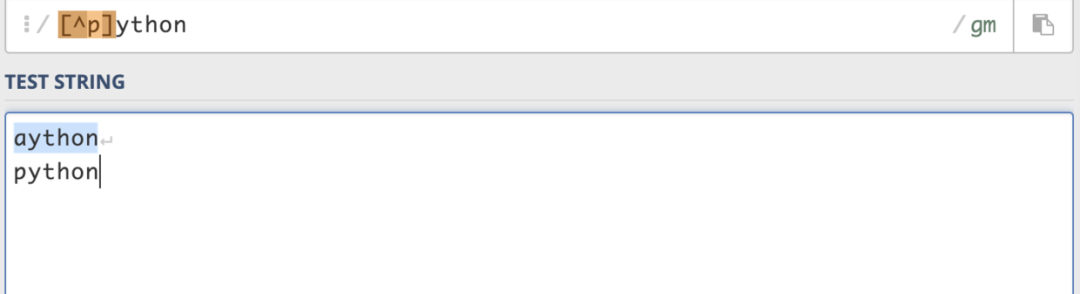
使用 ^ 可以匹配补集,例如[^p]ython,就能匹配除了p之外的字符。
(2)次数字符 上面的正则表达式只能匹配一个字符,这时你就需要次数相关的字符。
* 表示后面可跟 0 个或多个字符 + 表示后面可跟 1 个或多个字符 ? 表示后面可跟 0 个或 1 个字符 {n,m}表示后面可跟n到m个字符
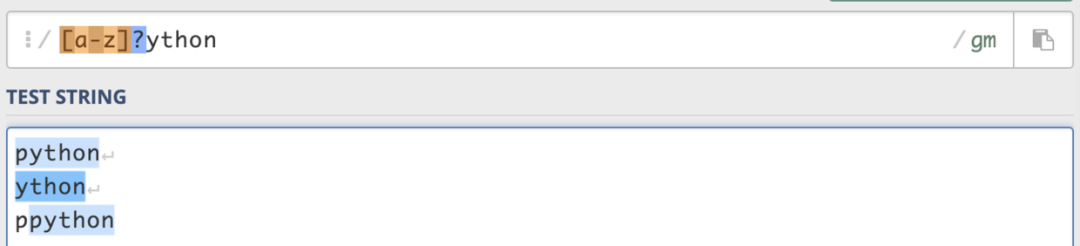
例如,匹配11个字符的电话号码。
这个使用方法很简单,大家多练习使用即可。但这里有一个很重要的知识点需要和大家讲解下。那就是贪婪模式和非贪婪模式。
以*为例,它可以匹配0个或多个字符,那到底是匹配多少个字符了?贪婪模式就是保证匹配成功的情况下,尽可能多的匹配,非贪婪模式则反之。默认情况下是贪婪模式,如果需要切换为非贪婪模式,就需要在*后面加上?号。
以
test
为例,如果我们使用<.*>,就会匹配到test
(.是匹配除换行符之外的任何单个字符)。
如果使用<.*?>,就会匹配到
和
。
(3)并列(|) 并列字符很好理解,当需要匹配两个字符中的一个的时候,就用|。A|B,匹配到了A,就不会查找B。
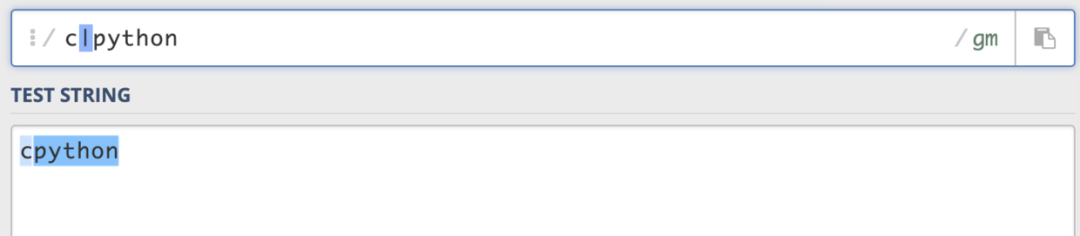
这里就是匹配到的就是c或者是python。
(4)提取() 如果需要把匹配的字符串提取出来,就需要使用小括号。这主要使用在编程中,对数据的提取。正如前面的爬虫代码,用上括号后,就能将h1标签中的内容提取出来。
import re
html = '''
test1
test2
test3
'''
content = re.findall('(.*?)
', html)
print(content)
#result [' test1 ', ' test2 ', ' test3 ']
在 () 中最前面加入 ?:,代表只匹配不获取(non-capturing)。
import re
html = '''
test1
test2
test3
'''
content = re.findall('(?:.*?)
', html)
print(content)
#result [' test1
', ' test2
', ' test3
']
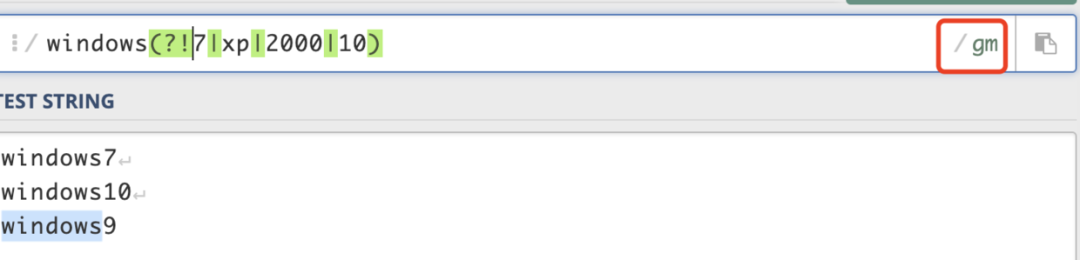
其实这里的?:是是非捕获元之一,还有两个非捕获元是 ?= 和 ?!,前者为正向预查,后者为负向预查。这两个又衍生出?<=和?
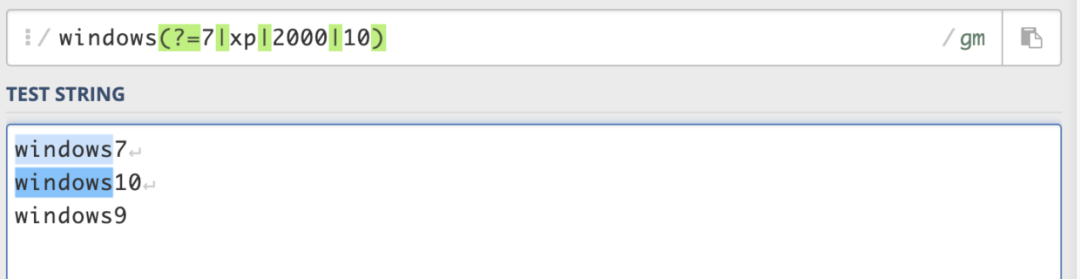
A(?=B),匹配符合B条件的A;(?<=B)A,匹配符合B条件的A。前者是匹配的是括号前面的,后者匹配的是后面的。
windows(?=7|xp|2000|10),能匹配windows7,windowsxp,windows2000,windows10前的windows。
A(?!B),匹配不符合B条件的A;(?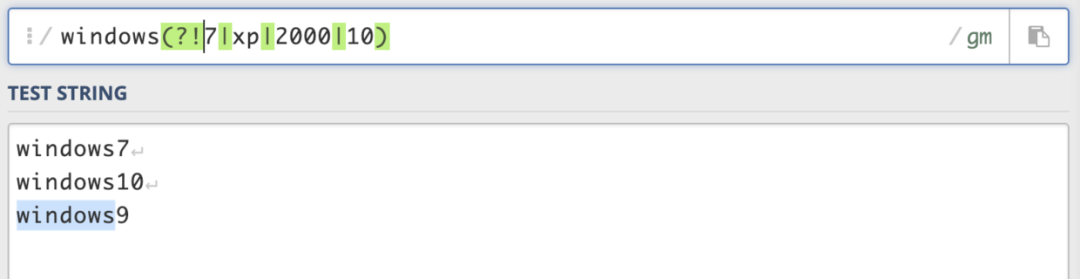
(5)特定意义符号 就是说固定的写法来代表特定的意义,例如\d代表的就是匹配一个数字字符,等同于[0-9]。
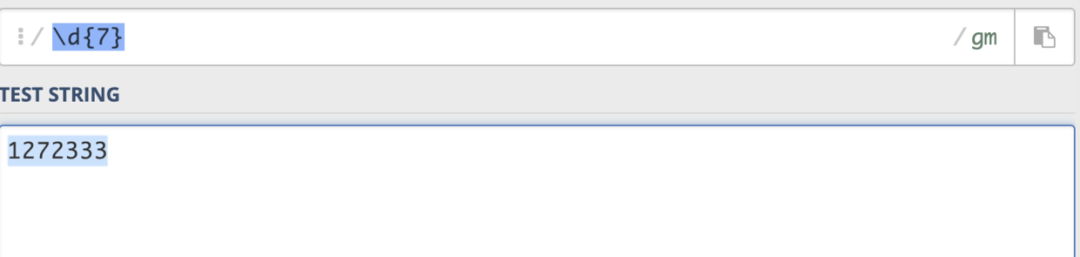
以下就是常用的特定意义符号:
| 字符串 | 含义 |
|---|---|
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符。 |
| \t | 匹配一个制表符。 |
| \v | 匹配一个垂直制表符。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 |
\为转义字符,例如\*,就可以匹配*本身。
修饰符(可选标记)
学完前面的元字符后,就算是完成了大部分正则表达式的知识点了,也能独立使用正则表达式来完成日常工作了。之前的截图中,可以看到gm,他们其实是修饰符。
修饰符不写在正则表达式里,标记位于表达式之外,我们来看下他们代表的意义。
| 修饰符 | 含义 | 具体解释 |
|---|---|---|
| i | ignore | 匹配时不区分大写小 |
| g | global | 全局匹配,查找所有的匹配项。 |
| m | multi line | 多行匹配,使边界字符 ^ 和 $ 匹配每一行的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
这期分享都到这了,下期我们讲正则表达式在日常工作中的使用案例。
更多阅读
特别推荐

点击下方阅读原文加入社区会员