
召奴-如何在 IDE 中针对海量数据做性能优化

点击上方蓝字关注我们
前端早早聊大会,前端成长的新起点,与掘金联合举办。加微信 codingdreamer 进大会专属周边群,赢在新的起跑线。
第二十九届|前端可视化专场,了解数据可视化/时空可视化/大屏/搭建/画布/等等的可能性,7-17 全天直播,10 位讲师(贝壳/奇安信/预策科技/蚂蚁/小米/阿里/阿里云/数字冰雹等等),点我上车👉 (报名地址):
所有往期都有全程录播,可以购买年票一次性解锁全部
正文如下
本文是第十八届 - 前端早早聊性能优化专场,也是早早聊第 127 场,来自 阿里 阿里云-召奴 的分享。
一、分享主题

我今天想要跟大家分享的主题叫做怎么样在 IDE 中去针对海量数据做性能优化。我先大概的讲一下,其实在我们的场景里面很多时候会面临到大数据的一个问题,大数据问题其实也是来自于我们的业务,我们的业务本身它就是一个要面对很多的数据,因为它可能需要对数据的整个内容去做开发,然后再去做一个报表呈现。所以在我们场景里面天然的就是跟海量数据每天在做一个奋斗的过程,我今天就会针对我们在 IDE 开发里面怎么去对海量数据的巨兽做一个性能优化的事情。
二、自我介绍
我是召奴,来自于阿里云的计算平台事业部,现在主要是负责 DataWorks 的云计算产品,云计算产品其实更多是给数据分析师和数据开发师,或者是一些跟数据开发,数据埋点相关的事情,所以我们有很多的产品都是跟大数据相关。
我目前也是在阿里云的前端影响力小组里面,也算干个杂活,就是帮忙去组织影响力,也会有一些定期的 conference 在内部的阿里云会议里面。这里是我的钉钉二维码跟我的微信二维码,如果有小伙伴对于今天的主题,或者是跟前端相关的事情,甚至说想要跟我聊聊都可以,可以加我的微信或者我的钉钉。
三、分享目录
我先大概说一下今天会讲的几个环节,第一个是讲一下 IDE,什么是 IDE ?然后 IDE 它的整个历史发展,再去讲一下现阶段我们的 IDE 它是什么情况,以及未来我们觉得说 IDE 可能朝什么地方去做发展,先跟大家有一个宏观的了解,知道 IDE 它整个一个從古至今的情况。
接下来我们会讲一下现在 IDE 它面临什么挑战,这个挑战会带来我们之后怎么去做一个发展,或者说怎么去走下一步,接下来会进入到第三个环节,就是在我们的场景里面怎么样去直迎这个挑战,然后怎么把我们的体验去做一个提升,最后会跟大家说一下我们将来的一些规划和其他的一些环节。
四、戏说 IDE
什么是 IDE?

先来看一下第一个什么叫做 IDE,IDE 有两个英文解释,第一个英文解释是来自于 Wikipedia 就是维基百科,它里面所摘录的一段话,我们可以简单看一下。首先什么叫做一个 IDE,它是这么描述的,整合式的一个开发环境,它是一种一站式的开发环境,它会帮助开发者去可视化的进行软件开发。我们可以把这一段话去拆解成几个Behavior,这 Behavior 包含第一个它是一站式的一个服务,第二个它是为开发者去做一个事情的,第三个它是可视化的,第四个它是开发软件用的,它会有这 4 个特性。
了解特性以后,我们要知道到底我们在 IDE 里面还会有哪些功能,第二段话它就描述 IDE 的功能,就是在开发的过程中它通常会包含几个要件,第一个它可以写代码,再来可以做一个运算的过程,可以做一个构建,最后你可以做一些 Debug 的事情,我们就把它拆解出来,它的功能大概有 4 大类,第一个就是说它可以写代码,然后它需要可以运算,它需要可以构建,并且它可以做 Debug 的事情。

刚讲完的是对于 Wikipedia 的描述,现在我们从 VSCode 来看一下现在的 IDE 普世来说长什么样子,它会有一个编辑区域,就刚刚提到一个很重要的功能,要能写代码,再来它可以做一些 compile 的事情跟一些 build 的事情,所以它需要有一个终端去跟我们的 PC 做一些沟通,比如说我要下指令,然后我要去做这些 compile 的事情。同时有一个目录树去让你做一些文件管理的一个工具,你可以在里面去新建很多的文件,最后一个侧边栏,侧边栏的话,它可能是一些扩展程序,或者是一些比如说像 VSCode 里面,它就有这一个 commit 的一些记录。
这个是我们现在普世所看到的一些 IDE 的形式,当然每一家的 IDE 可能都有一些不一样的地方,像 Eclipse 上面还会有一些插件化的东西。这大概就是我们从可视化的一种方式去看,IDE 它是长什么样子,实际上 IDE 也给大科普,但其实大家都是程序员,天天都在用 IDE,所以也可以看一下自己的 IDE 大概 making 一下刚刚的这一些拆解跟内容,看看是不是就是这个样子。

接下来看一下 IDE 从以前到现在它的发展过程,我们要從古至今,要知道原来 IDE 它不只是现在我们看到的这个样子,它可能是前人积累了很多的一个过程。从这个图上面来看,其实 IDE 这个词它最早出现在 1964 年一个叫做basic 的系统,在以前可能大家只是说我有打卡机,可能每次我要运算一行代码,我就要好几张打卡纸,然后在这个机器里面还不是可视化的,你就只能自己打好,自己觉得说 ok 没问题,然后就进去算,算完之后它可能带来一大堆复杂的运算跟庞大的工作站,它就算完之后给你一个答案,你可能中间的构成全部是黑盒,你不知道什么情况,从Basic 出来以后它就打破了以前这种非常不可视化,或者是说你没有办法去看到这个内容的一个过程。
Basic 它是可以在终端里面去做一些简单编写代码的过程,但它跟我们现在的 IDE 其实有一点区别就是它的编译过程它不算是这一种,它没有上下文关系,它基本上就是你一行代码它就帮你编译这行代码,然后下一行代码跟上一行代码有没有关系,它就是这样一行一行去看,所以它没有办法写一些复杂的逻辑,比如说 for 或者是 if 这种判断逻辑,它可能在 Basic 里面它是做不到的,你可以理解为它就是现在的终端可能比现在的终端还要低级的一个编译器,但是这个东西在 1964 年根本就是奇迹,因为在这之前你可能连一个界面都没有,原来写代码还可以可视化的去写,这个对于那时候来讲就是一件不可思议的事情。
后来在 1964 年以后中间有一段时间,实际上是有一些其他的 IDE 出来,但是它的过程或者说它的内容都跟 Basic差不了太多,直到 1983 年的 TurboPascal 出来以后,它就是一个可以脱离这种直译式的,有 compile 的一个过程在里面,到 1989 年的时候,Softbench 的时候,它就是一个就是成熟的方案,但是 Debug 的过程可能还是没有。
真正的到跟我们现在的 IDE 非常接近的一个软件出来是在 1991 年 Visual Basic,可能也有同学碰过就是 VB,但VB 语言的话,它除了你可以写代码以外,它还有一个图形界面出来,这个可能也是在 IDE 里面很早就出现的一个搭建平台,你可以把按钮,input 框等直接就可以通过拖拽的方式去呈现出它的页面,再去编写里面的代码。大概在 1991 年的时候,Visual Basic 是真正开始进入完全可视化搭建的一个过程,它不但可以敲代码,还可以拖拽展示界面,可以说它是比较特立独行的,因为发展至今 IDE 的历史也没有朝这个方向去发展。
后来这种可视化拖拽的 IDE 后来就没有再跟它类似的,当然微软体系里面还是有,但是慢慢的就没落下来,不太有人会去用这个方式,所以后来的几款就跟这个内容比较不一样,比如说 Delphi,然后再就是 NetBeans,Eclipse 跟IDEA,在 XCode 开始就是进入到 IDE 全胜时期,直到 2008 年,2008 年是下一个 IDE 的突破口,开始出现了所谓的 ODE,什么叫 ODE 就是 online development environment,它是一个在网页上面就可以去做 compile 或者是写代码的一个事情,这个是从 JSBin 开始的。
ODE 以后就开始出现了比如说 JSFiddle,再来像是 Codepen 这种 ODE 的内容,当然在这个过程台基式的 IDE 还继续发展,比如说著名的 Cloud9,Android Studio,Atom 跟 2015 年的 VSCode 也算是一个突破,真正到我认为现今为止,下一个突破口是 2019 年的 VSCode online。
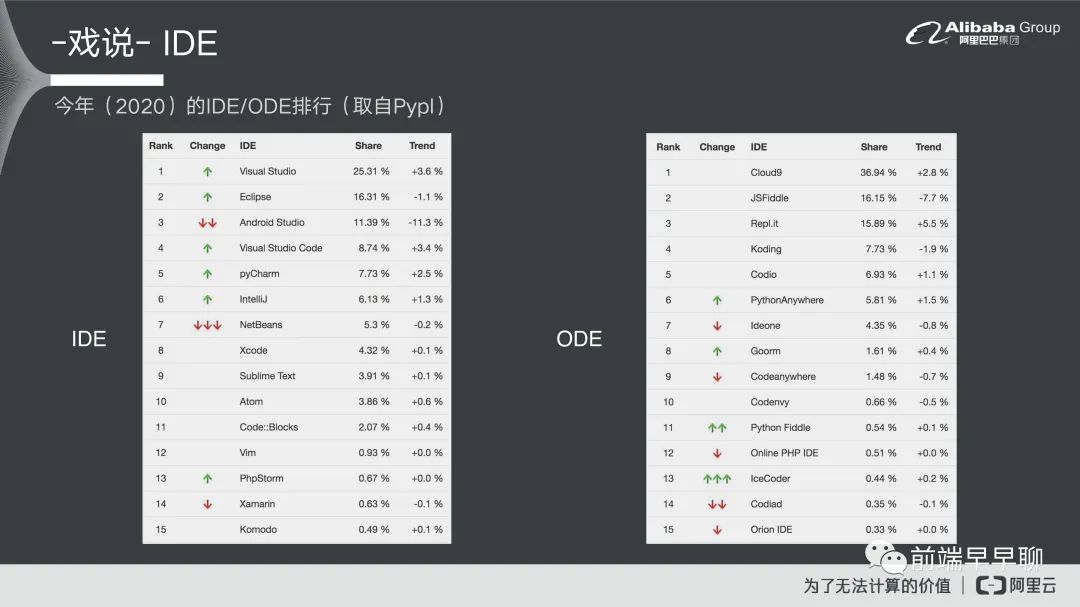
我们来看一下今年的 IDE 排行榜,了解一下你现在用的 IDE 它的排行是怎么样子,我们可以看一下,以IDE 来说的话,我指 IDE 这里就是指台基式的,它现在第一名的还是 Visual Studio 就是微软体系的部分,第二名是 Eclipse,它现在还是一个上升的趋势,再来是 Android Studio,它今年是整个下滑而且下滑得比较厉害。另外一个黑马是 VSCode,自从它上来以后年年不停往上升,其他的还有 PyCharm、IntelliJ、NetBeans 等。
ODE 的部分我们也可以看一下。目前第一名排行的是 Cloud9,Cloud9 是亚马逊并购了别人以后再进行开发的一个工具。他现在是第一名,跟前几年基本上没怎么变,他出来以后基本上就一直在第一名的位置。然后第二名是 JSFiddle,再是 Relp.it 然后 Koding,再然后 Codio 等等。这个可以看出来现在整个 IDE 跟 ODE 里面,它的一些龙头产品是哪一些,这个资料是取自于 Pypl,如果有兴趣大家也可以去查一下,看一下今年的排行是怎么样子。

我们也看一下阿里现在的 IDE 战场,在阿里里面实际上我们对于 IDE 是遍地开花,在不同场景在不同的领域里面会有 IDE 的一个应用,我们举一些比较常见的或者说有名的例子,第一个是开天(KAITIAN)是阿里集团公认的 IDE 底层框架,很多的 IDE 产品都是基于它去做一个衍生。
第二个是德芙(DEF),德芙在我们内部里面它算是一个重的 CI 或者说是一个 DI 工具,它在里面会有很多的 IDE 交互。
第三个 Ant Codespaces 是蚂蚁集团在使用的主要编辑器,它主要是用于 CI 跟 DI 工具跟一些数据开发的一个过程。
然后是 DataWorks,在阿里集团里面它算是数据开发领域里面标杆型的产品,就是说目前在阿里集团里面没有比它出名或者好用的数据开发工具。再是 Riddle 在阿里里面做前端的代码演示,或者是一些简单代码撰写的一些 ODE 线上工具,最后是 Aone IDE,这个是我们在做需求管理的一个平台,那里面也会有 IDE 的一个需求,这大概是整个阿里集团目前的 IDE 的情况。
IDE 的下一步发展是什么?

IDE 它下一步的发展,大家觉得应该是一个什么样的情况?我认为是 Cloud Native IDE 就是一个云原生的 IDE,为什么会有这个看法?当然也不是我说的,这个是来自于在今年的云原生大会它里面提出的一个论点。就是说将来我们的开发过程会慢慢的移步到云端的过程,所有的这些开发资源我们都会朝云端去做一个集中,从数据库编码到整个开发的过程都会在云上面去做执行,所以我们的 IDE 它就会占在开发过程里面前端的一个重要角色。我认为他就是下一代的 IDE 的走势。
这个是云原生大会他所说的一些内容,但是我们也可以有一些合理的怀疑,它有包含的几个项目:
第一个就是 Serverless 崛起,它意味着说我们以后上云可以更容易,所有的资源都可以更好的被集中,比如说我现在要调一个服务,我直接一个 Function Call,然后我可以用 4 个网路上所有的网络资源找你付费,这样的话我们把所有的资源都开始往云上集中; 第二个是 IDE 的大头开始转型,最直接的例子就是微软 VSCode 开始做 VSCode online,再来是亚马逊去收购 Cloud9 这个事情; 第三个是最近才发生的,Chrome 在 86 版本,支持本地文件读取,对于本来桌面端跟网页端隔离的过程,可以透过浏览器去直接读取本地的文件,比如可以直接把本地文件拉到网页里面,然后开始做一些编译的过程都可以想象。
五、筑基艰难
筑基艰难·挑战
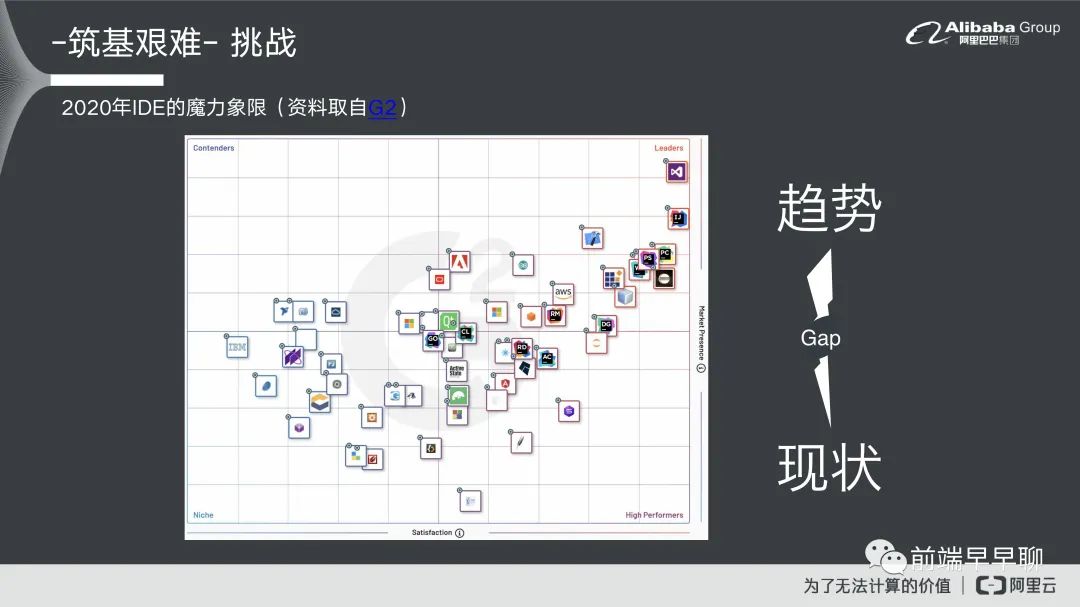
我们看一下现在的发展趋势,2020 年 IDE 的魔力象限。这个资料是取自 G2 的页面,如果大家有兴趣可以去看一下。现在的整个 IDE 发展的领导者地位基本上第一名还是 VSCode,但这个是桌机板,不是 ODE 的部分,第二名是IntelliJ,然后是 PyCharm 跟其他的这些工具 XCode 等等,整个大图里面你觉得哪一个是 ODE?
唯一的一个 ODE 是 AWS 的 Cloud9,它是唯一一个在领导者上线里面出现的 ODE 的产品。这个说明什么?虽然在大家的认为里面ODE 是未来的趋势,但实际上大家都没有正式的去用起来,它还不具有市场的占有性,或者大家都觉得还是观望的一个态度,为什么会有这个情况?它实际上在趋势跟现状之中是存在一个 GAP 的,可能因为市场预期或者大家的一个满意度还达不到,所以他没有办法进入领导者象限。
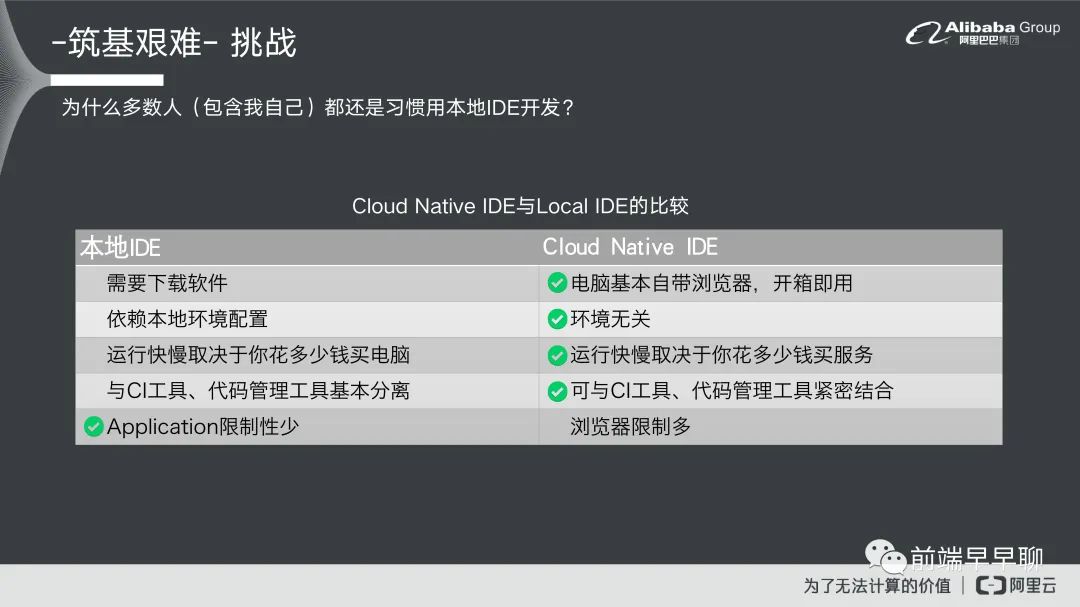
什么原因会导致现在 ODE 起不来,我们稍微拆解一下。我认为有几个因素,这里有 ODE 跟本地 IDE 他们之间的一些比较。
第一个在下载的部分,就是说本地的 IDE 它需要下载一个软件无论它多轻你都要做一个下载的动作,你才可以开始用。在 Cloud Native IDE 里面,基本上现在电脑都自带浏览器了,所以基本上就是开箱即用打开访问页面就可以开始用了,这个来看的话基本上就是 ODE 胜出。
第二个 IDE 本身因为它是台基式的,所以它依赖于你本地的环境,比如说你 CPU 多少,它的运算速度就取决于你的本地台机有多强。对于 ODE 来说就不是这样的,他取决于你花多少钱,其实都一样。如果说你的云上资源是够丰富的情况下,它甚至可以媲美国家级的运算实验室,你都可以做得到,只要你能够去花钱去买这个环境那就无所谓。
第三个的话其实跟第二项也很接近,就是说它的快慢 IDE 就取决于你电脑的配备,ODE 就取决于你花多少钱买服务。
第四个是说目前本地的 IDE 它跟 CI 工具还有代码管理工具是分离的,现在趋势是 CI 跟代码管理,它主要都还是来自于云上,就是说我们会把代码推到 GitLab 或者 GitHub 上面去,然后再去做发布或者是 check 的一些动作。ODE 部分基本上可以跟 CI 工具和代码管理工具去做紧密的结合。
刚刚讲的 4 点基本上都是 ODE,为什么现在领导者像现在看起来是这个样子对吧?不合理,所以我就认为最后一点就是取胜的机制,在本地的 IDE 里面它的限制性是比较少的,因为你可以用电脑的所有权限,比如说你可以控制你电脑的 CPU,或者说你可以控制你的线程,但是浏览器的限制就会很多,这个限制来自于浏览器它本身需要有一些安全的机制,还有一些网路通信的开销在里面,我们等下会说。为什么今天 ODE 要起头会这么难,主要的原因还是在于限制性,就是浏览器的一个限制。

我们来看浏览器的限制有哪一些,我们刚刚也提到第一个是网路通信,因为我们所有的资源请求全部都仰赖于我们的网络。我们期待将来网络通信不再是困难,当然现阶段来说它还是一个问题。
第二个是网页的原生语言是 JS,因为 JS 本身在开发,在一开始的设计之初,它就有一些限制,比如说它需要做一个转译转成底层的 C,当然这个也跟浏览器本身的实现有关,但基本上来说 JS 它是一个高阶语言,它不是一个低阶语言,所以它肯定会有一个转译的成本在里面。
第三个就是安全限制,因为浏览器本身它具备的一个特性是说你可以在网页上面去浏览资源,资源可能来自于各方,所以浏览器会保护你的浏览安全,它会去限制一些你使用的一个过程,这就会导致你在开发上面或者是说本身 ODE 它比起 IDE 来说更加绑手绑脚的,限制了很多的东西。

我们简单的归类一下,就是说为什么今天这么难,主要的原因还是因为体验不好,大家为什么今天不想要去云上做开发,就是因为你觉得本地开发还是比云上开发的体验好,它更加的方便而且更加的让你觉得比较安全,我的文件至少应该不会说不见了会怎么样。
刚刚讲的是现在的挑战,就是说我们有一个梦想在,但我们跟梦想之间有一个 GAP,有 GAP 就会存在挑战。我们接下来就来提一下我们怎么样去提升体验,怎么样去迎面挑战,然后去解决它。我们就问一个大灾问,怎么样可以让 Cloud IDE 体验更佳?突破现状?
厚积薄发·体验

或许我可以跟大家说一下,我们在业务里面的一些沉淀,毕竟在我们部门里面基本上天天都在接触 IDE,对于 IDE 的体验问题多少有一些沉淀,所以我们可以给大家一些经验或者是一些想法,然后来跟大家一些输入。先简单的介绍一下我这边的场景,我所在的部门是计算平台事业部,我们做的一些业务场景就是一些数据开发相关的事情,列举一些在我们部门里面比较有名的一些产品,第一个就是数据开发的一个工具叫做 Data Studio,然后还有一个数据分析的工具,另外还有一些数据引擎 hologres 其他的 APP 等等之类的一些引擎。在有数据服务,数据建模跟机器学习,还有数据质量,就是说我们的内容基本上离不开 ODE,基本上都是长这个样子的,有一个编辑框有一棵树,然后你给它一个终端,比较不一样的是可能有一些图,因为跟建模相关还有机器学习,但大体上来说都是一个 ODE 的形式。
基本上 DataWorks 是阿里云重要的 PaaS 平台,可以帮助我们的数据分析师跟开发师更好的去挖掘数据价值。我大概也讲一下我们现在整个 ODE 的架构,让大家大概可以看一下我们怎么去做 ODE 的,我们在顶层的话就刚刚提到的一些模块。
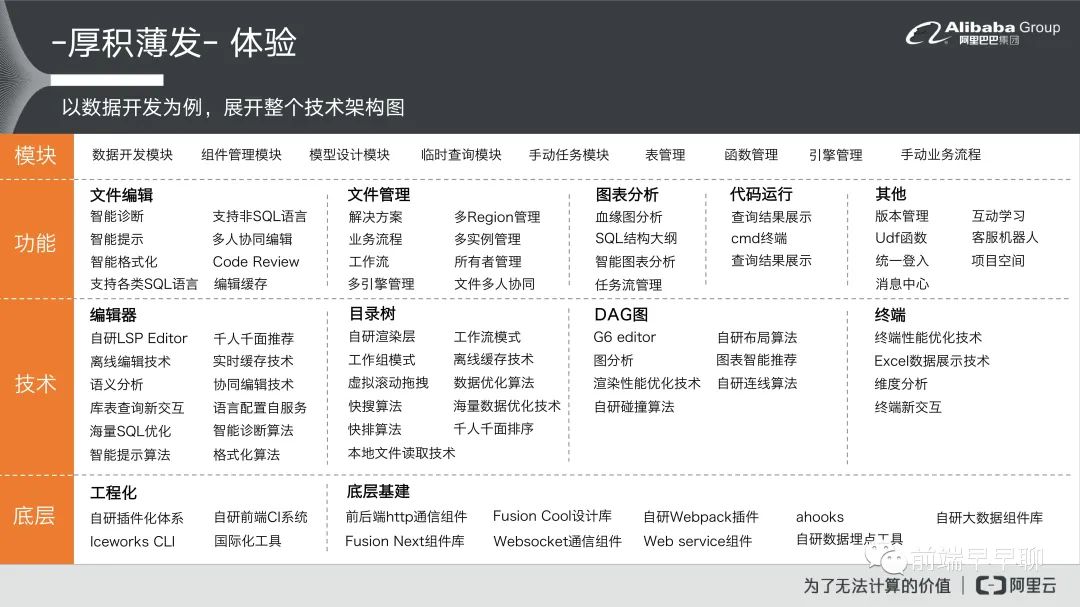
这里以刚刚提到的数据开发为例去展开的一些模块,包含数据开发、数据组建管理等等之类的。功能里面拆解成大概 5 大块,第一个是文件编辑类,文件管理类,还有一些图表分析跟代码运行,还有一些其他的东西。这里面比如说文件编辑里面,就会做一些比较增加体验的事情,比如说我们会有智能诊断,智能提示,然后还有这种智能格式化跟 SQL 语言的提供,在数据开发里面我们基本上支持了将近 30 种的 SQL 语言,大家可以想象就是 ODE 它本身需要具备的能力是非常强的,因为你要支持这么多语言,你就必须要有一个配置管理的能力,甚至说你要针对不同语言都要有不同的智能提示,格式化,诊断整套的配套在里面。第二个是文件管理,因为我们本身文件量很大,就以我们业务场景来说,大概 10 万笔是常见的一种情况,最高的话大概有客户到 100 多万笔的数据,就一棵树上面要展示这么多数据。再就是图表分析,我们对图表分析的部分也有很多的沉淀,包含血缘分析,SQL 大纲,然后还有智能图表分析,我们也做智能图表,还有代码运行诊断跟其他。
再往下看技术的部分,我们就会拆解成 4 大类编辑器,目录树,DAG 跟终端,然后底下就是整个我们的技术栈。也可以看一下,然后最后是底层,我们底层的话基本上很多是自研的工程化体系,我们的 CLI 用的是 Iceworks CLI。我们有自研插件化体系跟前端的 CI 工具,还有国际化工具,还有一些组件库,这个是我们整个 IDE 展开的架构。
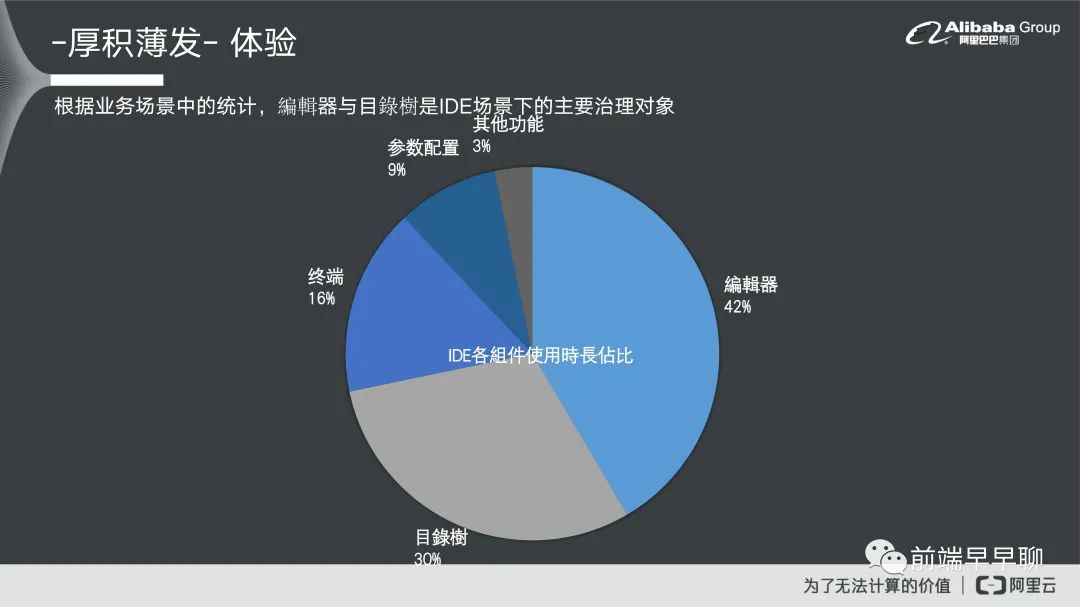
我们有统计过在整个 IDE 里面它大概的组件使用情况。统计下来发现第一个时间占比最大的还是在编辑器身上,因为大部分的数据开发它需要去做代码编写。所以很多时常就会放在编译器里面。第二个是目录数,因为大家平常在做文件管理的时候,肯定需要新建文件或者是说对文件做一些编辑。第二个是目录数,再是第三个终端,然后是参数配置跟其他功能,这个是在我们业务里面它整个组件的使用情况。我们可以从使用情况里面进一步的去得知,如果想要对我们现在的 IDE 就我们业务场景的 IDE 去做体验优化,应该把这个目标着重放在用户最常使用的这个地方,我们就会着重在编译器目录树或者是终端这三个组件上面去。
接下来就来谈一下我们怎么去做一些性能优化的事情,去增加我们的体验。第一个想跟大家谈一下的编译器的性能优化。
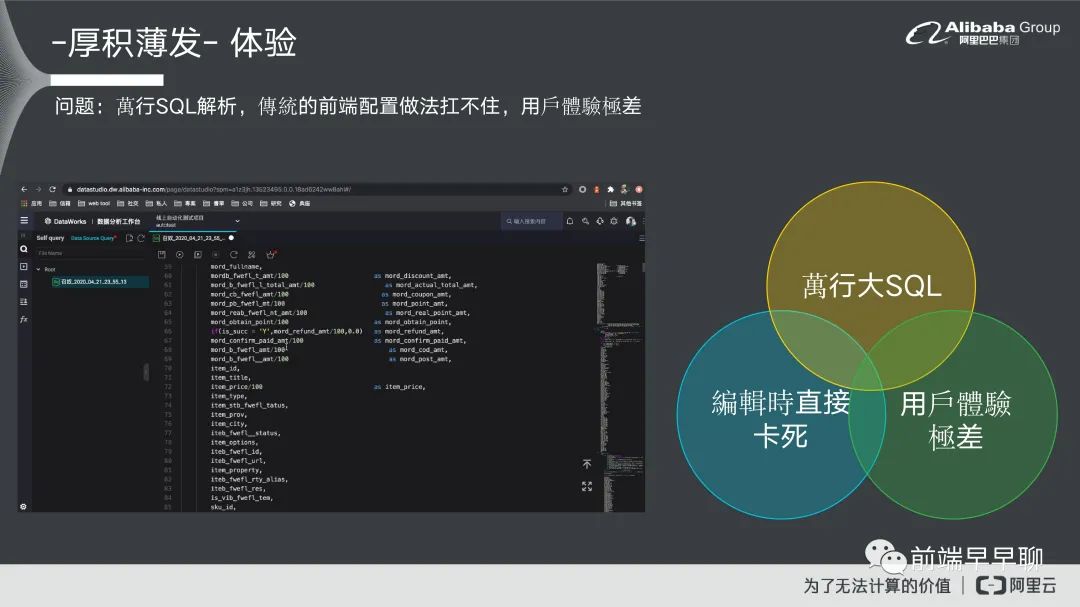
这个是我们遇到的 case,就是说它的 SQL 有将近 10 万行,我如果没记错的话应该是 11 万行。其实这个也不算特例,对于数据分析比较不了解的人可能会这么写,可能会把一些数据直接就写在你的 SQL 语句里面去做一个 insert的过程或者是说它可能就当做他本地编译器在用了,这个也很正常。这个会导致我们现在遇到的一个大问题。当你的SQL 语句达到 11 万行层级的时候,你基本上做什么事情都卡。编辑页卡,现在这个画面就是他敲一个字就卡住了,基本上就不用谈体验了,这根本就是系统 bug 了,对用户体验来说也是非常差的一个过程。我们大概去看一下这个问题以后,到底什么原因导致他在编辑的过程中直接就卡死了,我们去做一个前端的诊断。
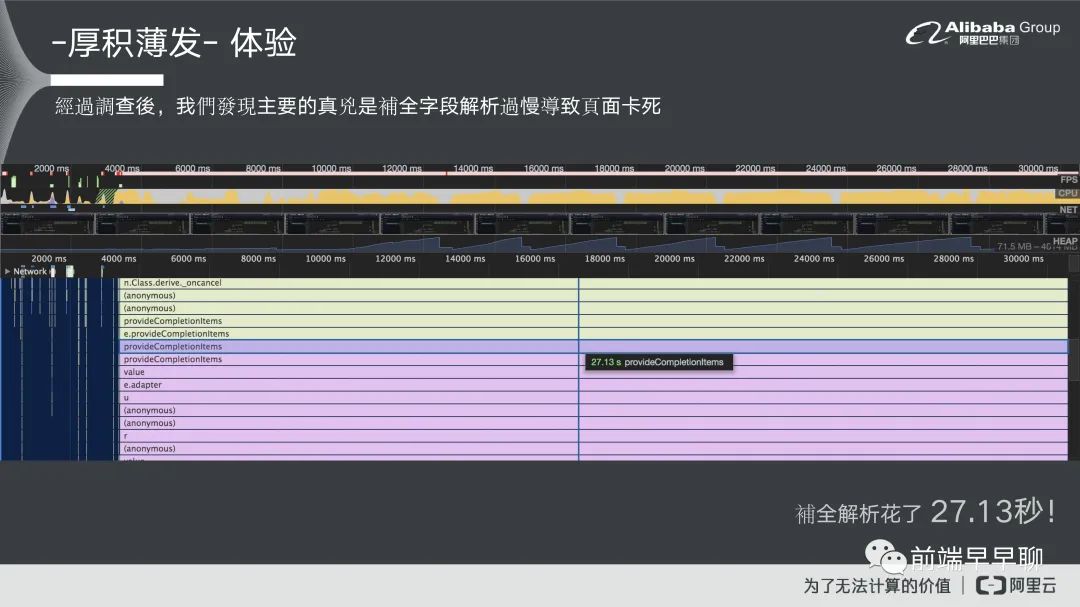
我们用 Chrome 它本身自带的工具,可以看到在它的现成使用情况里面,它大部分的时间都给了这一个函数,我们去追踪一下这个函数,它实际上是一个字段补全的一个函数,补全的意思就是说它需要去针对你的 SQL 做解析,解析完以后他知道你现在在敲的代码是什么,然后会很智能的告诉你这个代码它后面可能你要写的是什么,来帮助你去完成这个语句。所以它中间过程需要做解析,然后需要做一个提示的过程。
我们发现实际上整个过程在这个函数里面是非常花时间的,往下追踪以后就发现原来真正原因是因为他在解析的时候花了太多时间,因为这个解析他需要对 11 万行的 SQL 去整个扫描过一遍,然后找到他语句相关联性,因为语句本身是有上下文关系的,所以你还必须要解析它的整个上下文,这个是非常花时间的一个过程,整个补全大概是 27.13 秒。

我们为了解这个问题,我们想的一个思路就是说,本来我们的一个做法是我们的补全尽可能的就在前端做掉了,因为实际上对后端来说它是没啥价值的,因为第一个它不做存储,第二个它也不需要做一些调资源的一个过程,所以我们一开始的一个设计思路是说简单做,就在前端做解析就好了,但后来遇到这个问题之后,我们发现不能这么搞,因为前端的浏览器限制的关系,所以导致如果把它放在前端,那会造成很大的性能瓶颈,我们后来跟后端去做讨论,然后我们拟定的方案。我们的方案就是说我们希望把解析过程挪到后端,去透过一个后端的解析机制来把这个过程就相当于是把成本转嫁过去。我们整个技术栈也是有去协议过,就是说我们透过 LSP 协议做前后端通信的一个协议。
我们可以看到这个场景里面的第一个 Monaco Editor 里面包含几种场景,第一个是 Hover,它需要出一些补全提示,所以它会有一些 Hover Provide,然后会有一些 Completion 补全的内容,还有一些诊断的内容,我们会透过Data Converter,我们会把数据做一层转换,转换以后再抛给后端,通过 LSP 协议的方式去做一个通信。到了后端以后,LSP 协议它实际上是一个 Language Server 的协议,所以它可以帮你去做一个处理,直接指定到你当前所编译的语言它所在的 Language Server。比如说我今天可能敲一个 ODPS 的一个 SQL 或者是一个 MySQL,那就可以指定到 Language Server 里面。
接下来我们需要对整个 SQL 语句做解析,我们解析方式是透过 Antlr4 语法,我们会把整个 SQL 语句转成语法树就可以拆解出它的内容,然后找到他要做解析的一个位置跟它的上下文关系。接下来进入到下一个层级,就是要跟他做提示,包含 Hover 的提示,补全提示跟诊断提示,中间过程我们还加了一些新的东西,我们加入了机器学习的要素,如果今天他的补全内容到了后端以后,他可以根据我们其他用户的使用行为,或者是语言内容来去跟他推荐一些比较常用,或者是比较符合它现在 SQL 上下文语句的推荐代码或者是诊断内容。
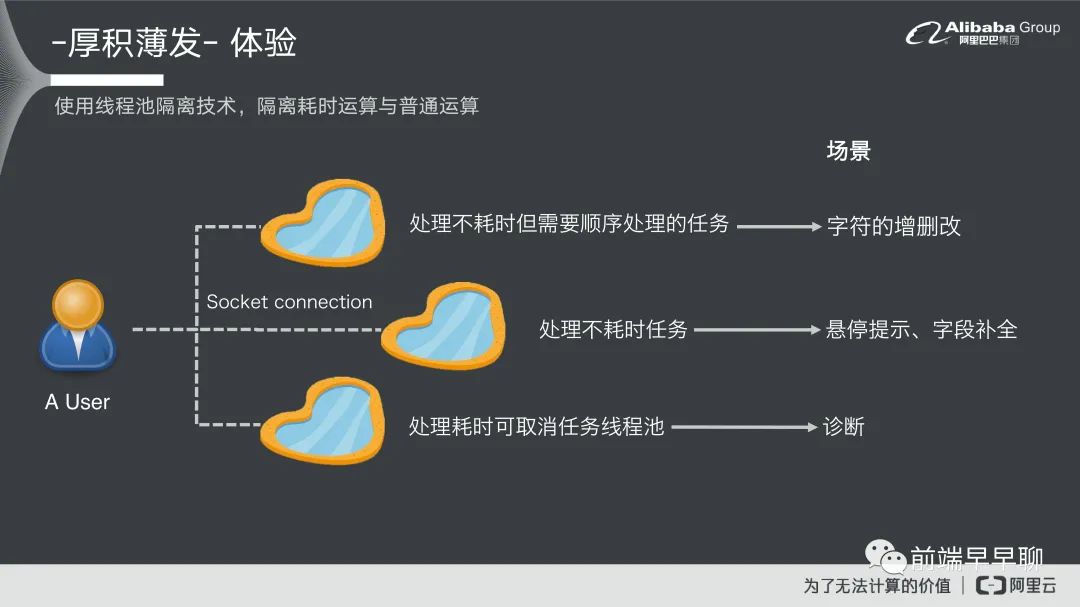
在这里刚提到的是一个我们怎么解问题的整个架构,其他的话还有一些比较琐碎的一些技术问题,第一个我们提到的是一个线程池隔离的一个技术,实际上编辑器它在做补全或者是做诊断都是一个高频操作,用户在敲的一个过程,在敲代码的过程中要及时的反馈,要把这个内容直接做一个快速诊断然后给到前端。所以它对于后端的要求也是非常高的,就是你要如何的去把这个信息马上的吞吐掉然后给到一个答案。对于后端来说,它就需要去拿一些比较重的操作,比如说有一些它解析比较慢的操作,有一些是比较快的操作,然后根据这些操作去区分线程池。
这过程中我们可以看到它分为三大类:
第一个是处理耗时,但是它需要顺序处理一个任务,简单来说它是一个串流任务不耗时,但是需要顺序处理好,这一类型任务最常见的场景就是字符的增删查改,这个类型我们会区分一个线程池给他; 第二个类型就是处理不耗时的任务,基本上这个就是快来快去,我们也分配一个线程池,线程池的场景就包含悬停提示或者是字段补全的过程; 第三种是处理耗时,但是这个任务可以取消,比如说我敲一个字,然后我快速再敲第二个字,我要取消上一个任务,最常见的就是诊断的一个类型。

那么通过这样的一个分流形式,我们就可以把交通给梳理好,让线程不会卡住,基本上我们是每一个 User 都会去分三个线程池出来,这样的话可以确保就是不同的 User,它们不会因为其他人可能有一些耗时任务要卡住,这个是我们整个线程池的一个隔离技术。
另外一个是在代码占领中的一个小技巧就是说我们实际上在数据存储的时候,我们使用的是 StringBuffer 而不是 Sring,这个主要的一个原因是在于,如果我们今天使用 String 的话,在编辑过程中我们可能会对存储内容去做修改。那我们修改的时候会导致说一些比较高频的 GC 过程,另外的话就是说 String 对线程的安全性也是有问题的,所以我们建议用 StringBuffer 的方式去做存储。
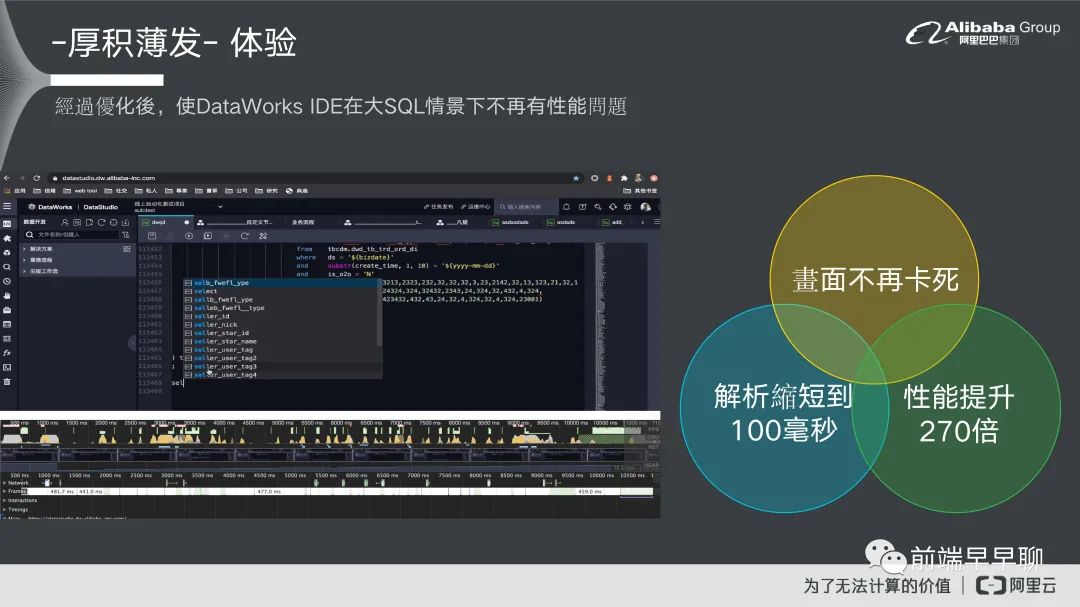
这个是我们整个优化过后的一个结果,大家可以看一下。这个是他在敲代码,一样是 11 万行基本上就不会卡住了,完全就可以很流畅的去做撰写代码的过程。首先我们就可以看到它这个画面不卡死,然后在它的解析整个过程是缩短到 100 毫秒的,性能将近也提升了 270 倍。这个基本上是一个很大的性能优化,对于产品来说它对用户体验也是非常大的一个注意。
接下来我们来谈一下的是目录数的性能优化,这个是我们另外一个重大的 Topic,也是我自己花时间比较多的一个部分,我基本上去年花了半年的时间在优化上面。
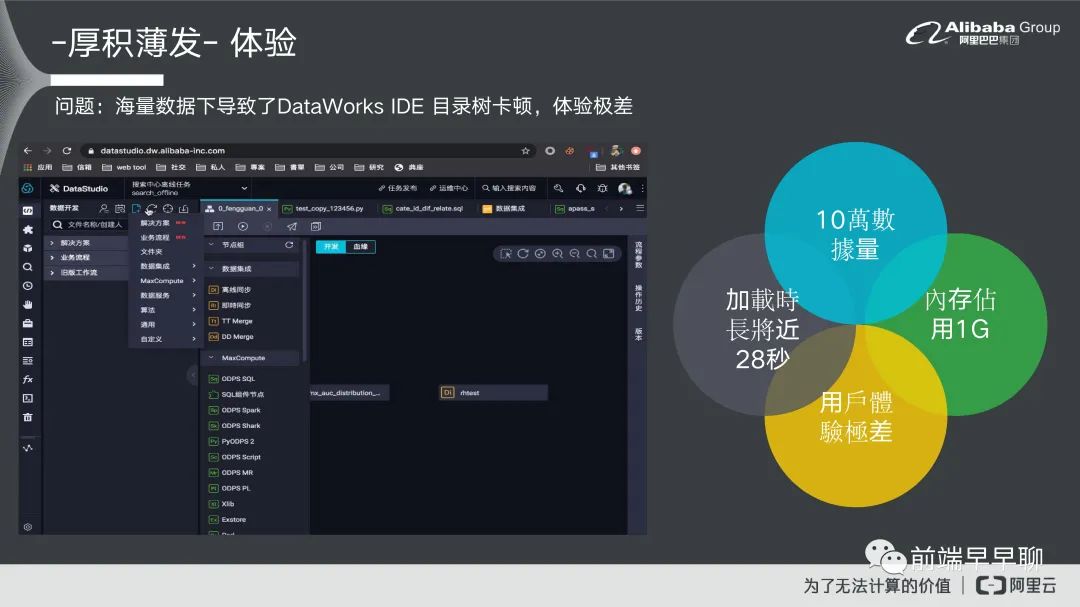
我们可以先看一下现在在我们场景里面目录数是发生什么问题,基本上它在大量数据底下,它整个加载时长是非常长的。我的场景里面基本上数据量是将近 10 万笔的数据,它的加载时长是将近 28 秒,就用户进来以后他就在这边坐着,然后看着这个目录树转圈圈,他啥事也不用干。好像也不错,对数据开发师来说可能是意大利好,可能对我们产品来说是意大利坏,这个的话用户体验非常差,另外的话它对内存的消耗也是非常大的,这个是我们所遇到目录数的一个问题。
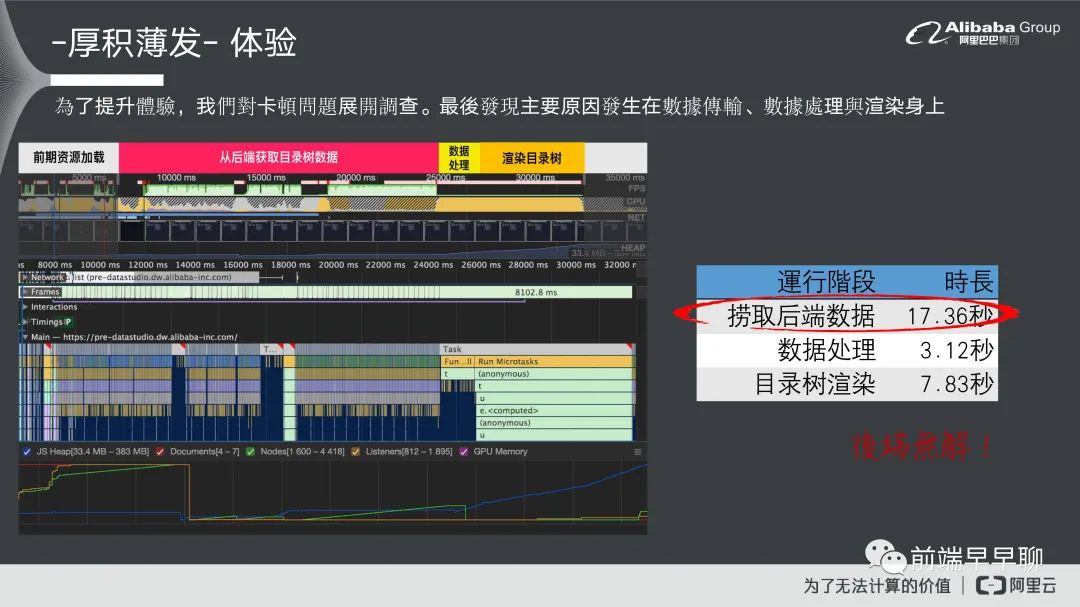
对于这个问题一样我们基本上就一个套路,当你遇到问题以后,你就开始打开 Chrome 工具,然后看一下到底前端发生什么问题,如果前端没问题,那就后端问题。看一下这个问题到底是什么问题,我们看到是整个目录数加载过程中它的线程使用情况。我们可以从线程使用情况里面看到,它主要的慢点在于第一个它跟后端要数据的时间过长,再就是它还有一个数据处理的一个时间,最后还要做一个渲染的时间。
首先后端捞数据这一块大概占大头,它是将近 17.36 秒,跟后端它本身的代码也有关系,在数据处理大概花了 3.12 秒,最后是树目录渲染大概花了 7.83 秒。那这一块我们看下来应该没问题,铁定是后端问题直接抛给后端,到后端解就好了。对,我们一开始也是这么做的,但是后来我们讨论了大概有一个多月,陆陆续续大概开了三四次会,把他们几个老大都叫过来,但后来解法就是后端没法解。
没法解决的原因,第一个在于历史包袱太重,我们整个在产品开始的时候,它的设计逻辑就没有考虑到这么大量的数据。加上我们的产品现在基本上动不了,就是你要做这么大量的改造,对于后端对于整个我们业务来说都是很大的一个风险。所以考量下来,后端意思就是说要不然就这样,反正既然问题解决不了问题,那就解决提出问题的人,这也是思路。
但我们认为就是说既然真的没有办法,我们就想想前端有没有办法可以去解决这个问题。我们后来怎么从前端解呢,我们就想到一个思路就是说,既然后端他要在一段时间内去处理大量数据,对他来说是一个难题,我们不如就让他一次处理一点点数据对吧?这样对他来说他也不用这么难了,我们就帮他把这个问题处理掉。

首先我们主要一个大的思路,就是说我们把数据去做拆解,拆解成数个数据的分割,然后再把这个数据分割以并发的形式,它是一个并发形式在跟后端请求,然后让他把数据抛过来。抛过来以后我们再对数据处理,最后再去做一个前端渲染,这个就是我们的一个解题思路,这解题思路就是非常简单粗暴对吧?但他却非常有用,我们可以看一下最后效果是怎么样子?
我们解题思路它实际上是一个简单粗暴,但是它也会同时的产生一些其他问题。最主要的大问题就是一个高并发的过程,因为我们看一下整个过程,它基本上是不给前端一点喘息机会的就是说你一旦数据马上出去了,他一回来我马上要处理完马上又出去了,基本上不等马上有东西来我马上处理,这样才能够做到一个高性能。
对于前端来说是一个很大的挑战,你就必须要处理这种非常大的并发量的一个过程。这个过程会有什么问题?就是对高并发的请求或者是高并发的一个处理,在代码的撰写上面是非常恶心的,就是你要处理一堆并发所导致的边际效应,比如说 A 先到 B 先到,然后 B 先到来了怎么做?要不要等 A,如果有异常要怎么处理,反正一大堆这种并发下所导致边际效应的问题就是副作用。
我们为了解副作用,我们去重新设计整个就是代码撰写的 Pattern,我们的一个方式就是透过响应式编程,响应式编程它在这种高并发的领域它是专家,你可以透过它的领域技术或者 Pattern,然后来把这种高并发问题去做一个很好的拆解让代码更加的流畅。

我们首先先用反应式编程的方式去把整个流程做一个 pipeline,把过程以流的形式去做串流。另外一个问题,我们虽然说用了反应式编程以后,我们可以把高并发的一个问题做比较好的拆解,但是反应式编程本身是流计算的一个过程,它并没有讲的是副作用的一个解决方案,比如说我如果同时有两个流,两个流之间我应该怎么样去做管理,或者他们两个如果互相依赖的情况下应该怎么办?
所以他对于这一块没有做一个讲解,这导致还是会有问题发生,在这里我们就引入了下一个概念叫做工作流模式。这是一个典型的流跟流之间交互的一个过程。工作流模式我简单讲一下,就是它是一个管理学上的一种模式,他讲的是流跟流之间应该怎么去做管理,然后他有哪一些流的组合形式,比如说我有串流,我有并发流,我有条件流等等之类的这种流的形式。流跟流之间有冲突的时候怎么办?他也会讲说流的冲突,比如说我应该释放资源,还是说我应该异常处理等等之类的。透过这样一个方式,我们就可以把流跟流之间的关系去做一个更好的处理,达到这样的一个效果,这是第一个我们所提到的工作流模式来去解高并发的问题。

另外一个问题是线程阻塞的一个问题,因为我们在设计架构里面,我们考虑的就是说当数据从后端来以后,有一些比较耗时运算,我们需要塞到 Worker 里面,然后另开一个线程让它去处理,而不会影响到我们的主线程,不会让 UI hint 在那边,所以我们基本上就会去开很多的 Worker,来去处理并发过来的数据,这个就会导致我们现在提到的问题就是 Worker 阻塞,比如说开了一个 Worker 专门来处理耗时计算,耗时计算它本身快那也就好了,比如说它这个过来马上买完就马上走,马上下一个人过来就马上走,它就不会堵在这里。
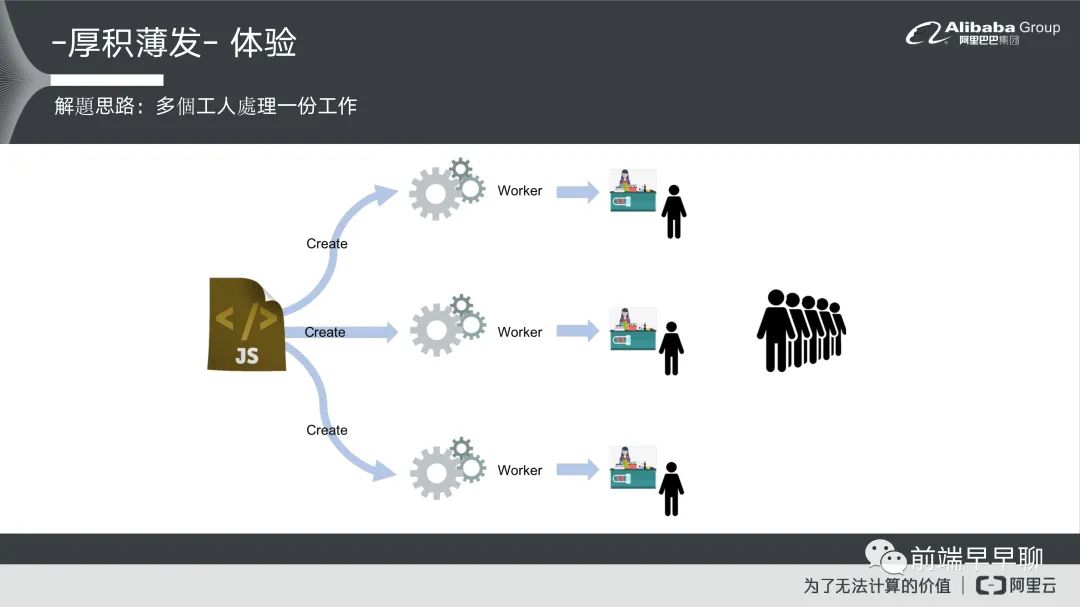
但是如果你来的太快,这个 Worker 来不及处理,他就会开始进入排队现象,这就导致你的 Worker 不起效。我们为了解 Worker 注册问题想到一个思路,就是说我们可以模拟后端他们真正多线程的一个过程,它实际上对一个工作可以拆解成多个线程来做处理,我们就可以做这样的一个方式就是说我有一份 js 文件,我同时去新建多个 Worker 来去处理同一件事情,我们去分散客流来让任务可以更好的去做执行。
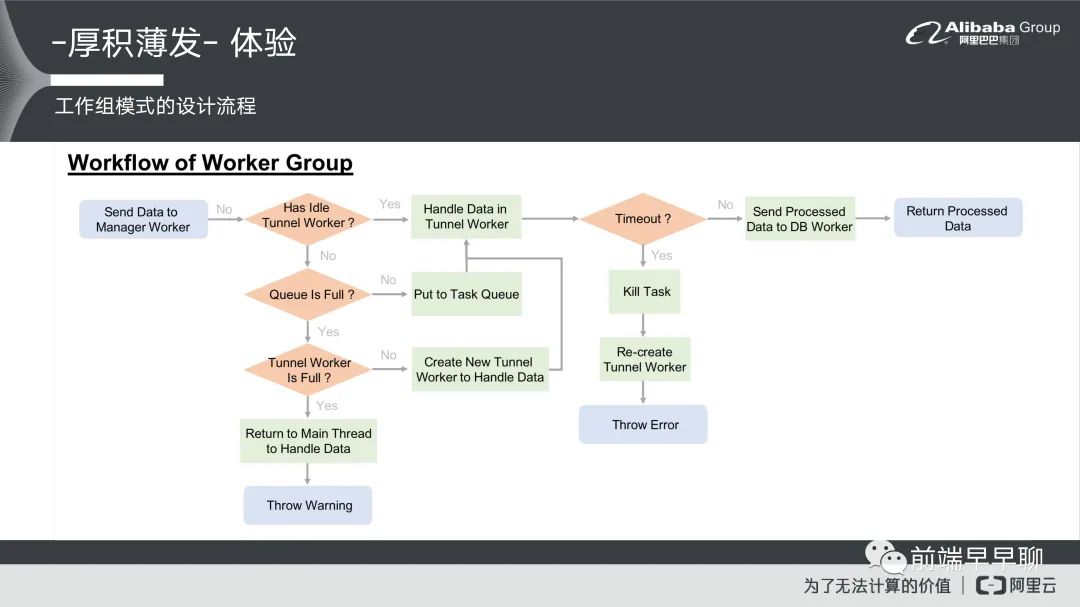
这个思路其实很简单,但它的实现里面还是有一些难处,首先它跟后端一样有这样的一套逻辑,你怎么样去实现一个工作组?简单讲一下工作组它整个实现的逻辑,这里进来以后,他先判断一下你现在的通道,就是你的 Worker 它是不是有闲置的 Worker。如果没有,它就再问一下你现在的排队 Queue 里面它是不是满的?
如果不是满的情况下,他可能就会等待它进入到 Queue 的 Task 里面,然后等待你的任务完成才去进入到 Worker 里面,如果是满的,它就会问一下你现在 Worker 的数量是不是已经 Full 已经满了?如果也满了,就只能回到主线程里面去做处理,并且有一个 Warning 的机制。比如说我们通道不是满的情况下,就可以去创建一个新的通道来去处理资料,这样我们就可以把资料通过这样的机制去做处理,然后我们会有一个 Timeout 的机制就是说如果你今天有耗时计算,比如说时间太久了,我们会设一个阀值如果阀值超过了,我们会把 Task 给 Kill 掉再去重新创建一个 Worker,再去做一个 Error。如果都没有 Timeout 的话,就会进入到下一个环节,这是整个工作组模式的一个设计流程。
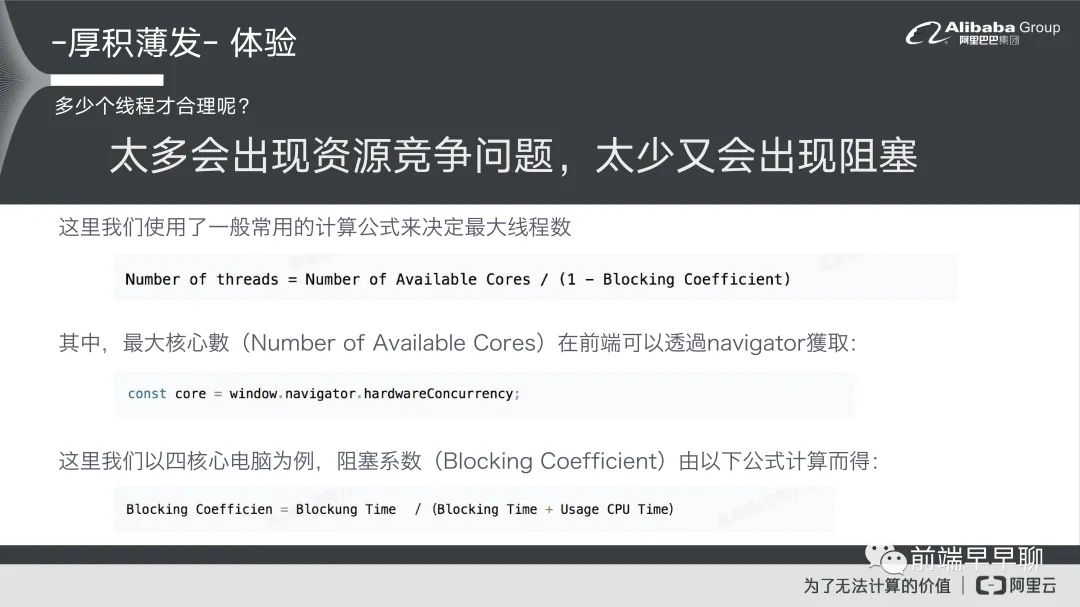
另外一个问题就是说工作组模式它会涉及到你需要开多少线程的问题,这个问题也是一个在后端里面很常见的一个问题,比如说我今天在商场里面我开三条线来处理客流没问题对吧?我可以把客流同时消耗完,但你这时候会发现怎么有一个收银员一直在偷懒,他都不干活因为没有客人到他那边去,这个其实有线程太多导致说有线程偷懒,如果你太少又出现排队问题。所以到底要有多少?它怎么取决的一个问题。
这里我们就使用一个公式来计算最大限值数。这个公式是后端他们本身在算线程的时候常用的一个公式,这个是正态公式,他是这么说的,我可以取得的核心数,然后去除以 1 减掉阻塞系数(Blocking Coefficient),来去算一个我现在所需要的线程数。
这个核心数在前端里面,我们可以通过 navigator 里面有一个 hardwareConcurrency 这个参数去拿到你电脑它的 CPU 有多少,假设说我们现在的 core 他是四核心的电脑,我们可以再进一步的来计算它的阻塞系数,阻塞系数怎么算?它是这么定义的就是说你任务它平均的阻塞时间,比如说一个任务它要花 10 秒钟,然后来去除以它的阻塞时间加上 CPU 的运算时间,我们就可以通过这样的方式去算它的阻塞系数。

这里面其实有几个数据需要做统计,第一个是 Blocking Time,是根据你的系统根据你的数据它可能会有不同的 Blocking Time。在我们自己的业务场景里面,我们就去算一下它的 Blocking Time 的话大概是在 300 毫秒是一个比较安全的阀值,如果小于 300 毫秒的话,任务可能会有失败的一个情况。通过这样的一个方式,我们就可以算出我们最好的线程数,这里是我们看到的一个最后结果。
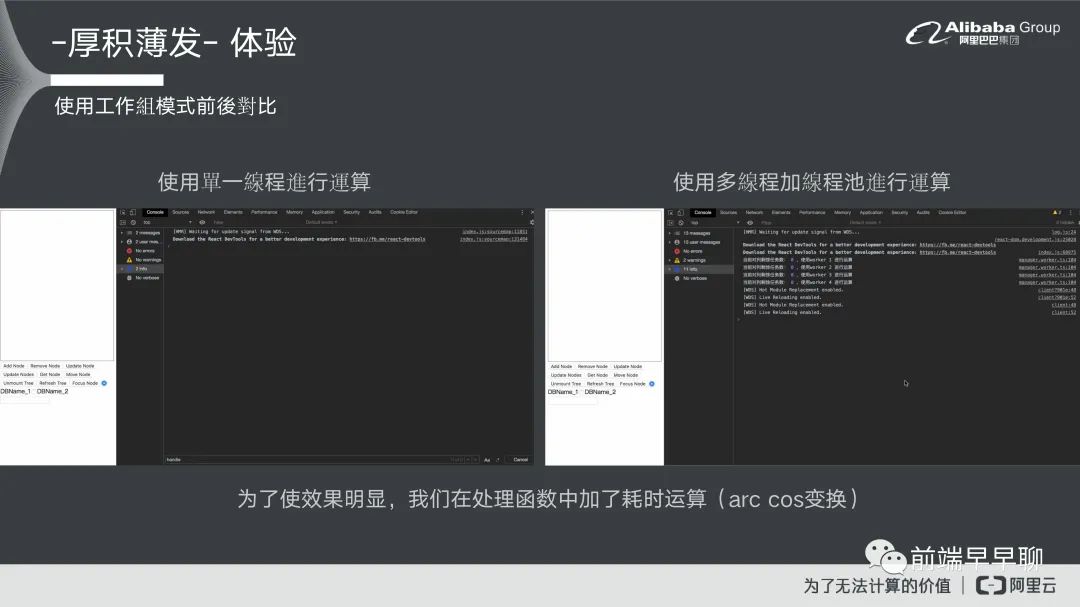
你可以看到就是说用工作组模式的话,基本上它的运算效能会比这边好将近 50%,这个实验里面我们使用的耗时运算就是一个 arc cos 的变换,然后把 arc cos 就放到 Worker 里面去做运算,这个就是工作组模式它本身运算的情况。

另外我们在渲染层里面也做了一些优化,渲染层里面的优化我们也可以看一下,我们是使用的虚拟滚动技术,虚拟滚动技术是谷歌他们在开发组中已经提出来的一个技术,它主要就是说它可以把 DOM 元素减少,当你在一屏里面比如说你有 10 万笔数据,我就只展示你当前看得到的部分其他的部分我就不展示,这样的话它可以减少你 DOM 元素的生成来减低你的效能损耗。
我们基本上原理是使用这个技术,但使用这个技术场景之下你会衍生很多的副作用,就是你必须要对树场景去做一些优化。对于这个部分我们也做了一些沉淀,在我们的场景里面数据是一个流的形式进来,我们会有一个时间线,在这个时间线里面获取数据以后,我们需要把数据马上做处理,然后马上丢到这个树里面,让它能够马上及时地展现出来。所以这里面基本上需要有一个数据组装的过程,然后以及怎么样快速的去把数据重新渲染到虚拟滚动树上面的一个过程。
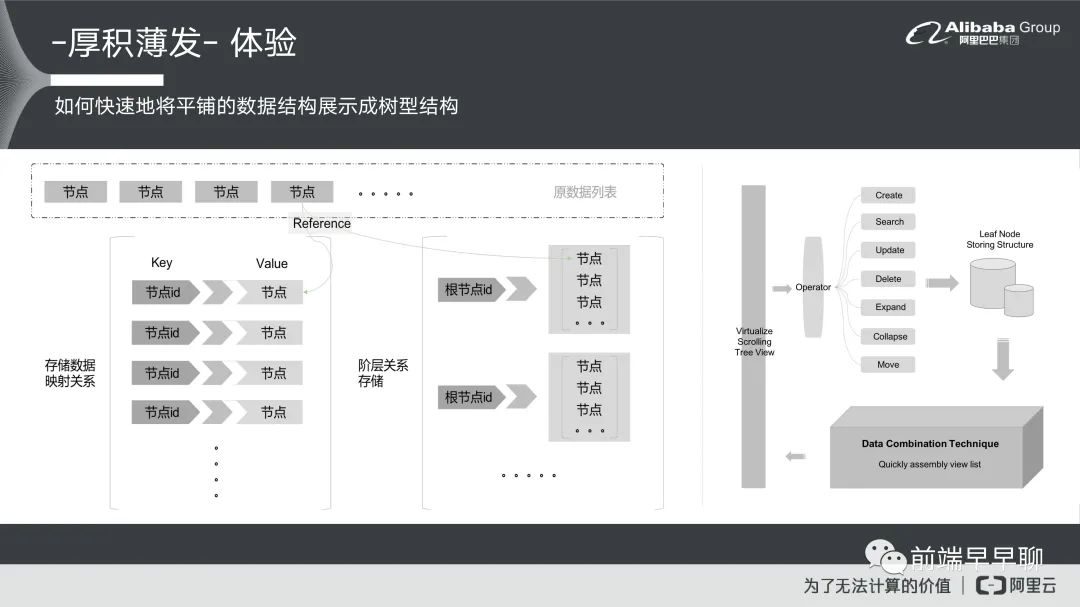
我们在这里面遇到比较有技术点的一个难题,首先怎么样能够把数据做一个快速的平铺?应该说怎么样把平铺的数据快速地变成一个树形结构,我先说一下为什么需要一个平铺的数据,是因为虚拟滚动它本身的限制。虚拟滚动它实际上在做所有事情的时候,它都是把这个数据当成条列式数据的一个方式展现,不管你是表格或者是 Table,或者是 Grid 或者是列表 List,它本身都是一个条列式的过程不允许这种嵌套结构,如果要嵌套结构你只能自己想办法。这个会导致在树里面你没办法直接用。因为树本身就是一个嵌套的结构,它是有上下层级关系,就是你的叶节点要能够展开,能够展示它的子叶节点,所以我们就必须把这个结构重新做一个调整,让它变成是可以展示在虚拟滚动里面的一个过程,同时又不能够有性能损耗。
我们有原数据在这边,这个是原数据,原数据进来的时候,它是条列式的一条一条。来了以后我们就把原数据做两层映射,一层映射是组成数据的映射关系,就是节点 id 对上一个节点,我们把节点 id 当做 Key,把这个内容当做它的Value,然后做成一个 map 去除存储映射关系,存储数据映射关系是为什么要这个东西?是因为在树上面我们才会有编辑删除等等 CRUD 的一个过程,我们如果能够快速做 CRUD 我们需要有一层映射的过程。
第二个我们存储的另外一个映射是叫做阶层关系的一个存储,这个阶层关系存储它基本上就以根节点的 id 当做它的 Key 然后把它的所有的节点当做它的 Value,做成一个数组存到 map 里面。这个存储关系它主要描述的就是平铺结构怎么样去组装成树结构的一个过程。
有了这两个 map 关系以后就可以去做树的组装以及快速的 CRUD, 可能中间过程大家会觉得说你这样做两个 map以后,不是整个内存就变大了吗,实际上在这里面我们都是 Reference 的方式去做存储,所以在这里面它实际上存的不是具体的存储空间,它本身是同时链到了同一个 Reference,所以虽然你会多一个存储空间地址的这个物件,但本身对于内存使用量来说,它并不会是平方倍的成长,它还是一样就是线性的。
另外要谈到的第二个点就是我们既然有了存储关系,我们怎么样可以快速的去做组装,为什么会需要组装的过程?是因为我们现在把这个数据以流的形式然后串接进来。当你进来新数据的时候,你要再重新快速的把数据组装成一棵树的结构,然后再展示到虚拟滚动里面去,对于组装来说它是一个高频操作,而且它的性能损耗也必须要控制好。

基本上我们最后会去做一些评比渲染层的一个方案。因为这个树现在是在蚂蚁内源跟我们蚂蚁集团,就是阿里旗下的蚂蚁它是有内源社区,我们在内源先做一些开源公测,如果说有确定它是具备业务价值,并且是可以开源的一个组件,它就会正式对外公布,我们目前组件是在内源去做公测,在内源公测的时候它需要有一些评比,就是说你要去对比你的竞品,去展现你的价值。
我在内源公测的时候,我就有一项需要去展现,为什么我的树会比现在开源树还要好?我就去做一个 Benchmark 然后来去证明它。根据 Benchmark 我取得的数据是这样的,如果分批倒入数据刚刚提到的这种串流形式,然后把数据分批倒入的话,我的手屏渲染时间大概在 0.56 秒。整个数据加载完成大概在 4.24 秒,如果是一次倒入的话在 2.58 秒,一次倒入数据基本上首屏时间跟完全加载时间就完全一致了,下面的也都一样。zTree 的话是 3.76 秒排第三名,antd Tree 大概是 4.62 秒。再来是 Fusion Tree 6.38 秒,RC Tree 是 23.62 秒,再是 jqTree 83.79 秒。这里 Tree 本身如果有虚拟滚动我就开了,我会让他们处于性能最好的情况下去做对比,大概结果是这样。
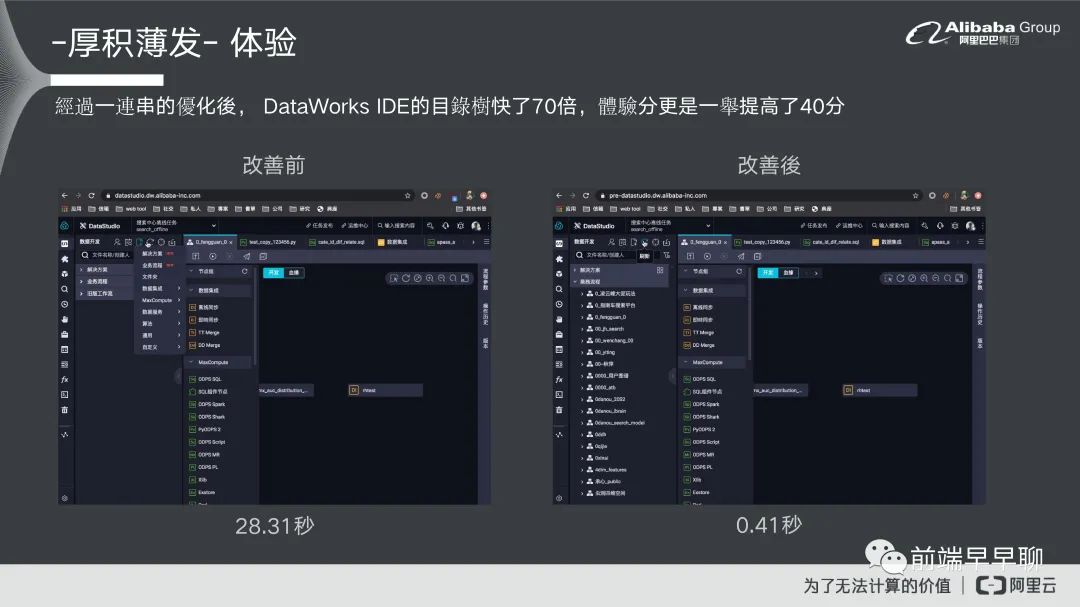
可以看一下我们最后改善的结果,就是说在我们自己本身的业务场景里面,它左边是改善前,右边是改善后,改善前的话基本上还在渲染,然后这边已经开始在做操作了,基本上时间在大概 0.41 秒的时间就可以完成渲染,这边的话要 28.31 秒,基本上就快了将近 70 倍。我们也有用 Chrome 的灯塔去测试产品的体验分,体验分本身是提高了 40分。

在我们场景里面实际上还有一个重点离线编辑,离线编辑的话因为我们在 ODE 里面其实很大一个让大家心中觉得最可怕的因素。如果你今天在浏览器上面做编辑以后,然后可能网络一下不稳定,你编辑的内容就没有了。比如说你先写了一张代码,你觉得这张代码很牛逼的,可以拿到世界第一,结果突然网络一卡顿这个代码不见了。所以我们希望我们的编辑器可以做到离线编辑,就是今天你在编辑过程中,它是不会说因为网络延迟或者一些异常就导致你的编辑内容就不见了。

基本上对于我们的编辑器它有几个离线要求,第一个就是目录树的展示要能够离线操作,在没有网的情况下它还是能够展开,还是可以右键去做一些新建,或者是做删除编辑等等之类的,在断网恢复以后,你必须要把这个内容再展现出来。另外的话就是编译器的部分,比如说你在弱网的情况下或者无网的情况下,你一样可以做编辑操作,并且这编辑操作它是可以保存在你的本地端,你今天可能浏览器它关掉了,或者在重新打开以后,你原来编辑的内容还是可以存在。另外的话就是一些补全、代码诊断等等都还可以存在的。
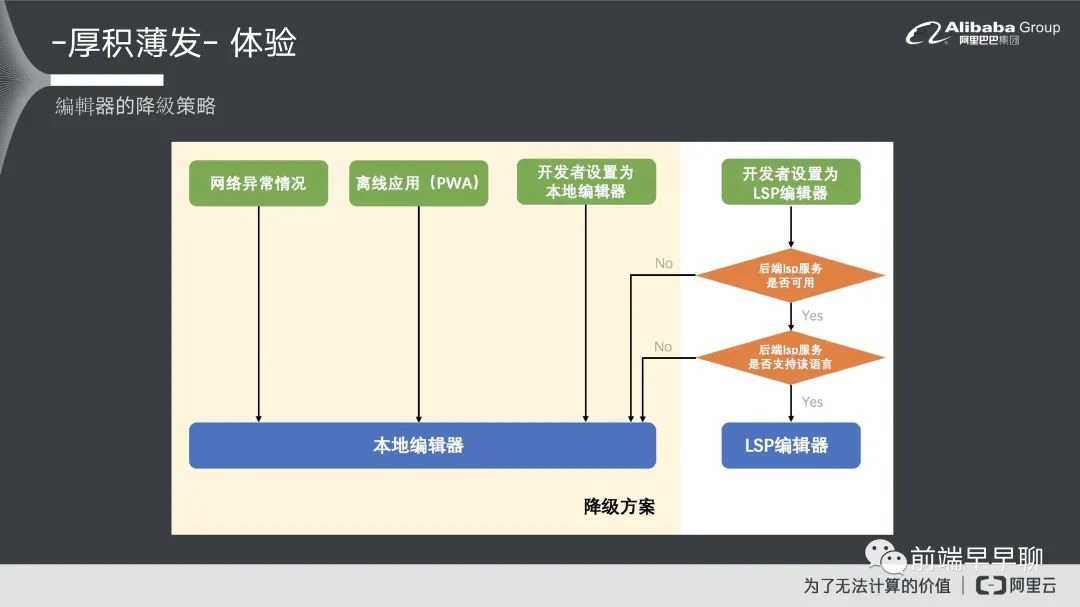
简单讲一下我们编辑器的降级策略,就是说我们实际上对编辑器本身我们会分几种场景:
第一个我们可能是网络异常的情况; 第二个就是我们可能真的离线应用; 第三个就是开发者会把编辑器设置为本地编辑器的一个过程。
这三个条件下我们都要把编辑器去做降级策略,做成本地编辑器。如果开发者把编辑器设为 LSP 编辑器的时候,它需要去判断一下后端它是不是有 LSP 的服务,比如后端服务有问题的时候,它也需要做一个降级。另外的话如果这个语言它是后端不支持的情况下也要做降级,不是这个情况编辑器就会以 LSP 的一个方式去做呈现。

目录树的本身它怎么去做离线体验,我们大概就简单画个草图,首先我们会把数据存在 indexedDB 里面,它是在前端浏览器里面一种现阶段比较符合现代浏览器的一个大数据存储的模式。因为浏览器本身存储模式有限,如果你要存储大量数据,比如说超过 5MB,对这个数据的话,基本上你现在的手段就是 indexedDB,因为另外一个 DB 已经死了。把数据存储的情况下首先我们在数据进来以后我们看一下,比如说你现在无网的情况下,它就去问你有没有缓存,如果有缓存的话,它直接从这个数据里面拿缓存,然后就把它直接渲染出来,如果没有缓存它就问你现在网络是不是已经连上了?如果是连上的情况下,它就会去请求数据,如果没有的话它就会等你的网络回来,然后回到等待的一个过程再把数据给拿出来。重点就在于你需要有一个 indexedDB 缓存的过程。
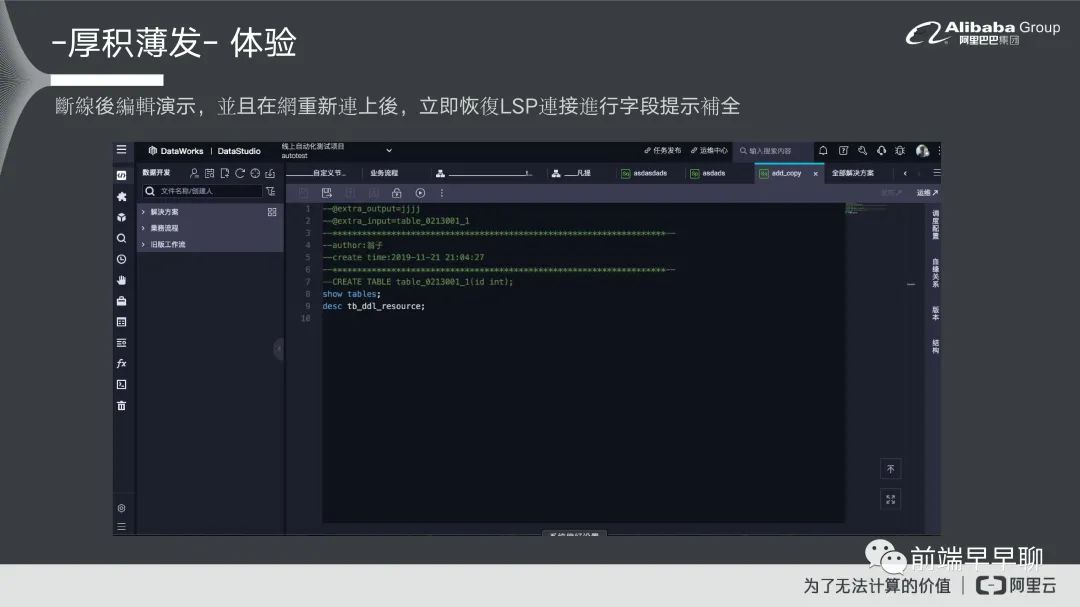
这个是我们做的弱网和无网的一个测试。你可以看到基本上在无网的情况下,你的所有操作都可以进行搜索等等,然后在接下来就在这编辑基本上高亮内容都还是可以好好呈现,然后补全都还是存在。但这个补全内容实际上是被阉割过的,是因为你拿不到后端的补全内容,所以它基本上主要是前端补全,它的内容肯定比后端少很多。把网络重新打开,然后再去看一下,现在编译器的补全内容就是后端给的。这就比你前端补全的内容多很多,包含表字段等等这些信息都可以得到,这个是我们大概整个离线的一个部分。
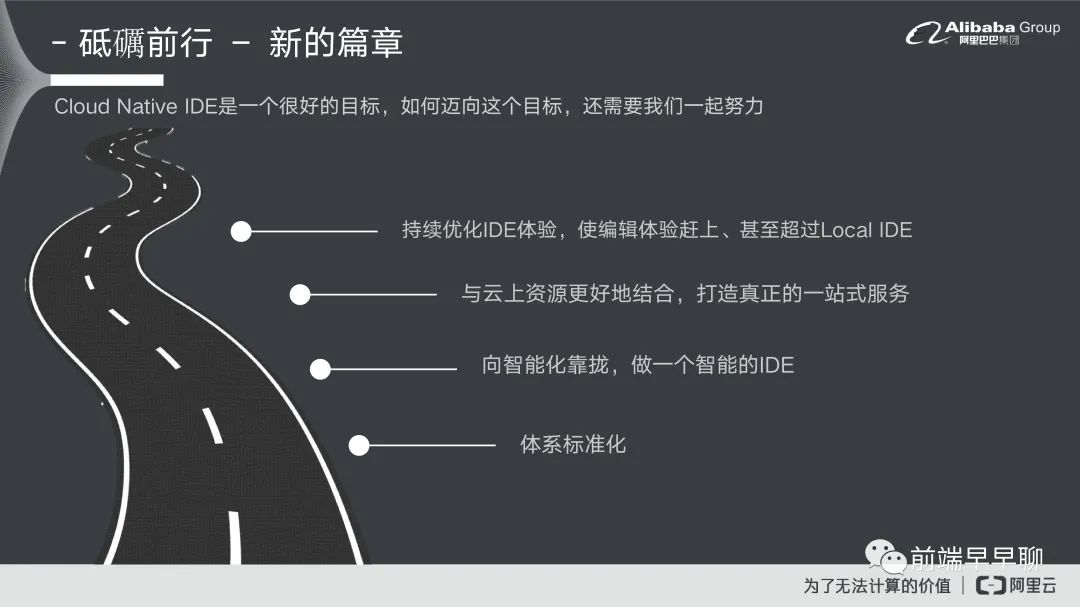
跟大家分享完我们自己的一些沉淀以后,我们谈一下接下来不管在未来 IDE 的趋势或者是我们自己业务里面该怎么走,我个人是这么认为的 Cloud Native IDE 就是我们云原生 IDE 它是一个很好的目标,至少我自己认为这个目标很吸引人,并且我觉得将来一定会朝方向前进,但是我们现在当下我们应该怎么样去朝着目标迈进。我们还有一些可以优化的点,第一个就是我们需要去持续优化 IDE 的体验,然后让编辑器它的体验可以赶上或者是超过本地的 IDE。
第二个可以跟云上资源更好去结合,去打造一站式的服务。比如说我们现在有的 CI 工具,现在其实微软它本身也在做,微软它在这一块看得非常远,它包含去收购 Github,然后去跟 VSCode 去做打通,基本上他就是要玩这一套,所以他这个目标非常明显。
第三个就是说我们需要去向智能化靠拢,去做一个智能 IDE,如果我们今天只是纯粹的去比拼大家都有的本地 Local IDE 都有,基本上你最多就做一个 Local IDE 也不会超过它,我们要怎么样超过他呢,我们要用我们云上游的资源去打磨它,我们云上游的资源就是数据,你怎么通过数据去做智能化,这个我觉得也是一个很好的目标。
最后就是体系标准化,现在实际上对于 Cloud IDE 还是处于一个百家争鸣的阶段,大家都会有一些自己的想法。
六、团队介绍

最后我就来推销一下,看看大家有没有兴趣,我在这个平台叫做 DataWorks,就是阿里云计算平台,可以说是阿里集团研发数据开发工具的一个部门,我们部门的历史非常久,基本上这个图上面写的已经不准了,因为我随便抄过来的,我们现在已经是 10 多年了。部门的整个人数将近 400 多人,那是一个大部门。
团队也非常全,我们前端团队是一个大团队,跟后端是整个分开的,所以你会有一个非常好的环境去做,不管做学习或者是做个人提升,甚至是说可以去跟团队内的人一起合作都会更加方便。另外的话就是在阿里集团里面我们也是领先的,所以你会有足够的资源去做一些你想做的事情。
别忘了 7-17(下周六) 的第二十九届|前端可视化专场,了解数据可视化/时空可视化/大屏/搭建/画布/等等的可能性,7-17 全天直播,10 位讲师(贝壳/奇安信/预策科技/蚂蚁/小米/阿里/阿里云/数字冰雹等等),点我上车👉 (报名地址):
所有往期都有全程录播,可以购买年票一次性解锁全部


扫码二维码
获取更多精彩
前端早早聊

点个在看你最好看

