
HPC:程序优化思考
今天老大在群里说了一个程序优化的事情,就顺便想了一下这个问题,但是比较零散不成体系,下午好好想了想和整理了一下,感觉相对有些完整了,就记录下来,这些年来光写代码不归纳和总结,这样是不好的
一、概述
以前学编译原理的时候,记得老师说过一句话,说做编译优化的人永远不会失业,因为编译优化没有尽头,而编译优化实际上是程序优化的一个子集,所以同理,程序优化也没有尽头,本文想从下面图中所示的三个层面对程序优化做一点总结:
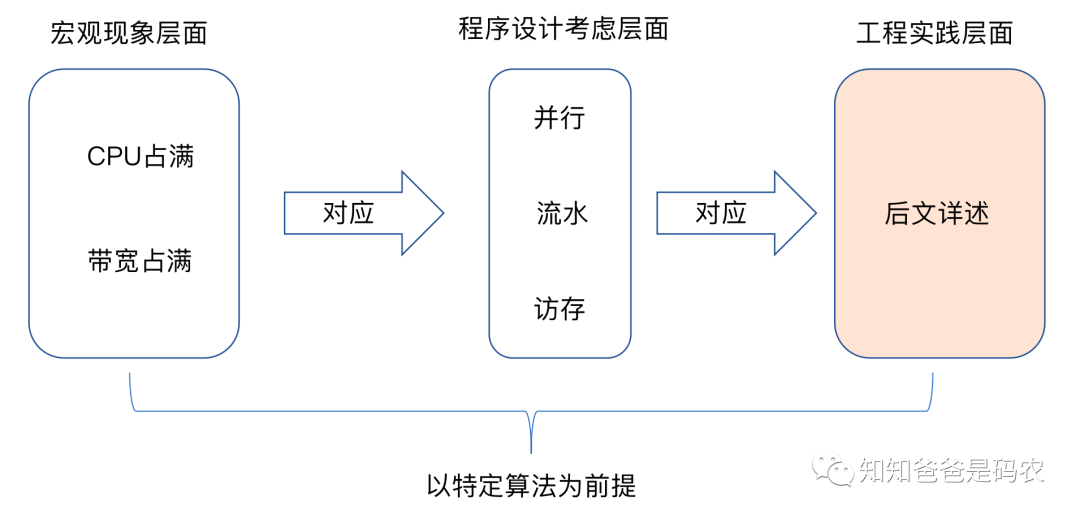
图1
先说明一下上面图示中的以特定算法为前提这句话的意思,同样一个问题,不同的算法有不同的时空复杂度,算法就像基因一样,属于程序性能的先天因素,只有好的算法加上后面说到的各种合理优化手段,才能让程序性能在特定硬件平台上有更出色的表现。
再看图中的宏观现象层面,这里的占满都是指有效占满(举个极端的例子,比如设置一个无限循环让处理器一直算A*B,这种占满如果不是为了解特定的问题,通常情况下就认为是无效占满):
CPU占满:这个很好理解,理想情况下,当然是不浪费CPU的每一个cycle,让CPU一直在忙
带宽占满:这个其实和减少访存(比如通过提高Cache利用率和命中率等方式)不互相矛盾,这里指的是在尽量减少访存的前提下把带宽占满,用更容易理解的话来说,就是让各种器件尽可能都能一直保持在工作状态,没人在偷懒
当然上面说的都是理想情况,实际上总会有一些bottleneck,让某些器件时不时处于空闲状态,这基本上都是由于处理器的处理速度和数据加载速度不匹配所造成的,Cache就是为了缓解这种速度不匹配而出现的。
为了能让物理器件尽可能的达到上面说的理想情况,做程序设计的时候,相对应的需要考虑并行、流水、访存这些方面,下面从工程实践的角度具体一个个来看这三个方面。
二、并行
说到并行,可能大家很快就会想到多线程/多进程和分布式(本文就不提分布式了),实际上并行还有其他的实现途径,我感觉并行在工程实践的角度可以分为下面图中的几个方面:
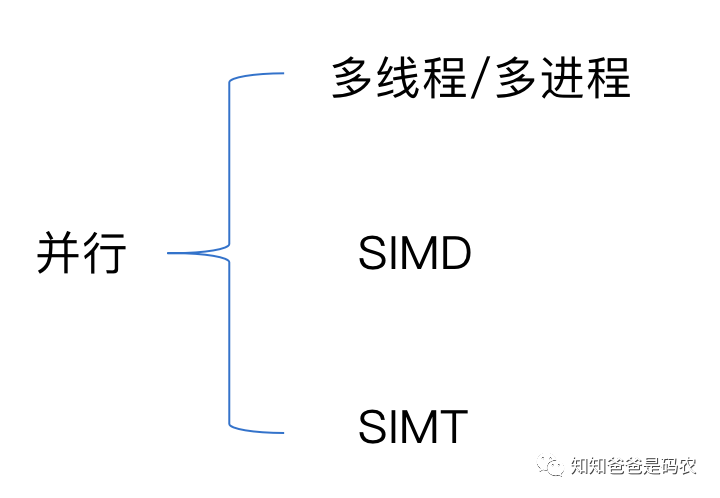
图2
先看多线程/多进程这种并行手段,如果处理器是多核的,那么很好理解,通过把任务划分成多个子任务,每个处理器核完成一个子任务,这是真正的物理上的并行,如果处理器是单核的,实际上多个线程/进程之间是系统内核通过某种调度算法来实现的逻辑上的并行,虽然是逻辑上的并行,也是有可能提高硬件使用效率的,最简单的例子,两个进程A、B,进程A需要在内存和外设之间通过DMA传一批数据,那么在传数期间,不需要CPU参与,那么自然可以把CPU让给进程B使用,这样一来,CPU的使用效率就上去了。当然这里分析的都是理想情况,忽略了线程/进程调度本身的开销等因素。
再看SIMD(单指令多数据),原理很简单,从名字就可以看出来,指令可以运算向量数据(拿加法来说,传统指令一次只能算a+b,而这种指令一次可以算a1+b1、a2+b2、a3+b3、a4+b4),之前写过不少相关的代码,ARM系列芯片是通过NEON指令集实现的,X86系列芯片是通过SSE、AVX指令集实现的,写这种代码时主要需要注意的问题是内存对齐,还有一些corner case的处理(比如有5个数,而这种指令一次只能4个4个一起处理),Halide中的vectorize这个schedule生成的就是这种优化代码。
最后看下SIMT(单指令多线程),主要是CUDA编程的范畴,老实讲这个我了解的很少,之前一直做专用加速器的相关应用,工作中没用过CUDA,之前看过一点书,写了两篇笔记:
总体来讲CUDA这方面的知识,目前还处于小白水平,以后有机会有时间好好学一下吧~
三、流水
流水这个问题在编译器中是很重要的一个问题,以下图为例来说明这个问题:
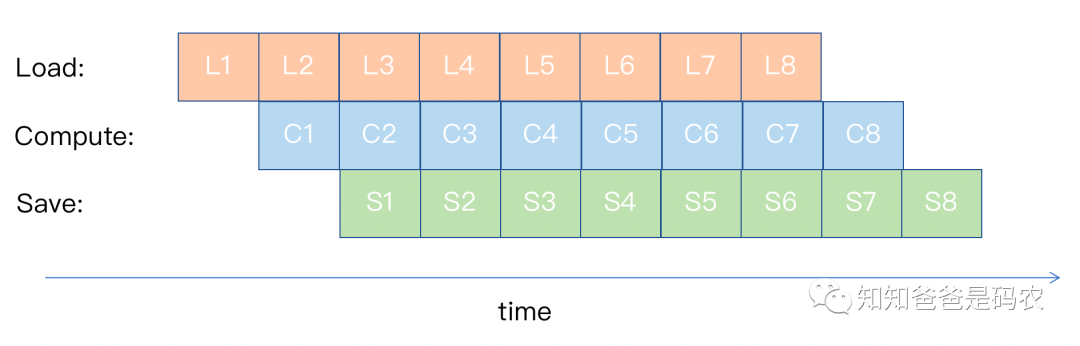
图3
在上图中,假设有三种硬件逻辑,Load(拿数给CPU)、Compute(用拿到的数做运算)、Save(把计算结果传回主存),如果每种操作所用的时间相同,那么经过若干系统时钟周期之后,所有的硬件逻辑都能处在一直工作的状态,这是最理想的情况,但现实往往不是理想的,如果Load、Save的时间比Compute的时间长,如下图所示:
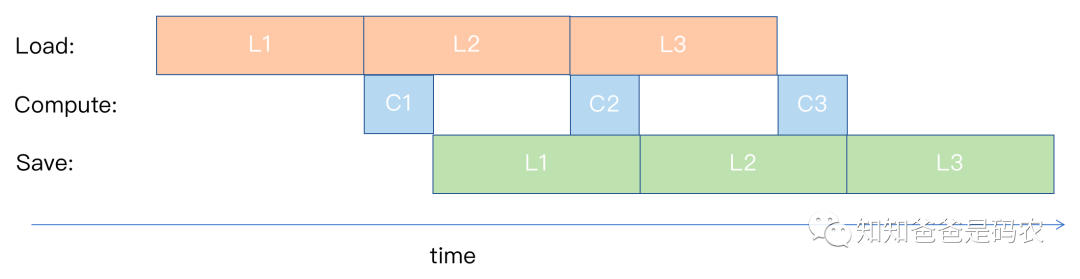
图4
这时候Compute对应的硬件逻辑就会忙一会闲一会,也就是流水流起来之后两次Compute之间有gap,这里如果Load、Save花的时间相对Compute多太多的话,某些情况下re-compute会是一个优化手段,即如果需要使用到以前的某个计算结果,但是Load、Save的开销又比较大,还不如重新算一次来的快,OneFlow中的后向计算中就使用了这种优化,具体可参考公司同事写的这篇《亚线性内存优化— activation checkpointing在oneflow中的实现(https://zhuanlan.zhihu.com/p/373662730)》。
还有一种情况,就是Compute所用时间比Load、Save多,如下图所示:
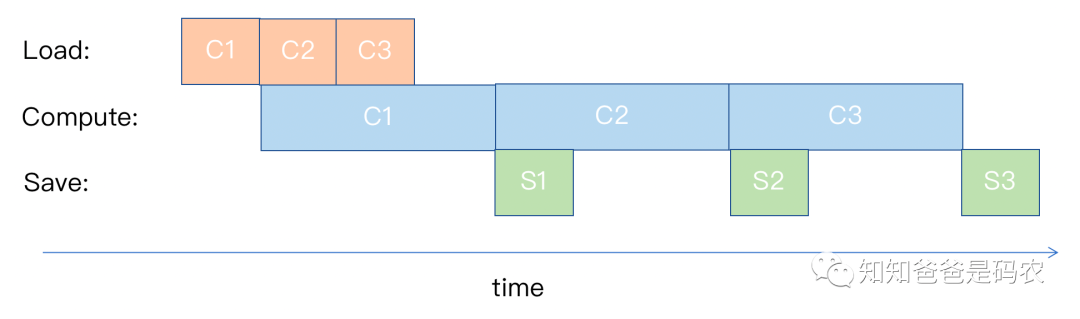
图5
在这种情况下,如果需要使用到以前的某个计算结果,在Compute所用时间比Load、Save多太多的情况下,re-load可能会是比较好的选择。
四、访存
访存问题几乎是我们写代码时打交道最多的一个问题,先做一下这类问题的分类,如下图所示:
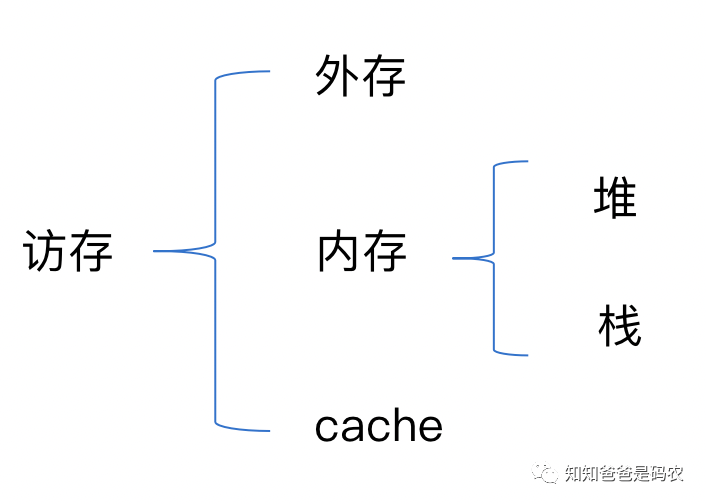
图6
先看访问外存的优化,这部分大家可能乍一听觉得接触不多,确实如此,这部分的优化大部分都被操作系统或者标准库做掉了,除非是写一些文件读写相关的程序,我们很少需要关注,但如果把一些常用外设的访问也放在这一类的话,比如标准输入、标准输出等,举个最简单的例子,如果用cout << xxx << endl这样的代码输出信息到stdout并换行,需要注意下endl的含义,直接看标准库中endl的实现会比较清楚:
// https://github.com/RTEMS/gnu-mirror-gcc/blob/master/libstdc++-v3/include/std/ostream#L678template<typename _CharT, typename _Traits>inline basic_ostream<_CharT, _Traits>& endl(basic_ostream<_CharT, _Traits>& __os){ return flush(__os.put(__os.widen('\n'))); }
可以看到endl中调用了flush,所以cout如果频繁使用endl来换行的话,速度肯定会慢,当然这个要看使用场景,如果想尽量实时显示运行输出,那这样使用没问题。
再看访问内存的优化,其实应该更细分为使用栈和使用堆的优化:
先看使用栈的优化,大家可能马上想到的是标准库中的栈,实际上我们在写代码的时候,我们用的更频繁或者说每个人都必然会用到的是函数的调用栈,函数的调用有开销,主要是栈上操作的开销,inline的作用就是为了做这种函数调用优化,但inline也不是万能的,它一般只适用于短小精悍的函数,否则函数展开之后容易导致代码膨胀,代码膨胀会导致生成的binary变大、CPU的指令cache效率变低等问题。之前讲的表达式模板中的优化手段归根结底也是利用编译器在编译期把模板函数实例化之后递归调用的inline函数做展开来实现的。
再看使用堆的优化,也就是通常意义上我们所说的访存,这是我们写代码考虑最多的部分,这部分需要和上面图6中的访问cache这部分一起说,写代码的时候既需要考虑内存管理(这是个非常大的话题,可参考之前写过的一个相关系列《内存管理:小结》),又需要考虑和cache的交互,即根据程序的局部性原理来尽可能的提高cache的使用率和命中率,Halide中的reorder这个schedule就是来解决这个方面问题的。
五、Summary and Reference
关于程序优化可说的实在太多了,一方面我们自己写的应用代码中自己会做手动优化,另一方面还有一些专门的工具如Halide可以做自动优化,它里面的fuse、split、tiling、unrolling、reorder、vectorize、parallel等等这些schedule就是在从本文谈的并行、流水、访存这些方面来做优化,还有一个感觉需要提的工具是Polyhedral,这个我不大懂。。。只是从公众号和知乎上看过Polyhedral专家赵捷博士(知乎名字是要术甲杰,公众号的三篇文章我贴会在最后,此外还有相关的论文我没看过)的一些科普文章,目前只看了个热闹,原理性的东西还没大看懂(捂脸),以后有时间一定要好好学一学。其实关于“以后有时间”这句话我感触良多,到底啥时候有时间我也不知道,感兴趣的东西太多,每个都要花很多时间研究,那么时间到底应该花在谁身上呢?不会的东西太多,每个都要花很多时间学习,那么时间到底应该花在谁身上呢?
最后列一下参考资料:
CSAPP的两个章节:
《第五章:优化程序性能》
《第六章:存储器层次结构》
NEON和AVX的官方文档
CUDA相关的书,我买了下面这几本,大家做参考:
《CUDA C编程,权威指南》
《GPU高性能编程,CUDA实战》
《CUDA并行程序设计,GPU编程指南》
《CUDA编程,基础与实践》
Halide官方文档和代码
Polyhedral相关的文章,主要来自赵捷博士,知乎上的文章大家自己去搜,下面列一下公众号上的三篇文章: