
「前端进阶必备」深入理解现代浏览器
编者按:本文作者李松峰,资深技术图书译者,翻译出版过40余部技术及交互设计专著,现任360奇舞团Web前端开发资深专家,360前端技术委员会委员、W3C AC代表。
各位,如果你的职业是开挖掘机,你说要不要深入理解挖掘机?通常来说,深入理解你操纵的机器才能最终达到人机一体的境界。
当然,你可以说:不用,因为如果挖掘机不好使,我可以换一台。嗯,也有道理。不过,假如你同时又是一名前端开发者,那你要不要深入理解浏览器呢?注意,身为前端,你不太可能有机会因为浏览器不好使就强迫用户换一个你认为好使的。这时候,你好像别无选择了。
不过也不用害怕,今天我们的现代浏览器深度游会非常轻松、快乐。这首先必须感谢一位名叫Mariko Kosaka(小坂真子,https://kosamari.com/)的同行。她在Scripto工作,2018年9月在Google开发者网站上发表了“Inside look at modern web browser”系列文章。本文就是她那4篇文章的“集合版”。为什么搞这个“集合版”?因为她的4篇文章写得实在太好,更难得的是人家亲手绘制了一大堆生动的配图和动画,这让深入理解现代浏览器变得更加轻松愉快。
好了,言归正传。本文分4个部分,对应上述4篇文章(原文链接附后)。
架构:以Chrome为例,介绍现代浏览器的实现架构。
导航:从输入URL到获到HTML响应称为导航。
渲染:浏览器解析HTML、下载外部资源、计算样式并把网页绘制到屏幕上。
交互:用户输入事件的处理与优化。
先来个小小的序言。很多人在开发网站时,只关注怎么写自己的代码,关注怎么提升自己的开发效率。这些当然重要,但是写到一定的阶段,就应该停下来想想:浏览器到底会怎么运行你写的代码。如果你能多了解一些浏览器,然后对它好一点,那么就会更容易达成你提升用户体验的目标。
架构
Web浏览器的架构,可以实现为一个进程包含多个线程,也可以实现为很多进程包含少数线程通过IPC通信。如何实现浏览器,并没有统一的标准。Chrome最新的架构:最上层是浏览器进程,负责协调承担各项工作的其他进程,比如实用程序进程、渲染器进程、GPU进程、插件进程等,如下图所示。
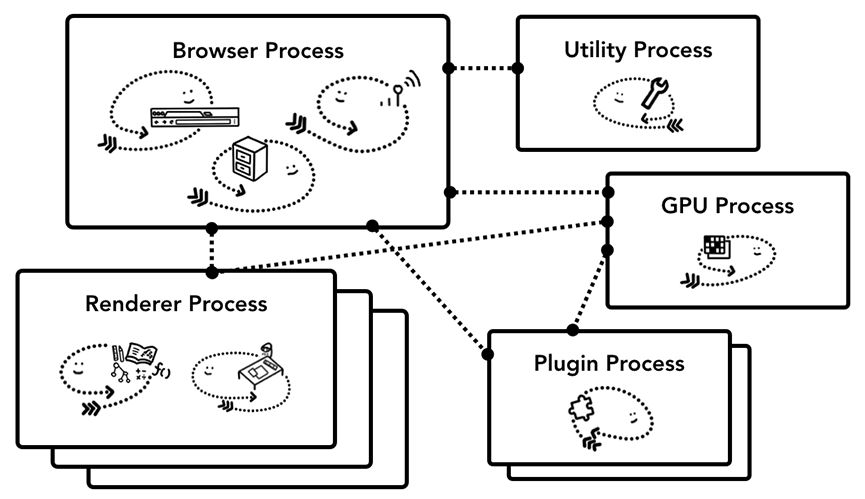
渲染器进程对应新开的标签页,每新开一个标签页,就会创建一个新的渲染器进程。不仅如此,Chrome还会尽量给每个站点新开一个渲染器进程,包括iframe中的站点,以实现站点隔离。
下面详细了解一下每个进程的作用,可以参考下图。
浏览器进程:控制浏览器这个应用的chrome(主框架)部分,包括地址栏、书签、前进/后退按钮等,同时也会处理浏览器不可见的高权限任务,如发送网络请求、访问文件。
渲染器进程:负责在标签页中显示网站及处理事件。
插件进程:控制网站用到的所有插件。
GPU进程:在独立的进程中处理GPU任务。之所以放到独立的进程,是因为GPU要处理来自多个应用的请求,但要在同一个界面上绘制图形。
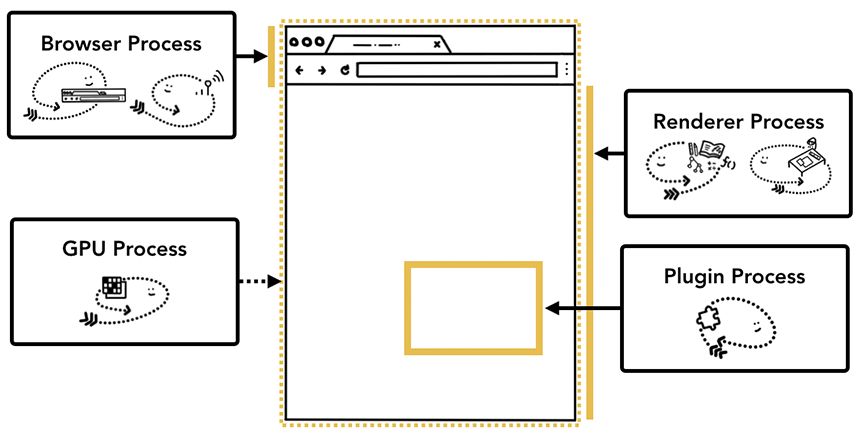
当然,还有其他进程,比如扩展进程、实用程序进程。要知道你的Chrome当前打开了多少个进程,点击右上角的按钮,选择“更多工具”,再选择“任务管理器”。
Chrome的多进程架构有哪些优点呢?
最简单的情况下,可以想像一个标签页就是一个渲染器进程,比如3个标签页就是3个渲染器进程。这时候,如果有一个渲染器崩溃了,只要把它关掉即可,不会影响其他标签页。如果所有标签页都运行在一个进程中,那只要有一个标签页卡住,所有标签页都会卡住。
除此之外,多进程架构还有助于安全和隔离。因为操作系统有限制进程特权的机制,浏览器可以借此限制某些进程的能力。比如,Chrome会限制处理任意用户输入的渲染器进程,不让它任意访问文件。
由于进程都有自己私有的内存空间,因此每个进程可能都会保存某个公共基础设施(比如Chrome的JavaScript引擎V8)的多个副本。这会导致内存占用增多。为节省内存,Chrome会限制自己可以打开的进程数量。限制的条件取决于设备内存和CPU配置。达到限制条件后,Chrome会用一个进程处理同一个站点的多个标签页。
Chrome架构进化的目标是将整个浏览器程序的不同部分服务化,便于分割或合并。基本思路是在高配设备中,每个服务独立开进程,保证稳定;在低配设备中,多个服务合并为一个进程,节约资源。同样的思路也应用到了Android上。
重点说一说站点隔离(http://t.cn/RgNAwLC)。站点隔离是新近引入Chrome的一个里程碑式特性,即每个跨站点iframe都运行一个独立的渲染器进程。即便像前面说的那样,每个标签页单开一个渲染器进程,但允许跨站点的iframe运行在同一个渲染器进程中并共享内存空间,那安全攻击仍然有可能绕开同源策略(http://t.cn/8s1ySzx),而且有人发现在现代CPU中,进程有可能读取任意内存(http://t.cn/R8FwHoX)。
进程隔离是隔离站点、确保上网安全最有效的方式。Chrome 67桌面版默认采用站点隔离。站点隔离是多年工程化努力的结果,它并非多开几个渲染器进程那么简单。比如,不同的iframe运行在不同进程中,开发工具在后台仍然要做到无缝切换,而且即便简单地Ctrl+F查找也会涉及在不同进程中搜索。
导航
导航涉及浏览器进程与线程间为显示网页而通信。一切从用户在浏览器中输入一个URL开始。输入URL之后,浏览器会通过互联网获取数据并显示网页。从请求网页到浏览器准备渲染网页的过程,叫做导航。
如前所述,标签页外面的一切都由浏览器进程处理。浏览器进程中有线程(UI线程)负责绘制浏览器的按钮和地址栏,有线程(网络线程)负责处理网络请求并从互联网接收数据,有线程(存储线程)负责访问文件和存储数据。
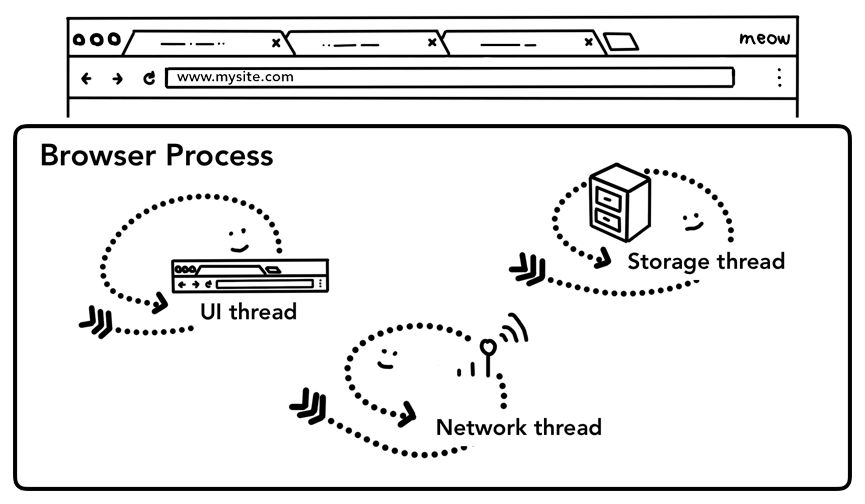
下面我们逐步看一看导航的几个步骤。
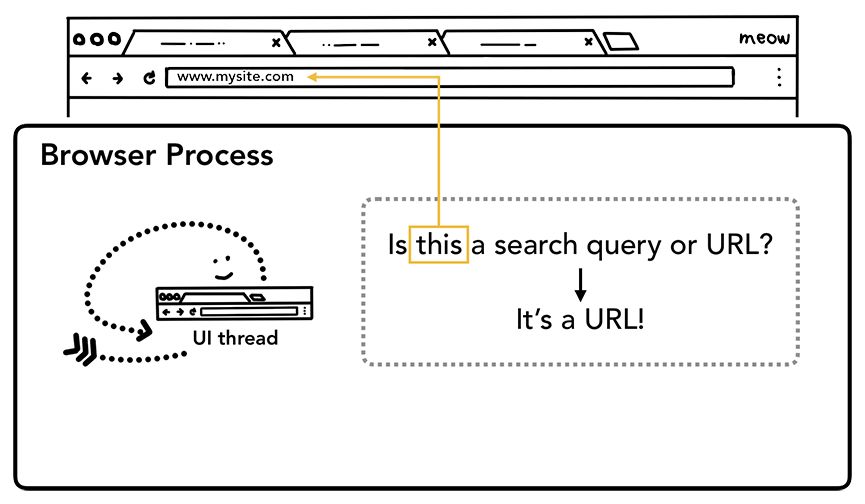
第一步:处理输入。UI线程会判断用户输入的是查询字符串还是URL。因为Chrome的地址栏同时也是搜索框。
第二步:开始导航。如果输入的是URL,UI线程会通知网络线程发起网络调用,获取网站内容。此时标签页左端显示旋转图标,网络线程进行DNS查询、建立TLS连接(对于HTTPS)。网络线程可能收到服务器的重定向头部,如HTTP 301。此时网络线程会跟UI线程沟通,告诉它服务器要求重定向。然后,再发起对另一个URL的请求。
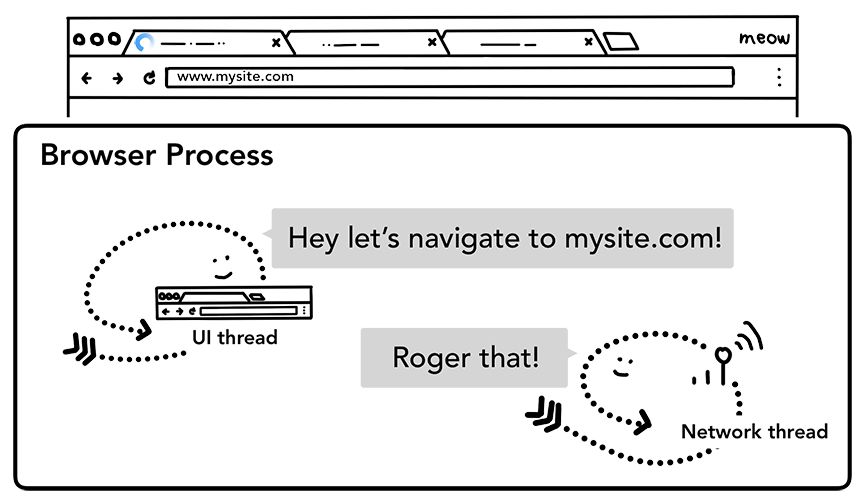
第三步:读取响应。服务器返回的响应体到来之后,网络线程会检查接收到的前几个字节。响应的Content-Type头部应该包含数据类型,如果没有这个字段,则需要MIME类型嗅探(http://t.cn/Rt2gG2J)。看看Chrome源码(http://t.cn/Ai9cZI7D)中的注释就知道这一块有多难搞。
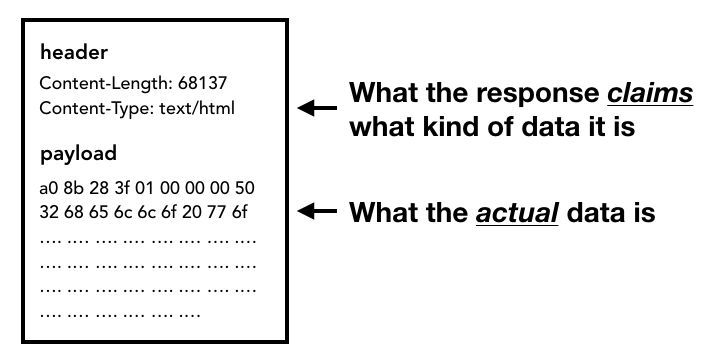
如果响应是HTML文件,那下一步就是把数据交给渲染器进程。但如果是一个zip文件或其他文件,那就意味着是一个下载请求,需要把数据传给下载管理器。
此时也是“安全浏览”(https://safebrowsing.google.com/)检查的环节。如果域名和响应数据匹配已知的恶意网站,网络线程会显示警告页。此外,CORB(Cross Origin Read Blocking,https://www.chromium.org/Home/chromium-security/corb-for-developers)检查也会执行,以确保敏感的跨站点数据不会发送给渲染器进程。
第四步:联系渲染器进程。所有查检完毕,网络线程确认浏览器可以导航到用户请求的网站,于是会通知UI线程数据已经准备好了。UI线程会联系渲染器进程渲染网页。
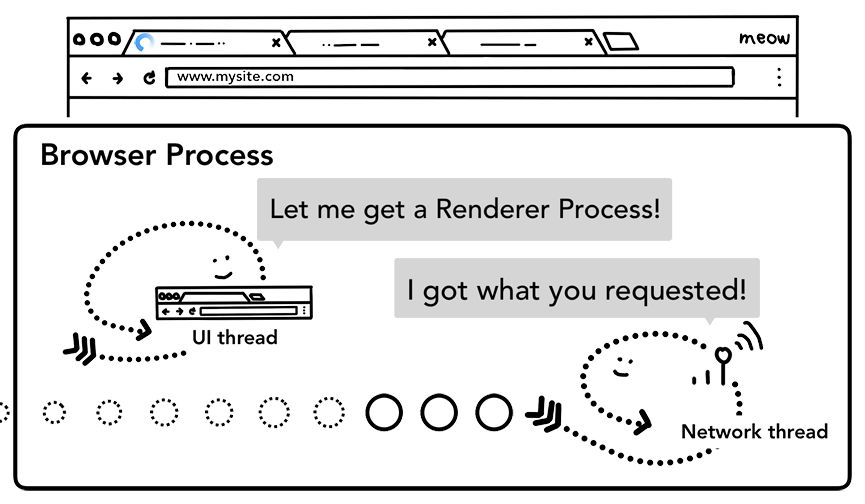
由于网络请求可能要花几百毫秒才能拿到响应,这里还会应用一个优化策略。第二步UI线程要求网络线程发送请求后,已经知道可能要导航到哪个网站去了。因此在发送网络请求的同时,UI线程会提前联系或并行启动一个渲染器进程。这样在网络线程收到数据后,就已经有渲染器进程原地待命了。如果发生了重定向,这个待命进程可能用不上,而是换作其他进程去处理。
第五步:提交导航。数据和渲染器进程都有了,就可以通过IPC从浏览器进程向渲染器进程提交导航。渲染器进程也会同时接收到不间断的HTML数据流。当浏览器进程收到渲染器进程的确认消息后,导航完成,文档加载阶段开始。
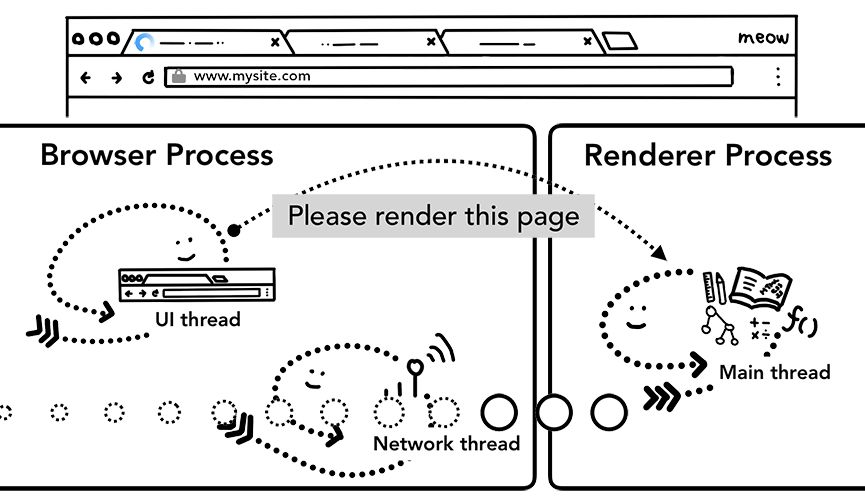
此时,地址栏会更新,安全指示图标和网站设置UI也会反映新页面的信息。当前标签页面的会话历史会更新,后退/前进按钮起作用。为便于标签页/会话在关闭标签页或窗口后恢复,会话历史会写入磁盘。
最后一步:初始加载完成。提交导航之后,渲染器进程将负责加载资源和渲染页面(具体细节后面介绍)。而在“完成”渲染后(在所有iframe中的onload事件触发且执行完成后),渲染器进程会通过IPC给浏览器进程发送一个消息。此时,UI线程停止标签页上的旋转图标。
初始加载完成后,客户端JavaScript仍然可能加载额外资源并重新渲染页面。
如果此时用户在地址又输入了其他URL呢?浏览器进程还会重复上述步骤,导航到新站点。不过在此之前,需要确认已渲染的网站是否关注beforeunload事件。因为标签页中的一切,包括JavaScript代码都由渲染器进程处理,所以浏览器进程必须与当前的渲染器进程确认后再导航到新站点。
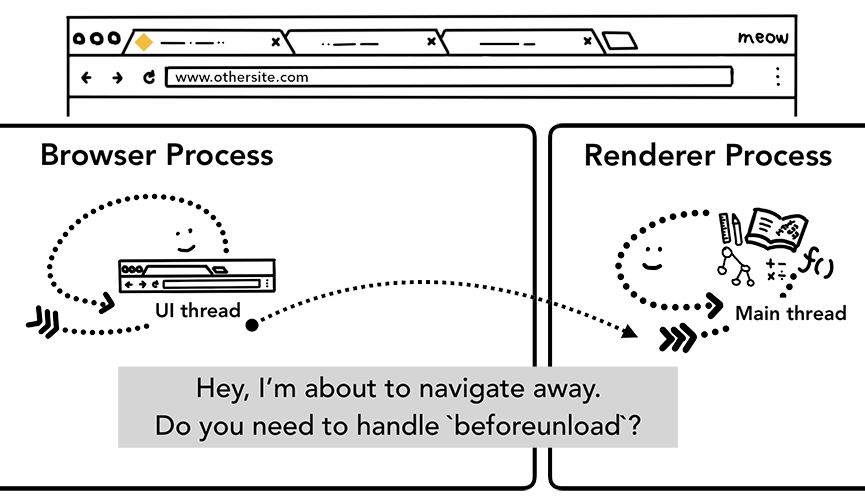
如果导航请求来自当前渲染器进程(用户点击了链接或JavaScript运行了window.location = "https://newsite.com"),渲染器进程首先会检查beforeunload处理程序。然后,它会走一遍与浏览器进程触发导航同样的过程。唯一的区别在于导航请求是由渲染器进程提交给浏览器进程的。
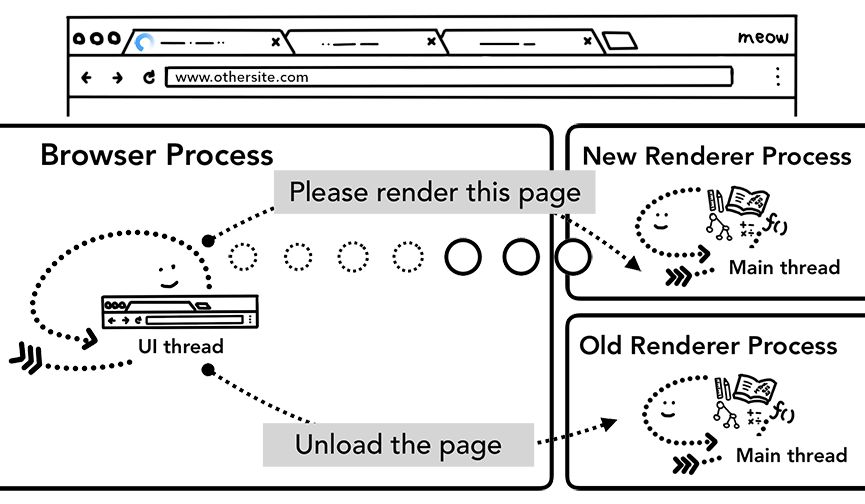
导航到不同的网站时,会有一个新的独立渲染器进程负责处理新导航,而老的渲染器进程要负责处理unload之类的事件。更多细节,可以参考“页面生命周期API”:http://t.cn/Rey7RIE。
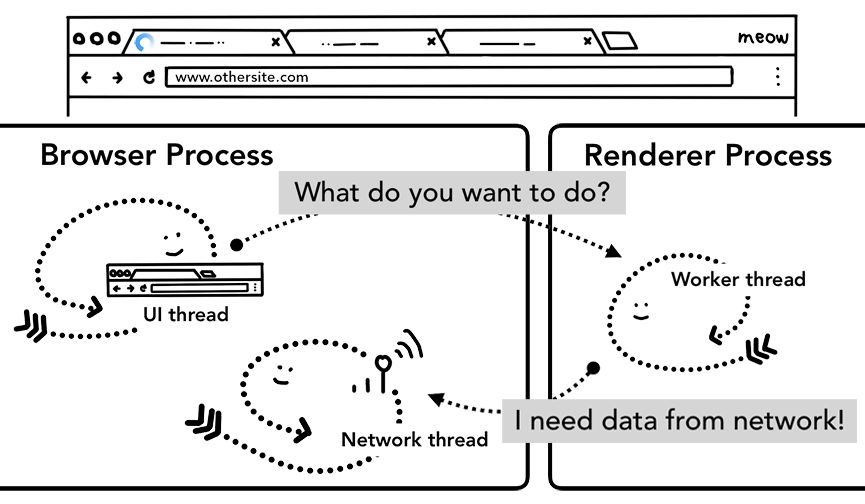
另外,导航阶段还可能涉及Service Worker,即网页应用中的网络代理服务(http://t.cn/R3SH3HL),开发者可以通过它控制什么缓存在本地,何时从网络获取新数据。Service Worker说到底也是需要渲染器进程运行的JavaScript代码。如果网站注册了Server Worker,那么导航请求到来时,网络线程会根据URL将其匹配出来,此时UI线程就会联系一个渲染器进程来执行Service Worker的代码:可能只要从本地缓存读取数据,也可能需要发送网络请求。
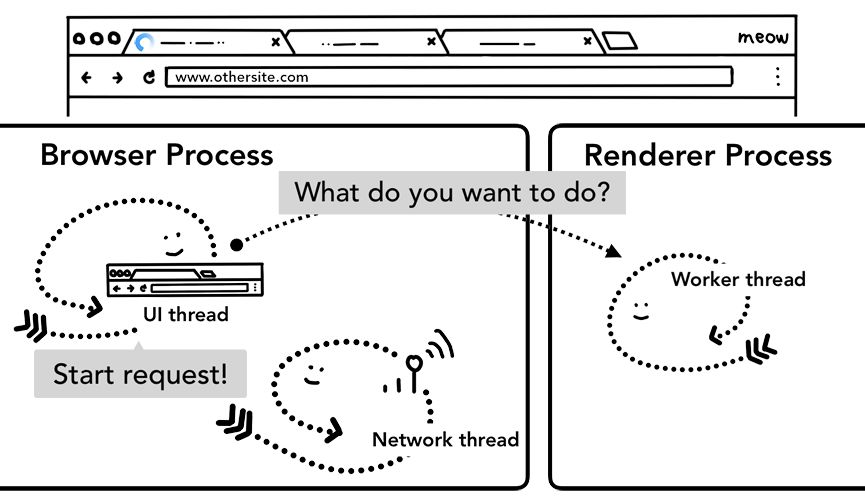
如果Service Worker最终决定从网络请求数据,浏览器进程与渲染器进程间的这种往返通信会导致延迟。因此,这里会有一个“导航预加载”的优化(http://t.cn/Ai9qGJ66),即在Service Worker启动同时预先加载资源,加载请求通过HTTP头部与服务器沟通,服务器决定是否完全更新内容。
渲染
渲染是渲染器进程内部的工作,涉及Web性能的诸多方面(详细内容可以参考这里http://t.cn/Ai9c4nUu)。标签页中的一切都由渲染器进程负责处理,其中主线程负责运行大多数客户端JavaScript代码,少量代码可能会由工作线程处理(如果用到了Web Worker或Service Worker)。合成器(compositor)线程和栅格化(raster)线程负责高效、平滑地渲染页面。
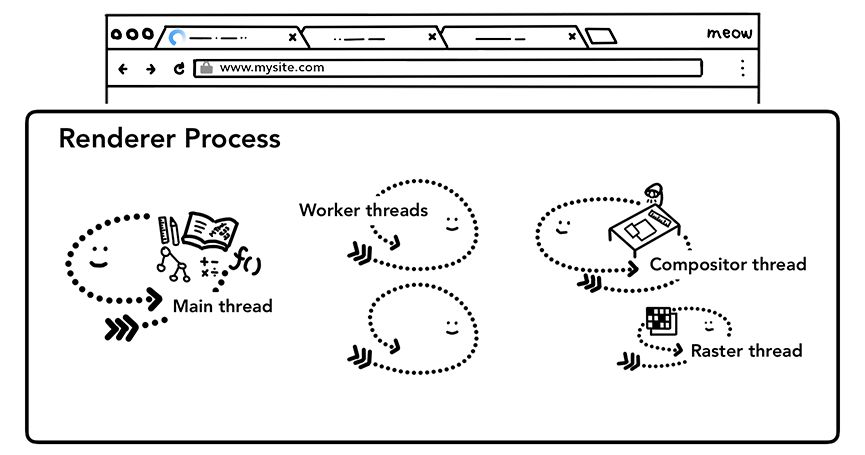
渲染器进程的核心任务是把HTML、CSS和JavaScript转换成用户可以交互的网页接下来,我们从整体上过一遍渲染器进程处理Web内容的各个阶段。
解析HTML
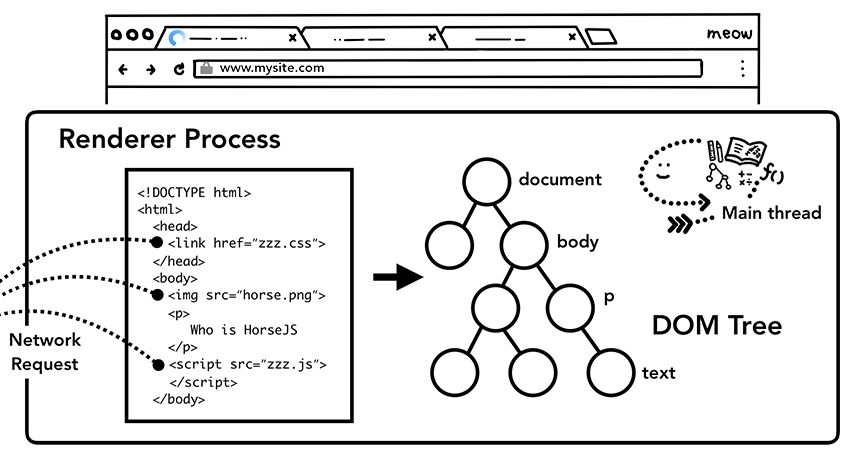
构建DOM。渲染器进程收到导航的提交消息后,开始接收HTML,其主线程开始解析文本字符串(HTML),并将它转换为DOM(Document Object Model,文档对象模型)。
DOM是浏览器内部对页面的表示,也是JavaScript与之交互的数据结构和API。
如何将HTML解析为DOM由HTML标准(http://t.cn/R2NREUt)定义。HTML标准要求浏览器兼容错误的HTML写法,因此浏览器会“忍气吞声”,绝不报错。详情可以看看“解析器错误处理及怪异情形简介”(http://t.cn/Ai9c8i5D)。
加载子资源。网站都会用到图片、CSS和JavaScript等外部资源。浏览器需要从缓存或网络加载这些文件。主线程可以在解析并构建DOM的过程中发现一个加载一个,但这样效率太低。为此,Chrome会在解析同时并发运行“预加载扫描器”,当发现HTML文档中有或时,预加载扫描器会将请求提交给浏览器进程中的网络线程。
JavaScript可能阻塞解析。如果HTML解析器碰到