
豪取4个SOTA,谷歌魔改Transformer登NeurIPS 2021!一层8个token比1024个还好用
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


导读
谷歌改造Vision Transformer的新作被NeurIPS 2021收录了。在这篇文章里,谷歌提出了TokenLearner方法,Vision Transformer用上它最多可以降低8倍计算量,而分类性能反而更强!
目前,Transformer模型在计算机视觉任务(包括目标检测和视频分类等任务)中获得了最先进的结果。
不同于逐像素处理图像的标准卷积方法,Vision Transformer(ViT)将图像视为一系列patch token(即由多个像素组成的较小部分图像)。
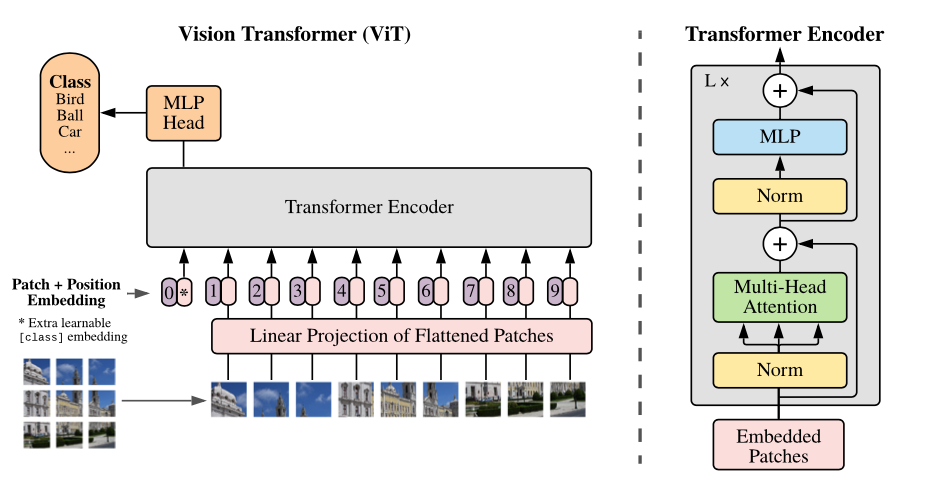
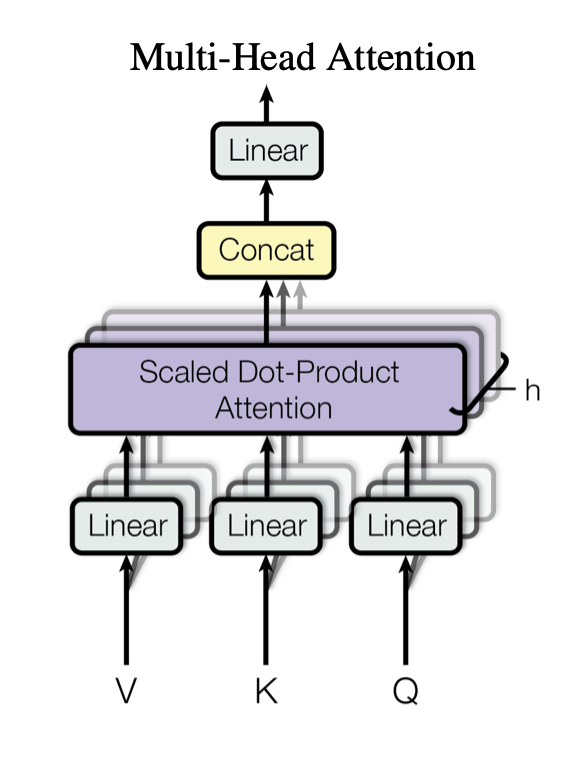
这也就意味着在每一层神经网络中,ViT模型使用多头自注意力(multi-head self-attention),基于每对token之间的关系来处理patch token。
这样,ViT模型就能够构建整个图像的全局表示。
在输入端,将图像均匀地分割成多个部分来形成token,例如,将512×512像素的图像分割成16×16像素的patch token。在中间层,上一层的输出成为下一层的token。
这里插一句。如果处理的是视频,则视频「管道」如16x16x2视频片段(2帧16x16图像)就成为了token。视觉token的质量和数量决定了Vision Transformer的整体性能。
许多Vision Transformer结构面临的主要挑战是,它们通常需要太多的token才能获得合理的结果。
例如,即使使用16x16patch token化,单个512x512图像也对应于1024个token。对于具有多个帧的视频,每层可能都需要处理数万个token。
考虑到Transformer的计算量随着token数量的增加而二次方增加,这通常会使Transformer难以处理更大的图像和更长的视频。
这就引出了一个问题:真的有必要在每一层处理那么多token吗?
谷歌在「TokenLearner:What Can 8 Learned Tokens Do for Images and Videos?」中提到了「自适应」这个概念。这篇文章将在NeurIPS 2021上进行展示。

论文地址:https://arxiv.org/pdf/2106.11297.pdf
项目地址:https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
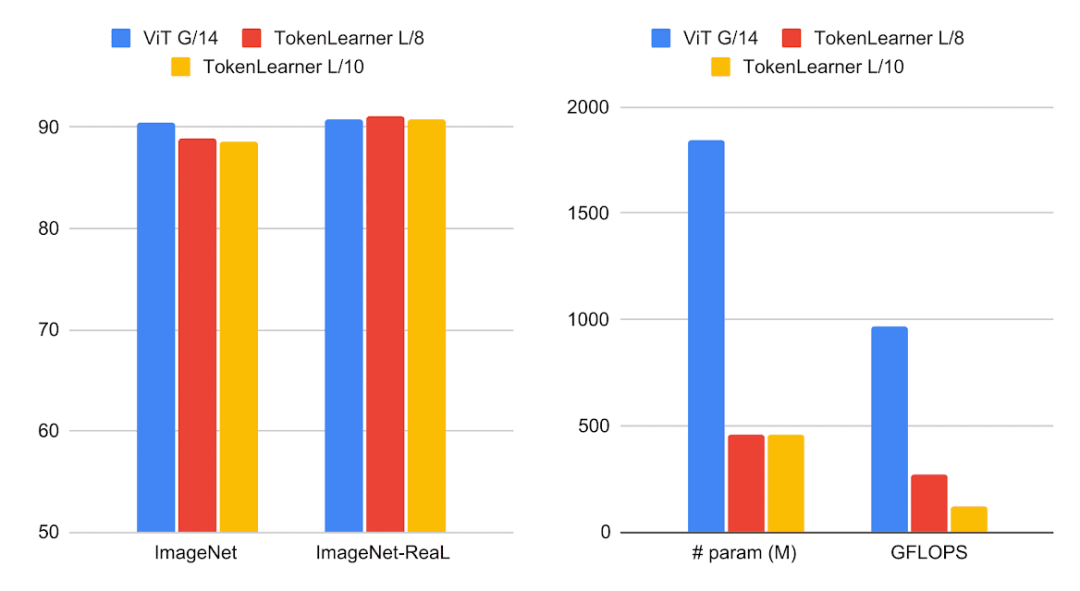
实验表明,TokenLearner可以自适应地生成更少数量的token,而不是总是依赖于由图像均匀分配形成的token,这样一来,可以使Vision Transformer运行得更快,性能更好。
TokenLearner是一个可学习的模块,它会获取图像张量(即输入)并生成一小组token。该模块可以放置在Vision Transformer模型中的不同位置,显著减少了所有后续层中要处理的token数量。
实验表明,使用TokenLearner可以节省一半或更多的内存和计算量,而分类性能却并不会下降,并且由于其适应输入的能力,它甚至可以提高准确率。
TokenLearner是啥?
TokenLearner其实是一种简单的空间注意力方法。
为了让每个TokenLearner学习到有用的信息,先得计算一个突出的重要区域的空间注意力图(使用卷积层或MLP)。
接着,这样的空间注意力图会被用来对输入的每个区域进行加权(目的是丢弃不必要的区域),并且结果经过空间池化后,就可以生成最终的学习好了的token。
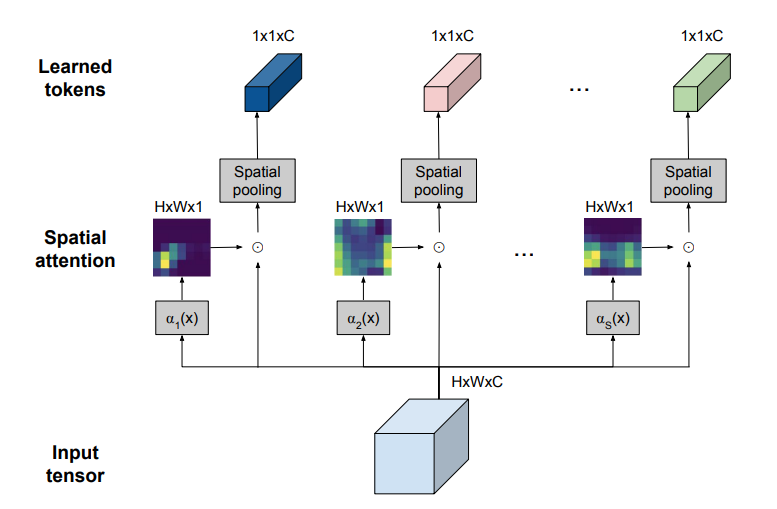
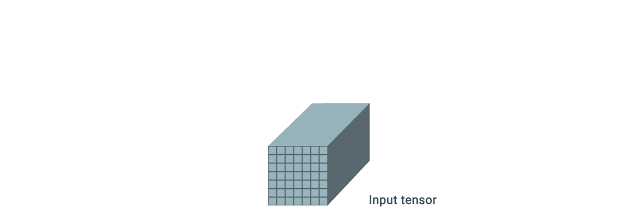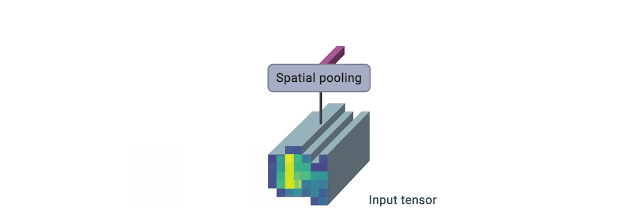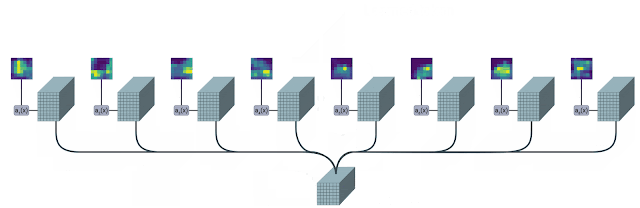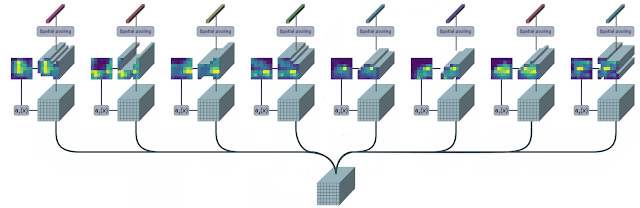
应用于单个图像的TokenLearner模块的直观图示
TokenLearner学习在张量像素的子集上进行空间处理,并生成一组适应输入的token向量。
这种操作被并行重复多次,就可以从原始的输入中生成n个(10个左右)token。
换句话说,TokenLearner也可以被视为基于权重值来执行像素的选择,随后进行全局平均。
值得一提的是,计算注意力图的函数由不同的可学习参数控制,并以端到端的方式进行训练。这样也就使得注意力函数可以在捕捉不同输入中的空间信息时进行优化。
在实践中,模型将学习多个空间注意力函数,并将其应用于输入,并平行地产生不同的token向量。
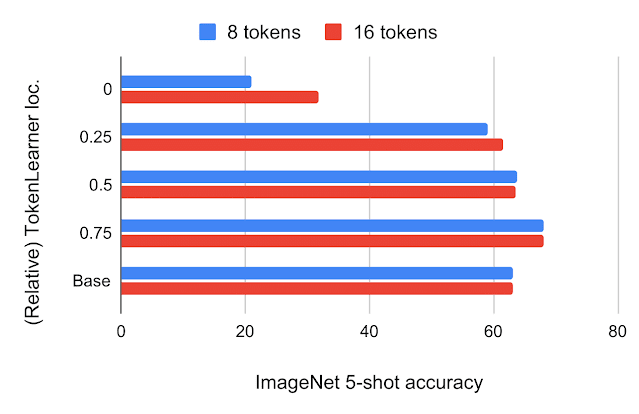
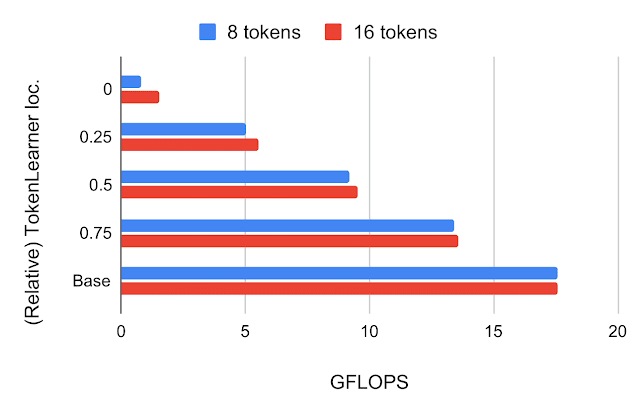
TokenLearner放在哪?
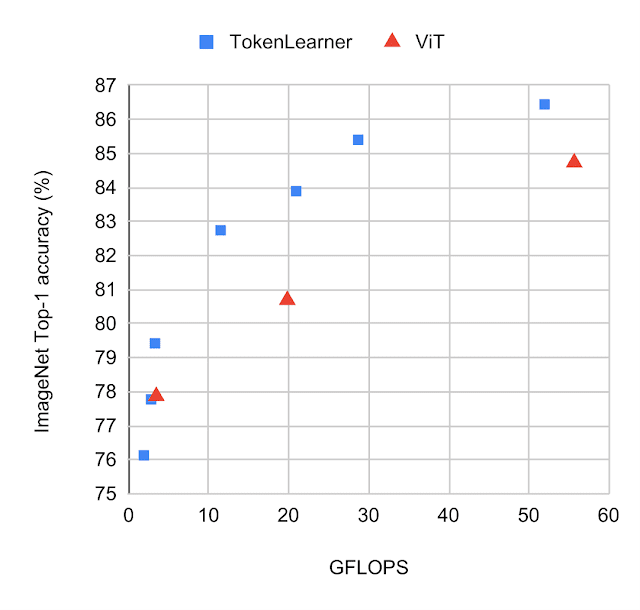
TokenLearner VS ViT
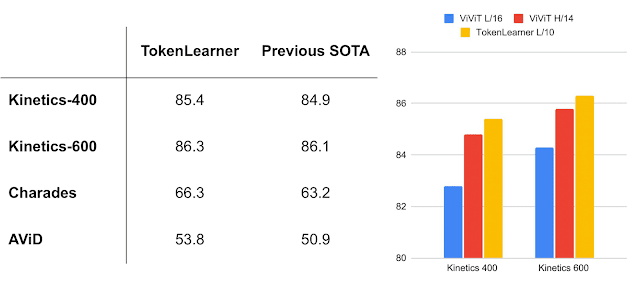
高性能视频模型
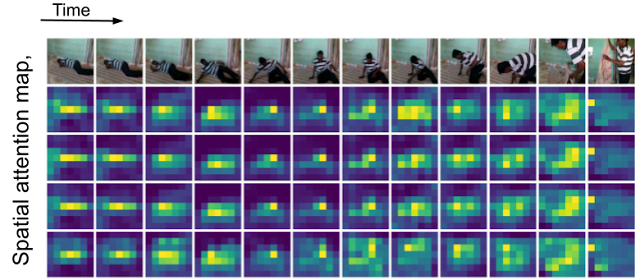
结论
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!