
基于OpenCV修复表格缺失的轮廓--如何识别和修复表格识别中的虚线
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
推荐阅读

 通过扫描或照片对文档进行数字化处理时,错误的设置或不良的条件可能会影响图像质量。在识别的情况下,这可能导致表结构损坏。某些图标的处理结果可能只是有轻微的瑕疵,甚至只是一些小孔,但是无法将其识别为连贯的系统。有时在创建在单元格时,表的某些侧面可能也没有线的存在。表和单元格类型多种多样,因此通常所提出的代码可能并不适合所有情况。尽管如此,如果我们能对提取的表格进行少量修改,大部分程序仍然可以使用。大多数表格识别算法是基于表格的结构。由于没有完整的边线会使一些单元格无法被识别,导致不良的识别率,因此我们需要想办法修复这些丢失的线段。
通过扫描或照片对文档进行数字化处理时,错误的设置或不良的条件可能会影响图像质量。在识别的情况下,这可能导致表结构损坏。某些图标的处理结果可能只是有轻微的瑕疵,甚至只是一些小孔,但是无法将其识别为连贯的系统。有时在创建在单元格时,表的某些侧面可能也没有线的存在。表和单元格类型多种多样,因此通常所提出的代码可能并不适合所有情况。尽管如此,如果我们能对提取的表格进行少量修改,大部分程序仍然可以使用。大多数表格识别算法是基于表格的结构。由于没有完整的边线会使一些单元格无法被识别,导致不良的识别率,因此我们需要想办法修复这些丢失的线段。
首先,我们需要导入OpenCV和NumPy。
import cv2import numpy as np
然后,我们需要加载包含表的图像/文档。如果是整个文档,并且表格周围有文字,则需要首先识别该表格,然后从图像提取出表格的部分。
# Load the imageimage = cv2.imread(‘/Users/marius/Desktop/holes.png’, -1)
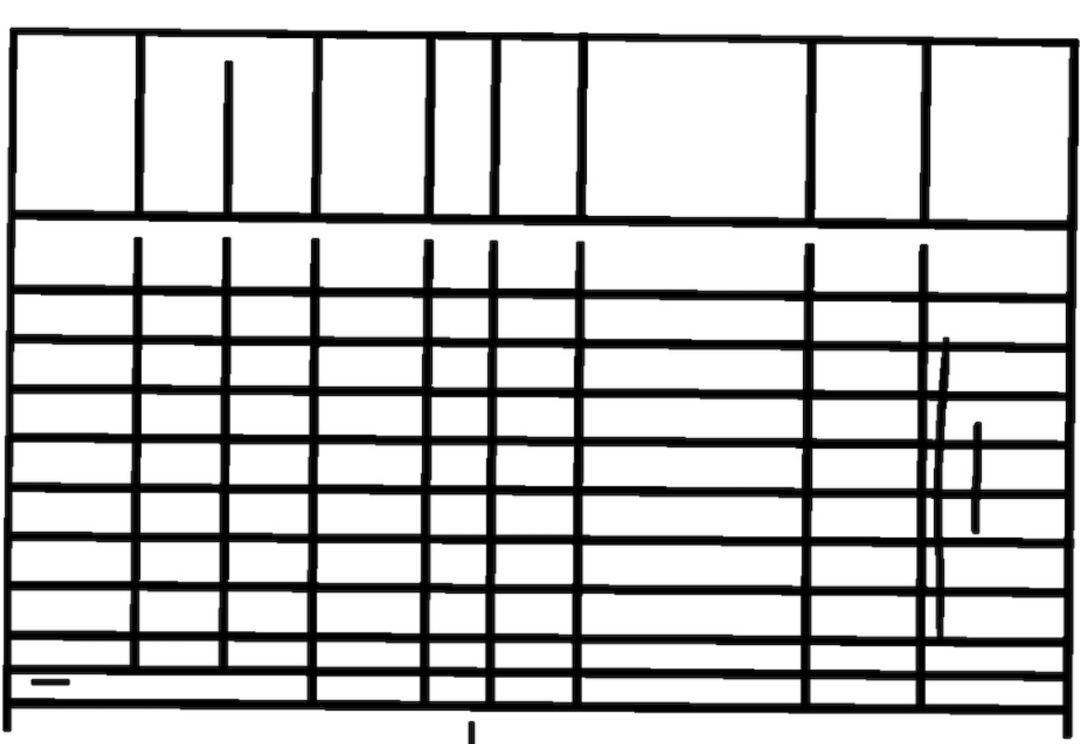
如果大家在输入图像使看到的第二行中的单元格线未完全连接。在表识别中,由于单元格不是封闭的框,因此算法将无法识别和考虑第二行。本文提出的解决方案不仅适用于这种情况。它也适用于表格中的其他虚线或孔。现在,我们需要获取图像的大小(高度和宽度)并将其存储在变量hei和wid中。
(hei,wid,_) = image.shape 下一步是通过高斯滤镜进行灰度和模糊处理,这有助于识别线条。
#Grayscale and blur the imagegray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)blur = cv2.GaussianBlur(gray, (3,3), 0)
然后,我们需要对图像进行阈值处理。
#Threshold the imagethresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
然后使用OpenCV的findContours算法获取所有轮廓的位置。对于所有轮廓,将绘制一个边界矩形以创建表格的框/单元格。然后将这些框与四个值x,y,宽度,高度一起存储在列表框中。
#Retrieve contourscontours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)#Create box-listbox = []# Get position (x,y), width and height for every contourfor c in contours:x, y, w, h = cv2.boundingRect(c)box.append([x,y,w,h])
然后将所有高度,宽度,x和y分别存储在列表中,并计算最小高度,宽度以及x和y。此外,最大y和x是也是必需的。
#Create separate lists for all valuesheights=[]widths=[]xs=[]ys=[]#Store values in listsfor b in box:heights.append(b[3])widths.append(b[2])xs.append(b[0])ys.append(b[1])#Retrieve minimum and maximum of listsmin_height = np.min(heights)min_width = np.min(widths)min_x = np.min(xs)min_y = np.min(ys)max_y = np.max(ys)max_x = np.max(xs)
现在使用存储的值来了解表的位置。最小y值可用于获取表的最上一行,该行可以视为表的起点。x的最小值是表格的左边缘。要获得近似大小,我们需要检索最大y值,该值是表底部的单元格或行。最后一行的y值表示单元格的上边缘,而不是单元格的底部。要考虑单元格和表格的整体大小,必须将最后一行的单元格高度加到最大y以检索表格的完整高度。最大的x将是表格的最后一列,并且连续地是表格的最右边的单元格/行。x值是每个单元格的左边缘,并且连续。
#Retrieve height where y is maximum (edge at bottom, last row of table)for b in box:if b[1] == max_y:max_y_height = b[3]#Retrieve width where x is maximum (rightmost edge, last column of table)for b in box:if b[0] == max_x:max_x_width = b[2]
在下一步中,将提取所有水平线和垂直线并分别存储。这是通过创建阈值并应用形态运算的内核来完成的。水平内核的大小为(50,1)。大家可以根据图像的大小来调整大小。垂直内核的大小为(1,50)。形态学操作根据检测到的结构的几何形状进行转换。扩张是应用最广泛、最基本的形态学操作之一。如果内核下的至少一个像素为白色,则原始图像中正在查看的像素将被视为白色。因此,白色区域变大了。请注意,由于反转,背景为黑色,前景为白色,这意味着表格行当前为白色。扩张可以看作是最重要的步骤。现在修复孔和虚线,为了进一步识别表,将考虑所有单元格。
# Obtain horizontal lines maskhorizontal_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (50,1))horizontal_mask = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, horizontal_kernel, iterations=1)horizontal_mask = cv2.dilate(horizontal_mask, horizontal_kernel, iterations=9)# Obtain vertical lines maskvertical_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1,50))vertical_mask = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, vertical_kernel, iterations=1)vertical_mask= cv2.dilate(vertical_mask, vertical_kernel, iterations=9)


然后使用OpenCV的bitwise_or操作将水平和垂直两个蒙版合并到一张表中。要检索原始的前后前景,可通过从255中减去cv2.bitwise_or来反转图像。
# Bitwise-and masks togetherresult = 255 — cv2.bitwise_or(vertical_mask, horizontal_mask)
 如果桌子被文本包围而不是独自站立(在我的示例中,它没有被包围),我们将其切出并放在白色背景上。现在我们需要前面检索的表的大小。我们使用最小y(顶部的边缘),最大y +最大y单元格的高度(底部的边缘),最小x(即左边缘)和最大x +最大x个像元的宽度(这是右边缘)。然后将图像裁剪为表格的大小。将创建文档原始大小的新背景,并完全用白色像素填充。检索图像的中心,将修复的表格与白色背景合并,并设置在图像的中心。
如果桌子被文本包围而不是独自站立(在我的示例中,它没有被包围),我们将其切出并放在白色背景上。现在我们需要前面检索的表的大小。我们使用最小y(顶部的边缘),最大y +最大y单元格的高度(底部的边缘),最小x(即左边缘)和最大x +最大x个像元的宽度(这是右边缘)。然后将图像裁剪为表格的大小。将创建文档原始大小的新背景,并完全用白色像素填充。检索图像的中心,将修复的表格与白色背景合并,并设置在图像的中心。
#Cropping the image to the table sizecrop_img = result[(min_y+5):(max_y+max_y_height), (min_x):(max_x+max_x_width+5)]#Creating a new image and filling it with white backgroundimg_white = np.zeros((hei, wid), np.uint8)img_white[:, 0:wid] = (255)#Retrieve the coordinates of the center of the imagex_offset = int((wid — crop_img.shape[1])/2)y_offset = int((hei — crop_img.shape[0])/2)#Placing the cropped and repaired table into the white backgroundimg_white[ y_offset:y_offset+crop_img.shape[0], x_offset:x_offset+crop_img.shape[1]] = crop_img#Viewing the resultcv2.imshow(‘Result’, img_white)cv2.waitKey()
这就是结果。该方法可用于表中的虚线,间隙和孔的多种类型。结果是进一步进行表格识别的基础,对于包含文本的表,仍然有必要将包含表的原始图像与数据与具有修复孔的最终图像合并。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目31讲
在「小白学视觉」公众号后台回复:Python视觉实战项目31讲,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
下载4:leetcode算法开源书
在「小白学视觉」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~