
斯坦福下了臭棋?Percy Liang发文辩解:基础模型是人类社会的未来

新智元报道
新智元报道
来源:Stanford
编辑:LRS
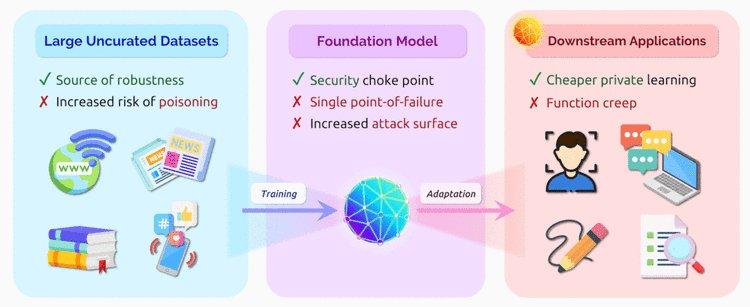
【新智元导读】斯坦福基础模型研究中心仅仅成立两个月就站在了风口浪尖上,各个领域的学者都对基础模型的研究产生质疑,这究竟是「真理」还是斯坦福的一步「臭棋」,只能交给时间去检验。最近实验室的主任华人Percy Liang发了一篇文章回应,基础模型只是研究的第一步,他的目标是更美好的未来。





参考资料:
https://crfm.stanford.edu/2021/10/18/reflections.html

评论