
求求你别再用offset和limit分页了
不需要担心数据库性能优化问题的日子已经一去不复返了。
随着时代的进步,随着野心勃勃的企业想要变成下一个 Facebook,随着为机器学习预测收集尽可能多数据的想法的出现,作为开发人员,我们要不断地打磨我们的 API,让它们提供可靠和有效的端点,从而毫不费力地浏览海量数据。
如果你做过后台开发或数据库架构,你可能是这么分页的: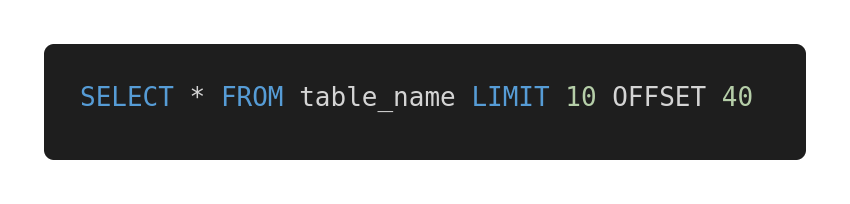 如果你真的是这么分页,那么我不得不抱歉地说,你这样做是错的。
如果你真的是这么分页,那么我不得不抱歉地说,你这样做是错的。
你不以为然?没关系。Slack、Shopify 和 Mixmax 这些公司都在用我们今天将要讨论的方式进行分页。
我想你很难找出一个不使用 OFFSET 和 LIMIT 进行数据库分页的人。
对于简单的小型应用程序和数据量不是很大的场景,这种方式还是能够“应付”的。
如果你想从头开始构建一个可靠且高效的系统,在一开始就要把它做好。
今天我们将探讨已经被广泛使用的分页方式存在的问题,以及如何实现高性能分页。
1.OFFSET 和 LIMIT 有什么问题?
正如前面段落所说的那样,OFFSET 和 LIMIT 对于数据量少的项目来说是没有问题的。
但是,当数据库里的数据量超过服务器内存能够存储的能力,并且需要对所有数据进行分页,问题就会出现。
为了实现分页,每次收到分页请求时,数据库都需要进行低效的全表扫描。
什么是全表扫描?全表扫描 (又称顺序扫描) 就是在数据库中进行逐行扫描,顺序读取表中的每一行记录,然后检查各个列是否符合查询条件。这种扫描是已知最慢的,因为需要进行大量的磁盘 I/O,而且从磁盘到内存的传输开销也很大。
这意味着,如果你有 1 亿个用户,OFFSET 是 5 千万,那么它需要获取所有这些记录 (包括那么多根本不需要的数据),将它们放入内存,然后获取 LIMIT 指定的 20 条结果。
也就是说,为了获取一页的数据:
10万行中的第5万行到第5万零20行
需要先获取 5 万行。这么做是多么低效?
如果你不相信,可以看看这个例子:
https://www.db-fiddle.com/f/3JSpBxVgcqL3W2AzfRNCyq/1?ref=hackernoon.com
左边的 Schema SQL 将插入 10 万行数据,右边有一个性能很差的查询和一个较好的解决方案。只需单击顶部的 Run,就可以比较它们的执行时间。第一个查询的运行时间至少是第二个查询的 30 倍。
数据越多,情况就越糟。看看我对 10 万行数据进行的 PoC。
https://github.com/IvoPereira/Efficient-Pagination-SQL-PoC?ref=hackernoon.com
现在你应该知道这背后都发生了什么:OFFSET 越高,查询时间就越长。
2.替代方案
你应该这样做:
 这是一种基于指针的分页。
这是一种基于指针的分页。
你要在本地保存上一次接收到的主键 (通常是一个 ID) 和 LIMIT,而不是 OFFSET 和 LIMIT,那么每一次的查询可能都与此类似。
为什么?因为通过显式告知数据库最新行,数据库就确切地知道从哪里开始搜索(基于有效的索引),而不需要考虑目标范围之外的记录。
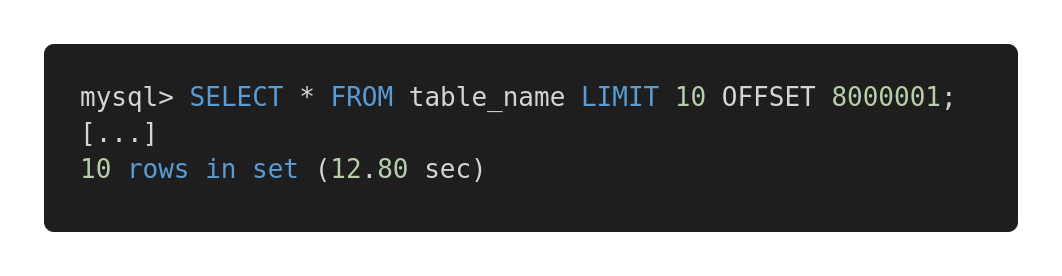
比较这个查询:
 和优化的版本:
和优化的版本:
 返回同样的结果,第一个查询使用了 12.80 秒,而第二个仅用了 0.01 秒。
返回同样的结果,第一个查询使用了 12.80 秒,而第二个仅用了 0.01 秒。
要使用这种基于游标的分页,需要有一个惟一的序列字段 (或多个),比如惟一的整数 ID 或时间戳,但在某些特定情况下可能无法满足这个条件。
我的建议是,不管怎样都要考虑每种解决方案的优缺点,以及需要执行哪种查询。
如果需要基于大量数据做查询操作,Rick James 的文章提供了更深入的指导。
http://mysql.rjweb.org/doc.php/lists
如果我们的表没有主键,比如是具有多对多关系的表,那么就使用传统的 OFFSET/LIMIT 方式,只是这样做存在潜在的慢查询问题。我建议在需要分页的表中使用自动递增的主键,即使只是为了分页。
最后免费给大家分享50个Java项目实战资料,涵盖入门、进阶各个阶段学习内容,可以说非常全面了。大部分视频还附带源码,学起来还不费劲!
附上截图。(下面有下载方式)。
项目领取方式:
扫描下方公众号回复:50,
可获取下载链接
???
?长按上方二维码 2 秒 回复「50」即可获取资料 点赞是最大的支持






