
淘宝是如何缩短首屏时间、降低服务器压力的?边缘计算告诉你答案!

NO.1
前情
在开始正题之前,我先讲一个内容详情的业务场景和其面临的性能问题
业务特点
图文内容详情业务本身有三个比较大的特点:
内容量大,几十亿的内容量,并且每天还在疯狂增长;
流量大,为了支撑这么大的业务,需要很多服务器成本;
内容数据极具静态化,页面参考如下,除了蓝色标识的数据,其他数据很少会改动;
那我们看这么一个页面的加载和渲染过程大概是什么样的?
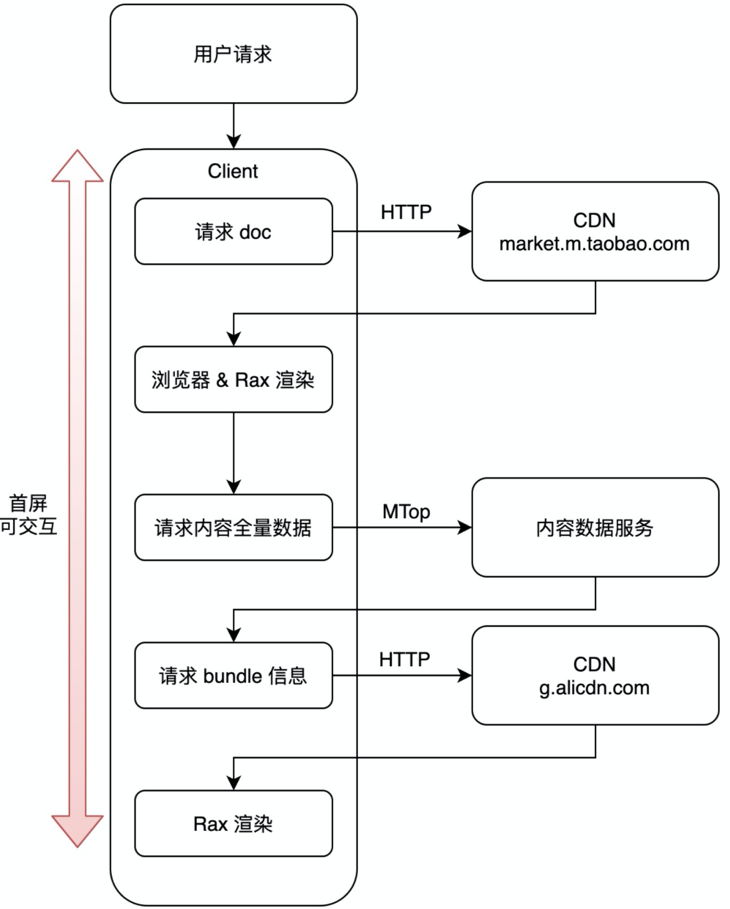
总结问题
从上面的流程可以看出几个问题:
首屏渲染依赖多次请求,导致首屏渲染性能差,尤其是低端机
服务端压力大,每次请求都需要请求到服务端,对服务器也会带来非常大的压力
内容重复渲染,同样一篇内容每个人看到都一样,但是渲染结果又无法共享
大胆思考
这时候我们要结合业务本身的特性进行一些大胆的思考:
研发时预渲染
首先想到的是在研发过程中就对内容进行预渲染并存储起来,但是这个方案很快被 pass 了,有两个主要原因:
内容量太大:内容数量特别大,并且一篇内容在不同的场景(上百)还会展示出不同的风格,全部静态化存储 CDN 资源浪费严重
更新成本大:内容会被达人修改,或者一些打擦边球的内容需要尽快下线
按需渲染结果静态化
既然数据绝大部分是静态化的,为什么不能把用户访问时静态数据和代码渲染后的结果进行静态化,这样不是省去了 renderToHTML 的过程了吗?,如下图所示

那讲到这里,我们首先想到的是通过 SSR renderToHTMLString,然后把渲染后的结果进行缓存,这样访问到相同内容的请求可以直接将缓存结果返回,那这样有什么好处呢:
减少重复渲染,提升首屏性能
降低接口服务的压力
基于访问存储,避免资源浪费
但是同时也带来了其他的问题:
SSR 应用服务器距离用户远带来的白屏时间延长
SSR 本身的压力也会提升,因为这样意味着每一个用户请求都要经过 SSR(虽然可以走缓存)
缓存数据存储的问题,存哪里,内存肯定不满足需求,因为刚开始就讲到了内容量特别大,这时候要借助于其他的一些快速存储的云服务,显得特别复杂
这时候我们就在想,如果能够将渲染的结果或者渲染的过程放在 CDN 上就好了,因为 CDN 节点比较多,并且在世界范围部署广泛,所以我们尝试着将 SSR 渲染的结果存储在 CDN 上,但是随之带来另外一些问题:
SSR 服务器出错了怎么办,现在 CDN 是一种配置生效系统,如下图所示,我们上文说到了图文详情的流量特别大,这也就意味着各种异常情况都要考虑,像 SSR 服务器宕机带来的风险我们也必须有降级方案,保障不影响用户

对于两种特殊场景需要及时更新缓存:擦边球内容要能够及时下线,页面代码更新要能够批量更新缓存,目前通过 CDN 的配置项是解决不了这些问题的
这时我们正好了解到了 CDN 正在推广一种边缘计算的能力(EdgeRoutine,下面会做简单的介绍),简单点理解就是可以在 CDN 请求返回结果之前加上你的自定义脚本,并且可以访问 CDN 的数据,那就意味着我们可以控制 CDN 请求返回的内容或者HTTP 状态,好像基本能够解决我上面说的两个问题,所以按照当前的技术能力和我们的需求我们针对请求链路进行了改造:
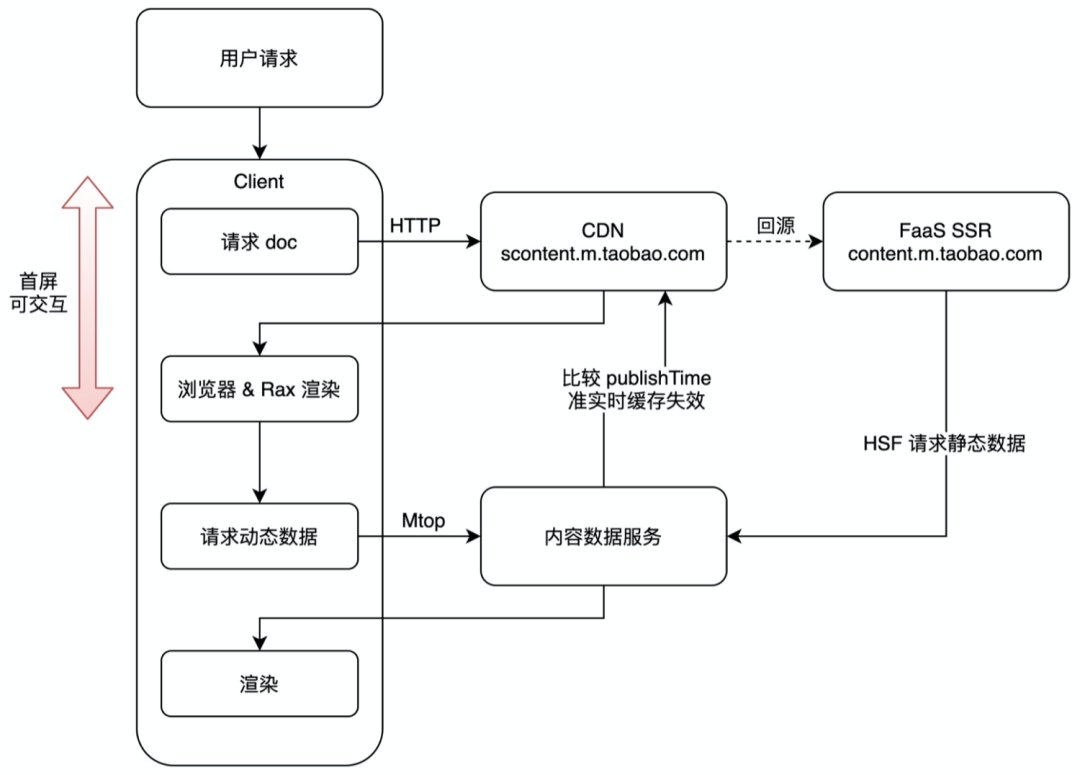 具体的降级和缓存清除的逻辑没有画出来,因为那是解决安全生产的问题,我主要想强调方案调整带来的性能提升。所以从上图可以看出,一个正常的请求首先会请求到 CDN,CDN 如果发现缓存中没有的话会回源到 SSR 服务器,这样首屏其实只需要一个网络请求,有效的提升的首屏性能和降低了服务器压力。细心的你会发现页面首屏后还进行了一次请求动态数据的动作,因为还有一个对实时性要求比较高的数据需要展示给用户,但是并不影响用户浏览,另外虽然内容不怎么会更新但也会存在更新的情况,所以我们会在浏览器端做一次缓存的时间和内容最新更新时间的对比,如果发现不一致,会主动做缓存更新,这样,既保证了性能,又避免了缓存过期
具体的降级和缓存清除的逻辑没有画出来,因为那是解决安全生产的问题,我主要想强调方案调整带来的性能提升。所以从上图可以看出,一个正常的请求首先会请求到 CDN,CDN 如果发现缓存中没有的话会回源到 SSR 服务器,这样首屏其实只需要一个网络请求,有效的提升的首屏性能和降低了服务器压力。细心的你会发现页面首屏后还进行了一次请求动态数据的动作,因为还有一个对实时性要求比较高的数据需要展示给用户,但是并不影响用户浏览,另外虽然内容不怎么会更新但也会存在更新的情况,所以我们会在浏览器端做一次缓存的时间和内容最新更新时间的对比,如果发现不一致,会主动做缓存更新,这样,既保证了性能,又避免了缓存过期收益
通过做如上的方案我们在性能,业务指标提升,服务器压力上都有很大的收获
性能提升明显,低端机首屏 1S 内
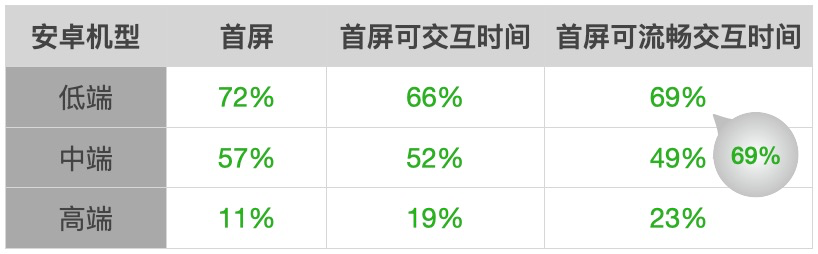
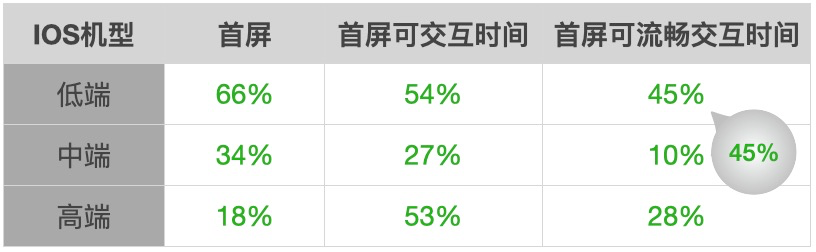
业务指标提升明显

服务器压力降低 80%
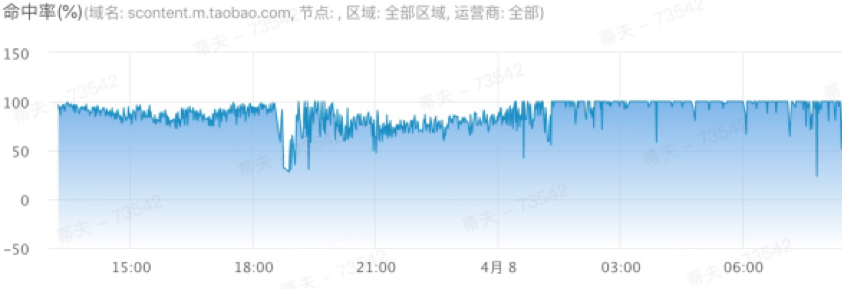
NO.2
边缘计算 ER
关于边缘计算,大家可以参考:https://developer.aliyun.com/article/757950
本篇文章贴出几张核心的图供大家参考:
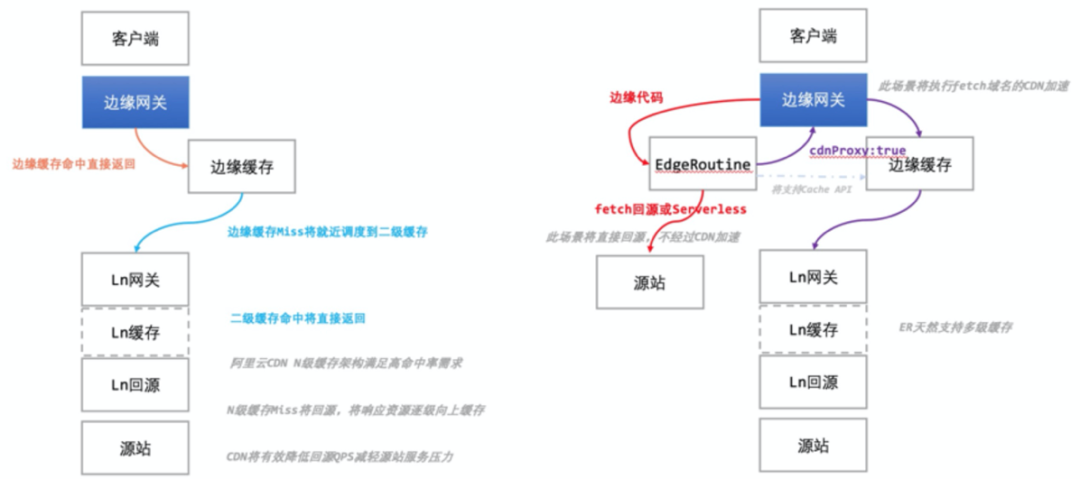

简单总结就是我们可以在 CDN 返回结果之前进行一些逻辑计算,并且这部分代码兼容 ES6 的规范,并且可以通过 HTTP 和外界服务进行沟通,达到有效的控制的 CDN 返回的表现的目的
优势-共享
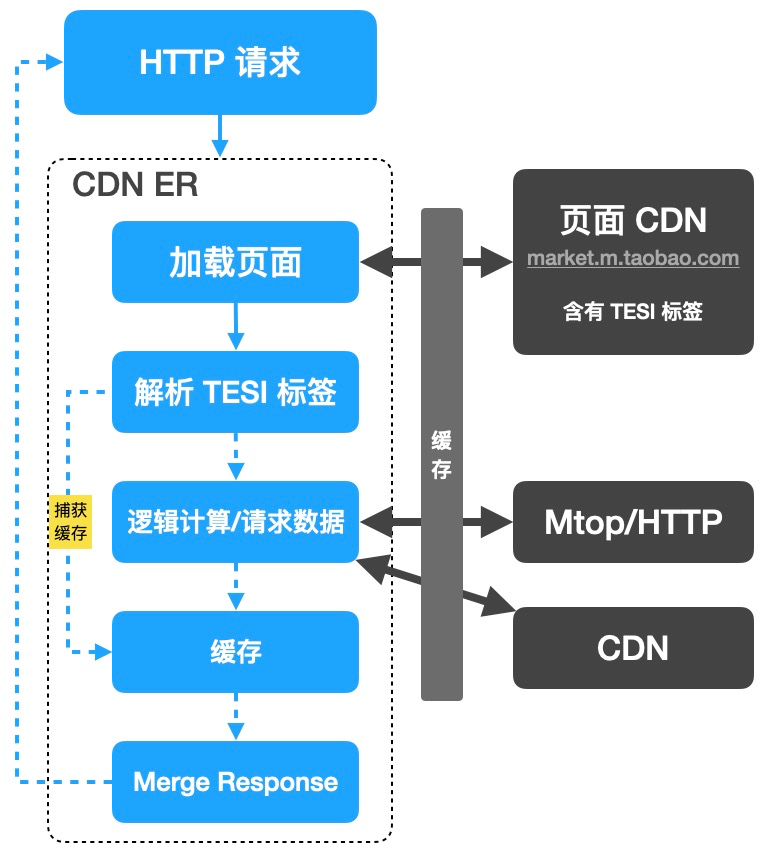
在此我想重点介绍下边缘计算的共享优势,对于边缘计算来说,它不仅可以处理一些逻辑计算,还可以将计算的结果进行存储,存储能力是 Swift 的 Open API ,实现数据的 KV 存储,这就意味着,这个存储空间可以非常大。说道这里大家可能会感觉比较抽象,可以看下面这张图,上面是指我们正常的网络请求,用户手机直连数据服务器和页面 CDN,这就意味每个人都要经历加载页面,加载数据,渲染页面等逻辑。下面是指 CDN ER 做了一层代理,这就意味着用户手机链接 CDN,CDN 负责和数据服务器和页面 CDN 进行沟通。那样这样有什么好处呢,这就意味着我们可以将像内容详情这种数据或者渲染的结果直接存储在 CDN 上,并且不用担心存储内容太多影响性能,这就就像一群人公用一部手机,你看完传递给下一个人刷新看相同的内容
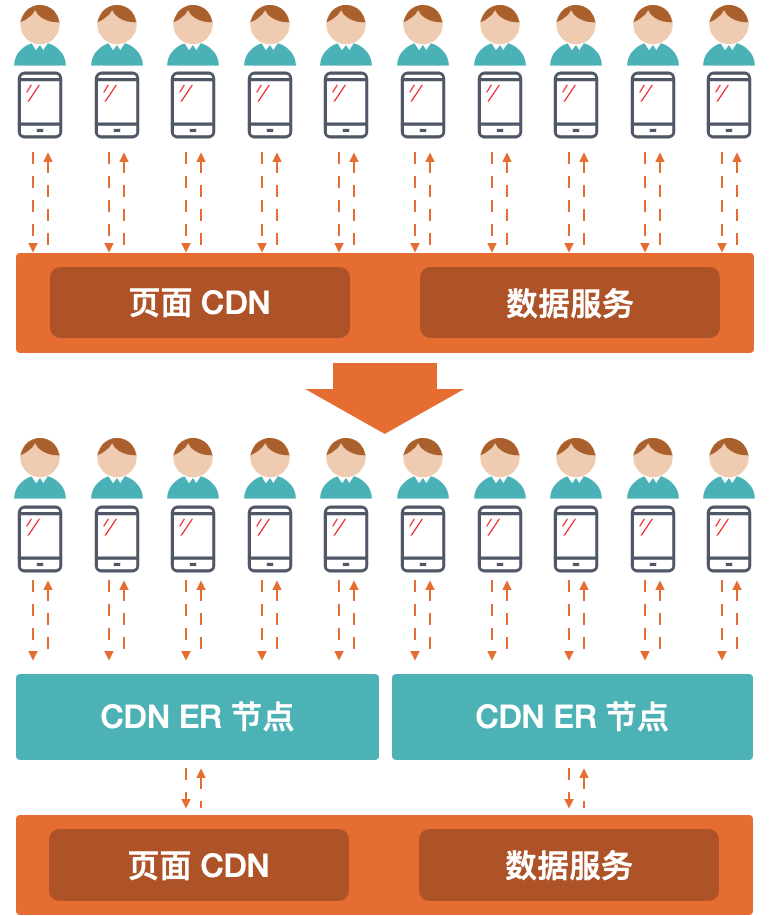
优势-计算能力
既然能在 CDN 的 ER 节点上写 ES6 的代码,并且可以请求数据,这就意味着我们可以在ER上执行很多逻辑,在这里我整理一些常用的:
 那基于这些能力我们还能支持哪些合适的场景落地呢,所以我们针对淘系的场景进行了调研
那基于这些能力我们还能支持哪些合适的场景落地呢,所以我们针对淘系的场景进行了调研NO.3
场景调研
整体调研有一个统一的思路,就是要找适合静态化的高流量场景,就是说页面是否有可被缓存的数据或者渲染结果,为此我们整理了一个简单的表格:
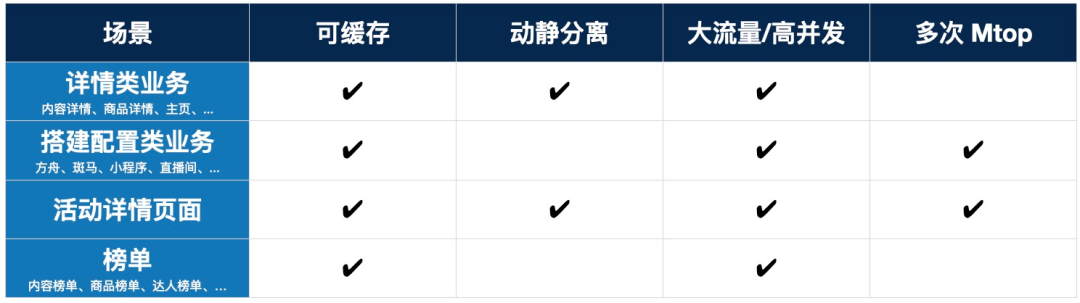
接下来我做一些简单的说明:
末端类型的页面一般是有内容主体,并且这些主体数据不是千人千面的,例如上图提到的,内容详情、商品详情、个人主页、评论列表、评论详情
搭建类业务,配置信息目前需要异步加载,模块还要异步加载,这些配置化的东西是否可以直接和页面一起输出
榜单类型的页面,同样的一个榜单,每个人看到的都一样,但是榜单要更新,但是这个更新并非真正的实时,一般为了承载更大的流量,数据都是准实时,例如分钟级更新,小时级更新,甚至一天更新一次,那在有效期内其实可以将榜单数据或者榜单的渲染结果缓存起来的
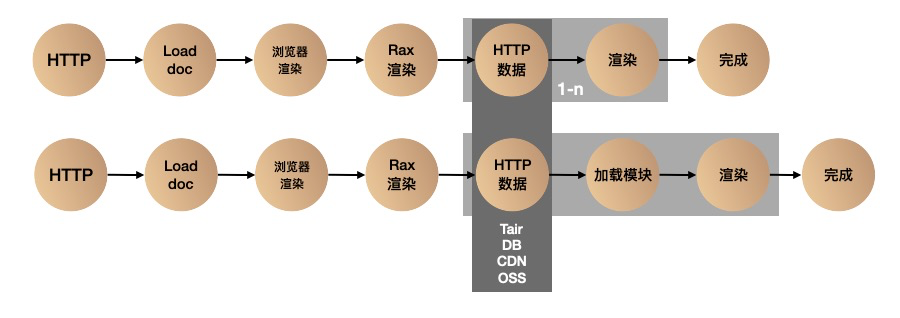
这里说一下,其实在数据侧有很多静态化策略已经被用的游刃有余,例如借助于 CDN、Tair、OSS,如果我们能够让静态化的过程变得更加简单和通用,例如将数据或者页面渲染结果直接存储在 CDN,下次请求就可以直接复用渲染结果,有没有可能变成如下模式:
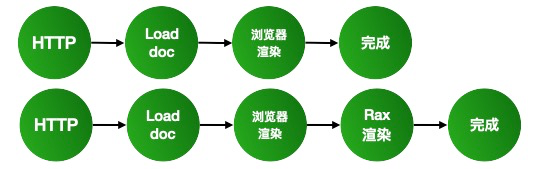
其实就是两个原则:
减少 HTTP 请求次数,尽可能一次请求出首屏;
复用渲染结果:将渲染过程放在 ER 上并缓存下来,直接复用渲染结果,或者针对我们常用的骨架图方案,是否能够换成静态数据的渲染结果;

NO.4
场景标准化
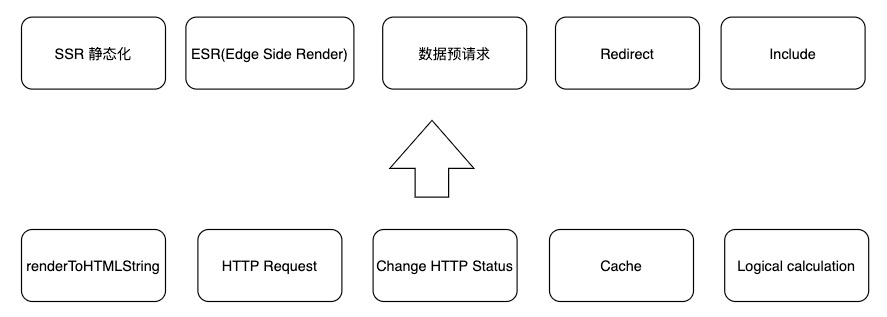
最终结合 ER 的能力和我们的业务场景,我们抽象为以下四种:
SSR 静态化:指快速将 SSR 的结果缓存在 CDN 上
ESR(Edge Side Render):顾名思义,将 renderToHTMLString 的过程放在 ER 节点上,并且缓存渲染结果
数据预请求:就是指将本来需要渲染后再请求数据的逻辑前置在 ER 上,将请求的结果合并返回给浏览器
Redirect:重定向,是指在 ER 上根据逻辑实现重定向的能力,相对于以往我们前端通过制定 location.href 的方式要快很多了,这个可以满足逻辑分流需求,例如 AB
Include:片段注入,可以注入任何文字内容到任意文件类型中,一种更加通用的方案
经过我们的测试和实践,针对前三种产出了一些性能报告也可以分享给大家,虽然不全面,但是能说明问题,由于测试的页面场景不一样,所以相互(数据预加载、 ESR、SSR 静态化)没有必要作对比,以下指标是相对没有使用 TESI 的能力进行的对比
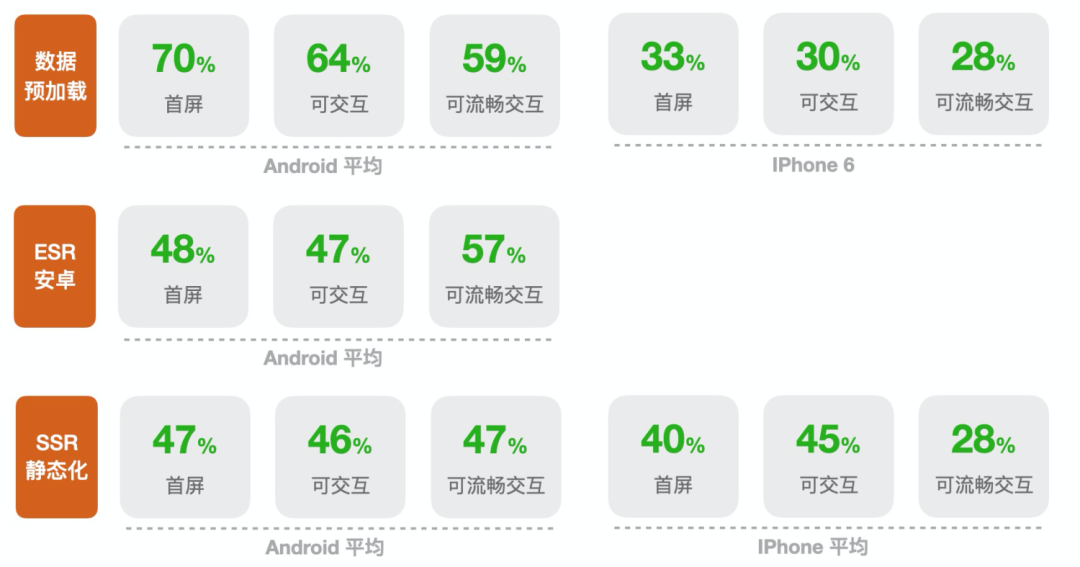
NO.5
标准化接入
虽然 ER 有这么多优势,但是接入成本还是比较大的,例如要注意 ER 容器本身的各种限制、调试成本、云资源申请成本等,所以我们需要提供一种标准的接入方式,初步了解到 W3C 有一个 ESI 的标准,维基百科介绍如下:
Edge Side Includes or ESI is a small markup language for edge level dynamic web content assembly. The purpose of ESI is to tackle the problem of web infrastructure scaling. It is an application of edge computing.
简单翻译一下:ESI 是一种边缘级 web 动态化的小型标记语言。ESI 的目的是解决 web 基础设施的扩展问题。它是边缘计算的一种应用方案原理如图:
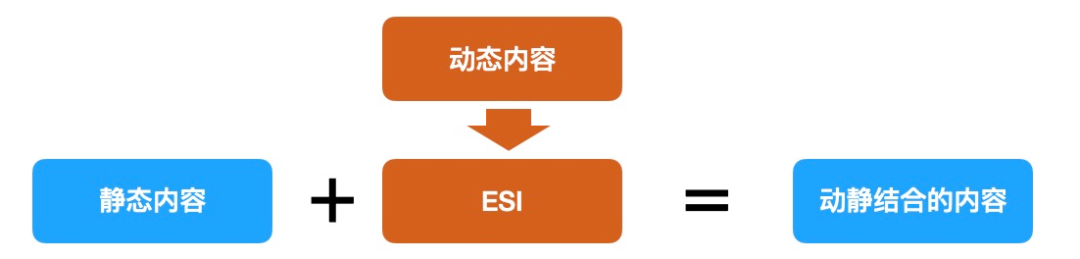
其实就是说,可以通过标签注入的方式,实现动静内容混合混合输出,比较符合我们的诉求,并且其在语法上也比较丰富
 但问题是 ESI 是一种 XML 的标准,阿里有很多页面资源类型并不是 HTML,例如 weex、小程序等等,它们加载的页面并不是 HTML,并且我们要满足标准化场景的接入,所以我们需要在 ESI 的基础上进行改造-TESI(Taobao Edge Side Includes),合适的才是最好的
但问题是 ESI 是一种 XML 的标准,阿里有很多页面资源类型并不是 HTML,例如 weex、小程序等等,它们加载的页面并不是 HTML,并且我们要满足标准化场景的接入,所以我们需要在 ESI 的基础上进行改造-TESI(Taobao Edge Side Includes),合适的才是最好的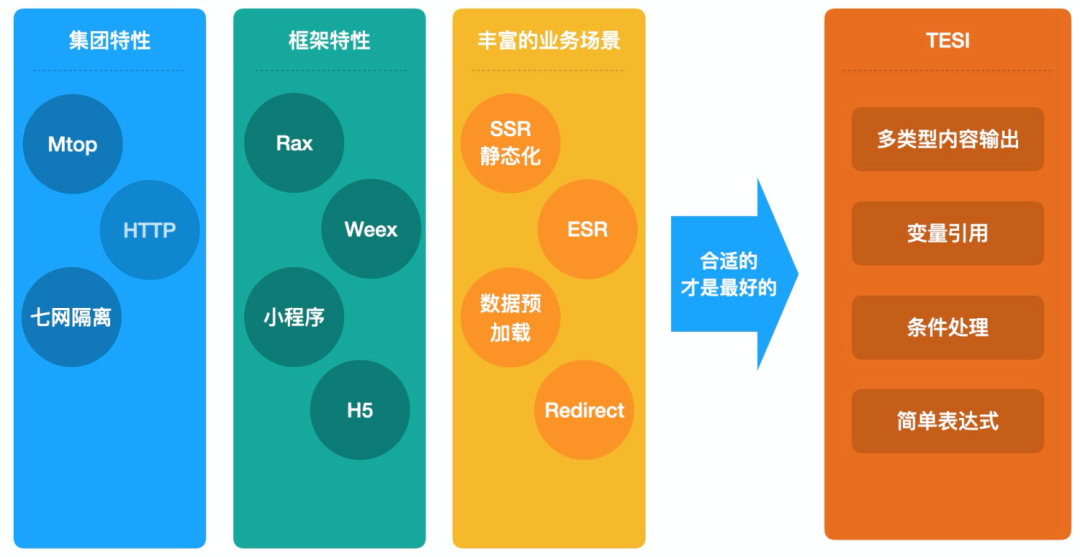
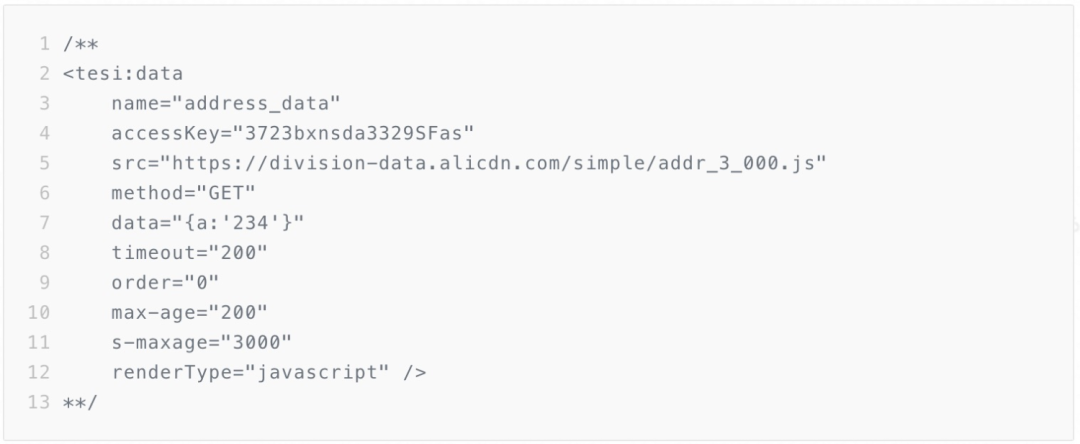
基本的代码形式如何,我们以数据预加载为例,如下 H5 中出现 TESI 标签(鼠标选中部分)

TESI 标签描述了一个 http 接口的信息,并且配置了其缓存时长 s-maxage,ER 会解析这个标签,并且在 ER 上发起请求,并将请求的数据按照 s-maxage 配置的值进行缓存,这就意味着下一次请求到相同的节点,就会直接返回缓存结果
渲染结果如下:

我们看其实像数据预加载这种情况,在 HTML 中会渲染成一个 script 标签,其中存储的是一个全局变量方便运行时获取。其实 TESI 标签不仅可以用于 HTML 中,JS 中可以出现 TESI 标签,如下:
渲染后
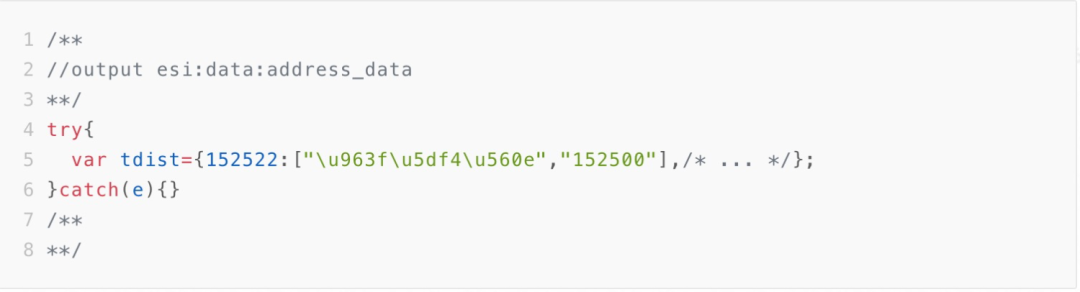
其基本渲染原理如下,比较简单,这里不做赘余:
 还有其他几种类型的标签如下:
还有其他几种类型的标签如下:| 标签名 | 描述 |
| tesi:data | 数据预加载 |
| tesi:esr | 边缘渲染 |
| tesi:ssr | SSR 静态化 |
| tesi:redirect | 逻辑跳转 |
| tesi:include | 区块引入 |
NO.6
稳定降级
整个 ER 执行的过程会遇到各种各样的问题,甚至 ER 都有挂掉的风险,所以需要有稳定降级的预案保证不影响用户,所以我们会将 CDN 源站指向页面 CDN 的源站,这样,及时 ER 解析出现问题,可以把解析前的页面直接返回给浏览器
NO.7
缓存管理
存储
ER 提供了两种缓存:内存缓存(以下简称 Cache)和 Swift KV 缓存(以下简称 KV),这两种模式在存取速度、体积大小、QPS 上都有差别,总结基本如下:
| 指标 | VS | 胜出 |
| 存储空间 | Cache ﹤ KV | KV,可达 几十 GB |
| QPS | Cache ﹥ KV | Cache |
| 存取速度 | Cache ﹥ KV | Cache |
| 存储副作用 | Cache ﹥ KV | KV |
这里指的存储副作用是指,存储大小对于 ER 性能的影响,存储在缓存中,如果存储体积接近内存大小,首先会影响 ER 执行性能,严重会导致 ER 容器重启综合以上两种对比结果来看各有千秋,但合适的场景用合适的模式才是最好,为此我们设计了二级缓存模式,一级缓存存入内存,二级缓存存入 KV,主要完成如下三个重点逻辑:
动态计算热度内容推入一级缓存
采用 LRU(最近最久未使用算法)的模式实现一级缓存和二级缓存的数据推出,充分利用缓存空间
每一个标签设定指定的缓存空间,避免缓存分配不均,导致相互影响
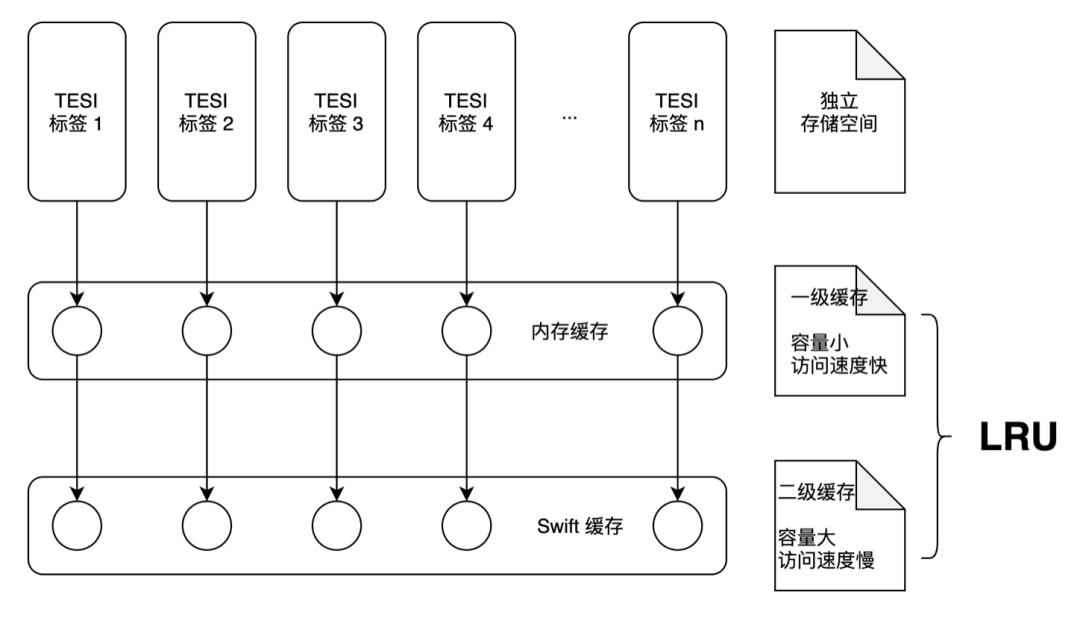
缓存失效
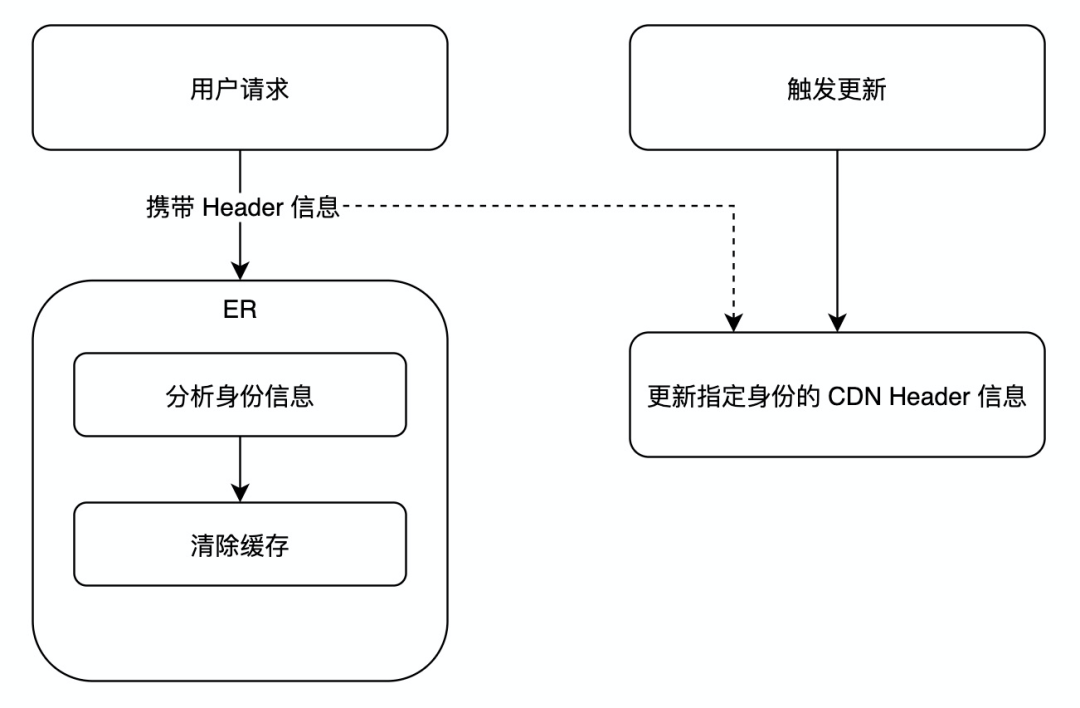
缓存的内容需要具备快速清除的能力,因为数据会更新、页面 bundle 会更新,特别是遇到紧急情况,例如线上问题紧急修复,需要能够实现缓存及时清除,所以需要一定的策略来满足需求,总体清除的逻辑会依赖请求,根据标签的身份信息进行清除
NO.8
接入过程
为了满足系统稳定性和安全生产的要求,TESI 标签的生产过程是需要被管控起来的,所以我们要提供一个 TESI 的运维系统主要满足以下几个需求:

运维系统使用过程如下:
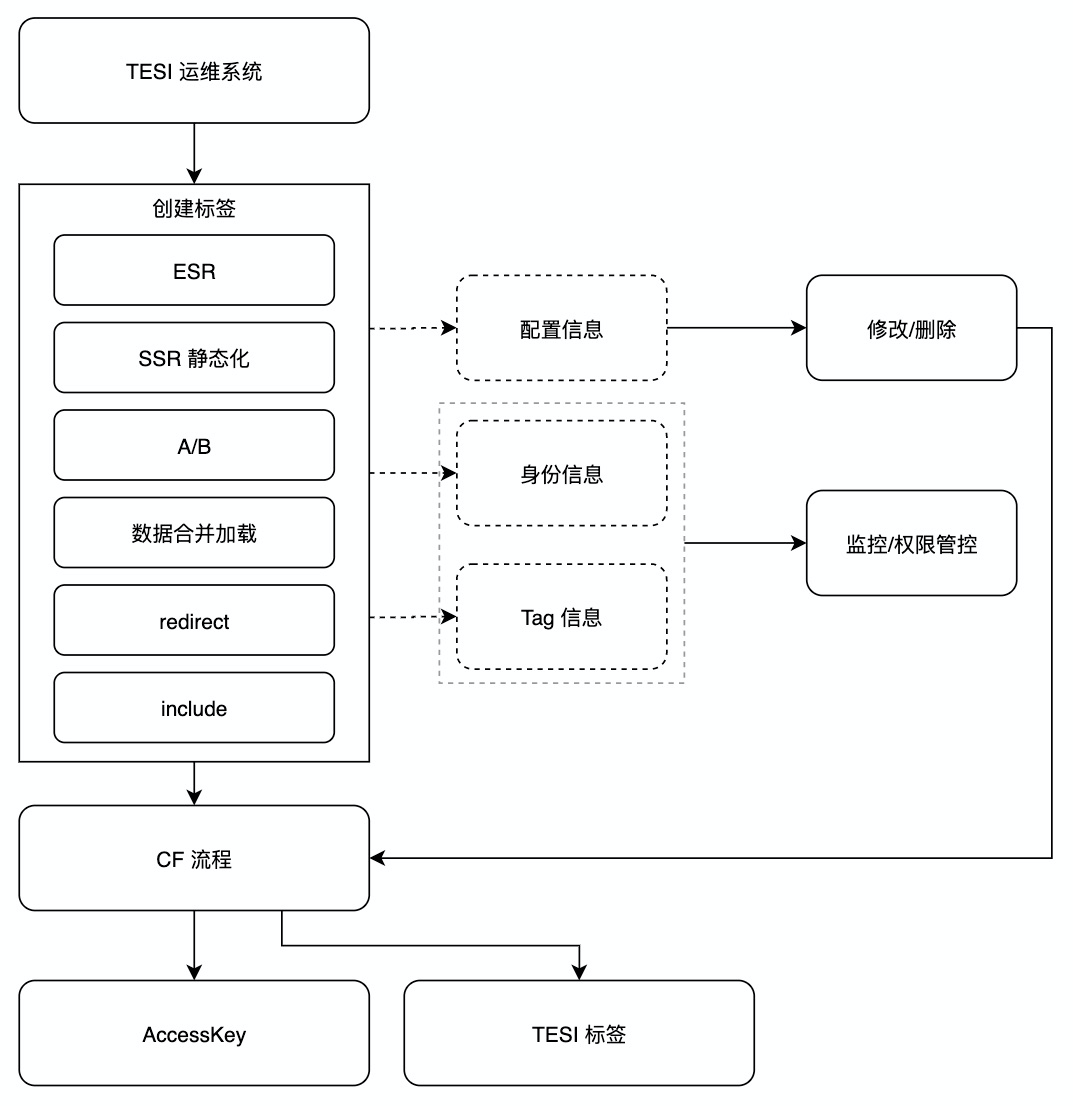 运维系统主要为了生成一个可用的 TESI 标签,真正发布生效我们会借助于 DEF 发布系统,这样既沿用了标准,安全生产相关能力我们也不用重复建设了,基本流程如下:
运维系统主要为了生成一个可用的 TESI 标签,真正发布生效我们会借助于 DEF 发布系统,这样既沿用了标准,安全生产相关能力我们也不用重复建设了,基本流程如下: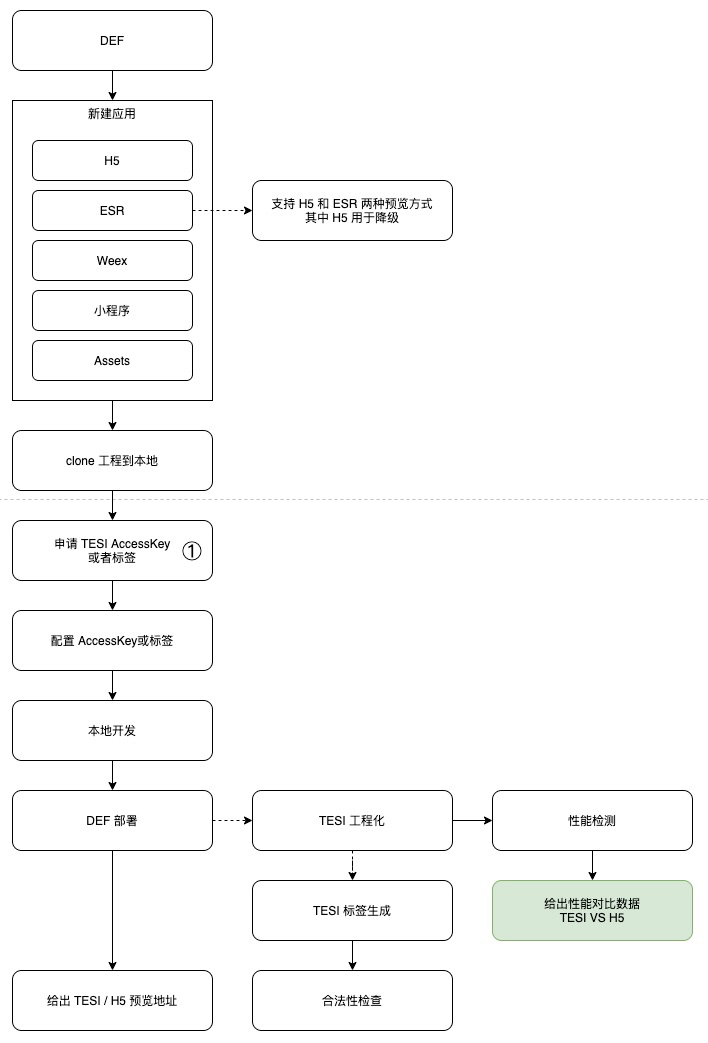
NO.9
附录
名词介绍:
ER:EdgeRoutine
ESR: Edge Side Render
SSR: Server Side Render
ESI: Edge Side Includes
TESI: Taobao Edge Side Includes
DEF: 阿里前端发布系统
Swift:阿里云 CDN 文件存储
常用服务类型简介
其基本的配置信息和执行过程如下,大家可以参考下:


