
北交大TransGPT,开源了!
转自:机器之心
火热了半年多,国内大模型领域迎来中场战事,眼下入场的包括在垂直领域深耕多年的机构、企业,开始借助行业特色优势打入大模型战场。
近日,北京交通大学联合中国计算机学会智慧交通分会与足智多模公司等正式发布、开源了自主研发的国内首款综合交通大模型:TransGPT・致远。
项目地址:
https://github.com/DUOMO/TransGPT
TransGPT・致远的训练基于约 34.6 万条交通领域文本数据(用于领域内预训练)和 5.8 万条交通领域对话数据(用于微调),可支持实时类 APP 接入(地图、公交等应用)。目前,TransGPT・致远已开源,相关资源不仅对学术研究完全开放,仅需邮件申请并获得官方商用许可后,即可以免费商用。
与通用型的多模态交通大模型产品不同,TransGPT 主要致力于在真实交通场景中发挥实际价值,包括交通情况预测、智能咨询助手、公共交通服务、交通规划设计、交通安全教育、协助管理、交通事故报告和分析、自动驾驶辅助系统等能力。
功能特色
「TransGPT 综合交通大模型」的主要功能和特色如下:
1、交通安全教育
交通大模型可以用于生成交通安全教育材料,如安全驾驶的建议、交通规则的解释等。

2、智能出行助手
在车辆中的智能助手可以使用大型交通大模型来理解和生成更自然、更复杂的对话,帮助驾驶者获取路线信息、交通更新、天气预报等。自动回答关于公共交通服务的问题,如车次、票价、路线等。这可以提高服务效率并提升乘客体验。

3、智能交通管理
通过实时监测和分析车辆、道路、信号灯等信息,协助智能协调交通流量,减少交通拥堵。分析社交媒体或新闻报道中的文本信息,预测交通流量、交通堵塞或事故的可能性。同时,该模型能分析交通事故历史和特征,给出相应对策和方案,减少交通事故的发生。

4、智能交通规划
交通大模型可以帮助分析公众对于交通规划提案的反馈和意见,提供决策者更全面的信息。

5、交通事故报告和分析
交通大模型可以帮助快速理解和分类交通事故报告,提供事故原因的初步分析。

6、交通政策研究
大型交通大模型可以用于分析公众对于交通政策的反馈,或者生成关于交通政策影响的报告。这可以帮助政策制定者更好地了解政策的实际效果。

TransGPT 交通大模型已经具备面向 BIM 模型审核员、智能运维、智能咨询等场景的应用落地能力,将大幅度促进铁路工程等数字化转型和智能化提升。韩文娟团队介绍,交通大模型采用了基于 Transformer 架构的文本大模型、多模态大模型与实时场景数据调用能力,整体上形成综合交通大模型为基础设施、辅以交通细分行业应用的架构。支持实时类应用,包括:驾车规划、公共交通规划、(逆)地理编码查询等落地场景应用能力,能够促进铁路交通等领域的数字化转型和智能化提升。
数据
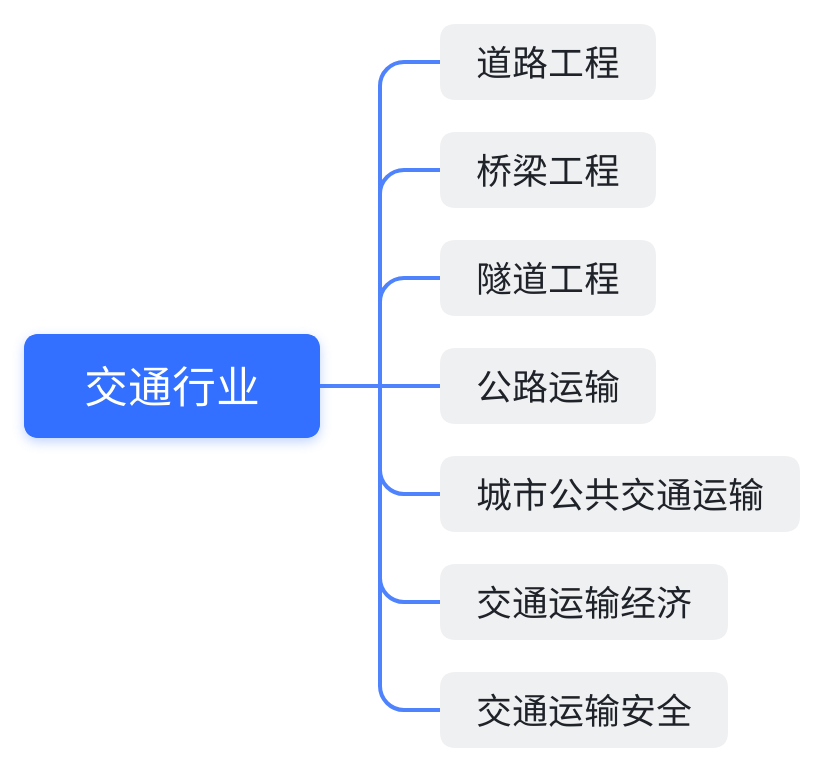
TransGPT 背后团队北京交通大学长期深耕交通主赛道,形成了数据壁垒,因而对于构建综合交通大模型有很多先天优势,其数据内容覆盖以下交通行业:
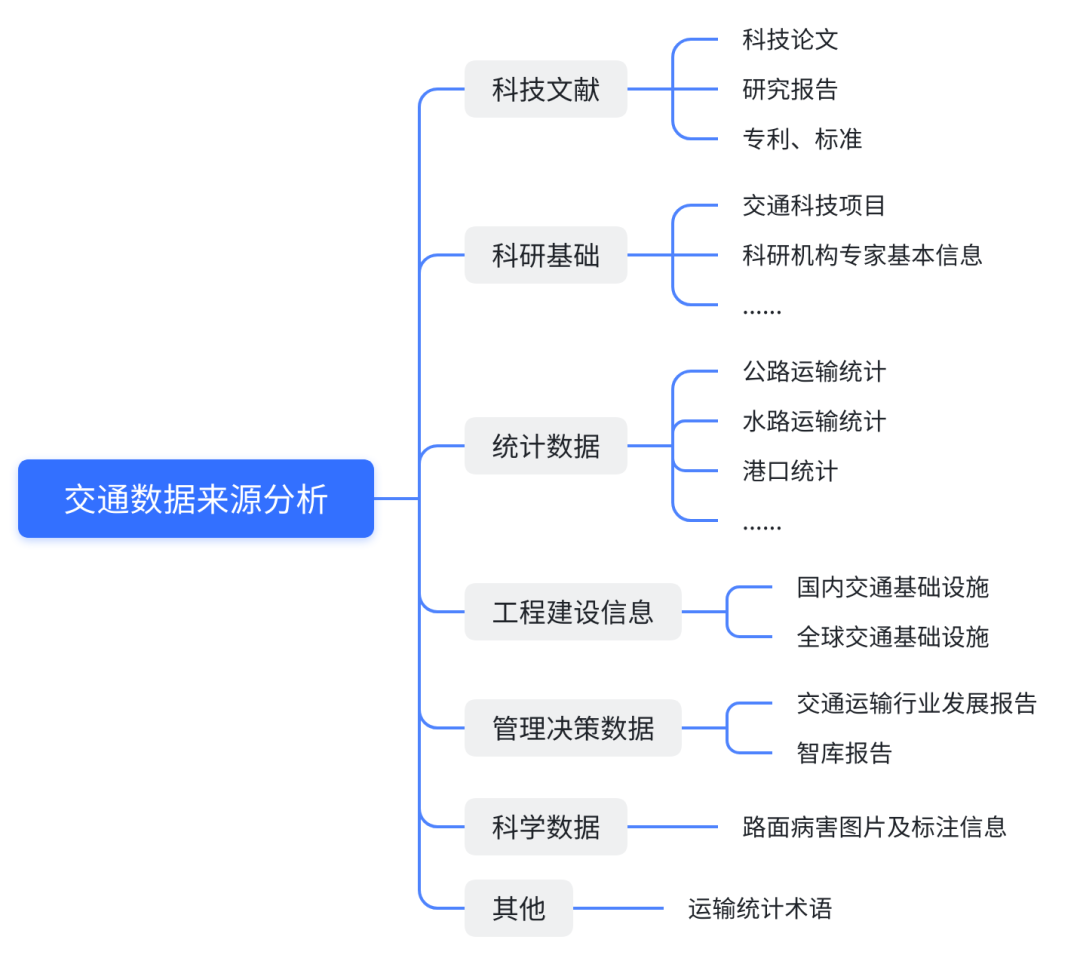
数据来源包含以下方面:
模型
目前已开源内容包括:
模型 TransGPT
数据集 TransGPT-DATA-sft (可商用)
数据集 TransGPT-DATA-pt (可商用)
语言模型
研究者基于 chinese-alpaca-plus-7b-hf 模型框架训练了综合交通大模型的语言模型版本。实现了包括通用领域预训练、交通领域内预训练、有监督微调、奖励建模、强化学习训练。
交通领域的训练过程如下:
1、从原始 pdf、docx,doc 格式文件中提取文本
2、利用 LLM 根据文档生成对话数据(微调对话数据生成方法见 LLMforDialogDataGenerate)
3、pt 训练代码见 supervised_finetuning.py。
4、sft 训练代码见 supervised_finetuning.py。
多模态模型
在多模态复杂场景中,图片和文本的细粒度对应是一项挑战,特别是在存在多个图像且图像的顺序、绝对位置和相对位置至关重要的复杂环境中。为了准确地指示图像位置,区别图像表征和文本表征,研究者使用了图像标志(image token,即 <\image n>),并且模型允许多图像输入(<\image 1>、<\image 2>))。
为了充分利用 LLM 的优势,研究者利用强大的 LLM(Vicuna)作为骨干。训练过程中冻结语言模型(LLM)和视觉编码器(visual encoder)的参数,解冻 LLM 和 visual encoder 之间的连接模块(Q-former)的参数,并在交通领域数据集上对其进行微调。从而既能利用 LLM 和 visual encoder 预训练的知识,同时使其适应交通多模态场景中的特定需求。
多模态模型训练包括三步:
1、预训练:预训练的视觉编码器和 LLM 都保持冻结,只有 Q-Former 需要学习与文本最相关的视觉表示,并由 LLM 通过类似 LAION-400M 的训练进行解释。
2、多模态指令微调:执行多模态指令微调以提高 VLM 的性能,类似 InstructBLIP。
3、多模态上下文指令微调:进一步在数据集中执行多模态上下文指令微调,以激活处理 VLM 的多图像输入的能力。这个阶段使其能够充分激发多模态环境中 LLM 令人印象深刻的推理潜力。
评测
研究者在交通 benchmark 上进行了 zero-shot 评测:

1、交通安全教育:生成交通安全教育材料,如安全驾驶的建议、交通规则的解释等。
2、交通情况预测:分析社交媒体或新闻报道中的文本信息,预测交通流量、交通堵塞或事故的可能性。
3、事故报告和分析:理解交通事故报告,提供事故原因的初步分析。
4、交通规划:分析公众对于交通规划提案的反馈和意见,提供决策者更全面的信息。
写在最后
以交通行业大模型为关键驱动,TransGPT 运用现代信息技术,集成感知、通信、控制、决策、协同等功能,实现交通设施、交通运输工具、交通管理和交通服务的智能化,赋能行业生产效率和服务质量提升,将会推动交通行业的深刻变革。实际应用行业场景的反馈,又将进一步加速交通行业大模型的技术迭代,从而提高国产交通大模型的竞争力。「TransGPT 综合交通大模型」可化身为「交通行业专家、工程师」,与交通行业政策制定者、执行者、工程师、运维人员、普通用户进行交流合作,提供支撑辅助能力,协助其分析解决方法并提供决策建议。
此前,北京交通大学长期深耕交通主赛道,在人工智能交通行业大模型能力上已具备一定基础,形成了一定的行业壁垒、数据壁垒、知识壁垒,逐步夯实了面向铁路工程、道路工程、桥梁工程、隧道工程、公路运输、水路运输、城市公共交通运输、交通运输经济、交通运输安全等交通行业大模型优势。
综合交通大模型的诞生只是一个起点,其最终还是要落脚到特定细分的交通应用场景。未来,团队将以 TransGPT 综合交通大模型为基础,打造以交通知识大模型为中心、以实时信息为渠道,自主预测、提前预警、主动服务的交通一体化体系,为交通参与者提供多样性的服务,从而使人、车、路之间的相互作用关系以新的方式呈现,从而实现实时、准确、高效、安全、节能的目标。
 ·················END·················
·················END·················