
笑了,面试官问我遇到过线上问题没有?

不知道面试的时候,面试官问你遇到过线上性能问题没有?
GC频繁,CPU飙高,任务队列积压,线程池任务拒绝等等,对于看重项目经验的面试官,这种问题基本是标配。
问线上问题处理的经过,问题定位,排查的思路,怎么做的业务快速止血。
一方面考察候选人项目的真实性,一般遇到线上问题大部分时候是系统主要负责人着手处理的,所以如果你处理过线上问题,也从侧面反映你的重要性。
另外还能知道面试者是不是真的从原理上掌握了问题的根本原因,对技术的热忱等。
另外建议大家处理完线上问题,排查了原因之后不要停,把排查过程和问题原因记录下来,一方面以后遇到类似问题可以基于已有的经验快速反应,另外就是一定让自己的知识体系化,怎么体系化呢?
就需要把日常的技术问题做归类总结。
这篇文章主要是给大家一个参考,讲讲安琪拉遇到的线上问题以及排查思路。
问题描述
一个在普通不过的周末,手机突然收到线上告警短信,吓得我一激灵,赶紧从床上爬起来打开电脑。
起因: 消息队列积压了十几万消息,第一反应,什么情况...

赶紧穿衣服,对待线上问题要严肃。
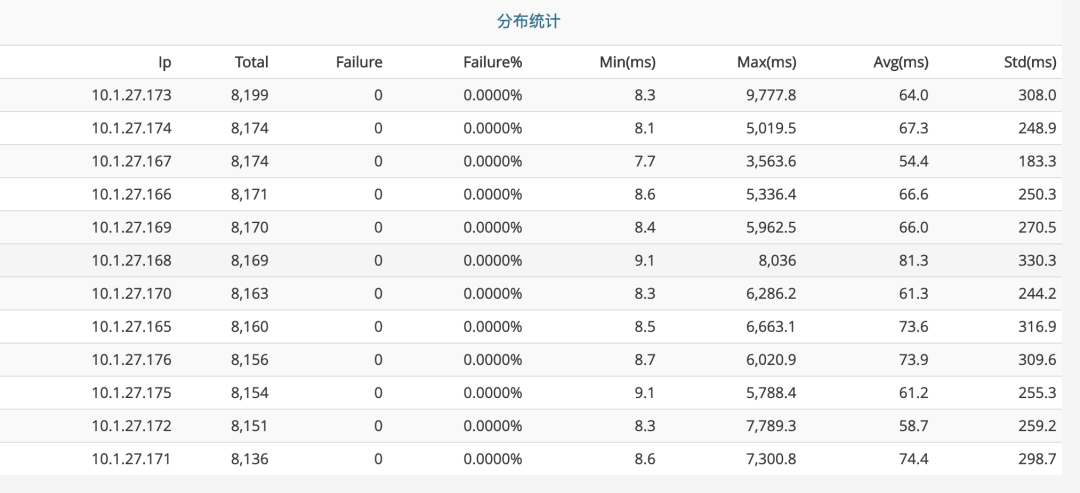
如下图,【待处…】 那一列就是指队列中“待处理的”消息。
消息积压,指的是消息的消费速度跟不上生产的速度,消息在消息队列中。
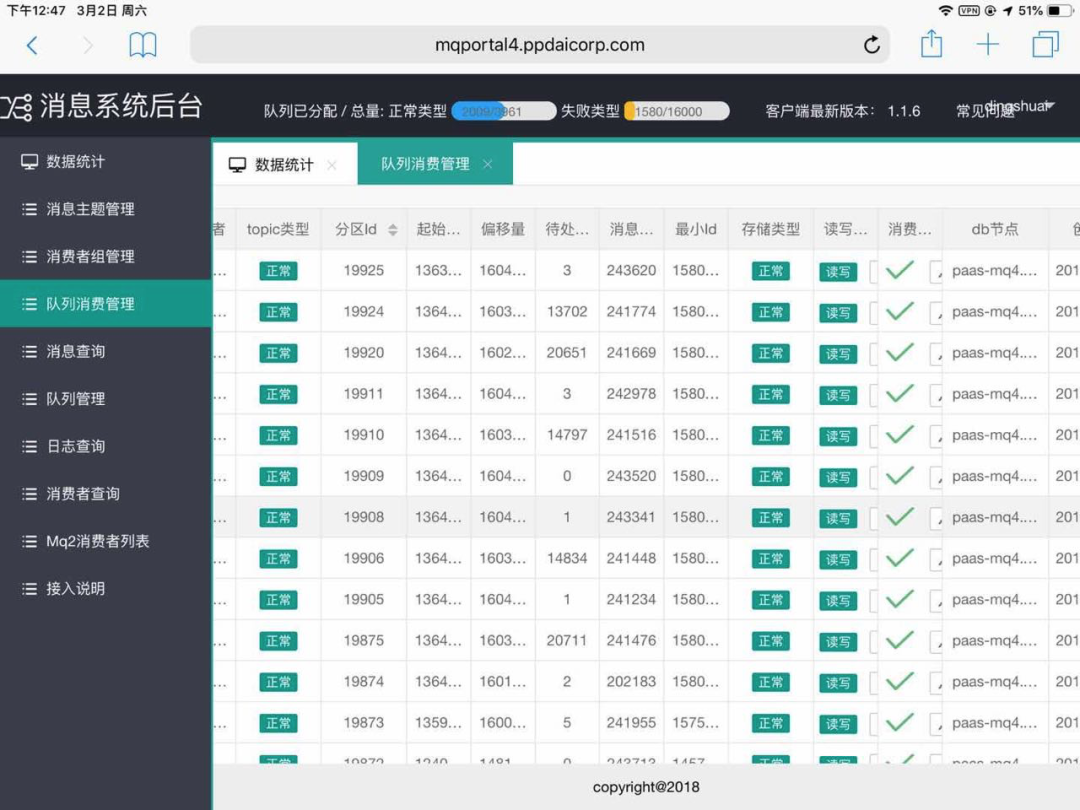
可以看到有好几个分区已经积压了上万条消息。
问题排查
立即开始问题排查,遇到线上问题,一定是保证最快速度止血,降低对业务的影响。
然后才是排查原因,当然有的问题也需要快速找到原因。
第一反应是不是入口流量太大,处理消息的线程池核心线程数满了,任务都在排队,但是看了入口流量并没有尖刺。
看监控的消息消费任务耗时,如下图:
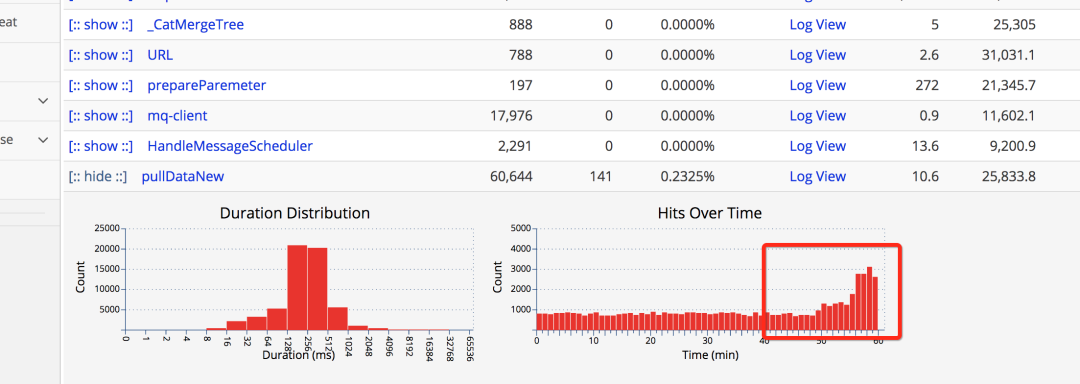
可以看到耗时在不断增加。那就需要看处理耗时增加原因了,为什么处理任务的耗时上涨了。
查看消息日志,如下:
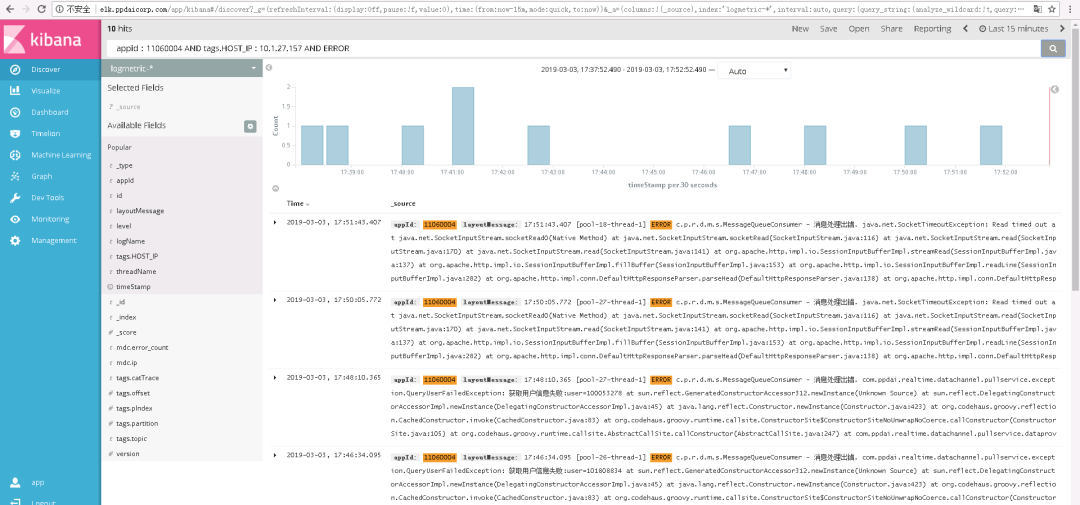
发现有很多网络接口超时的异常:

排查到这里,大致得出结论:
消息处理任务依赖下游系统接口,连接下游接口超时,连接下游接口设置的超时时间不算短,为什么下游接口如此多SocketTimeOut呢?

恰好下游系统也是我负责的系统,非常熟悉。
于是重点开始看下游的系统监控,发现相关的接口调用的单机耗时时间极不规律,如下图所示:
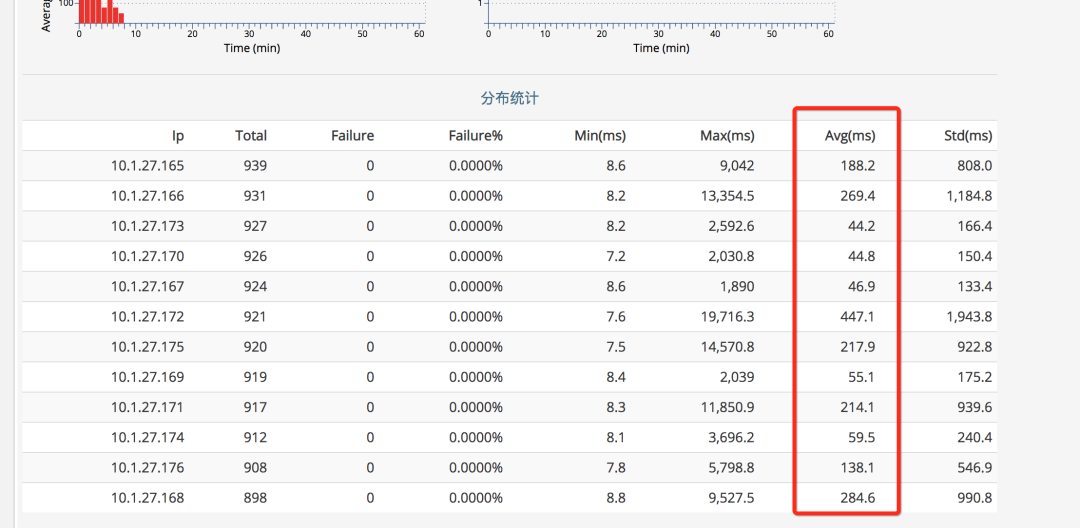
对比一下日常这个接口的耗时时间,如下图,日常都没有超过 100ms 的:
初步猜测这个地方是出现了问题,查看下游系统的监控大盘,发现了问题:
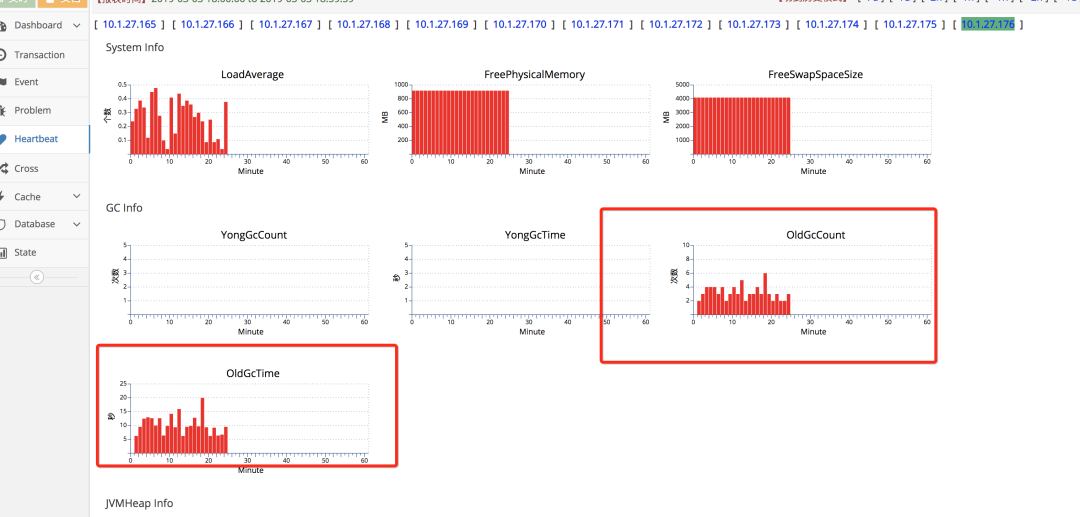
老年代 GC 次数暴涨,而且 GC 耗时都到了秒级别,1 分钟 5~10 秒的 stop the world,太恐怖了。
分析GC问题找一台机器,把GC回收dump下来分析,使用mat查看,如下图所示:
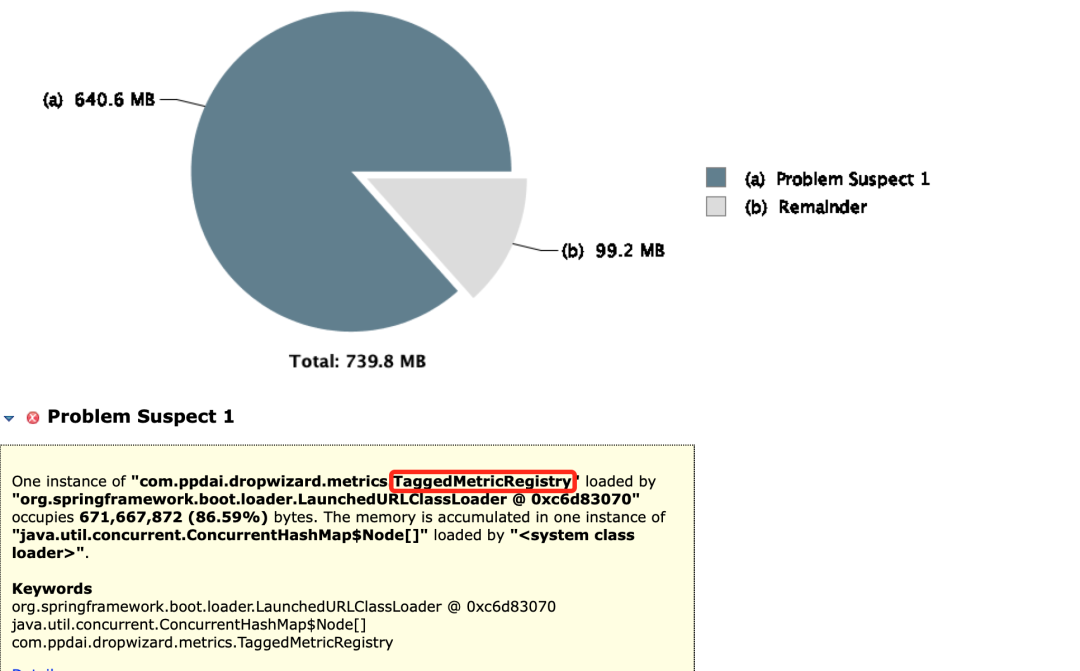
一共七百多M空间,一个对象就占了640M空间,找到原因了,大对象!
这个对象为什么会这么大呢?
我们用 MAT 分析一波。从 GC Roots 最短路径如下:
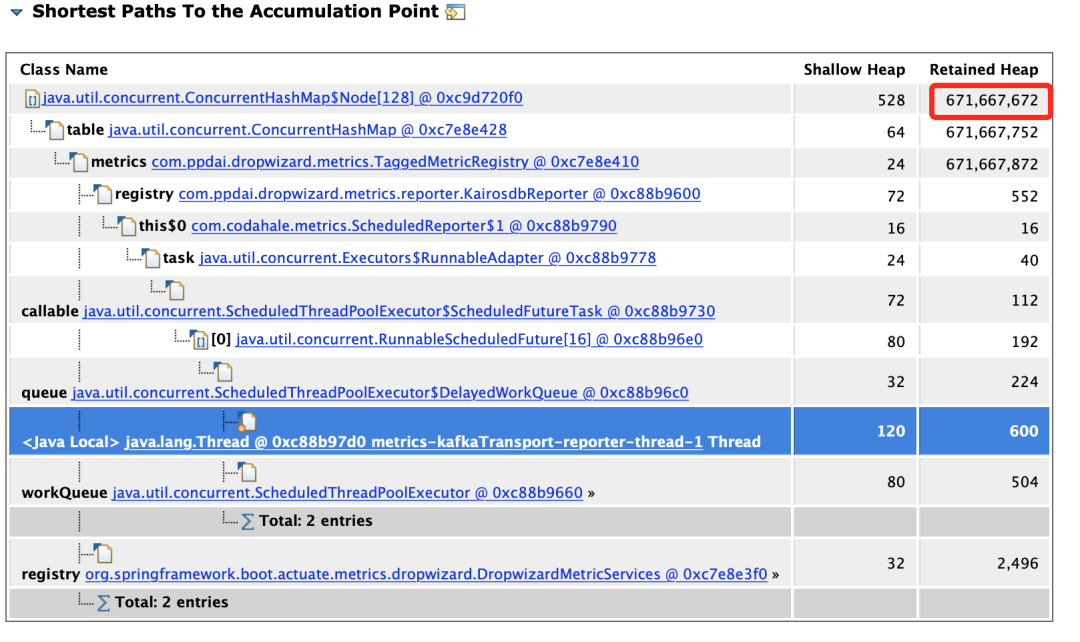
解释下,上面主要有三列:
- 第一列是内存对象的类。
- 重点在二,三列,Shallow Heap 指的是对象本身占据的内存大小,Retained Heap = 本身本身占据内存大小 + 当前对象可直接或间接引用到的对象的大小总和。说人话就是当前对象如果被回收,能够回收的内存大小。
继续看,第一步,查看谁引用了这个对象,找到自己代码中的类:
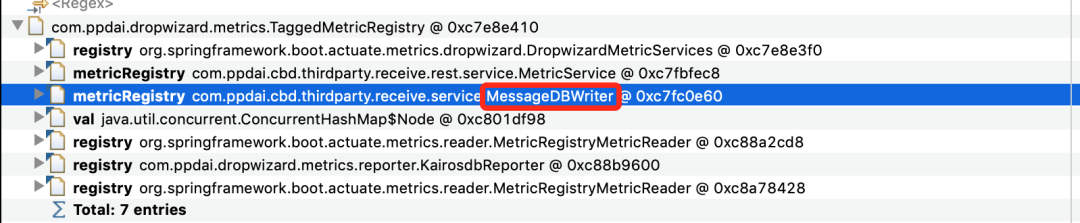
第二步,查看这个对象 TaggedMetricRegistry 都引用了谁,为什么会占用这么大的内存空间,如下图所示:

找到罪魁祸首了,metrics 这个 ConcurrentHashMap 占了 671M 内存。
现在开始可以看下代码,找到 TaggedMetricRegistry 继承自 MetricRegistry ,metrics 是 MetricRegistry 的成员变量,如下图:

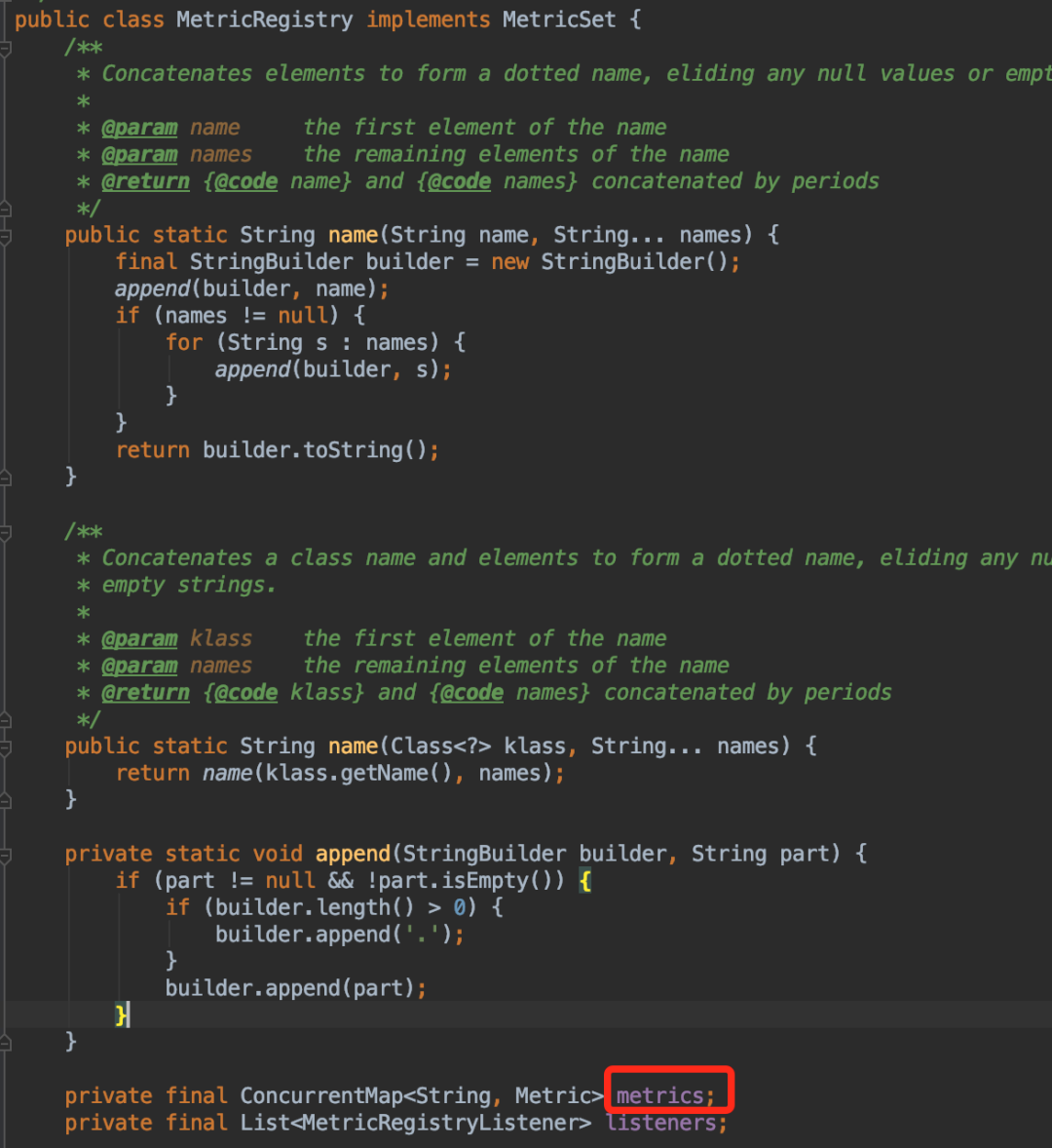
那为什么这个 ConcurrentHashMap 占了这么大的内存空间,并且 GC 也回收不掉呢?
我们继续看 MAT ,分析 ConcurrentHashMap 占有的详细内存分布:
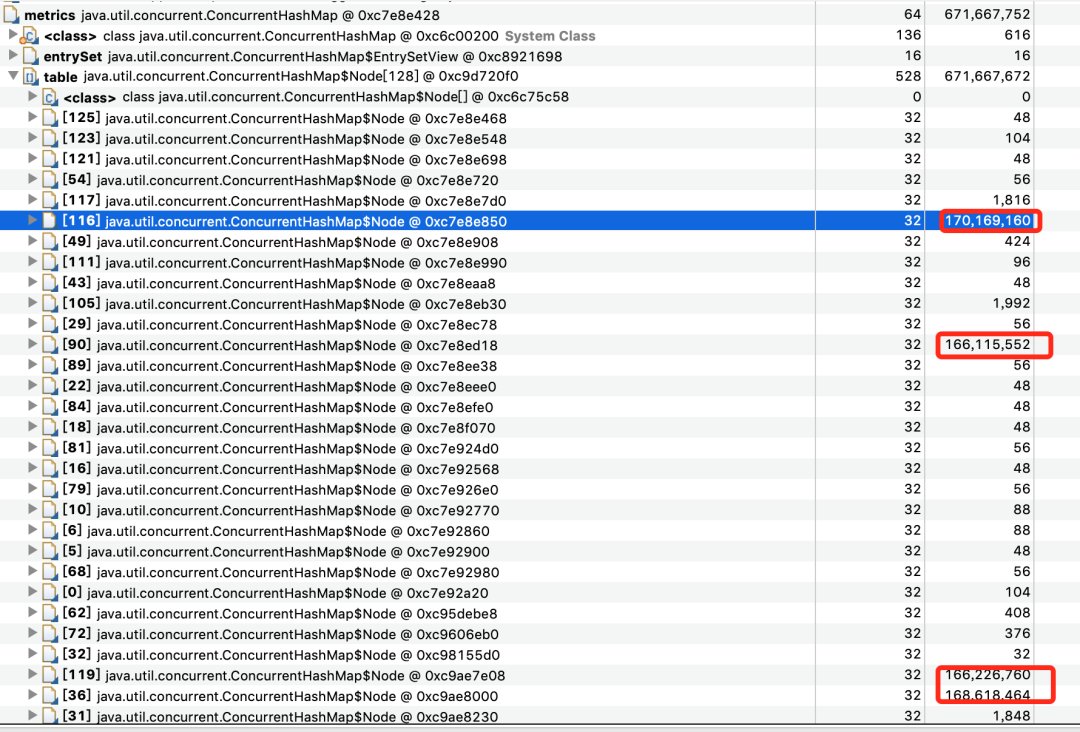
从上图我们可以发现 ConcurrentHashMap 有几个 Node 节点特别大。
于是继续追下去:
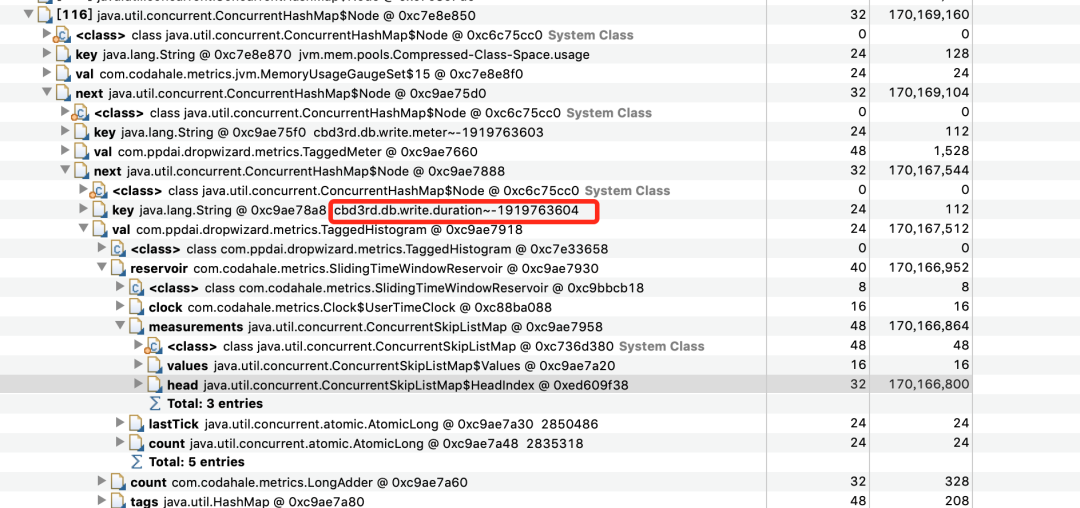
看到这个 key ,对应在代码中的位置:

这段代码就是万恶之源。
那么这段代码是干嘛的呢?
它的作用是统计接口每次的执行时间,它内部 update 的源码如下:
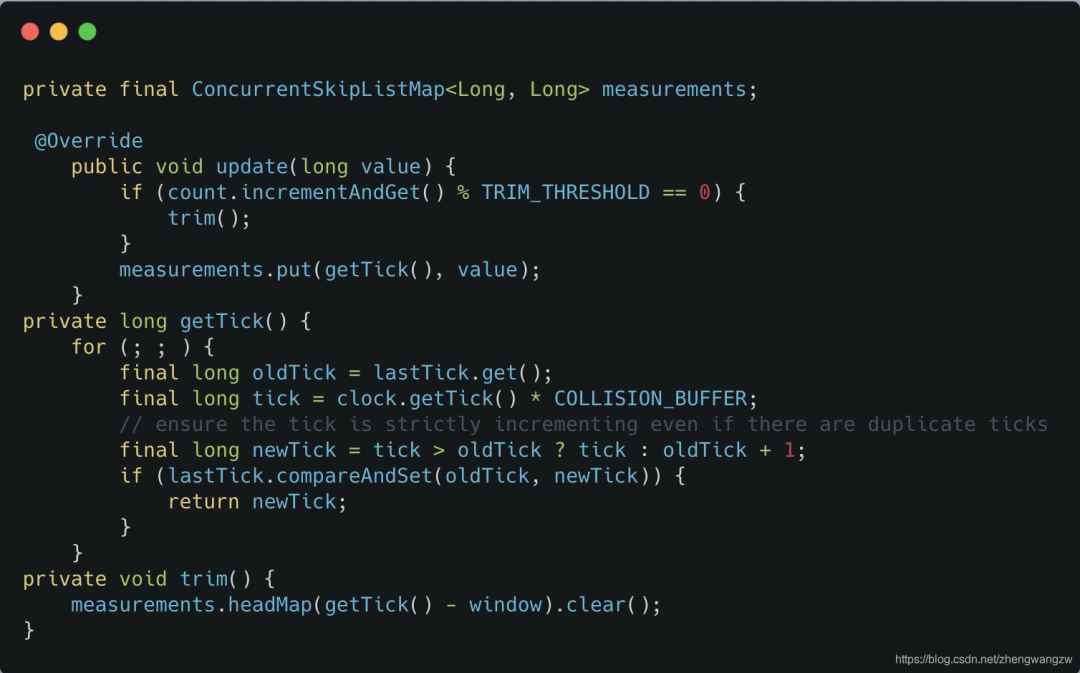
这个方法是统计接口的耗时、调用次数的。
它内部有一个 measurements 的跳跃表,存放时间戳和统计指标(耗时、调用次数)的键值对。
设置的时间窗口是 1 分钟,也就是它会存放 1 分钟的统计数据在内存中。
当然这里面有个采样比,不是 1 分钟的全量数据。
可以看到采样比是 COLLISION_BUFFER 决定的,然后 1 分钟上报一次内存数据到远端。
问题就出现在这,因为这个耗时统计的函数的 QPS 非常高,1 分钟有数据频繁产生的时候,会导致在一个时间窗口(1分钟)measurements 极速增长,导致内存占用快速增长,但是因为有强引用,GC 的时候也不会把这个回收掉,所有才出现了上面的那个情况。
why哥说
前面就是公众号[安琪拉的博客]的号主安琪拉给大家分享的一个线上问题排查的实操案例。
首先建议大家关注一波安琪拉,是个大佬,大厂 offer 收割了个遍。在公众号里面分享的文章也很硬核。
然后基于他分享的这个案例,我也想简单的分享一点自己的看法。
第一点就是监控预警系统的重要性。
文中的案例中的监控系统就是 CAT。
CAT 是什么?
我从 github 上给大家截个图:
https://github.com/dianping/cat

除了 CAT 之外,why哥知道的比较知名的监控系统还有:
- Skywalking,专注于链路和性能监控,国产开源,埋点无侵入,UI功能较强。能够加入Apache孵化器,设计思想及代码得到一定认可,后期应该也会有更多的发展空间及研发人员投入。目前使用厂商最多。版本更新较快。
- Pinpoint,专注于链路和性能监控,韩国研发团队开源,埋点无侵入,UI功能较强。
- zipkin 由Twitter开源,调用链分析工具,基于 spring-cloud-sleuth 得到广泛使用,非常轻量,使用部署简单。
监控预警系统,就是系统的眼睛。
所以why哥在上家公司的时候有幸深度参与了自研的监控系统,取名就叫做:眼睛蛇。
我取的。
第二点就是日志收集。
文中的案例,日志收集使用的是 ELK 体系。
不管是什么日志收集手段吧。
日志收集的意义是非常重大的。
现在大家都是微服务化部署,一个应用部署到几十个服务器上去。
如果需要登录到每个服务器上去查询日志,将是一件非常低效且耗时的事情。
而日志收集,就是一把利器,用顺手了,事半功倍。
第三点也就是最重要的一点:敬畏生产。
我的领导曾经不止一次的给我说过:
遇到生产问题,第一件事千万不要想着排查问题,而是想着怎么恢复业务。
其实上面这句话我也感觉很矛盾,不把问题排查出来了,怎么去解决问题然后恢复业务呢?
其实,我们常见的一个手段就是先保留现场,然后立即回滚版本。
有问题,拿到测试环境、预发布环境、灾备环境去定位,而不要在生产定位问题。
比如在这个案例中。
当我们定位到是 GC 导致的问题时,就应该当机立断的先对应用进行重启,然后对消息进行消费。
能争取一点时间就算一点时间。
而我们根据保留的现场,继续定位到是这个监控统计功能的问题,且这个功能确实是需要这么多的内存的时候。
我们知道重启是解决不了根本问题的,需要发布紧急版本,把这个统计功能关闭掉。
再之后,验证线上稳定之后,才是去复盘分析这个生产问题的前因后果。
荒腔走板
前段时间有个读者在我的公众号后台给我留言:
他说他站在我曾经拍照的地方也拍了一张照片。
是的,我当时就站在他拍的这个路牌下拍了一张照片,发在了文章里面。
只是我一个小小的、卑微的、成都的打工人,何德何能,通过一篇文章,让别人对成都产生向往。
当然,我也衷心的祝愿你,明年春暖花开的时候,现在大四实习的你,留在了成都自己喜欢的岗位,工位上插着一把花正旺盛的绽放着。
我主要是想要分享一下真正让我澎湃的关于成都的一篇文章:
《什么是成都?》
这是星球研究所于 2018 年 3 月 2 日发布的一篇文章,那一天正是戊戌年正月十五,彼时我还是一个在外的游子,那天我没有吃到元宵,但是这篇文章就是最好的“元宵”。
甚至不舍得一口气读完,仿佛在细品着一碗佳酿。之后又反复观看了几遍这篇文章,内心产生了无数的遐想。
成都不是我的故乡,但是我仿佛是听到了来自故乡的欢呼。
引用评论中的一句话:
如若 1600 万的成都人都能有幸阅读到,那一定是至少 1600 万次的澎湃与自豪。
加油哦,成都欢迎你。
《什么是成都?》这篇文章分享给你,希望你能喜欢。
推荐👍 :有哪些道理是我当了程序员后才知道的?
推荐👍 :没想到你竟然是这样的volatile!
推荐👍 :这个Bug的排查之路,真的太有趣了。
推荐👍 :卧槽,这年轻人。
推荐👍 :我给Apache顶级项目贡献了点源码。
我是 why,一个主要写代码,经常写文章,偶尔拍视频的程序猿。
还有,欢迎关注我呀。
转发、点赞、在看、一键三连。
